Amazon Web Services ブログ
NEW — Amazon Comprehend for IDP を使用して PDF、ワードドキュメント、および画像を処理
2022/12/01に、インテリジェントドキュメント処理 (IDP) 用 Amazon Comprehend の新機能を発表します。この機能により、最初にテキストを抽出しなくても、Amazon Comprehend から直接 PDF ドキュメント、Microsoft Word ファイル、および画像からエンティティを分類して抽出できます。
多くのお客様は、スキャンされた領収書の画像や PDF 形式の税務申告書など、半構造化された形式の文書を処理する必要があります。これまでは、まず光学式文字認識 (OCR) ツールを使用して文書を前処理してテキストを抽出する必要がありました。その後、Amazon Comprehend を使用して、前処理されたファイルからエンティティを分類および抽出できます。
Amazon Comprehend for IDP を使用することで、お客様は PDF、docx、PNG、JPG、TIFF 画像などの半構造化ドキュメントだけでなく、プレーンテキストドキュメントを 1 回の API 呼び出しで処理できます。この新機能は、OCR と Amazon Comprehend の既存の自然言語処理 (NLP) 機能を組み合わせて、ドキュメントからエンティティを分類および抽出します。カスタムドキュメント分類 API では、ドキュメントをカテゴリまたはクラスに分類できます。また、カスタム名エンティティ認識 API を使用すると、製品コードやビジネス固有のエンティティなどのドキュメントからエンティティを抽出できます。例えば、ある保険会社ではスキャンしたお客様からの請求を、より少ない API コールで処理することができるようになりました。Amazon Comprehend エンティティ認識 API を使用することで、請求から顧客番号を抽出し、カスタム分類子 API を使用して請求をさまざまな保険カテゴリ (住宅、自動車、個人) に分類できます。
2022/12/01より、Amazon Comprehend for IDP API は、ファイルのリアルタイム推論や、大規模なドキュメントセットの非同期バッチ処理に使用できるようになりました。この機能により、文書処理パイプラインが簡略化され、開発作業が軽減されます。
開始方法
Amazon Comprehend for IDP では、AWS マネジメントコンソール、AWS SDK、または AWS コマンドラインインターフェイス (AWS CLI) から使用できます。
このデモでは、カスタム分類子を使用して半構造化ファイルを非同期的に処理する方法について説明します。エンティティを抽出する場合は手順が異なりますので、ドキュメントを確認することでその方法を学ぶことができます。
分類子を使用してファイルを処理するには、まずカスタム分類器をトレーニングする必要があります。Amazon Comprehend 開発者ガイドの手順に従うことができます。この分類器にはプレーンテキストデータを使用して学習させる必要があります。
カスタム分類器をトレーニングしたら、非同期操作または同期操作を使用してドキュメントを分類できます。同期操作を使用して単一のドキュメントを分析するには、カスタムモデルを使用してリアルタイム分析を実行するエンドポイントを作成する必要があります。リアルタイム分析の詳細については、ドキュメントを参照してください。このデモでは、非同期操作を使用して、分類するドキュメントを Amazon Simple Storage Service (Amazon S3) バケットに配置し、分析バッチジョブを実行します。
コンソールからドキュメントの一括分類を開始するには、Amazon Comprehend ページで [分析ジョブ] に移動し、次に [ジョブの作成] に移動します。
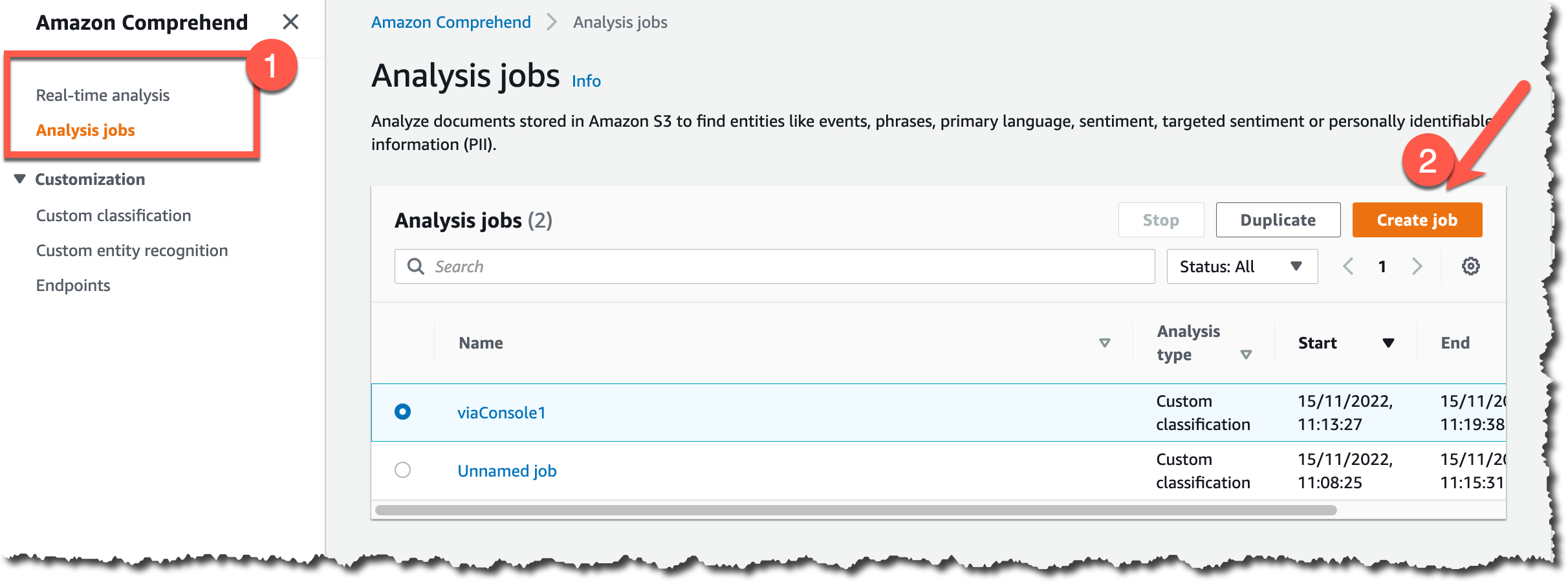
その後、新しい分析ジョブを設定します。まず、名前を入力して [カスタム分類] と以前に作成したカスタム分類子を選択します。
その後、入力データを構成します。まず、そのデータの S3 ロケーションを選択します。その場所に、PDF、画像、Word 文書を配置することができます。半構造化文書を処理するため、1 ファイルにつき 1 つの文書を選択する必要があります。Amazon Comprehend の設定を変更して文書を抽出および解析する場合は、高度な文書入力オプションを設定できます。
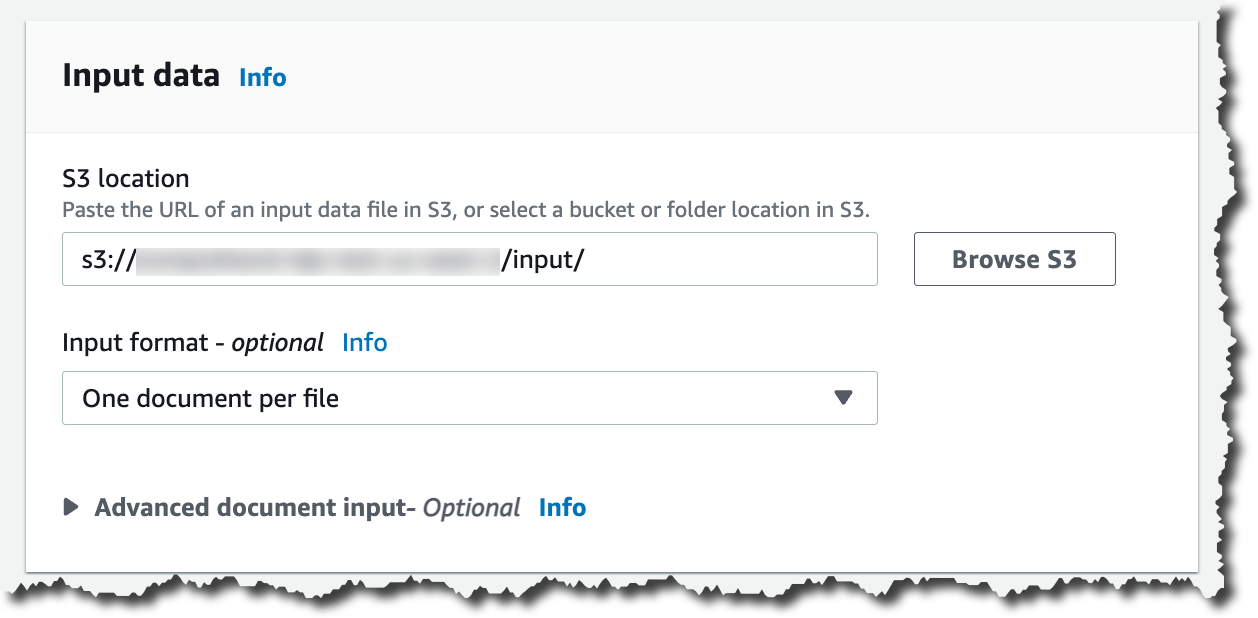
入力データを設定したら、この分析の出力を保存する場所を選択します。また、この分析ジョブにアクセス権限を付与して、指定した Amazon S3 ロケーションでの読み取りと書き込みを行う必要があります。これで、ジョブを作成する準備が整います。
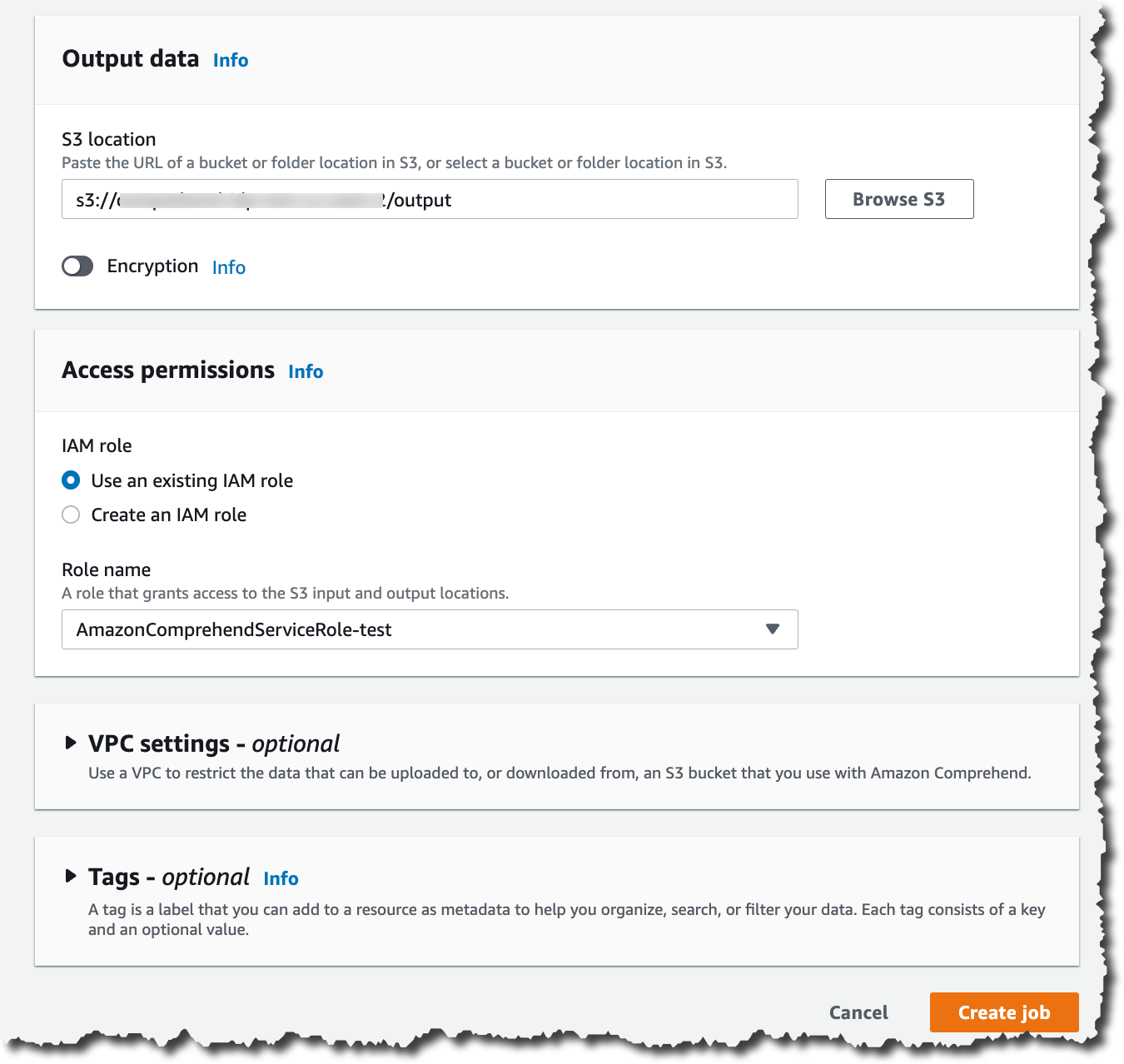
入力のサイズにもよりますが、ジョブの実行には数分かかります。ジョブの準備ができたら、出力結果を確認できます。結果は、ジョブを作成したときに指定した Amazon S3 ロケーションで確認できます。
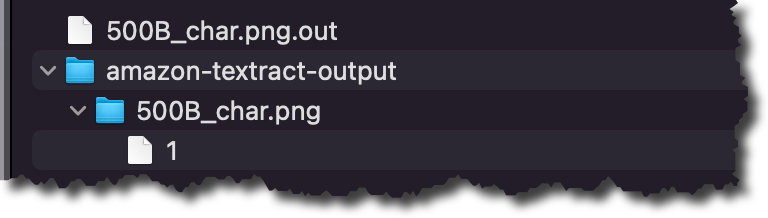
結果フォルダーには、Amazon Comprehend が分類した各半構造化ファイルの.out ファイルがあります。.out ファイルは JSON で、各行がドキュメントのページを表します。amazon-textract-output ディレクトリには、分類されたファイルごとにフォルダーがあり、そのフォルダー内には、元のファイルの 1 ページに 1 つのファイルがあります。これらのページファイルには分類結果が含まれています。分類の出力について詳しくは、ドキュメントページを確認してください。
今すぐご利用いただけます
Amazon Comprehend が利用可能なすべてのリージョンで、Amazon Comprehend を使用して、PDF、画像、ワードドキュメントなどの半構造化ファイルからのエンティティの分類と抽出を非同期かつ同期的に始めることができます。この新しいリリースの詳細については、Amazon Comprehend 開発者ガイドをご覧ください。
– Marcia
原文はこちらです。