Amazon Web Services ブログ
Amazon Rekognition と Amazon Athena を使用してソーシャルメディア上の画像を探る
たいていの企業と同様であれば、お客様とブランドイメージをよりよく理解したいと考えておられるでしょう。マーケティングキャンペーンの成功と、お客様が関心を持っているトピック、あるいは不満を感じているトピックを追跡したいと考えておられるでしょう。ソーシャルメディアはこの種の情報の豊富な情報源になると期待されており、多くの企業が Twitter などのプラットフォームから情報を収集、集約、分析し始めています。
ただし、ソーシャルメディアでの会話の中心は画像と動画です。ある最近のプロジェクトでは、収集されたすべてのツイートの約 30% に 1 つ以上の画像が含まれていました。こうした画像には、分析なしでは簡単にアクセスできない関連情報が含まれています。
| このブログ記事について | |
| 完了するまでの時間 | 1 時間
|
| 完了するためのコスト | ~ 5 USD (公開時、使用する条件による)
|
| 学習レベル | 中級 (200) |
| AWS のサービス | Amazon Rekognition
Amazon Athena Amazon Kinesis Data Firehose Amazon S3 AWS Lambda |
ソリューションの概要
次の図は、ソリューションコンポーネントと、画像や抽出データがコンポーネントの間をどのように流れるかを示しています。

これらのコンポーネントは、AWS CloudFormation テンプレートを介して利用できます。
- Twitter Search API はツイートを収集します。
- Amazon Kinesis Data Firehose は、ツイートを送信して、Amazon S3 に保存します。
- 指定されたバケットフォルダーで S3 オブジェクトが作成されると、Lambda 関数がトリガーされます。
- Lambda は、各ツイートテキストを Amazon Comprehend に送信して、感情 (ポジティブまたはネガティブ)、エンティティ (人、場所、商品などの現実世界のオブジェクト) を検出し、日付や数量などの正確な値を把握します。詳細については、Amazon Comprehend 開発者ガイドの DetectSentiment および DetectEntity を参照してください。
- Lambda は、ツイートの
extended_entitiesにあるタイプ「photo」のメディアの各ツイートをチェックします。写真の拡張子が .JPG または .PNG の場合、Lambda は各画像に対して次の Amazon Rekognition API を呼び出します。Detect_labels画像内のPerson、Pedestrian、Vehicle、Carなどのオブジェクトを識別します。Detect_moderation_labels画像や保存された動画に、露骨なアダルトコンテンツや暴力的なコンテンツなどの安全でないコンテンツが含まれているかどうかを判断します。detect_labelsAPI がTextラベルを返すと、detect_textは画像内で見つかった行、単語、文字を抽出します。detect_labelsAPI がPersonラベルを返すと、Lambda は以下を呼び出します。detect_faces顔を検出し、サングラス、あごひげ、口ひげなどの特徴を分析します。recognize_celebritiesさまざまな設定、化粧品によるメイク、その他の条件で、できるだけ多くの有名人を検出します。
単一の画像に対するすべての呼び出しの結果が、単一の JSON レコードに結合されます。これらの API の詳細については、Amazon Rekognition 開発者ガイドの Actions を参照してください。
- Lambda の結果は Kinesis Data Firehose に移動します。Kinesis Data Firehose はレコードをバッチ処理し、指定された S3 バケットおよびフォルダに書き込みます。
- Amazon Athena を使用して、S3 データセットでテーブルとビューを構築し、AWS Glue データカタログでこれらの定義をカタログ化することができます。テーブルとビューの定義により、これらの S3 データセットに含まれる複雑な JSON オブジェクトに対するクエリがはるかに簡単になります。
- 処理されたツイートが S3 に到着すると、Athena でデータを照会できます。
- Amazon QuickSight を使用してデータを視覚化することもできますし、Amazon SageMaker または Amazon EMR を使用してデータをさらに処理することもできます。詳細は、 機械学習と BI サービスを使用してソーシャルメディアダッシュボードを構築するを参照してください。この記事では Athena を使用しています。
前提条件
このウォークスルーには、次の前提条件があります。
- AWS アカウント。
- Twitter のアプリ。アプリを作成するには、Twitter 開発ウェブサイトのアプリセクションを参照してください。
- コンシューマキー (API キー)、コンシューマシークレットキー (API シークレット)、アクセストークン、アクセストークンシークレットを作成します。このソリューションは、AWS CloudFormation スタックのパラメータとしてそれらを使用します。
ウォークスルー
このブログ記事では、以下の内容について順を追って説明します。
- 提供された AWS CloudFormation テンプレートを起動し、ツイートを収集する。
- スタックが S3 でデータセットを作成したことを確認する。
- Athena を使用してデータセットのビューを作成する。
- データを調べる。
S3 は、未加工のツイートと Amazon Comprehend および Amazon Rekognition の出力を JSON 形式で保存します。Athena のテーブルとビューの定義を使用して、生成された複雑な JSON をフラット化し、目的のフィールドを抽出することができます。このアプローチによって、データへのアクセスと理解が容易になります。
AWS CloudFormation テンプレートの起動
この記事では、Lambda への S3 通知 (図の青い点線) を除いて、前の図に表示されるすべての取り込みコンポーネントを作成する AWS CloudFormation テンプレートを提供します。
- AWS マネジメントコンソールで、AWS CloudFormation テンプレートを起動します。

これにより、AWS CloudFormation スタックが自動的に
us-east-1リージョンに起動します。 - 機械学習と BI サービスを使用してソーシャルメディアダッシュボードを構築するの記事の「このアーキテクチャを自分で構築する」のセクションで概説された手順に、以下の変更を加えて実行します。
- この記事の Launch Stack リンクを使用します。
- AWS Glue データベース socialanalyticsblog が既に存在する場合 (たとえば、前の記事からウォークスルーを完了した場合)、AWS CloudFormation スタックの起動時にデータベースの名前を変更し、このソリューションの残りの部分で新しいデータベース名を使用します。
- Twitter の言語については、「en」 (英語) だけを使用してください。この記事では、シンプルさとコスト削減のために Amazon Comprehend Translate 機能は削除しています。
- 「S3 通知を設定する – 新しいツイートから Amazon Translate と Amazon Comprehend を呼び出す」のセクションは省略します。 これは、「Add Trigger」Lambda 関数によって AWS CloudFormation スタックを起動するときに自動的に発生します。
- 「Athena テーブルの作成」セクションで停止し、代わりにこの記事の以下の指示を実行してください。
Twitter ストリーミング API から取得する用語を変更して、会社や顧客に関連する用語にすることができます。この記事では、Amazon 関連のいくつかの用語を使用しました。
この実装は、ツイートごとに 2 回の Amazon Comprehend 呼び出しと最大 5 回の Amazon Rekognition 呼び出しを行います。この実装を実行するコストは、収集するツイートの数に正比例します。効率とコスト管理のために、1 秒間に数十または数百のツイートを取得できるように用語を変更する場合は、バッチ呼び出しを実行するか、トリガーによって AWS Glue を使用してバッチ処理とストリーム処理を実行することを検討してください。
S3 ファイルの確認
スタックが約 5 分間実行された後、AWS CloudFormation テンプレートが作成した S3 バケット (rTweetsBucket) にデータセットが表示され始めます。各データセットは、S3 の個別のディレクトリにある以下のファイルとして表されます。
- Raw – Twitter から受け取った未加工のツイート。
- Media – Amazon Rekognition API 呼び出しからの出力。
- Entities – Amazon Comprehend エンティティ分析の結果。
- Sentiment – Amazon Comprehend センチメント分析の結果。
ディレクトリの次のスクリーンショットを参照してください。
エンティティおよびセンチメントのテーブルについては、機械学習と BI サービスを使用してソーシャルメディアダッシュボードを構築するを参照してください。
調査するのに十分なデータがある場合 (選択した用語の人気度と画像がある頻度に依存)、Twitter ストリームプロデューサーを停止し、Amazon EC2 インスタンスを停止または終了できます。これにより、Amazon Comprehend、Amazon Rekognition、EC2 による請求が停止します。
Athena ビューの作成
次の手順は、Athena データベースとテーブルを手動で作成することです。詳細については、Athena ユーザーガイドの開始方法を参照してください。
これは、データレイクアーキテクチャで AWS Glue クロール機能を使用するのに最適な場所です。クローラーは、S3 に存在するさまざまなデータセット (およびリレーショナルデータベースとデータウェアハウス) のデータ形式とデータ型を自動的に検出します。詳細については、クローラーの定義を参照してください。
- Athena コンソールの [Query Editor] で、ファイル sql にアクセスします。AWS CloudFormation スタックが、データベースとテーブルを自動的に作成しました。
view createステートメントを Athena クエリエディターに 1 つずつ読み込み、実行します。この手順により、テーブルのビューが作成されます。
前の記事と比較して、media_rekognition テーブルとビューは新しいものです。ツイートテーブルには、画像と動画のメタデータ用の新しい extended_entities 列があります。他のテーブルの定義は同じままです。
Athena データベースは、次のスクリーンショットのようになります。S3 の各データセットに 1 つずつ、合計 4 つのテーブルがあります。media_rekognition テーブルの詳細を組み合わせて公開する 3 つのビューもあります。
recognize_celebritiesAPI の結果に焦点を当てているCeleb_viewdetect_labelsAPI の結果に焦点を当てているMedia_image_labels_querydetect_facesAPI の結果に焦点を当てているMedia_image_labels_face_query

テーブルとビューの定義を調べます。JSON オブジェクトは複雑であり、これらの定義は、ネストされたオブジェクトや複雑なタイプの配列を照会するためのさまざまな使用方法を示しています。基礎となる JSON の複雑さをカプセル化する基礎となるテーブルとビューの定義のおかげで、クエリの多くは比較的単純になりました。詳細については、複合型およびネストされた構造を持つ配列の照会を参照してください。
結果を調べる
このセクションでは、このデータの 3 つの使用例について説明し、同様のデータを抽出する SQL を提示します。実際の検索用語と期間はこの記事のものとは異なるため、結果は異なるでしょう。この記事では、Amazon 関連の用語のセットを使用しました。ツイートコレクターは約 6 週間実行され、約 950 万のツイートを収集しました。ツイートには、約 50 万枚の写真があり、ツイート全体の約 5% でした。この数は、ツイートの約 30% に写真が含まれていた、他のビジネス関連の検索用語セットと比較して低いものでした。
この記事では、4 つの画像のユースケースについてレビューします。
- バズ
- ラベルおよび顔
- 疑わしいコンテンツ
- 有名人の探索
バズ
ツイートに関連付けられたリンクで表される主要なトピック領域は、自然言語処理によって表面化されたツイート言語のコンテンツのトピックを補完することがよくあります。詳細は、 機械学習と BI サービスを使用してソーシャルメディアダッシュボードを構築するを参照してください。
最初のクエリは、ツイートがリンクされているウェブサイトです。以下のコードは、ツイートからリンクされた上位のドメイン名を示しています。
次のスクリーンショットは、返された上位 10 のドメインを示しています。

Amazon ウェブサイトへのリンクが頻繁にあり、amazon.com、amazon.co.uk、goodreads.com など、いくつかの異なるプロパティに名前が付けられています。
さらに調べると、これらのリンクの多くは Amazon ウェブサイトの製品ページへのリンクであることがわかります。リンクに /dp/ (詳細ページ) があるため、これらのリンクを簡単に認識できます。次のクエリを使用すると、これらのリンク、含まれている画像、画像内のテキストの最初の行 (存在する場合) のリストを取得できます。
次のスクリーンショットは、このクエリによって返されるレコードの一部を示しています。first_line 列には、media_url 列の画像 URL に対して detect_text API によって返された結果が表示されます。
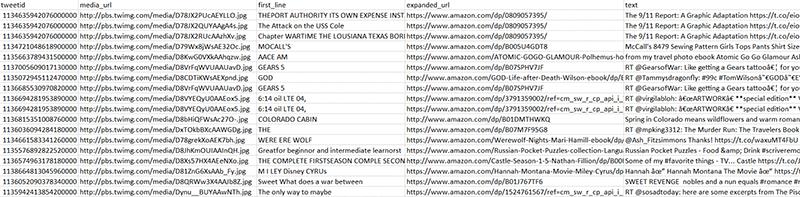
多くの画像に、テキストが含まれています。また、ツイートがリンクされている製品を特定することもできます。 ツイートの多くは売り手による製品広告であり、製品に直接関連する画像を使用しているからです。
ラベルおよび顔
また、Amazon Rekognition detect_labels API を呼び出した結果を見ると、画像の視覚的な内容を把握できます。次のクエリは、写真で見つかる最も一般的なオブジェクトを見つけます。
次のスクリーンショットは、そのリクエストの結果を示しています。最も人気があるラベルは Human または Person であり、Text、Advertisement、Poster が続いて登場します。Novel はリストのさらに下にあります。この結果は、Amazon ウェブサイトについてツイートされている最も人気がある製品が、書籍であることを反映しています。

detect_faces API の結果を見ることで、さらに顔について調べるできます。API は、性別、年齢層、顔の位置、人がサングラスをかけているか口ひげを生やしているか、顔の表情など、画像内のそれぞれの顔の詳細を返します。また、こうした特徴のそれぞれには、信頼レベルも関連付けられています。詳細については、Amazon Rekognition 開発者ガイドの DetectFaces を参照してください。
media_image_labels_face_query ビューは、API 呼び出しによって返された複雑な JSON オブジェクトからこうした特徴の多くをネスト解除し、フィールドが容易にアクセスできるようにします。
Amazon Rekognition が最高の信頼スコアを付けて表現カテゴリを特定して返し、それに top_emotion という名前を付けた、(emotion,confidence) ペアの配列での reduce 演算子の使用を含めて、media_image_labels_face_query のビュー定義を調べることができます。次のコードをご覧ください。
その後、公開フィールド top_emotion を使用することができます。次のコードをご覧ください。
次のスクリーンショットは、メガネ、年齢層、この顔の端が配置されている場所など、この広範なクエリの中央からの列を示しています。この最後の詳細は、単一の画像に複数の顔が存在する場合に、顔を区別するのに役立ちます。

次のコードを使用して、これらの顔で見つかる上位の表現を確認できます。
次のクエリ結果のスクリーンショットは、CALM が明確にトップであり、次に HAPPY が続くことを示しています。奇妙なことに、うんざりした表現よりも混乱の表現がはるかに少ないです。

疑わしいコンテンツ
頻繁に懸念されるトピックは、ツイートあるいは関連する画像に管理する必要があるコンテンツが含まれているかということです。各画像に対して Lambda によって呼び出される Amazon Rekognition API の 1 つは moderation_labels です。これは、見つかったコンテンツのカテゴリを示すラベル (存在する場合) を返します。詳細については、安全でないコンテンツの検出を参照してください。
次のコードは、疑わしい画像を含むツイートを検索します。Twitter は、ツイートテキストだけに基づいて、possibly_sensitive フラグも提供します。
次のスクリーンショットは、最初のいくつかの結果を示しています。これらのエントリの多くには、ツイートテキストまたは画像に注意を要するコンテンツが含まれている場合がありますが、必ずしも両方に含まれているとは限りません。両方の基準を含めると、安全性が高まります。

Amazon Rekognition が返したモデレーションラベルの JSON 配列にマッピングするための上記のクエリでの transform 構造の使用に注意してください。この構造を使用すると、moderationlabels オブジェクトの元のコンテンツ (次の配列内) を名前フィールドだけを含むリストに変換できます。
特定のモデレーションラベルでフィルタリングすることにより、このクエリをフィルタリングして、特定の種類の安全でないコンテンツに焦点を合わせることができます。詳細については、安全でないコンテンツの検出を参照してください。
こうしたツイートの多くには、URL に製品リンクが埋め込まれています。Amazon.com ウェブサイトの URL にはパターンがあります: /dp/ を含む URL は、製品ページへのリンクです。これを使用して、明示的なコンテンツが関連付けられている可能性のある製品を特定することができます。
有名人の探索
Lambda が各画像に対して呼び出した Amazon Rekognition API の 1 つは、recognize_celebrity でした。詳細については、画像内の有名人の認識を参照してください。
以下のコードは、どの有名人がデータセットで最も頻繁に表示されるかを判断するのに役立ちます。
結果は、有名人のインスタンスの認識をカウントし、複数の有名人がいる画像を複数回カウントします。
たとえば、JohnDoe というラベルの有名人がいるとします。画像をさらに調べるには、次のクエリを使用します。このクエリは、JohnDoe がテキストまたは画像に表示されたツイートに関連する画像を検索します。
recognize_celebrity API は、各画像を最も近い外観の有名人に一致させます。その有名人の名前と関連情報を、信頼スコアとともに返します。時には、結果が誤解を招く可能性があります。たとえば、顔が背を向けている場合や、サングラスをかけている場合など、正しく識別するのが難しくなります。他の例では、有名人との類似性のために、API が画像モデルを選択する場合があります。このクエリと face_details 応答を使用するロジックを組み合わせて、メガネや顔の位置を確認すると便利な場合があります。
クリーンアップ
以後の請求が発生しないように、AWS CloudFormation スタック、作成した S3 バケットのコンテンツを削除します。
まとめ
この記事では、画像を使用してソーシャルメディアで顧客があなたについて何を言っているのかを調べ始める方法を示しました。この記事にあるクエリは、可能なことのほんの始まりにすぎません。顧客が行っている会話の全体をよりよく理解するために、この記事の機能を、ツイートに対して自然言語処理を実行した結果と組み合わせることができます。
Kinesis Data Firehose から開始し、Amazon Comprehend を使用してセンチメント分析を実行し、Amazon Rekognition を使用して写真を分析し、Athena を使用してデータを照会するこの処理、分析、および機械学習のパイプライン全体は、サーバーを起動することなく可能です。
この記事では、Lambda 内のいくつかの単純な呼び出しを通じて、高度な機械学習 (ML) サービスを Twitter 収集パイプラインに追加しました。また、このソリューションはすべてのデータを S3 に保存し、いくつかのエレガントな SQL 構造を使用して複雑な JSON オブジェクトを照会する方法も示しました。Amazon EMR、Amazon SageMaker、Amazon ES、またはその他の AWS のサービスを使用して、データをさらに分析することができます。制限するものは、あなたの想像力だけです。
著者について
 Veronika Megler 博士は、AWS プロフェッショナルサービスのデータサイエンス、ビッグデータおよびアナリティクス担当の主任コンサルタントです。彼女は、科学的データ検索をテーマとして、コンピュータサイエンスの博士号を取得しています。技術採択を専門とし、企業が新しい技術を使って新しい問題を解決し、古い問題をより効率的かつ効果的に解決できるように支援しています。
Veronika Megler 博士は、AWS プロフェッショナルサービスのデータサイエンス、ビッグデータおよびアナリティクス担当の主任コンサルタントです。彼女は、科学的データ検索をテーマとして、コンピュータサイエンスの博士号を取得しています。技術採択を専門とし、企業が新しい技術を使って新しい問題を解決し、古い問題をより効率的かつ効果的に解決できるように支援しています。
 Chris Ghyzel は、AWS プロフェッショナルサービスのデータエンジニアです。現在、彼は顧客と協力して、AWS の機械学習ソリューションを生産パイプラインに統合しています。
Chris Ghyzel は、AWS プロフェッショナルサービスのデータエンジニアです。現在、彼は顧客と協力して、AWS の機械学習ソリューションを生産パイプラインに統合しています。