Amazon Web Services ブログ
AQUA (Advanced Query Accelerator) – Amazon Redshift クエリをブースト
Amazon Redshift は、規模に関係なく、他のクラウドデータウェアハウスよりも最大 3 倍優れたコストパフォーマンスを提供します。これは、独自のハードウェアを設計し、機械学習 (ML) を使用することによって実現しています。
例えば、私たちは、2019 年の終わりに Amazon Redshift 向けの SSD ベースの RA3 をローンチしました (「Amazon Redshift Update – Next-Generation Compute Instances and Managed, Analytics-Optimized Storage」)。昨年 4 月 (「Amazon Redshift update – ra3.4xlarge Nodes」) と 12 月にノードサイズを追加しました (「Amazon Redshift Launches RA3.xlplus Nodes With Managed Storage」)。高帯域幅ネットワーキングに加えて、RA3 ノードには、洗練されたデータ管理モデルが組み込まれています。RA3 ノードのローンチでは、次のような記事を書きました。
各インスタンスには S3 でバックアップされた大容量の高性能 SSD ベースのストレージのキャッシュがあり、スケール、パフォーマンス、および耐久性を確保できます。ストレージシステムは、データブロックの温度、データのブロック、ワークロードパターンなどの複数のキューを使用して、キャッシュを管理して高性能を実現します。データは自動的に適切な階層に配置され、キャッシュやその他の最適化の恩恵を受けるために特別なことをする必要はありません。
多くのお客様が RA3 ノードを使用して非常に大きなデータセットを維持し、優れた結果を得ています。デジタルインタラクティブエンターテインメントからメディア購入のインプレッションやパフォーマンスの追跡まで、Amazon Redshift ノードと RA3 ノードは、単一のデータウェアハウスに最大 32 PB のデータを格納し、データを世界規模で格納およびクエリできます。
データウェアハウスが拡大を続ける場合でも、ストレージパフォーマンスの向上は、CPU パフォーマンスの向上を上回ります。大量のデータ (フルスキャンが必要なクエリによってアクセスされるデータ) とネットワークトラフィックの制限の組み合わせにより、ネットワークと CPU 帯域幅が制限の要因になる場合があります。
以降のセクションでは、その対処方法について説明します。
AQUA を導入する
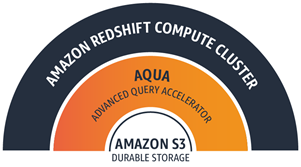 現在、私たちは、AQUA (Advanced Query Accelerator) の追加に加えて、さらに協力な ra3.4xl ノードと ra3.16xl ノードを作成しています。先に説明したキャッシュ上に構築され、AWS Nitro System と FPGA ベースのカスタムアクセラレーションを活用する AQUA は、削減クエリと集計クエリを処理するために必要なコンピューティングをデータに近づけます。ネットワークトラフィックが削減され、RA3 ノードの CPU 負荷が軽減されます。また、AQUA では、追加コストやコードの変更なしで、クエリのパフォーマンスを最大 10 倍向上させることができます。AQUA では、Amazon Simple Storage Service (S3) への高速な高帯域幅の接続も活用されます。
現在、私たちは、AQUA (Advanced Query Accelerator) の追加に加えて、さらに協力な ra3.4xl ノードと ra3.16xl ノードを作成しています。先に説明したキャッシュ上に構築され、AWS Nitro System と FPGA ベースのカスタムアクセラレーションを活用する AQUA は、削減クエリと集計クエリを処理するために必要なコンピューティングをデータに近づけます。ネットワークトラフィックが削減され、RA3 ノードの CPU 負荷が軽減されます。また、AQUA では、追加コストやコードの変更なしで、クエリのパフォーマンスを最大 10 倍向上させることができます。AQUA では、Amazon Simple Storage Service (S3) への高速な高帯域幅の接続も活用されます。
このビデオでは 、カスタム設計されたハードウェアを AQUA ノードで使用してクエリを高速化する方法について詳細に説明しています。利点はいくつかの方法で得られます。各ノードは、他のノードと並行して削減および集約オペレーションを実行します。並列処理による n 倍のスピードアップに加えて、一般的に、コンピューティングノード上で送信および処理する必要があるデータの量は、はるかに少なくなります (元のデータの 5% 程度)。次の図は、すべての要素が連動してクエリを高速化する方法を示しています。
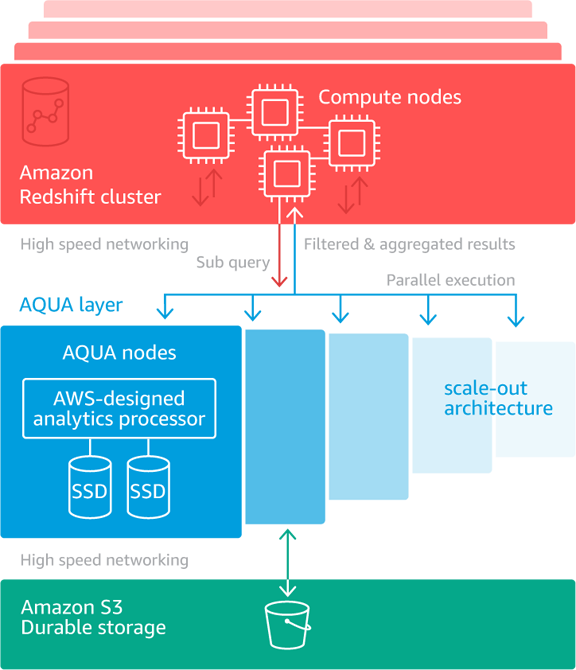
すでに ra3.4xl ノードまたは ra3.16xl ノードを使用してデータウェアハウスをホストしている場合、AQUA をすぐに使い始めることができます。AQUA を有効にしてクラスターを再起動するだけで、削減クエリと集約クエリのパフォーマンスが大幅に向上します。RA3 と AQUA をすでに使用している場合、既存の RA3 クラスターから新しい RA3 クラスターを作成するか、従来のサイズ変更を使用してインプレースアップグレードを実行することができます。
AQUA を使う
今回はデータウェアハウスがなかったので、 Redshift チームが提供するスナップショットを使用して、2 つのクラスターを作成しました。最初のクラスター (prod-cluster) では AQUA を有効にしないで、2 番目のクラスター ( テストクラスタ )で有効にしました。
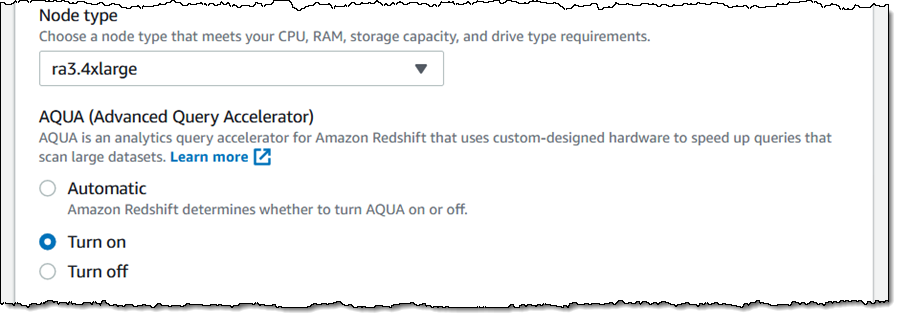
AQUA が有効なクラスターを作成するために必要な操作は、[Cluster configuration] (クラスター設定) ページで [Turn on] (有効化) を選択することだけです。
今回のクエリは、180 億行以上を含む lineitem テーブルを使用します。
各クラスターでセッションを作成し、Redshift 結果キャッシュを無効にします。
そして、両方のクラスターで同じクエリを実行します。
上の図 (およびビデオ) では、このタイプのクエリが AQUA で非常に効率的に処理できる理由を確認できます。コンピューティングノードの 18 億行すべてを順にスキャンするのではなく、AQUA では、similar to 式のコレクションを複数の AQUA ノードに分散して並列実行します。
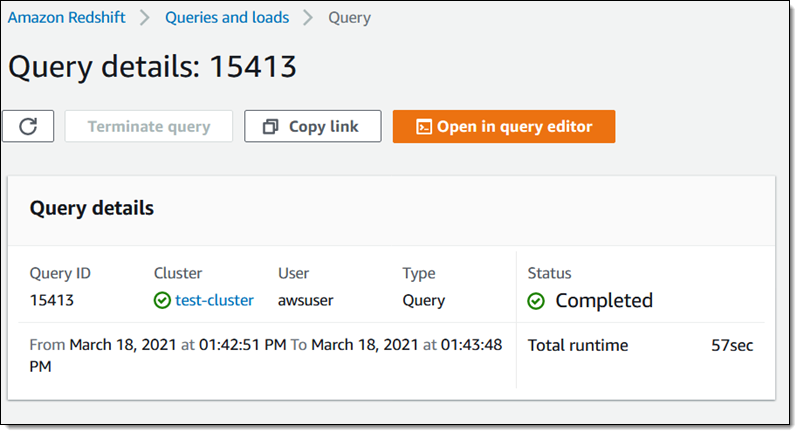
AQUA が有効なクラスターのクエリは 1 分以内で終了します。
AQUA が有効でクラスターのクエリが完了するまでには 4 分程度の時間がかかります。
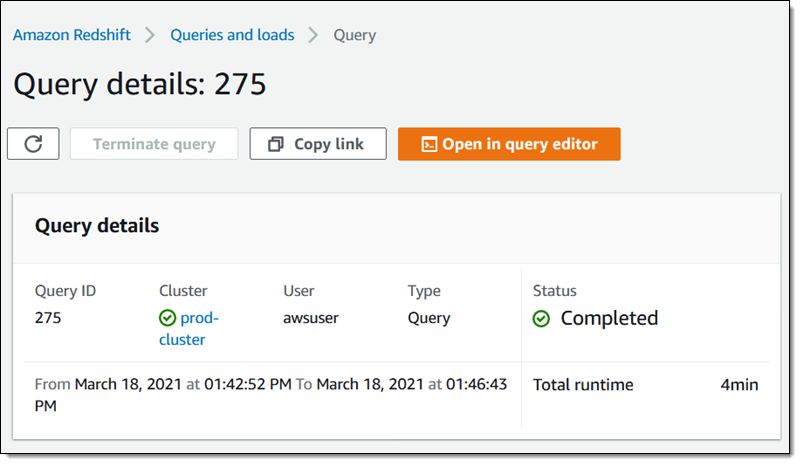
データベース、複雑なデータ、均等に複雑なクエリの場合と同様に、要する時間は異なります。たとえば、複数のテーブルから選択 (SELECT) された複数の行の複雑な JOIN を実行するクエリでは、各 SELECT は AQUA のメリットを活用するので全体的にさらにスピードアップされます。この記事で使用した簡単なクエリが示すように、AQUA では、クエリ時間を劇的に短縮できるだけでなく、これまで不可能または非実用的だった新しいタイプのリアルタイムクエリを有効にすることも可能になります
知っておくべきこと
AQUA に関する興味深い事実をいくつか示しておきます。
クラスターバージョン – AQUA を使用するには、クラスターで Redshift バージョン 1.0.24421 以降を実行している必要があります。AQUA を有効または無効にする方法の詳細については、「Managing an AQUA Cluster」を参照してください。
関連クエリ – AQUA は、LIKE 述語と SIMILAR_TO 述語で大規模なスキャン、集計、およびフィルタリングを実行するクエリで最大 10 倍のパフォーマンスを実現するよう設計されています。今後、その他のクエリのサポートが追加される予定です。
セキュリティ – AQUA によってキャッシュされるすべてのデータはキーを使用して暗号化されます。フィルタリングまたは集約オペレーションを実行した後、AQUA は結果を圧縮して暗号化し、Redshift に戻します。
リージョン – AQUA は、現在、米国東部 (バージニア北部)、米国西部 (オレゴン)、米国東部 (オハイオ)、欧州 (アイルランド)、アジアパシフィック (東京) リージョンで利用できます。2021 年前半には、欧州 (フランクフルト)、アジアパシフィック (シドニー)、アジアパシフィック (シンガポール)で利用可能になる予定です。
料金 – 先に説明したように、AQUA を使用するための追加コストは必要ありません。
今すぐ AQUA を試す
Redshift で ra3.4xl ノードまたは ra3.16xl ノードを使用している場合、AQUA を有効にしてクラスターを再起動すれば、すぐにクエリをテストできます。AQUA の使用に関するフィードバックをお待ちしています。
– Jeff