Amazon Web Services ブログ
Amazon SageMakerでのディープラーニング学習時における、GPUパフォーマンスチューニングのためのI/O最適化
GPUはディープラーニングの学習スピードを著しく向上させ、学習にかかる時間を数週間からほんの数時間へと短縮させる可能性があります。しかし、GPUを使用する恩恵を十分に得るためには以下の点を考慮する必要があります。
- 基盤となるハードウェアを十分に稼働させるためのコードの最適化
- 最新の高性能なライブラリとGPUドライバの使用
- GPUの計算と一致する速度でデータがGPUに供給されるためのI/Oとネットワーク操作の最適化
- マルチGPUもしくは分散学習の際のGPU間の通信の最適化
Amazon SageMakerは開発者とデータサイエンティストがあらゆる規模で迅速かつ簡単に機械学習(ML)モデルをビルド、学習、デプロイするためのフルマネージドサービスです。この記事では、インフラ基盤やディープラーニングフレームワークに関わらず、Amazon SageMakerでの学習時におけるGPUパフォーマンスの最適化に関して、I/Oの改善の一般的なテクニックに焦点を当てます。典型的には、I/Oの処理ルーチンを最適化するだけで、GPUを用いた学習全体で最大10倍のパフォーマンス向上がみられます。
基本事項
1台のGPUは毎秒数兆回(TFLOPS)の浮動小数点演算をおこなうことができ、CPUの10〜1000倍の速度に相当します。GPUでこれらの演算を適切に実行するためには、データがGPUのメモリー上に乗っている必要があります。GPUにデータを高速にロードすればするほど、GPUは素早く処理をおこなうことができます。課題は、GPU演算時にデータの到着を待つことのないようI/Oもしくはネットワーク操作を最適化することです。
次の図はI/Oの最適化のアーキテクチャを示しています。

通常、データをGPUメモリに送る際の一般的なステップは以下の通りです。
- ネットワークオペレーション – Amazon Simple Storage Service (Amazon S3)からデータをダウンロードします。
- ディスクI/O – ローカルディスクからCPUメモリにデータを読み込む。ローカルディスクとはインスタンスストアのことを指しており、ホストコンピュータに物理的に接続されたディスク上にストレージが配置されています。Amazon Elastic Block Store (Amazon EBS) ボリュームはローカルのリソースではなく、ネットワークオペレーションを含むことに注意します。
- データ処理 – 一般的に、CPUはデータ変換やサイズ変更などのデータのあらゆる前処理をおこないます。これらの処理は画像やテキストをテンソルやリサイズされた画像に変換することを含みます。
- GPUメモリへのデータ転送 – 処理されたデータをCPUメモリからGPUメモリへコピーします。
次のセクションでは、各ステップにおける最適化について見ていきます。
ネットワークを介したデータダウンロードの最適化
このセクションでは、ネットワークオペレーションを介したデータ転送の最適化のヒントについて見ていきます。例えば、S3からのデータのダウンロードやAmazon EBSやAmazon ElasticFile System (Amazon EFS) の使用です。
ファイルサイズの最適化
Amazon S3を使えば大容量のデータを低コストで保存することができます。これにはETLプロセスを通じてアプリケーションデータベースからJSONやCSVフォーマットもしくは画像ファイルへと抽出されたデータを含みます。Amazon SageMakerが行う最初のステップの一つはAmazon S3からファイルをダウンロードすることです。これは、デフォルトのインプットモードで”ファイルモード”と呼ばれます。
たとえ並列処理をおこなったとしても、非常に小さなファイルをダウンロードしたりアップロードすることは、総量として同じサイズの大きなファイルを送るよりも遅くなります。もしサイズが5KBのファイルが200万個あったとき(トータルサイズは10GB = 2,000,000 X 5 * 1024)、このようなたくさんの小さなファイルをダウンロードするのには数時間かかることもあります。対照的に、5MBのファイルを2000個ダウンロードする場合(この場合もトータルサイズは10GB = 2,000 X 5 * 1024 * 1024)は数分で済む場合もあるでしょう。
このようなデータ転送の速度差の主な原因の一つは、読み込み/書き出しのブロックサイズにあります。大きなファイルと小さなファイルの場合で、転送に用いられるスレッドの総容量と数が概ね等しいと仮定します。その場合、もし転送ブロックサイズが128KBでファイルサイズが2KBの時、128KBの転送が一回で行えるのにもかかわらず、2KBしか転送することができません。
一方で、ファイルサイズが大きすぎる場合、異なるブロックを並列でダウンロードするためにAmazon S3の”range gets“と呼ばれるようなオプションを使わない限り、高速にアップロードやダウンロードするための並列処理の恩恵を受けることができません。
このようなトレードオフを避けるために、MXNet RecordIOやTFRecordのようなフォーマットを用いることで複数の画像ファイルを一つのファイルに圧縮・高密度化することができます。例えば画像に対するMXNet RecordIOでは、少なくとも一つのミニバッチがCPU/GPUメモリーに乗るように画像をリサイズし、さらに複数の画像を単一のファイルになるように高密度に充填することを推奨しています。これによって小さなファイルに対するI/O操作がボトルネックとなることが避けられます。
一般論として、最適なファイルサイズは1-128MBです。
大規模データセットに対するAmazon SageMakerでのShardedByS3Keyと呼ばれるAmazon S3のデータ分散
分散学習の実行時に非常に大きなデータセットを様々なインスタンス間で共有することができます。Amazon SageMakerの学習ジョブでこれを行うには、S3DataDistributionTypeパラメータをShardedByS3Keyにセットします。Amazon S3の入力データセットが全体でM個のオブジェクトを持ち学習ジョブがN個のインスタンスである場合、このモードではそれぞれのインスタンスがM/N個のオブジェクトを扱います。詳細はS3DataSourceを参照してください。このユースケースでは各マシンのモデル学習は学習データのサブセットしか扱えません。
大規模データセットに対するAmazon SageMakerのパイプモード
上述したSageMakerの(デフォルトである)ファイルモードとは対照的に、パイプモードでは初回に大容量のデータを学習インスタンスのディスクにダウンロードする必要はなく、Amazon S3から学習インスタンスに直接大容量のデータをストリーミングすることができます。パイプモードでは、ダウンロードの完了を待たずにデータにアクセスし、コードを実行することが可能です。なぜならデータは学習インスタンス上のディスクにダウンロードせず、メモリ内の比較的小さな領域にのみ保持されるからです。データは各エポックを通してAmazon S3から継続的にダウンロードされます。この方式はCPUメモリーに乗らないような非常に大規模なデータセットに対してとてもよく機能します。ストリーミングされ利用可能になった未加工の部分的なバイト列の利点を活かすには、(CSVのような)レコードフォーマットに依存しているバイト列をデコードし、部分的なバイト列を論理的なレコードへと変換するためにレコードの終端を見つけるコードを書く必要があります。Amazon SageMaker TensorFlowは、テキストファイルやTFRecordのような一般的なフォーマットのためのビルトインのパイプモード用データリーダーを提供しています。詳細は「Amazon SageMakerにTensorFlowコンテナにおけるバッチ変換機能とパイプ入力モードが追加」を参照してください。ビルトインのデータリーダーがないようなフレームワークやライブラリを使う場合は、パイプモードを使うためにML-IOライブラリを使うか自前のデータリーダを作成する必要があるかもしれません。
パイプモードによるストリーミングで他に考慮すべきことはデータをシャッフルすることです。Amazon S3 key prefixのマッチの結果、もしくはマニフェストファイルおよび拡張マニフェストファイル中のテキスト行をシャッフルするために、ShuffleConfigを用いるとよいでしょう。もし単一の大きなファイルを用いる場合、Amazon SageMakerではこれらのシャッフルは期待できません。そのような場合には、データを”N”個のバッチとして先読みして、使用するMLフレームワークに応じた形でシャッフルするようなコードを自身で書く必要があります。
もしCPUメモリに完全なデータセットを乗せることができるのでれば、ファイルモードがパイプモードよりも有効です。なぜならデータを一括でディスク上にダウンロードし、一括でメモリーにロードすれば、全エポックに渡ってメモリーからデータを読み出せばよいからです。メモリからの読み込みはネットワークI/Oよりも十分に早いので、よりよいパフォーマンスを達成することができます。
次のセクションでは非常に大きなデータセットをどのように扱うかについて議論します。
大規模データセットのためのAmazon FSx for LustreおよびAmazon EFS
非常に大規模のデータセットの場合、分散ファイルシステムを用いることでAmazon S3のダウンロード時間を減らすことができます。
Amazon SageMakerでAmazon FSx for Lustreを使えば、Amazon S3内のデータを保ちつつスタートアップ時間を減らすことができます。詳細は「AmazonFSx for LustreとAmazon EFSファイルシステムを用いたAmazon SageMakerにおける学習の高速化」を参照ください。
トレーニングジョブの初回実行時、FSx for LustreはデータをAmazon S3から自動的にコピーし、Amazon SageMakerが使える状態にします。加えて、Amazon SageMakerの学習ジョブのその後の繰り返しに対しても同じFSx for Lustreを使うことができるため、共通するAmazon S3オブジェクトの再ダウンロードを避けることができます。このような特性があるため、学習セットがAmazon S3上にあり、最適な結果を得るために異なる学習アルゴリズムやパラメータを用いて繰り返し学習を行うようなワークフローの時に、FSx for Lustreは最適な結果をもたらします。
もし学習データがAmazon Elastic File System (Amazon EFS) 上にすでにある場合、Amazon EFSをAmazon SageMakerとともに使うことができます。詳細は「AmazonFSx for LustreとAmazon EFSファイルシステムを用いたAmazon SageMakerにおける学習の高速化」を参照ください。
このオプションを用いる時に考慮することはファイルサイズです。ファイルサイズが非常に小さい場合、転送ブロックサイズのような要因によってI/Oパフォーマンスが低下することがあります。
ローカルNVMe-based SSDストレージを用いたAmazon SageMakerインスタンス
Amazon SageMaker GPUインスタンスのいくつか、例えばml.p3dn.24xlargeやml.g4dnはEBSボリュームのかわりにローカルNVMe-based SSDストレージを提供しています。一例として、ml.p3dn.24xlargeインスタンスは1.8TBのローカルNVMe-based SSDストレージを搭載しています。ローカルNVMeベースのSSDを使うことで、学習データをAmazon S3からローカルディスクストレージにダウンロードした後のI/O速度が、EBSボリュームやAmazon S3のようなネットワークリソースから読み込むよりも圧倒的に速くなります。これによって、学習データサイズがローカルNVMeベースのストレージに収まるときに学習時間を高速化することができます。
データのロードと前処理の最適化
これまでのセクションで、Amazon S3のようなソースからデータをどう効率的にダウンロードするかについてお話しました。このセクションでは、どのように並列性を向上させるか、またデータのロードをより効率的にするためにできるだけ無駄のない汎用的な関数を作る方法について議論します。
データのロードと処理に関する複数のワーカー
TensorFlow, MXNet Gluon、そしてPytorchはデータの読み込みを並列化するためのデータローダライブラリを提供しています。次のPyTorchの例では、ワーカーの数を増やせば増やすほど、より多くのワーカーが並列にアイテムを処理するようになっています。一般論として、ワーカーの数は単一のワーカーからCPUのコア数よりおおむね一個少ない数までスケールアップさせることができます。一般的に、それぞれのワーカーが一つのプロセスを代表してPythonマルチプロセスを使いますが、その実装の詳細はフレームワークごとに異なります。マルチプロセッシングを使うことでPythonのグローバルインタプリタロック(GIL)を回避し、全てのCPUを並列に用いることができますが、それぞれのプロセスがメモリにオブジェクトのコピーを保つため、メモリの消費量がワーカーの数に比例して増えていきます。ワーカーの数を増やしていった時にメモリ不足の例外処理を見ることがあるかもしれませんが、そのような場合はCPUメモリをより多く搭載したインスタンスを使うべきです。
複数のワーカーを用いる効果を理解するために以下のデータセット例を紹介します。このデータセットでは、__get_item__オペレーションは次のレコードの読み込みの際のレイテンシーを再現するために1秒待機します。
class MockDatasetSleep(Dataset):
"""
Simple mock dataset to understand the use of workers
"""
def __init__(self, num_cols, max_records=32):
super(MockDatasetSleep).__init__()
self.max_records = max_records
self.num_cols = num_cols
# Initialising mock x and y
self.x = np.random.uniform(size=self.num_cols)
self.y = np.random.normal()
print("Initialised")
def __len__(self):
return self.max_records
def __getitem__(self, idx):
curtime = datetime.datetime.now()
# Emulate a slow operation
sleep_seconds = 1
time.sleep(sleep_seconds)
print("{}: retrieving item {}".format(curtime, idx))
return self.x, self.y
例として、単一のワーカーのみをもつデータローダーインスタンスを作成します。
# One worker
num_workers = 1
torch.utils.data.DataLoader(MockDatasetSleep(), batch_size=batch_size, shuffle=True, num_workers=num_workers)単一のワーカーを用いた場合、1秒間隔でそれぞれのアイテムを受け取っていることがわかります。
15:39:58.833644: retrieving item 0
15:39:59.834420: retrieving item 6
15:40:00.834861: retrieving item 8
15:40:01.835350: retrieving item 5ワーカーの数を3つに増やします。その際、最大の並列プロセスを確保するために少なくとも4コアのCPUを用意します。下記のコードを参照してください。
# You may need to lower the number of workers if you encounter out of memory exceptions or move to a instance with more memory
num_workers = os.cpu_count() - 1
torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)このデータセット例では、3つのワーカーが3つのアイテムを並列で受け取ることを試み、ほぼ1秒の時間間隔で次の3つのアイテムを受け取っています。
16:03:21.980084: retrieving item 8
16:03:21.981769: retrieving item 10
16:03:21.981690: retrieving item 25
16:03:22.980437: retrieving item 0
16:03:22.982118: retrieving item 7
16:03:22.982339: retrieving item 21このノートブックデモ例では、約30,600枚の画像を含むCalteh-256データセットとResNet 50を用いています。Amazon SageMaker学習ジョブでは、1つのGPUと8つのvCPUを持つ単一のml.p3.2xlargeインスタンスを用いています。シングルワーカーでは、単一のGPUを用いて毎秒約100枚の画像を処理し、1エポックに260秒かかりました。7ワーカーを用いた場合、毎秒約300枚の画像を処理し、1エポックに96秒かかり、3倍の速度向上が見られました。
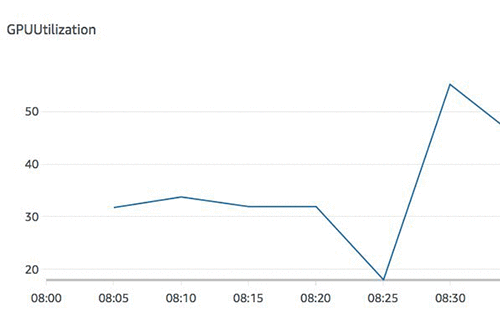
次のグラフはシングルワーカーのGPU使用率のメトリクスで、ピークで50%の使用率を示しています。
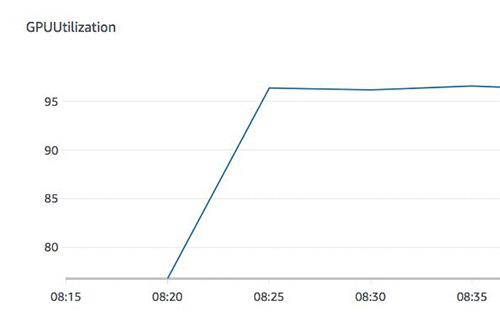
次のグラフは複数ワーカーのGPU使用率のメトリクスで、平均95%の利用率を示しています。
num_workersをほんの少し変えるだけでデータ読み込みの速度を向上させることができます。結果として、GPUがデータを受け取るための待ち時間が短くなり、学習が速くなります。これがデータローダのI/Oパフォーマンスを最適化することでGPU使用率を改善する例です。
マルチGPUやマルチホスト分散GPU学習を行うときは、先にシングルGPUでの使用率の最適化をおこなうべきです。したがって、分散学習に移行する前にシングルGPUの最大使用率を測定し最適化することは決定的に重要です。
頻繁に使用する関数の最適化
レコードアイテムを受け取る際に、計算処理負荷の高い操作を可能な限り最小にすることで、GPUやCPUの選択にかかわらず学習パフォーマンスを改善することができます。頻繁に用いる関数を様々な方法で、例えば正しいデータ構造を用いることでそのような最適化を行うことができます。
デモノートブックの例では、以下のコードのように画像ファイルをロードしてそれぞれの画像をリサイズする単純な実装になっています。Caltech256データセットを前処理して、つまり事前に画像をリサイズしpickle形式に保存しておくことで、この関数を最適化してみます。これにより、__getitem__関数は画像をランダムクロップするだけでよくなり、無駄のない関数になります。CPUがデータを前処理する間にGPUが待機する時間が短くなるため、GPUに高速にデータを供給できます。以下のコードを参照してください。
# Naive implementation
def __getitem__(self, idx):
curtime = datetime.datetime.now()
self.logger.debug("{}: retrieving item {}".format(curtime, idx))
image, label = self.images[idx], self.labels[idx]
# Convert to PIL image to apply transformations
# This could be faster if handled in a preprocessing step
image = Image.open(image)
if image.getbands()[0] == 'L':
image = image.convert('RGB')
# Apply transformation at each get item including resize, random crop
image = self.transformer(image)
self.logger.debug("{}: completed item {}".format(datetime.datetime.now(), idx))
return image, label
# Optimised implementation
def __getitem__(self, idx):
curtime = datetime.datetime.now()
self.logger.debug("{}: retrieving item {}".format(curtime, idx))
image, label = self.images[idx], self.labels[idx]
# Apply transformation at each get item - random crop
image = self.transformer(image)
self.logger.debug("{}: completed item {}".format(datetime.datetime.now(), idx))
return image, labelこの単純な変更を行うだけで、1エポックを96秒で完了させることができました。これは毎秒約300枚の画像を処理していることに相当し、シングルワーカーで最適化を行わないデータセットより3倍高速です。この状態ではデータ読み込みプロセスがもはやボトルネックではなくなるため、もしワーカー数を上げたとしてもGPU利用率にはほとんど変化がありません。
ユースケースによっては、GPU利用率を最大化させるためにワーカー数を上げることとコードを最適化することの両方を試す必要があるかもしれません。
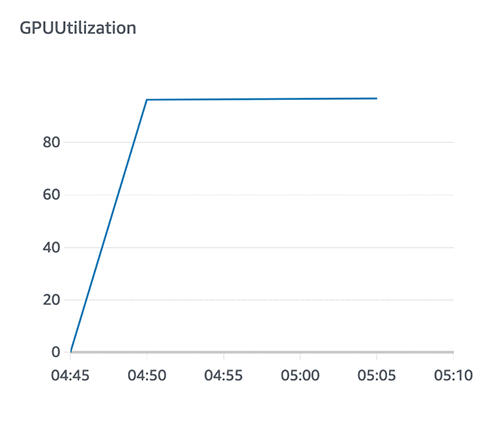
次のグラフはシングルワーカーかつ最適化されたデータセットを用いた場合のGPU利用率を示しています。
以下のグラフは最適化されていないデータセットのGPU利用率を示しています。

使用するMLフレームワークを理解する
各ディープラーニング フレームワークのデータ読み込みライブラリ(Tensorflow dataloder, MXNet, Pytorch データローダを含む)はデータ読み込みを最適化するための追加のオプションを用意していることがあります。自身のユースケースで最適に動作させるためには、データローダおよびライブラリのパラメータを理解する必要があります。また最適化にともなうトレードオフについても理解する必要があるでしょう。オプションの例をいくつか示します。
- CPU pinned memory: CPU(ホスト)メモリーからGPU(デバイス)メモリへのデータ転送を加速させます。GPUにデータを転送する際にページング領域のメモリを一旦確保してからページロック領域(すなわち”ピン留め”された)メモリにデータをコピーするのではなく、直接ページロックされたメモリを確保することでパフォーマンスが向上します。データローダでCPU pinnedメモリを可能にするオプションはPyTorchおよびMXNetで利用可能です。考慮すべきトレードオフは、ページングされたメモリを使う代わりにピン留めされたCPUメモリをリクエストする際に、メモリ超過の例外がより起きやすくなることです。
- Modin: この軽量な並列処理データフレームを用いることでPandasデータフレームに似た操作を並列して行うことができ、マシン上のCPUを持て余すことなく使用することができます。ModinはDaskやRayのような異なるタイプの並列処理に対応しています。
- CuPy: NumPyに似たこのオープンソース行列ライブラリはPythonでGPUアクセラレートコンピューティング機能を提供します。
I/Oのボトルネックを特定するためのヒューリスティックス
Amazon SageMakerでは学習時のGPU、CPUそしてディスク利用率のようなAmazon CloudWatchメトリクスを使うことができます。詳細はAmazon CloudWatch による Amazon SageMaker のモニタリングを参照してください。
Amazon CloudWatchが提供する定義済みのメトリクスを使って、I/Oに関連したパフォーマンス問題の原因を特定するためのヒューリスティックスを以下に示します。
- 学習が始まるまでに非常に長い時間がかかる場合は、ほとんどの時間をデータのダウンロードに費やしています。前述した方法でAmazon S3からのダウンロードを改善する方法を考えるべきです。
- ディスクやCPU利用率が高いにも関わらずGPU利用率が低い場合は、データ読み込みや前処理が潜在的なボトルネックとなっている可能性があります。可能ならば学習の前にデータの前処理を行った方がよいかもしれませんし、すでに示したように頻繁に使う関数を最適化することも検討してください。
- 十分大きなデータセットにも関わらず、GPU利用率が低くてCPUとディスク利用率が継続的に低い(ただしゼロではない)場合は、実装したコードがリソースを効果的に用いることができていない可能性があります。CPUメモリ利用率が低い場合、パフォーマンスを潜在的にブーストさせるクイックな方法として、使用中のディープラーニングフレームワークのデータローダAPI中のワーカー数を増やす方法があります。
結論
データ読み込みやデータ処理の基本的な性質がGPU利用率に影響を与え、I/Oやネットワークに関連したボトルネックを解決することでGPUパフォーマンスを改善できることがわかりました。マルチGPUや分散学習のような先進的なトピックに進む前に、これらのボトルネックを解決することが重要です。
Amazon SageMakerを始めるためには、以下が参考になるでしょう。
- Amazon SageMaker examples – GitHub repo
- TensorFlow – Better performance with the tf.data API
- MXNet – Designing Efficient Data Loaders for Deep Learning
- PyTorch data loader – TORCH.UTILS.DATA
著者について
Aparna Elangovan氏は、AWSの人工知能および機械学習のプロトタイプエンジニアで、お客様がディープラーニングのアプリケーションを開発する手助けをしています。
原文はこちらをご覧ください。
このブログ記事は機械学習ソリューションアーキテクトの卜部が翻訳しました。