Amazon Web Services ブログ
最新情報 – Amazon S3 バッチオペレーション
 AWS のお客様は、S3 の規模、耐久性、低コスト、セキュリティ、およびストレージのオプションを利用して、個々の Amazon Simple Storage Service (S3) バケットに何十億にも及ぶオブジェクトを定期的に保存しています。お客様は、イメージ、ビデオ、ログファイル、バックアップ、およびその他のミッションクリティカルなデータを保存し、データストレージ戦略の重要な部分として S3 を使用しています。
AWS のお客様は、S3 の規模、耐久性、低コスト、セキュリティ、およびストレージのオプションを利用して、個々の Amazon Simple Storage Service (S3) バケットに何十億にも及ぶオブジェクトを定期的に保存しています。お客様は、イメージ、ビデオ、ログファイル、バックアップ、およびその他のミッションクリティカルなデータを保存し、データストレージ戦略の重要な部分として S3 を使用しています。
バッチオペレーション
今回は、Amazon S3 バッチオペレーションについて説明したいと考えています。この新機能を使用すると、数百、数百万、または数十億の S3 オブジェクトを簡単かつ直接的に処理することができます。オブジェクトを別のバケットにコピーしたり、タグを設定したり、アクセスコントロールリスト (ACL) を設定したり、Glacier から復元を開始したり、それぞれに対して AWS Lambda 関数を呼び出したりすることができます。
この機能は、インベントリレポート (詳細については、S3 ストレージ管理の更新記事を読んでください) に対する S3 の既存のサポートに基づいており、レポートまたは CSV ファイルを使用してバッチオペレーションを推進できます。コードを記述したり、サーバーフリートを設定したり、作業を分割してフリートに配信する方法を考えたりする必要はありません。代わりに、数回のクリックでジョブを数分で作成し、S3 がひそかに大規模な並列処理を行うことができます。S3 コンソール、S3 CLI、または S3 API を使用して、バッチジョブを作成、モニタリング、および管理できます。
簡単な語彙レッスン
バッチジョブを開始して作成する前に、いくつかの重要な用語を確認して紹介します。
バケット – S3 バケットは、オプションの各オブジェクトのバージョニングを使用して、任意の数の S3 オブジェクトのコレクションを保持します。
インベントリレポート – 毎日または毎週のバケットインベントリが実行されるたびに S3 インベントリレポートが生成されます。レポートは、バケット内のすべてのオブジェクトを含めるように、またはプレフィックスで区切られたサブセットに焦点を合わせるように設定できます。
マニフェスト – バッチジョブで処理されるオブジェクトを識別するリスト (インベントリレポート、または CSV 形式のファイル)。
バッチアクション – マニフェストによって記述されたオブジェクトに必要なアクション。オブジェクトにアクションを適用すると、S3 バッチタスクが構成されます。
IAM ロール – インベントリレポートのオブジェクトを読み取り、必要なアクションを実行し、オプションの完了レポートを作成する権限を S3 に提供する IAM ロール。[AWS Lambda 関数の呼び出し] アクションを選択した場合、関数の実行ロールは、必要な AWS サービスおよびリソースにアクセスする権限を付与する必要があります。
バッチジョブ – 上記のすべての項目を参照します。各ジョブにはステータスと優先順位があります。優先順位が高い (数値的に) ジョブは、優先順位が低いジョブよりも優先されます。
バッチジョブの実行
では、S3 コンソールを使ってバッチジョブを作成して実行してみましょう。 このブログ記事に備えて、今週初めに S3 バケットの 1 つ (jbarr-batch-camera) のインベントリレポートを有効にし、そのレポートを jbarr-batch-inventory にルーティングしました。
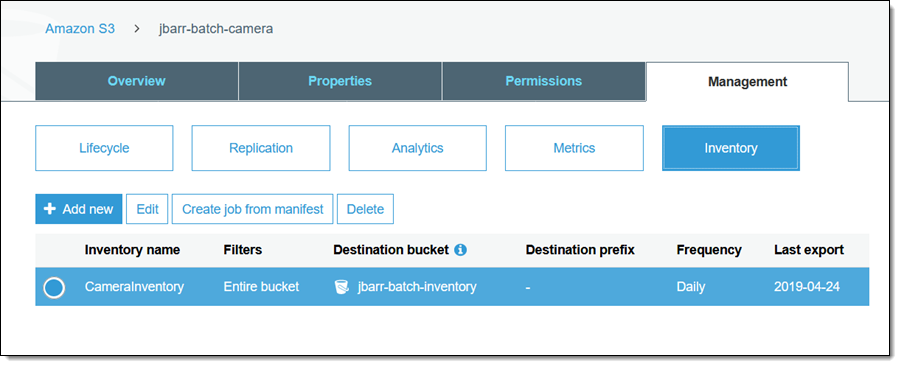
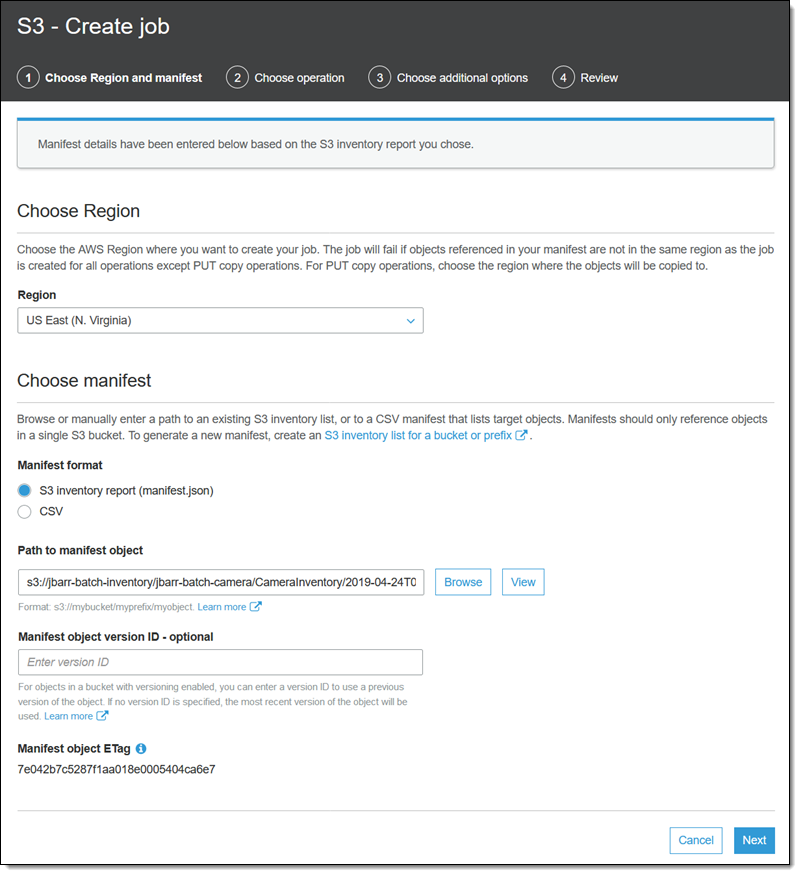
必要なインベントリ項目を選択し、[マニフェストからジョブを作成] をクリックして開始します (バケットのリストを参照しながら [バッチオペレーション] をクリックすることもできます)。すべての関連情報がすでに入力されていますが、必要に応じて以前のバージョンのマニフェストを選択できます (このオプションは、バージョニングが有効になっているバケットに保存されているマニフェストに対してのみ適用されます)。[次へ] をクリックして続けます。
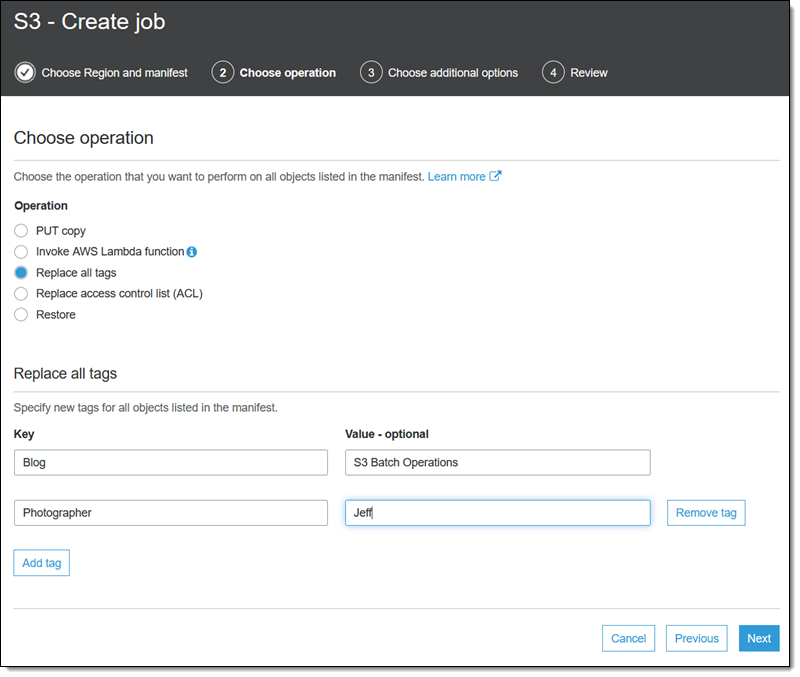
オペレーション (すべてのタグを置き換える) を選択し、固有のオプションを入力して (後で他のオペレーションを確認します)、[次へ] をクリックします。
ジョブの名前を入力して、その優先順位を設定し、すべてのタスクを含む完了レポートをリクエストします。次にレポートのバケットを選択して、必要な権限を付与する IAM ロールを選択し (コンソールにはコピーして使用できるロールポリシーと信頼ポリシーも表示されます)、[次へ] をクリックします。
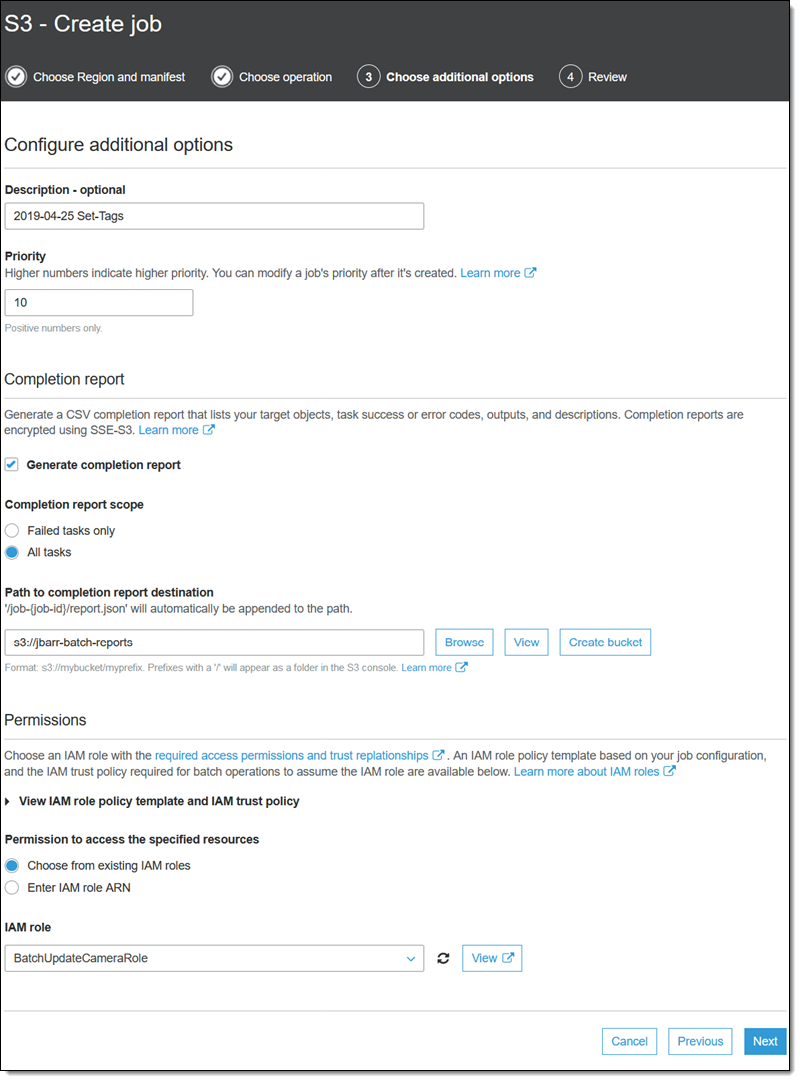
最後に、ジョブを確認して、[ジョブの作成] をクリックします。
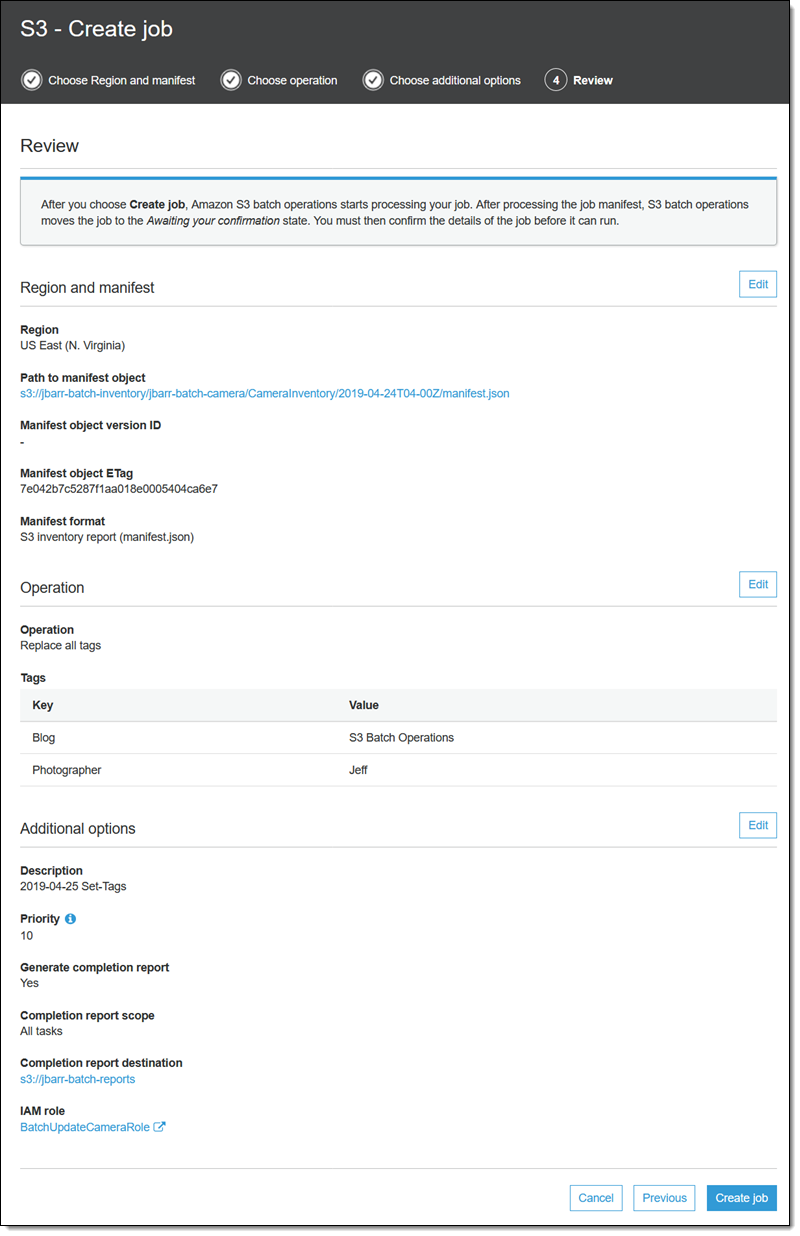
ジョブは「準備中」状態になります。S3 バッチオペレーションはマニフェストをチェックしてその他の検証を行い、ジョブは「確認待ち」状態になります (これはコンソールを使用している場合にのみ発生します)。選択して [確認および実行] をクリックします。
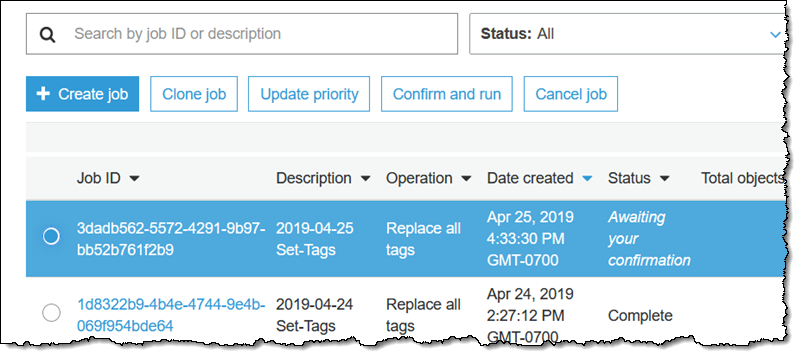
確認 (表示されていない) を行い、実行するアクションを理解したことを確認して、[ジョブの実行] をクリックします。ジョブは「準備完了」状態に入り、その後間もなく実行を開始します。完了すると、[完了] 状態に入ります。
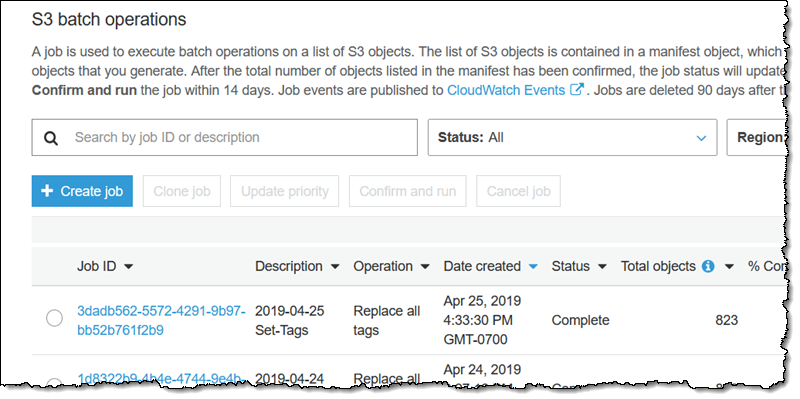
かなり多数のオブジェクトを処理するジョブを実行していた場合は、このページを更新して状況をモニタリングすることができます。知っておくべき重要事項: 最初の 1000 個のオブジェクトが処理された後、S3 バッチオペレーションは全体的な失敗率を調べてモニタリングし、失敗率が 50% を超えるとジョブを停止します。
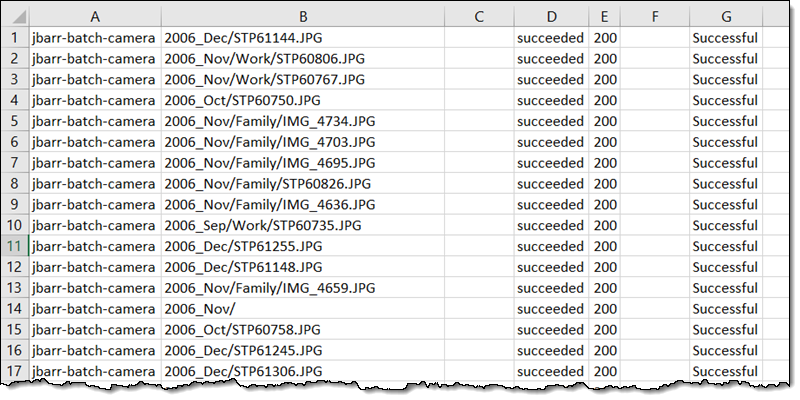
完了レポートには、オブジェクトごとに 1 つの行が含まれており、次のようになります。
その他の組み込みバッチオペレーション
他の組み込みバッチオペレーションを完全に実行するための十分なスペースがありません。概要は次のとおりです。
PUT コピーオペレーションは、ストレージクラス、暗号化、アクセスコントロールリスト、タグ、およびメタデータを制御して、オブジェクトをコピーします。
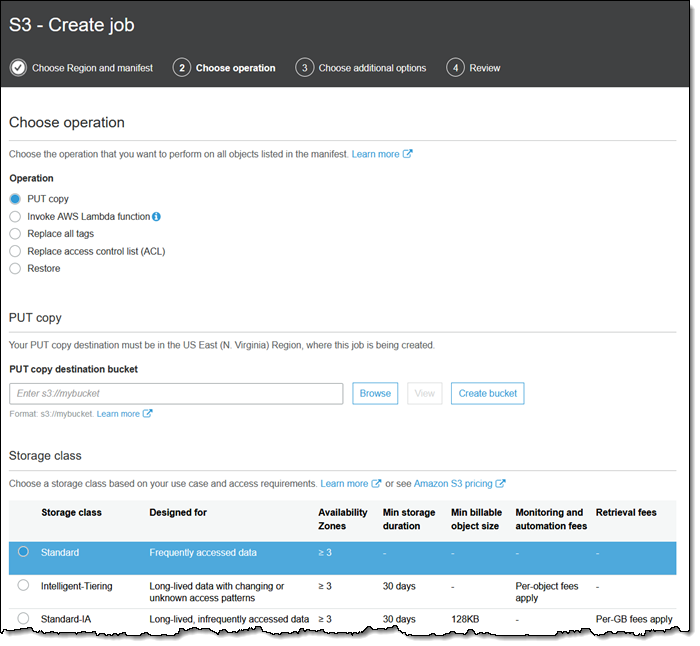
オブジェクトを同じバケットにコピーして、暗号化ステータスを変更することができます。また、オブジェクトを別のリージョン、または別の AWS アカウントが所有するバケットにコピーすることもできます。
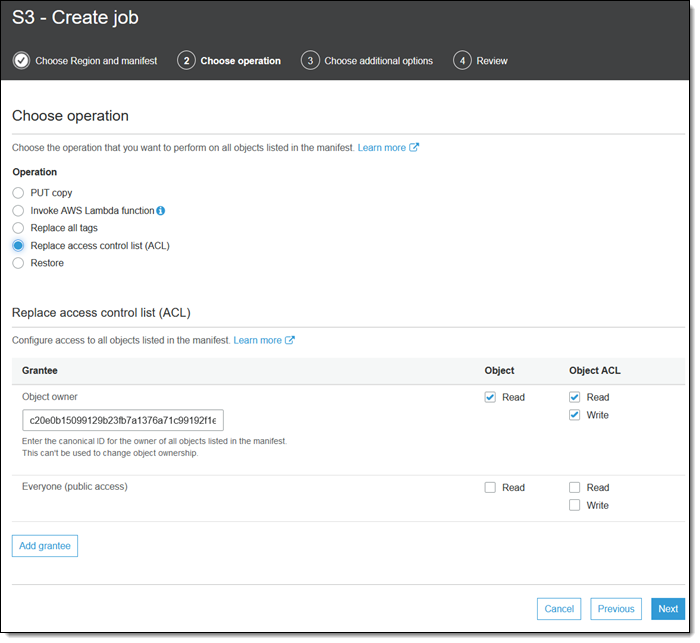
アクセスコントロールリスト (ACL) の置き換えオペレーションでは、付与されている権限を制御して、正確に実行します。
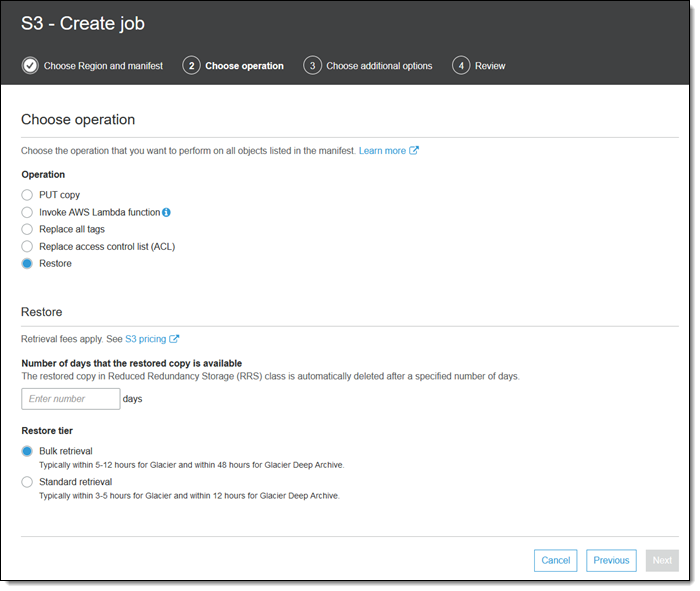
そして、復元オペレーションは Glacier または Glacier Deep Archive ストレージクラスからオブジェクトレベルの復元を開始します。
AWS Lambda 関数の呼び出し
最後に最も一般的なオプションを保存しました。各オブジェクトに対して Lambda 関数を呼び出すことができ、その Lambda 関数は各オブジェクトをプログラムで分析および操作できます。機能の実行ロールは S3 バッチオペレーションを信頼する必要があります。
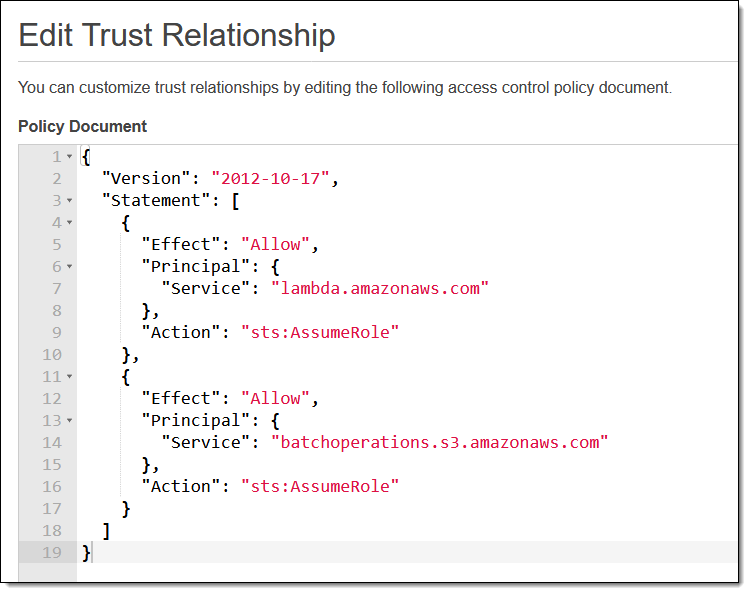
また、バッチジョブのロールでは、Lambda 関数を呼び出せるようにする必要があります。
必要なロールが整ったら、各イメージに対して Amazon Rekognition を呼び出す単純な関数を作成できます。
関数を配置したら、ジョブを作成するときに [AWS Lambda 関数の呼び出し] をオペレーションとして選択し、次に BatchProcessObject 関数を選択します。
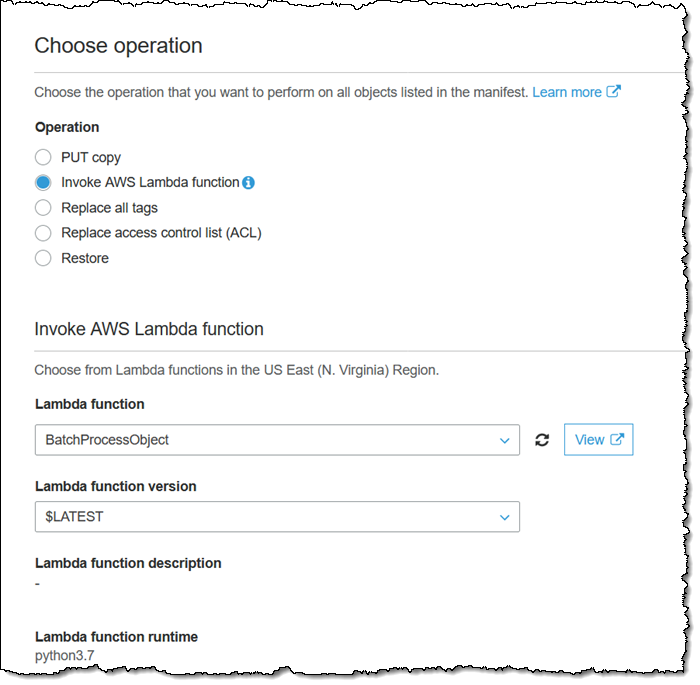
その後、いつものようにジョブを作成して確認します。この関数は、各オブジェクトに対して呼び出されます。また、Lambda の拡張機能を利用して、この中規模のジョブを 1 分以内に完了できるようにします。
CloudWatch Logs コンソールに「検出済み」のメッセージが表示されます。
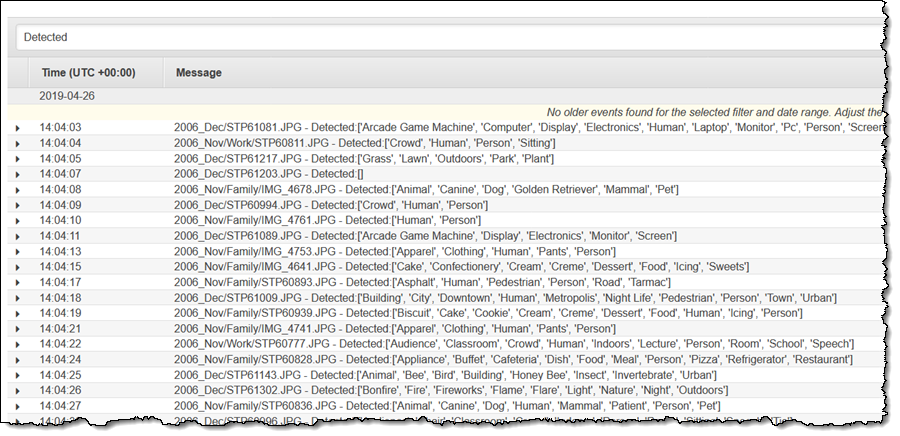
非常に単純な例からわかるように、多数の S3 オブジェクトに対して Lambda 関数を簡単に実行できることによって、さまざまな興味深いアプリケーションを利用できるようにします。
知っておくべきこと
それでは、S3 バッチオペレーションでお客様が発見されたユースケースについてお聞きする日を楽しみにしています! まとめる前に、最後の考察を述べたいと思います。
ジョブのクローン作成 – 既存のジョブのクローンを作成し、パラメータを微調整して、新しいジョブとして再送信できます。これを使用して、失敗したジョブを再実行したり、必要な調整を加えたりすることができます。
プログラムによるジョブの作成 – インベントリレポートを生成するバケットに Lambda 関数をアタッチして、レポートが届くたびに新しいバッチジョブを作成することができます。プログラムによって作成されたジョブは確認する必要がなく、すぐに実行することができます。
CSV オブジェクトリスト – バケット内のオブジェクトのサブセットを処理する必要があり、それらの識別に共通プレフィックスを使用できない場合は、CSV ファイルを作成し、それを使用してジョブを進めることができます。インベントリレポートから始めることができます。また、名前に基づいて、またはデータベースや他のリファレンスに対してチェックを行うことによって、オブジェクトをフィルター処理できます。たとえば、Amazon Comprehend を使用して、保存されているすべてのドキュメントの感情分析を実行するとしましょう。インベントリレポートを処理して、まだ分析されていないドキュメントを見つけて、CSV ファイルに追加することができます。
ジョブの優先順位 – 各 AWS リージョンで同時に複数のジョブをアクティブにすることができます。優先順位の高いジョブが優先されると、既存のジョブが一時的に中断される可能性があります。その場で変更を加えるために、アクティブなジョブを選択して、[優先順位の更新] をクリックします。
詳細
S3 バッチオペレーションの詳細については、以下の資料を参照してください。
ドキュメント – ジョブの作成、バッチオペレーション、およびバッチオペレーションジョブの管理についてお読みください。
チュートリアルビデオ – S3 バッチオペレーションのビデオチュートリアル、ジョブの作成方法、ジョブの管理と追跡方法、および権限の付与方法をご確認ください。
今すぐ利用可能
今日からアジアパシフィック (大阪) を除くすべての商用 AWS リージョンで S3 バッチオペレーションの使用を開始できます。また、S3 バッチオペレーションは、AWS GovCloud (米国) リージョンの両方でもご利用いただけます。
— Jeff;