Amazon Web Services ブログ
NEW — Amazon SageMaker Data Wrangler でのリアルタイム推論とバッチ推論のサポートのご紹介
機械学習モデルを構築するには、機械学習エンジニアは、データ変換パイプラインを開発して、データを準備する必要があります。このパイプラインの設計プロセスには時間がかかり、データ準備パイプラインを本番環境に実装するには、機械学習エンジニア、データエンジニア、データサイエンティストのチーム間のコラボレーションが必要です。
Amazon SageMaker Data Wrangler の主な目的は、データ準備とデータ処理ワークロードを簡単に実行できるようにすることです。SageMaker Data Wrangler を使用すると、データ準備プロセスとデータ準備ワークフローに必要なすべてのステップを、単一のビジュアルインターフェイスで簡素化できます。SageMaker Data Wrangler では、データ処理ワークロードのプロトタイプを迅速に作成して本番環境にデプロイする時間を短縮できるため、お客様は MLOps の本番環境と簡単に統合できます。
ただし、モデルトレーニングのためにお客様のデータに適用された変換は、リアルタイム推論中に新しいデータに適用する必要があります。リアルタイム推論エンドポイントで SageMaker Data Wrangler がサポートされていない場合、お客様はフローからの変換を前処理スクリプトに複製するコードを記述する必要があります。
Amazon SageMaker Data Wrangler でのリアルタイム推論とバッチ推論のサポートのご紹介
リアルタイム推論とバッチ推論を行うために、SageMaker Data Wrangler からデータ準備フローをデプロイできるようになりました。この機能により、SageMaker Data Wrangler で作成したデータ変換フローを Amazon SageMaker 推論パイプラインのステップとして再利用できます。
SageMaker Data Wrangler のリアルタイム推論とバッチ推論のサポートにより、データ変換フローの実装を繰り返す必要がなくなり、本番環境へのデプロイがスピードアップします。SageMaker Data Wrangler を SageMaker 推論と統合できるようになりました。SageMaker Data Wrangler の使いやすいポイントアンドクリックインターフェイスで作成された、主成分分析やワンホットエンコーディングなどのオペレーションを含むデータ変換フローと同じものが、推論中のデータ処理に使用されます。つまり、リアルタイム推論およびバッチ推論のアプリケーション用にデータパイプラインを再構築する必要がなく、本番稼働までの時間を短縮できます。
リアルタイム推論とバッチ推論を開始する
SageMaker Data Wrangler のデプロイサポートの使用方法を見てみましょう。このシナリオでは、SageMaker Data Wrangler の内部にフローがあります。しなければならないことは、SageMaker 推論パイプラインを使用して、このフローをリアルタイム推論とバッチ推論に統合することです。
まず、データセットにいくつかの変換を適用して、トレーニングに備えます。
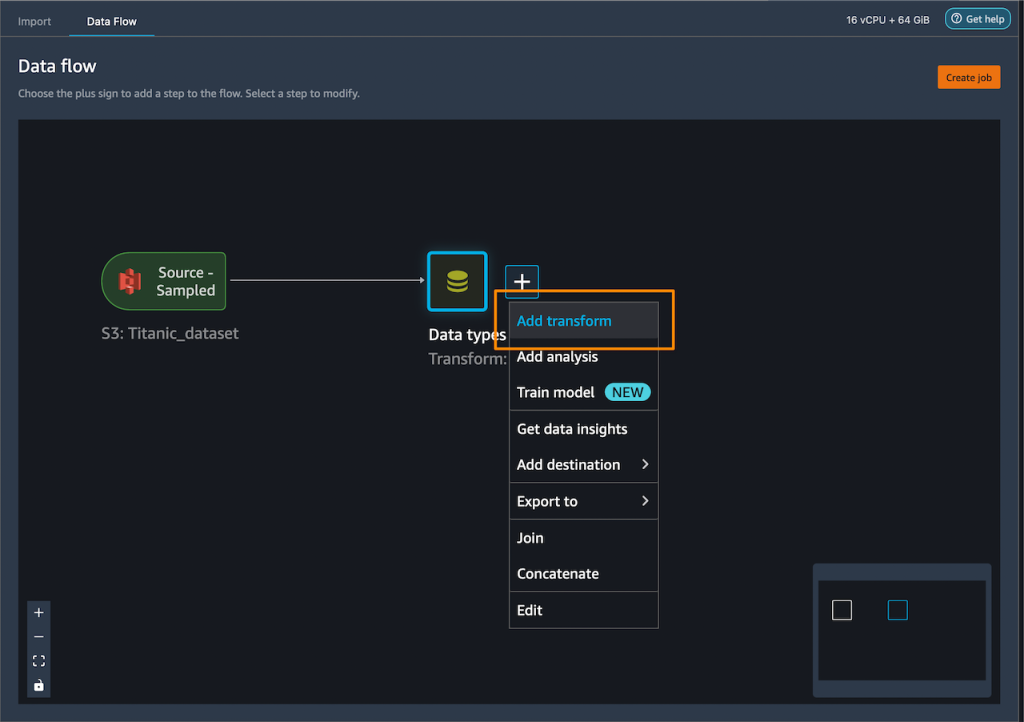
カテゴリ列にワンホットエンコーディングを追加して、新しい機能を作成します。
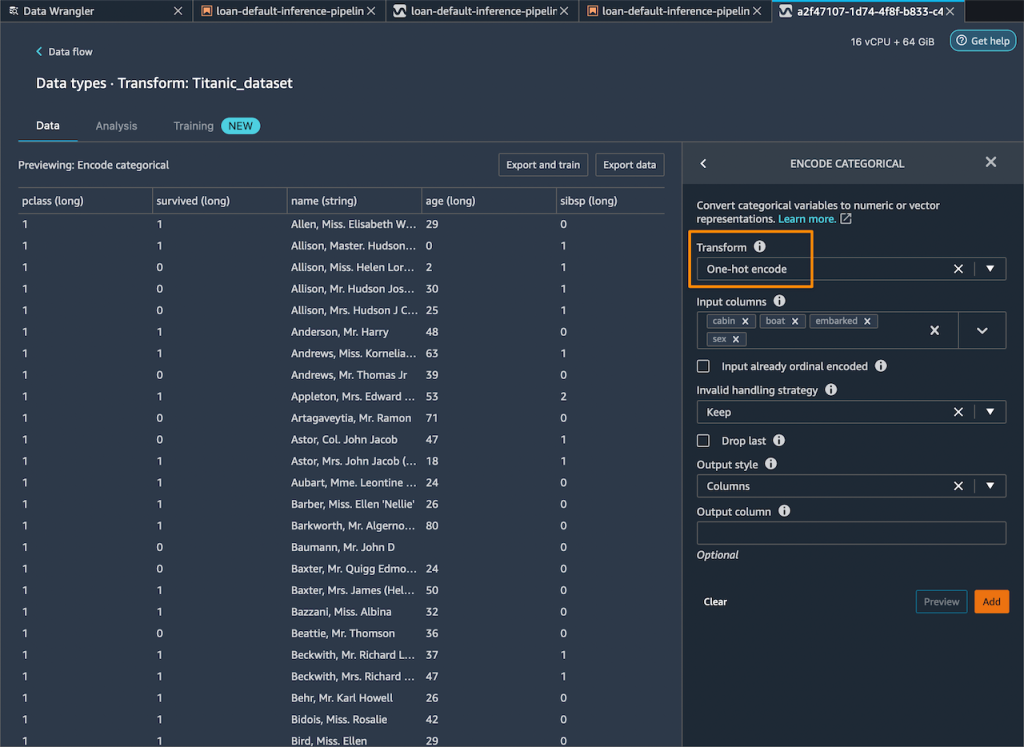
次に、トレーニング中に使用できない残りの文字列の列をすべて削除します。

作成したフローには、次の 2 つの変換ステップが含まれています。
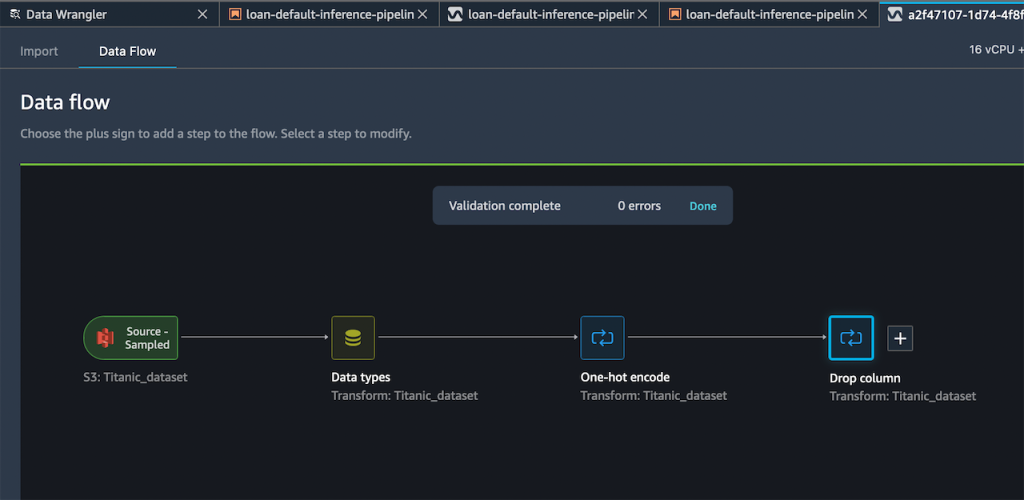
追加したステップに納得したら、Export to (エクスポート先) メニューを展開して、SageMaker 推論パイプライン (Jupyter Notebook 経由) にエクスポートするオプションを表示することができます。

Export to SageMaker Inference Pipeline (SageMaker 推論パイプラインにエクスポート) を選択すると、SageMaker Data Wrangler が完全にカスタマイズされた Jupyter Notebook を用意して、SageMaker Data Wrangler のフローと推論を統合します。この生成された Jupyter Notebook は、いくつかの重要なアクションを実行します。まず、データ処理を定義し、SageMaker パイプラインのトレーニングステップをモデル化します。次のステップは、パイプラインを実行して Data Wrangler でデータを処理し、処理されたデータを使用して、リアルタイムの予測を生成するために使用されるモデルをトレーニングすることです。それから、Data Wrangler フローとトレーニング済みモデルを、推論パイプラインとしてリアルタイムエンドポイントにデプロイします。最後に、エンドポイントを呼び出して予測を行います。

この機能では Amazon SageMaker Autopilot を使用しているため、ML モデルを簡単に構築できます。必要なのは、SageMaker Data Wrangler ステップの出力である変換後のデータセットを提供し、予測するターゲット列を選択することだけです。残りは Amazon SageMaker Autopilot が処理し、さまざまなソリューションを検討して最適なモデルを見つけます。

SageMaker Autopilot のトレーニングステップとして AutoML を使用することは、ノートブックで use_automl_step 変数を使ってデフォルトで有効になっています。AutoMLステップを使用する場合、推論中に予測したいデータの列である target_attribute_name の値を定義する必要があります。代わりに XGBoost アルゴリズムを使用してモデルをトレーニングしたい場合は、use_automl_step を False に設定することもできます。
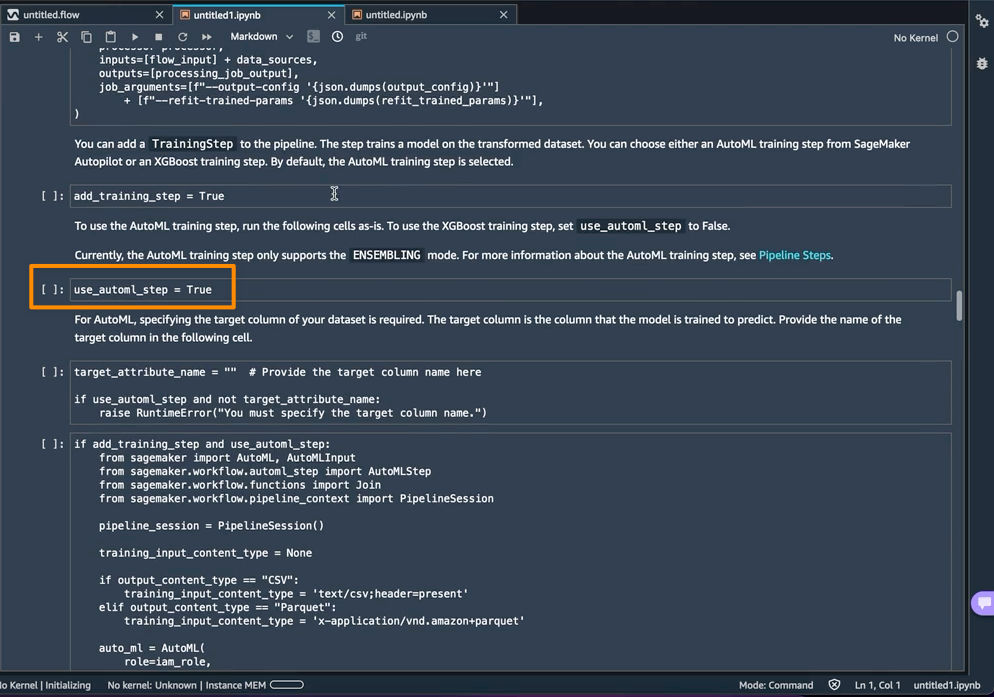
一方、このノートブックの外部でトレーニングしたモデルを代わりに使用したい場合は、ノートブックの Create SageMaker Inference Pipeline (SageMaker 推論パイプラインの作成) セクションに直接進んでもかまいません。ここでは、byo_model 変数の値を True に設定する必要があります。また、algo_model_uri の値も指定する必要があります。これは、モデルが配置されている Amazon Simple Storage Service (Amazon S3) URI です。ノートブックを使用してモデルをトレーニングすると、これらの値は自動入力されます。
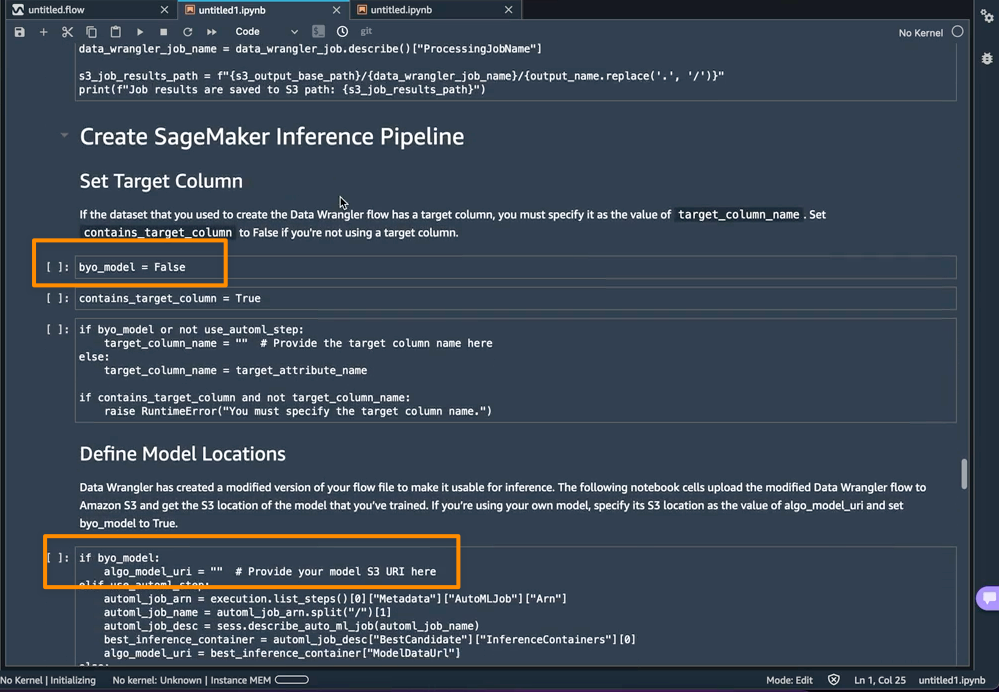
さらに、この機能により、SageMaker Studio インスタンスの data_wrangler_inference_flows フォルダー内に tarball が保存されます。このファイルは SageMaker Data Wrangler フローの修正版で、推論時に適用されるデータ変換ステップが含まれています。このファイルはノートブックから S3 にアップロードされ、推論パイプライン内の SageMaker Data Wrangler 前処理ステップの作成に使用できます。
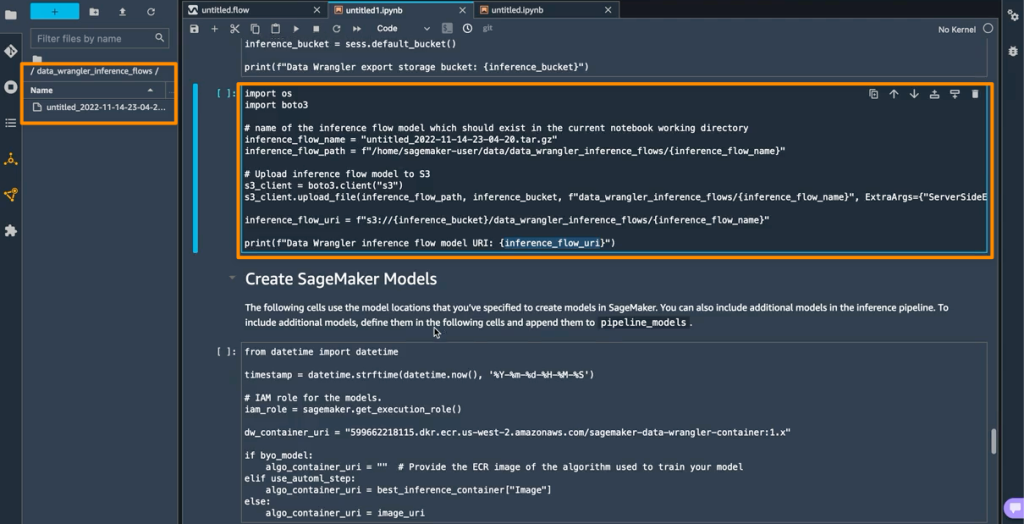
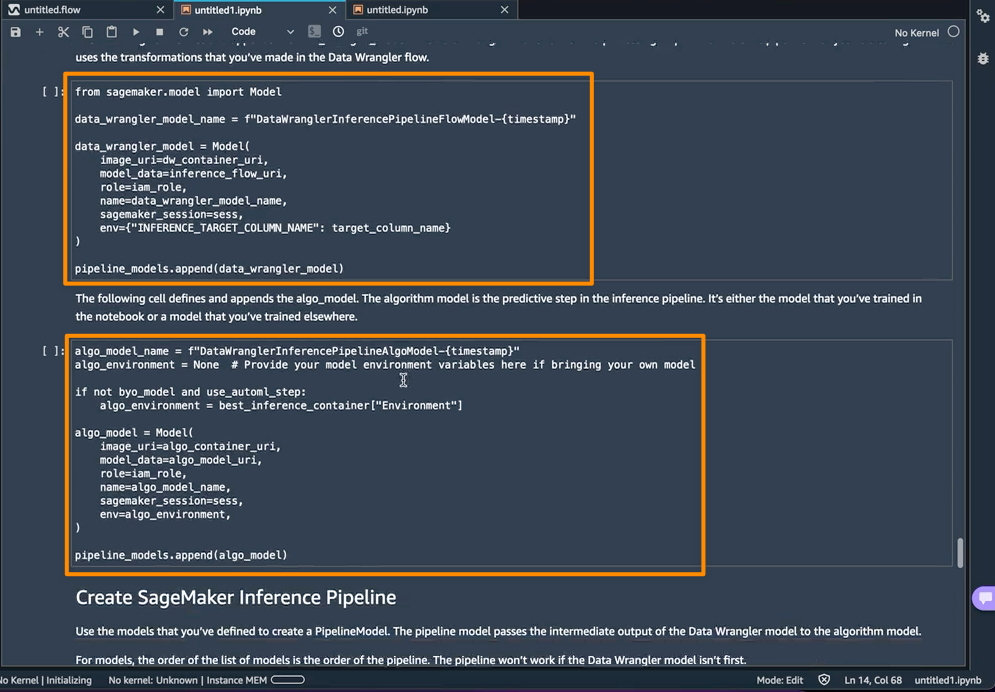
次のステップでは、このノートブックが 2 つの SageMaker モデルオブジェクトを作成します。最初のオブジェクトモデルは data_wrangler_model という変数を持つ SageMaker Data Wrangler モデルオブジェクトで、2 番目のオブジェクトモデルは変数 algo_model をもつアルゴリズムのモデルオブジェクトです。オブジェクト data_wrangler_model は、予測のために algo_model に処理されたデータの形式で入力を提供するために使用されます。
このノートブックの最後のステップは、SageMaker 推論パイプラインモデルを作成し、それをエンドポイントにデプロイすることです。
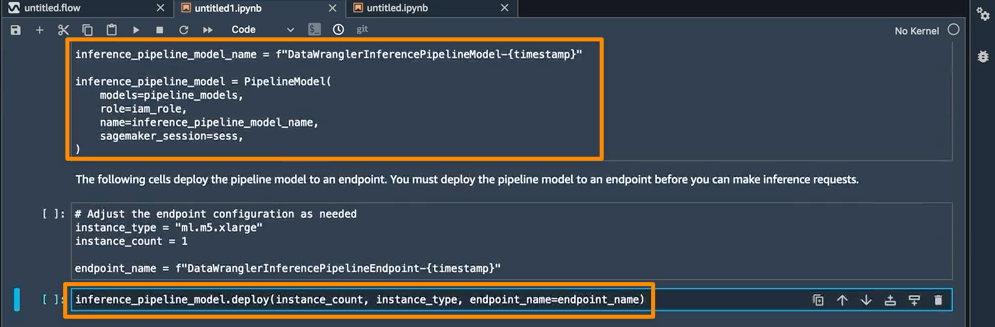
デプロイが完了すると、予測に使用できる推論エンドポイントが取得されます。この機能により、推論パイプラインは SageMaker Data Wrangler フローを使用して、推論リクエストのデータをトレーニング済みモデルが使用できる形式に変換します。
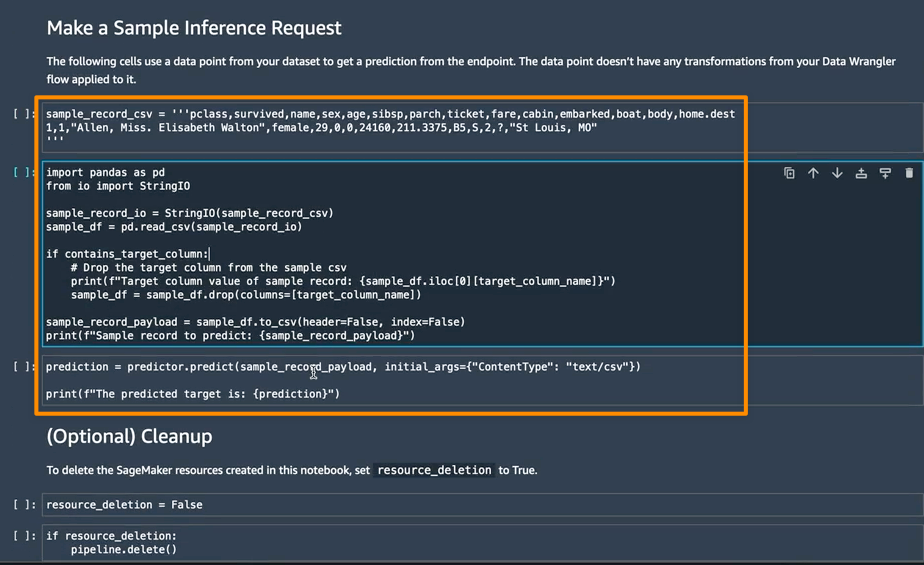
次のセクションでは、Make a Sample Inference Request (サンプル推論リクエストの作成) で個々のノートブックセルを実行できます。これは、未処理のデータから単一のデータポイントを使用してエンドポイントを呼び出すことで、エンドポイントが機能しているかどうかを簡単に確認する必要がある場合に役立ちます。Data Wrangler はこのデータポイントを自動的にノートブックに配置するので、手動でデータポイントを提供する必要はありません。
知っておくべきこと
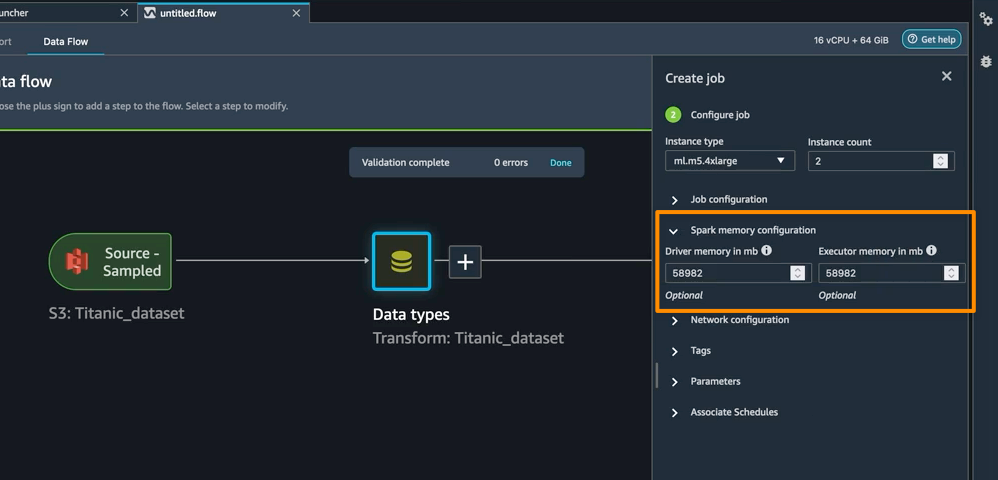
Apache Spark 設定の強化 — SageMaker Data Wrangler のこのリリースでは、Amazon S3 にデータを保存するときに Apache Spark が SageMaker Data Wrangler のジョブの出力をどのようにパーティション分割するかを簡単に設定できるようになりました。宛先ノードを追加すると、Amazon S3 に書き込まれるファイルの数に対応するパーティション数を設定できます。また、パーティション化の基準となる列名を指定して、それらの列の値が異なるレコードを、Amazon S3 のさまざまなサブディレクトリに書き込むことができます。さらに、付属のノートブックで設定を定義することもできます。

ジョブ作成ワークフローの一部として、SageMaker Data Wrangler 処理ジョブのメモリ設定を定義することもできます。ノートブックにも同様の設定が組み込まれています。
可用性 — SageMaker Data Wrangler はリアルタイム推論とバッチ推論をサポートしているほか、データ処理ワークロード用の Apache Spark 設定の強化もサポートしており、Data Wrangler が現在サポートしているすべての AWS リージョンで一般的に利用可能です。
Amazon SageMaker Data Wrangler によるリアルタイム推論およびバッチ推論のデプロイのサポートを開始するには、AWS ドキュメントを参照してください。
構築がうまくいきますように
— Donnie
原文はこちらです。