Amazon Web Services ブログ
VMware Cloud on AWSデータストアのAWS Analyticsサービスとの統合方法
AWSでSpecialist Solutions Architectを務めるBalakrishnan NairとPartner Solutions Architectを務めるKiran Reidによる記事です。
オンプレミスでVMwareを稼働させているお客様は、 VMware Cloud on AWSをハイブリッドクラウド戦略に取り入れることでAWSグローバルインフラストラクチャを使えるという非常に大きなメリットを得ようとしています。
VMware Cloud on AWSをハイブリッドクラウド戦略に取り入れることでAWSグローバルインフラストラクチャを使えるという非常に大きなメリットを得ようとしています。
一方で、AWS Analyticsサービスはお客様のエンタープライズデータベース、データレイク、ログファイルレポジトリにあるデータからビジネス価値を創出する手段を提供します。
データ分析ソリューションの主な流れは以下です。
- ソースから未整形の状態のデータを取り出します。これはテキスト、数値、ビデオファイルなどです。
- データを整形しデータベースやデータレイクなどのストレージソリューションに格納します。
- 分析、洞察のために収集、ノイズ除去されたデータを可視化します。
お客様のデータセンターではファイルサーバー、FTPサーバー、データベース、ログなどの様々な異なるソースやアプリケーションからデータが生成され、なおかつこれらはビジネスにとって極めて重要なデータを含みます。
有用なデータの管理と抽出はお客様にアドバンテージをもたらし、また遵守しなければならない特定の企業コンプライアンス要件にも合致する可能性があります。
VMware Cloud on AWSへ移行中のお客様の中には、非構造化データを含むファイルシステムを扱うワークロードの移行を考えている方もおられるかもしれません。これらのファイルシステムは有用なビジネスデータを生み出す貴重なソースとなり得ますが、データセットからどうやって意義のある洞察を得るかを決めづらくする原因ともなり得ます。
本稿ではVMware Cloud on AWSがどのようにこういったデータセットをAWS Analyticsサービスの近くに配置し、これらのサービスを利用してより容易にビジネスデータから有用な洞察を引き出せるかをガイドします。
構成
以下の図1に示すように、VMware Software Defined Data Center (SDDC)が左側にあり、お客様のフロントエンドの仮想マシンとともにMySQLデータベースの仮想マシンがホストされています。
右側はお客様のAWSアカウントで、分析に使われるAWSネイティブなサービスがホストされています。

図1: ENIを介したVMware Cloud on AWSとAWSの統合
データ分析ソリューションを設計する際には、データ量、ファイルシステムに入る、もしくはファイルシステムを通る各データフローのスピード、そしてデータが有効で改竄されていないことを保証するために異なる種々のデータフォーマットを意識しなくてはいけません。
VMware Cloud on AWSを利用することでお客様のワークロードをネイティブのAWSサービスのすぐ隣に配置することができます。これによりElastic Network Interface (ENI)を通じてネイティブのAWSサービスから直接アクセスすることができます。
ENIは25Gbpsの広帯域でプライベートな専用接続であり、全ての分析サービスはお客様のVirtual Private Cloud (VPC)内で実行されます。ENI接続によってこれら2つの環境が繋がり、お客様のデータセンターにデータベースを持つ場合に比べてより早くデータを処理できるようになります。
以下の例では、VMware Cloud on AWS環境のVMで稼働するMySQLデータベースで分析を実行しています。データベースにはCOVID-19ワクチンに関するデータや、世界各国で実施されたワクチン接種に関するデータが含まれています。
このデータに関する洞察を得るため、以下の図のようにAWS Analyticsサービスを利用します。

図2: 分析サービスコンポーネントとプロセス
これにより「ワクチン種別ごとの1日あたりのワクチン接種実施回数は?」といった単純な質問に、複雑なSQLクエリを書くことなく答えられるようになります。
図2に示したように、AWS Glueクローラを作成してVMware Cloud on AWS上のMySQLインスタンスからデータを取り出し、AWS GlueデータカタログとAmazon Simple Storage Service (Amazon S3)バケットに格納します。
次にAWS Glueの抽出、変換、ロード (ETL)ジョブを実行して、Amazon AthenaやAmazon QuickSightでの分析に適したデータ形式であるParquet形式にデータを変換しS3に保存します。
設定
分析の設定と実行のワークフローは以下の2つのパートから成ります。
- MySQLデータベースでETLジョブを実行し、出力結果をS3バケットに格納するようAWS Glueを設定する。
- S3のデータに対してAmazon Athenaのクエリを実行し、その結果をQuickSightで可視化する。
AWS Glueの設定を始める前に、まずデータベースの乗っている仮想マシンがAWSからアクセス可能であることを確認しておく必要があります。そのためにはデータベースエンドポイント、認証情報、必要なセキュリティグループが適切な権限で設定されていなければなりません。
最小権限モデルでAWSセキュリティグループを利用する際には、こちらの推奨事項に従います。このセキュリティグループは接続先のVPCのENIに適用され、全ての分析サービスが接続を確立するために使うことになります。
パート1: JDBC接続を利用したAWS GlueでのETL処理
まず初めにソースデータ(VMware Cloud on AWS MySQL)をサンプリングし、AWS Glueデータカタログにメタデータを構築するためのクローラ(bncrawler-01)を作成します。
以下はAWS Glueのウィザードに従って入力した最初のcrawler-01の設定詳細です。

図3: crawler-01設定詳細
ソースデータに接続するにはJDBC接続が必要となります。JDBC接続を確立するためには、JDBC URL (VMware Cloud on AWS MySQL仮想マシンのIPアドレス)、データベースの認証情報、データベース名が必要です。
設定が完了したらRun Crawlerをクリックし、AWS Glueデータカタログ内にメタデータを作成します。Tablesをクリックして前のステップで新規に作成されたテーブルが反映されていることを確認してください。
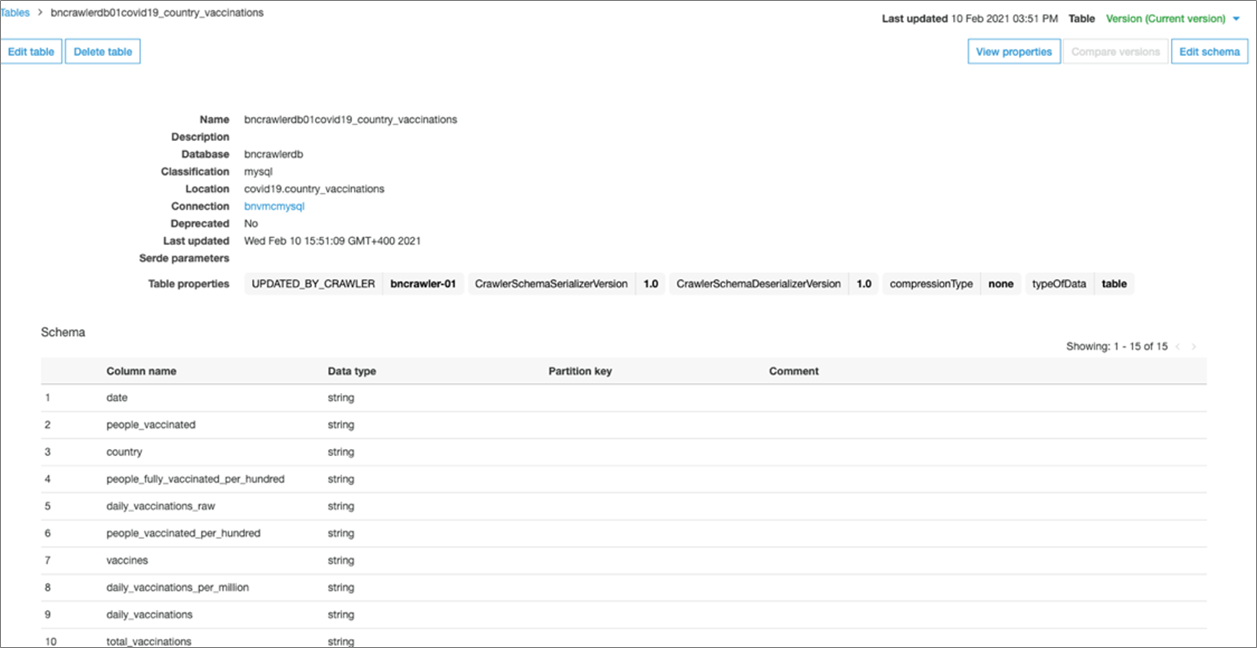
図4: AWS Glueデータカタログの確認
MySQLデータベースのテーブルに存在するものと同じカラムがカタログにも反映されているはずです。
次に、データをVMware Cloud on AWS MySQLからParquet形式でS3バケットへ移すためのETLジョブを作成します。より詳細な情報はこちらのドキュメントをご参照ください。
Jobs > Add Jobの順にクリックし、ウィザードに従ってください。次にETLスクリプトのためのAWS Identity and Access Management (IAM) roleとS3 bucket locationsを選択してください。もしS3バケットが存在しない場合は作成することができます。
次のページではAWS Glueデータカタログから、VMware Cloud on AWS MySQLデータカタログテーブルをポイントしているデータソースであるVMC MySQLを選択します。
続いてCreate tables in your data targetを選択し、Data storeとしてAmazon S3を選択します。FormatはParquetを選び、Target pathはS3バケットのprefixを入力します。
transform data typeにてChange Schemaを選択します。Data type (S3)、Format (Parquet)、Connection (S3 network connection)、Target path (S3 bucket)をそれぞれ設定します。

図5: FormatとConnection Typeの選択
次にAWS Glueで作成されたマッピングを検証します。Map to target列で他のカラムを選択し、マッピングを変更できます。Clearで全てのマッピングを削除したり、Resetで最初のAWS Glueマッピングの状態に戻すこともできます。マッピングが決定するとAWS Glueはスクリプトを作成します。
Nextをクリックし、スクリプトと実行順序を確認したらRun Jobをクリックします。
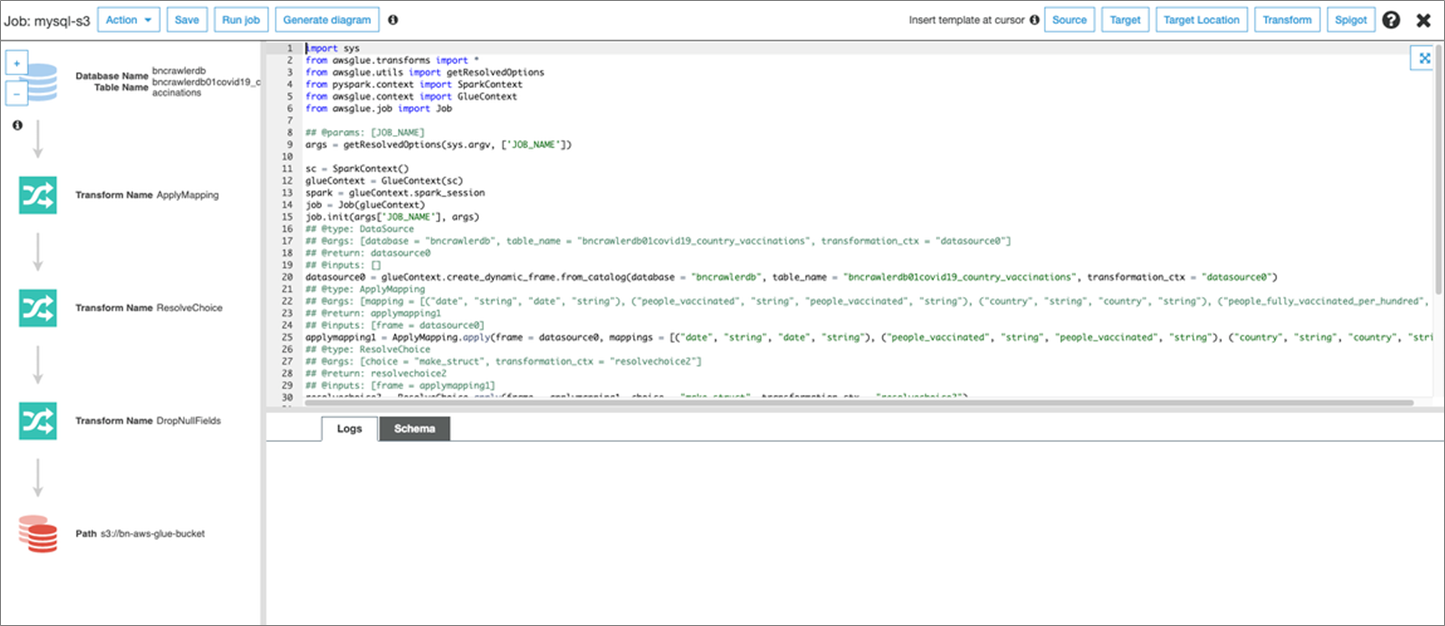
図6: プロセスの確認
ジョブ実行が完了すると、変換されたデータが利用可能な状態でS3バケットに保存され、データレイクとして利用できます。データは既にAmazon AthenaやAmazon QuickSightなどの他のサービスから分析のために利用可能な状態となっています。
パート2: データレイクに対するAthenaでのクエリ実行とQuickSightでの可視化
次に、前のパートで作成された分割Parquetデータに対して新しいクローラを作成し実行します。
Tablesをクリックし、データカタログに新たに作られたテーブルを選び、Action > View dataの順に選択します。以下に示すように、View dataを選択することでAthena Query Editorから分割Parquetデータに対してSQLクエリを発行することができます。

図7: View data
View DataをクリックするとAthenaに移動し、select country, vaccines from “name_of_the_table”;のような簡単なクエリを実行することができます。
この出力結果からは、各国ごとにどのワクチンが採用されているのかが分かります。
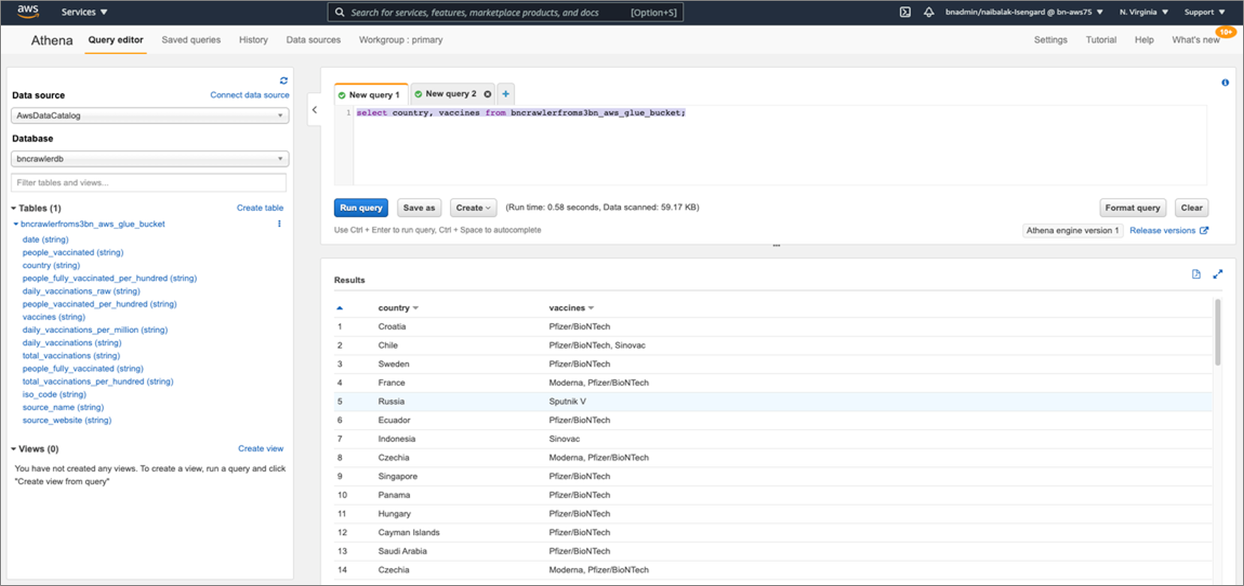
図8: Amazon Athenaでのクエリ実行
以上でクエリの実行ができましたので、次はAmazon QuickSightを使ってデータを可視化します。
QuickSightにてCreate a new datasetをクリックし、Athenaを選択します。データソースの名前を入力してCreate data sourceをクリックします。
次に、Catalogは既定のものを選び、パート1で作成したAWS Glueデータカタログを選択します。
前段の2つ目のクローラで作成したテーブルを選択してSelectをクリックします。Import to SPICE for quicker analyticsを選択してからVisualizeをクリックします。
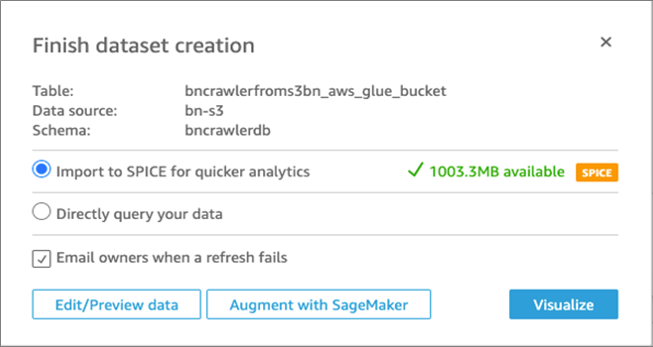
図9: 可視化の作成
これで要件に合わせてデータの可視化とカスタマイズができます。
QuickSightを使うことで非常に迅速に洞察を得ることができ、また以下のような質問にも答えることができます。
- ワクチン種別ごとの1日あたりのワクチン接種実施回数は?
- 特定の日にちまでのトータルのワクチン接種実施回数は?
- 現在までの各国のワクチン接種者数は?
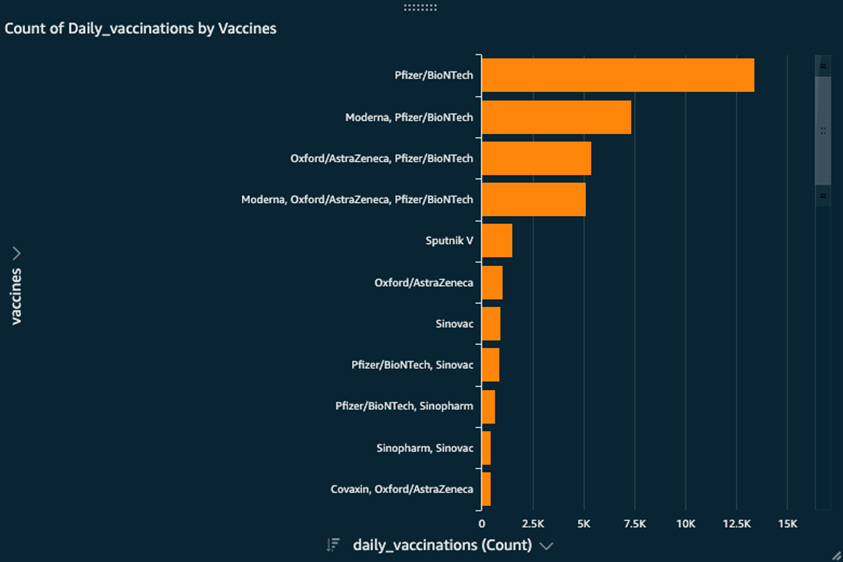
図10: 簡単なクエリの可視化結果
まとめ
VMware Cloud on AWS上でデータベースやデータストアの仮想マシンを稼働させることで、オンプレミスのVMware vSphere環境と同じ管理ツールやVMを使うことができます。
お客様は容易にこれらオンプレミスのワークロードをクラウドに拡張することができ、ビジネス目標達成のためにオンデマンドでの利用、グローバル規模のサービス展開、弾力性、拡張性といったAWSのメリットを享受することができます。
組み込みのSDDC機能やAWSのネイティブサービスを活用することで、VMware Cloud on AWSはビジネスデータのニーズにさらなる価値をもたらします。
クラウドのマネージドETLサービスであるAWS Glueを使う際、既存のデータベースサービスへアクセスするために移行の多大な労力を払うことなく、お客様のVPCとVMware Cloud on AWS環境の間にある既存接続を利用することができます。
お客様はAmazon S3を利用してデータレイク基盤を作り、定期的にデータをVMware Cloud on AWSのデータソースからデータレイクに移動させることができます。AWS Glueやその他のサービス、例えばAmazon Athena、Amazon Redshift Spectrum、Amazon QuickSightなどはコスト効率の良い方法でデータレイクと連携することができます。
これらのAWSサービスについてさらに詳しく知りたい場合はAWS Analyticsサービスのページをご参照ください。
参考文献
- Central logging and analytics in hybrid environments
- Exit your data center with confidence using VMware Cloud on AWS
- Application modernization with AWS and VMware
翻訳はGF SA太田が担当しました。原文はこちらです。