Amazon Web Services ブログ
Amazon SageMaker で OpenChatKit モデルを活用し カスタムチャットボットアプリを構築するには
オープンソースの大規模言語モデル (LLM) が普及し、研究者、開発者、組織がこれらのモデルにアクセスして、イノベーションや実験を促進できるようになりました。オープンソースコミュニティの協業が促進され、LLM の開発と改善に貢献しています。オープンソースの LLM はモデルアーキテクチャやトレーニングプロセス、トレーニングデータに透明性を提供し、これによって研究者はモデルの仕組みを理解し、潜在的なバイアスを特定し、倫理的な懸念に対応することができます。これらのオープンソースの LLM は、高度な自然言語処理 (NLP) テクノロジーを幅広いユーザーが利用してミッションクリティカルなビジネスアプリケーションを構築できるようにすることで、生成系AIを民主化しています。GPT-NeoX や LLaMA、Alpaca、GPT4All、Vicuna、Dolly、OpenAssistant は、人気のあるオープンソースの LLM のうちの一部です。
OpenChatKit は、汎用的および特殊なチャットボットアプリケーションを構築するために、Apache-2.0 ライセンスの下、Together Computer によって2023年3月にリリースされた、オープンソースの LLM です。このモデルを利用すると、開発者はチャットボットの動作を特定のアプリケーションに合わせてより制御し、調整できるようになります。OpenChatKit はツールのセット、基本のボットと、フルカスタマイズされたパワフルなチャットボットを構築するためのビルディングブロックを提供します。主要な要素は以下の通りです。
- 100%カーボンネガティブなコンピュート上の4,300万を超えるInstructionを備えた、EleutherAI の GPT-NeoX-20B によるチャット用にファインチューニングされたInstruction tuning済みの LLM 。
GPT-NeoXT-Chat-Base-20Bモデルは、EleutherAI の GPT-NeoX をベースにしており、ダイアログ式のInstructionに特化したデータでファインチューニングされています。 - 固有のタスクに対する高い精度を実現する、モデルをファインチューニングするためのカスタマイズレシピ。
- 拡張可能な検索システムにより、推論時にドキュメントリポジトリ、API、そのほかのライブ更新される情報ソースからの情報を利用して、ボット応答を拡張できます。
- GPT-JT-6B からファインチューニングされ、ボットが応答する質問をフィルターするよう設計された、モデレーションモデル。
深層学習モデルのスケールとサイズの拡大で、これらのモデルを生成系AI アプリケーションにうまく導入するのに妨げが生じています。低レイテンシーと高スループットの要件を満たすためには、モデルの並列処理や量子化などの高度な手法を採用することが不可欠になってきています。これらの手法の適用に熟練していないために、多くのユーザーは、生成系AIのユースケース用の大規模なモデルのホスティングを開始する際に困難に直面しています。
本投稿では、DJLサービングと、DeepSpeed や Hugging Face Accelerate などのオープンソースのモデル並列ライブラリ使用して、OpenChatKit モデル (GPT-NeoXT-Chat-Base-20B および GPT-JT-Moderation-6B) を Amazon SageMaker にデプロイする方法を記載します。プログラミング言語に依存しない Deep Java Library (DJL) を利用したハイパフォーマンスなユニバーサルモデルサービングである、DJLサービングを使用します。また、Hugging Face Accelerate ライブラリがどのようにして大規模なモデルの複数の GPU へのデプロイメントを簡素化し、それによって分散方式で LLM を実行する負担を軽減するかを示していきます。さあ始めましょう!
拡張可能な検索システム
拡張可能な検索システムは、OpenChatKit の重要な要素の一つです。これにより、クローズドドメインのナレッジを元に応答するボットを、カスタマイズすることが可能になります。LLM は事実に基づくナレッジをモデルのパラメータに保持することができ、ファインチューニングすると下流の NLP タスクで目覚ましいパフォーマンスを達成することができますが、クローズドドメインにアクセスして正確な予測を行う能力は、依然として制限されています。したがって、ナレッジの集約を行うタスクが与えられると、パフォーマンスはタスクに特化したアーキテクチャより劣ることとなります。OpenChatKit の検索システムを利用することで、Wikipedia、ドキュメントリポジトリ API、その他の情報ソースなどの外部ナレッジソースからの応答で、ナレッジを強化することができます。
拡張可能な検索システムでは、特定のクエリに応じて関連する詳細情報を取得することで、チャットボットが既存の情報にアクセスできるようになり、モデルが回答を生成するために必要なコンテキストを提供します。この検索システムの機能を説明するために、私たちは、Wikipedia 記事のインデックスの支援と、情報検索のために Web 検索 API を呼び出す方法として、サンプルコードを提供します。以下のドキュメントに従うことで、推論プロセスの中で任意のデータセットや API と検索システムを統合し、チャットボットが動的に更新されたデータを応答に組み込めるようになります。
モデレーションモデル
モデレーションモデルは、チャットボットアプリケーションにおいて、コンテンツフィルタリング、品質管理、ユーザーの安全性、法的およびコンプライアンスの理由を強化するために重要です。モデレーションは難しく主観的なタスクであり、チャットボットアプリケーションのドメインに大きく影響します。OpenChatKit は、チャットボットアプリケーションをモデレートし、不適切なコンテンツの入力テキストプロンプトを監視するツールを提供します。モデレーションモデルは、さまざまなニーズに適応およびカスタマイズできる最適なベースラインを提供します。
OpenChatKit には、60億のパラメータを持つモデレーションモデル、GPT-JT-Moderation-6B があり、チャットボットをモデレートし、モデレート対象への入力を制限することができます。モデル自体にはいくつかの組み込みのモデレーションがありますが、TogetherComputer は Ontocord.ai の OIG-moderation dataset を使用してGPT-JT-Moderation-6B モデルをトレーニングしました。このモデルは、メインのチャットボットと並行して実行され、ユーザーの入力とボットからの回答の両方に不適切な結果が含まれていないことを確認します。チャットボットのドメインの一部でない質問だった場合に、これを使用して、チャットボットへのドメイン外の質問を検出してオーバーライドすることもできます。
次のダイアグラムは OpenChatKit のワークフローを説明しています。
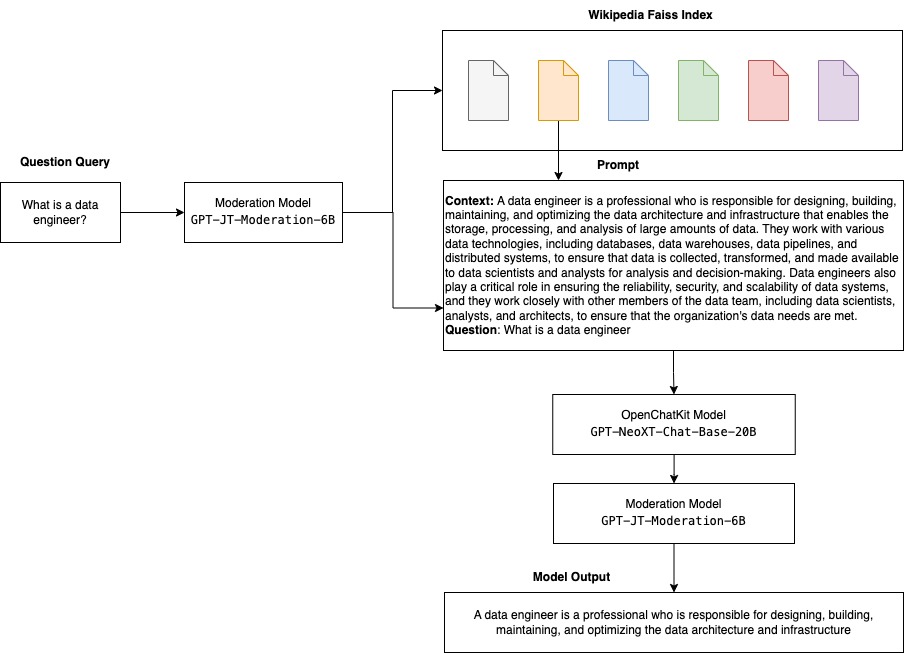
拡張可能な検索システムのユースケース
この手法はさまざまな業界に適用して生成系 AI アプリケーションを構築できますが、この投稿では、金融業界でのユースケースについて説明します。検索拡張された生成を金融調査で利用し、特定の企業、業界、金融商品に関する調査レポートを自動生成することができます。社内ナレッジベースや財務アーカイブ、ニュース記事、研究論文から関連情報を取得することで、主要な洞察、財務指標、市場動向、投資の推奨事項を要約した、包括的なレポートを生成できます。このソリューションを使用して、金融ニュース、市場センチメント、トレンドを監視および分析することが可能です。
ソリューション概要
次の手順で、OpenChatKit モデルを使用してチャットボットを構築し、SageMaker にデプロイします。
- チャットの元となる
GPT-NeoXT-Chat-Base-20Bモデルをダウンロードし、Amazon Simple Storage Service (Amazon S3) にアップロードするためにモデルアーティファクトをパッケージ化します。 - SageMaker の大規模モデル推論 (LMI) コンテナを使用し、プロパティを構成し、このモデルをデプロイするためにカスタム推論コードをセットアップします。
- モデル並列手法を構成し、DJLサービングプロパティで推論最適化ライブラリを使用します。Hugging Face Accelerate を DJLサービングのエンジンとして使用します。さらに、モデルを分割するためにテンソル並列構成を定義します。
- SageMaker モデルとエンドポイントコンフィグレーションを作成し、SageMaker エンドポイントをデプロイします。
GitHub リポジトリでノートブックを実行し、手順を進めることができます。
OpenChatKit モデルのダウンロード
初めに、OpenChatKit ベースモデルをダウンロードします。huggingface_hub と snapshot_downloadを使用して、モデルをダウンロードします。特定のリビジョンのリポジトリ全体をダウンロードします。プロセスを高速化するために、ダウンロードは同時に実行されます。次のコードを参照してください。
DJLサービングプロパティ
SageMaker LMI コンテナを使用して、独自の推論コードを提供しなくても、カスタム推論コードを使用して大規模な生成系AIモデルをホストすることができます。これは入力データのカスタム処理や、モデルの予測の後処理がない場合に、非常に役立ちます。また、カスタム推論コードを利用してモデルをデプロイすることも可能です。この投稿では、カスタム推論コードを使用して OpenChatKit モデルをデプロイする方法を示しています。
SageMakerではモデルアーティファクトがtarフォーマットであることが期待されます。ファイル serving.properties および model.py を使用して、各 OpenChatKit モデルを作成します。
serving.properties 構成ファイルは、どのモデル並列化や推論最適化ライブラリを使用するかを、DJLサービングに示します。以下は、この構成ファイルの中で使用する設定のリストです。
- engine – DJL を使うためのエンジン。
- option.entryPoint – Python ファイルやモジュールのエンドポイント。これは使用するエンジンに従う必要があります。
- option.s3url – モデルのある S3 バケットの URI を指定します。
- option.modelid – もし huggingface.co からモデルをダウンロードしたい場合は、
option.modelidを、huggingface.coのモデルリポジトリ内でホストされている、事前トレーニング済みモデルのモデル ID に設定できます。コンテナはこのモデル ID を使用して、huggingface.co で対応するモデルリポジトリをダウンロードします。 - option.tensor_parallel_degree – DeepSpeed がモデルを分割する必要がある GPU デバイスの数を設定します。このパラメータは、DJLサービングの実行時に起動されるモデルごとのワーカーの数も制御します。例えば、もし 8 GPU のマシンがあり、8つのパーティションを作成している場合、モデルごとにリクエストに対応する一つのワーカーを用意します。並列度を調節し、特定のモデルアーキテクチャとハードウェアプラットフォームの最適値を特定する必要があります。これを「推論適応型並列処理 (inference-adapted parallelism)」と呼びます。
完全なオプションのリストは Configurations and settings を参照してください。
OpenChatKit モデル
OpenChatKit ベースモデルの実装には以下の4つのファイルが必要です。:
- model.py – このファイルは主となる OpenChatKit GPT-NeoX モデルの処理ロジックを実装します。推論入力リクエストを受信し、モデルをロードし、Wikipedia のインデックスをロードし、レスポンスを提供します。追加の詳細は、
model.py( notebook の一部として作成されたもの)を参照してください。model.pyは、次のキークラスを利用します。:- OpenChatKitService – これは、GPT-NeoX モデル、Faiss による検索、および会話オブジェクト間のデータの受け渡しを処理します。
WikipediaIndexとConversationオブジェクトが初期化され、入力されたチャットの会話がインデックスへ送信され、WIkipediaから関連コンテンツを検索します。また、Amazon DynamoDBにプロンプトを保存する目的で一意のIDが指定されていない場合に、呼び出しごとに一意のIDを生成します。 - ChatModel – このクラスはモデルとトークナイザーをロードし、応答を生成します。
tensor_parallel_degreeを使用する複数のGPUを跨いだモデルの分割を処理し、dtypesとdevice_mapを設定します。このプロンプトはモデルに渡され、応答が生成されます。停止の基準であるStopWordsCriteriaは、推論のボット応答のみを生成するために構成されています。 - ModerationModel –
ModerationModelクラスでは、2つのモデレーションモデルを利用します。入力モデルは、入力が不適切であることをチャットモデルに示して、推論結果をオーバーライドできるようにします。出力モデルは、推論結果をオーバーライドします。入力プロンプトと出力応答を、次の可能なラベルで分類します。- casual
- needs caution
- needs intervention (モデルによってモデレートされるようにフラグが立てられます)
- possibly needs caution
- probably needs caution
- OpenChatKitService – これは、GPT-NeoX モデル、Faiss による検索、および会話オブジェクト間のデータの受け渡しを処理します。
- wikipedia_prepare.py – このファイルは、Wikipedia インデックスをダウンロードして準備する処理を行います。この投稿では、Hugging Face データセットで提供されている WIkipedia インデックスを使用します。関連するテキストをWikipediaドキュメントで検索するためには、他にインデックスがパッケージ化されていないため、Hugging Faceからダウンロードする必要があります。
wikipedia_prepare.pyファイルはインポート時のダウンロード処理を担当します。推論のために実行されている複数のプロセスのうち1つのプロセスだけが、リポジトリのクローンを作成可能です。残りは、ローカルファイルシステムにファイルが存在するようになるまで待機します。 - wikipedia.py – このファイルは、コンテキストが関連するドキュメントを Wikipedia インデックスから検索します。入力クエリをトークン化し、
mean_poolingを利用して埋め込みを作成します。クエリの埋め込みと Wikipedia インデックスとをコサイン類似度距離メトリクスで計算し、コンテキストが関連する Wikipedia 文を取得します。実装の詳細については、wikipedia.pyを参照してください。
- conversation.py – このファイルは、DynamoDB に会話スレッドを保存および取得し、モデルとユーザーへ渡すために使用されます。
conversation.pyは、オープンソースの OpenChatKit リポジトリから採用されています。このファイルでは、人とモデル間を行き交う会話を保管するオブジェクトを定義します。これによりモデルは会話のセッションを保持できるようになり、ユーザーは過去のメッセージを参照できるようになります。SageMaker エンドポイント呼び出しはステートレスなので、会話をエンドポイントインスタンス外の場所に保存する必要があります。DynamoDB テーブルが存在しない場合は、インスタンス起動時に DynamoDB テーブルを作成します。会話に対するすべての更新は、エンドポイントによって生成されたsession_idキーに基づいて DynamoDB に保存されます。セッション ID を使用した呼び出しは、関連する会話の文字列を取得し、必要に応じて更新します。
カスタム依存関係を使用したLMI推論コンテナの構築
インデックス検索は、類似検索を実行するための Facebook の Faiss ライブラリを使用します。ベースの LMI イメージに含まれないため、コンテナはそのライブラリをインストールして適用させる必要があります。次のコードは、ボットのエンドポイントに必要な他のライブラリとともに、ソースから Faiss をインストールする Dockerfile を定義しています。sm-docker ユーティリティを使用し、Amazon SageMaker Studio から Amazon Elastic Container Registry (Amazon ECR) へイメージを構築してプッシュします。詳細は Using the Amazon SageMaker Studio Image Build CLI to build container images from your Studio notebooks をご参照ください。
DLJコンテナには、Conda がインストールされていません。従って、Faiss をソースからクローンしてコンパイルする必要があります。Faiss をインストールするには、BLAS API を使用するための依存関係と Python サポートをインストールする必要があります。これらのパッケージがインストールされると、Faiss はインストールされた Python 拡張機能を使用してコンパイルされる前に、AVX2 と CUDA を利用するように構成されます。
pandas、 fastparquet、 boto3、 git-lfs は、インデックスファイルのダウンロードと読み取りに必要なため、後でインストールされます。
モデルの作成
Amazon ECRにDockerイメージができたので、OpenChatKit モデルの SageMaker モデルオブジェクトの作成に進むことができます。GPT-NeoXT-Chat-Base-20B 入力をデプロイし、GPT-JT-Moderation-6B を使用したモデレーションモデルを出力します。詳細は create_model を参照してください。
エンドポイントの構成
次に、OpenChatKit モデルのエンドポイントの構成を定義します。ml.g5.12xlarge のインスタンスタイプを使用して、モデルをデプロイします。詳細は create_endpoint_config をご参照ください。
エンドポイントのデプロイ
最後に、モデルと前の手順で定義したエンドポイントの構成を使用して、エンドポイントを作成します。
OpenChatKit モデルから推論を実行
推論リクエストをモデルに送信し、応答を取得してみましょう。入力テキストプロンプトと、temperature、 top_kや max_new_tokens のようなモデルパラメータを受け渡します。チャットボット応答の品質は、指定したパラメータに基づくため、ユースケースに沿った最適なパラメータの設定を見つけるために、パラメータを利用したモデルパフォーマンスのベンチマークをお勧めします。インプットプロンプトは最初に入力モデレーションモデルに送信され、出力は応答を生成するために ChatModel へ送られます。この手順の中で、モデルは Wikipedia インデックスを使用し、モデルからドメイン固有の応答を取得するためのプロンプトとして使用するための、コンテキストが関連するセクションを取得します。最後に、モデルの応答は分類を確認するために出力モデレーションモデルに送られ、応答が返送されます。次のコードをご覧ください。
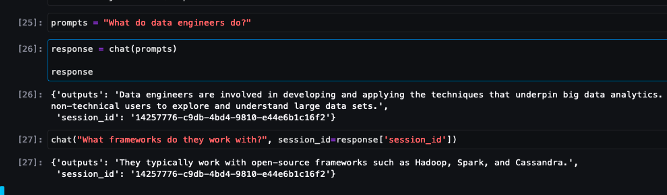
次のチャット対話のサンプルをご覧ください。
クリーンアップ
不要な料金が発生しないように、この投稿の中でプロビジョニングされたリソースを削除します。推論インスタンスのコストの詳細については、 Amazon SageMaker Pricing を参照してください。
結論
この投稿では、オープンソースのLLMの重要性と、次世代チャットボットアプリケーションを構築するためのOpenChatKit モデルを SageMaker へデプロイする方法について議論しました。さまざまな OpenChatKit モデルの要素や、モデレーションモデル、また、retrieval augmented generation (RAG) ワークフローで Wikipedia のような外部のナレッジソースを使用する方法についても議論しました。GitHub notebookでは、ステップバイステップの説明を見つけることができます。あなたが構築している素晴らしいチャットボットアプリケーションについてお知らせください。ではまた!
本記事は、Build custom chatbot applications using OpenChatkit models on Amazon SageMaker を翻訳したものです。
翻訳はソリューションアーキテクトの加藤 菜々美が担当しました。
著者について

Dhawal Patel は、AWS のプリンシパル マシンラーニング アーキテクトです。大企業から中規模の新興企業まで、分散コンピューティングや人工知能に関する問題についてさまざまな組織と協力してきました。彼は、NLP やコンピューター ビジョン ドメインを含むディープ ラーニングに焦点を当て、お客様が SageMaker で高パフォーマンスのモデル推論を実現できるよう支援しています。

Vikram Elango は、米国バージニア州に拠点を置く AWS のシニア AIML スペシャリスト ソリューション アーキテクトです。彼は現在、生成 AI、LLM、プロンプト エンジニアリング、大規模モデル推論の最適化、企業全体にわたる ML のスケーリングに重点を置いています。 Vikram は、設計とソート リーダーシップにより、金融および保険業界のお客様が機械学習アプリケーションを大規模に構築および展開できるよう支援します。余暇では、家族と一緒に旅行、ハイキング、料理、キャンプを楽しんでいます。

Andrew Smith は、オーストラリアのシドニーを拠点とする AWS の SageMaker、Vision & Other チームのクラウド サポート エンジニアです。彼は、Amazon SageMaker との連携に関する専門知識を備え、AWS で多くの AI/ML サービスを使用する顧客をサポートしています。仕事以外では、友人や家族と時間を過ごしたり、さまざまなテクノロジーについて学ぶことを楽しんでいます。