Amazon Web Services ブログ
Amazon SageMaker を使って新しいユーザーにリアルタイムで配信する音楽レコメンデーション
この記事は、iHeartRadio 社の Matt Fielder 氏および Jordan Rosenblum 氏による寄稿の Real-time music recommendations for new users with Amazon SageMaker を翻訳したものです。おふたりの言葉を借りると、「iHeartRadio は、毎月数千万人の人に配信しており、また、数万人の新規登録者を日々集めているオーディオストリーミングサービスです。」とのことです。
パーソナライゼーションはユーザー体験の中でも重要な位置を占めています。そして当社としても、お客様の使用履歴の早い段階で、有用なレコメンデーションを提供したいと強く希望しています。音楽作品の提案をユーザー登録直後に表示することで、当社のサービスがお客様の好みに素早く対応可能であり、その中で色々と探し回る必要はそれほどないのだと伝えられます。しかし、まだ視聴をまったく開始していないユーザーに対し、どうやってコンテンツの提案をしているのか、ご関心をお持ちの方もいらっしゃるでしょう。

この記事では、当社がリアルタイムのパーソナライズサービスを実現するために、ユーザーの方が登録の際に提供してくださる情報を、いかに活用しているかを説明します。新規のお客様には音楽視聴に関する記録がまったくありませんが、通常はサービス参加の段階で、一定数の好みジャンルを選択し、ご自身についての統計学的な情報を提供してくれるものです。ここではまず、当社がパーソナライゼーションに使用している有益なパターンを含む、それらの属性の分析をお見せします。次に、そういったデータを、新規のお客様それぞれに最良の音楽を予測するため使用しているモデルについて説明しいきます。最後に、登録直後に Amazon SageMaker を使用してこれらの予測をリアルタイムのレコメンデーションとして提供する方法を紹介します。これは、A/B テストにおけるユーザーエンゲージメントでの大幅な向上につながります。
新規ユーザーの視聴パターン
モデル構築を始める前に、ヒントとなり得る情報が含まれそうな特別なパターンが、データの中に存在するかを確認しておく必要があります。
最初に挙げられる仮説は、統計学的に違う背景をもつ人々は、それぞれ別のタイプの音楽を好むはずだということです。たとえば、まったく同じ環境にいたとしても、50 歳の男性は、25 歳の女性よりクラシックロックを聴く確率は高そうだといえます。仮に、平均的な意味で、このことの中に何らかの真実が存在するならば、有用なレコメンデーション作成のためにユーザーの方が視聴履歴を残すのを待つ必要はないことになります。ユーザー登録の際に提供していただく、統計的な情報を活用するだけで十分でしょう。
この点の分析を行うため、ユーザー登録から 2 か月経過した方の視聴行動に着目し、それを、同じ方から登録の時にご提供いただいた情報に照らし合わせてみることにしました。この 2 か月というギャップにより、既にコンテンツの中をいろいろ試しているアクティブなユーザーに対し確実に焦点を絞れます。この時期になれば、その方がどのような好みであるのかは、かなり明白になっていると思われます。同時に、サービス参加時やマーケティングの初期段階に存在したノイズも、すでに低減しているはずです。
次の図では、あるユーザーの方が、登録から 2 か月間にとった視聴行動についてのタイムラインを示しています。

次に、新規の男性ユーザーと新規の女性ユーザーを対比して、視聴するジャンルにおける分布を比較します。この結果から、音楽の好みには統計的情報と関連があるパターンが存在するという、先の仮説が立証できます。たとえば、スポーツやニュース、そしてトークショーなどは、男性の間でより人気があることが読み取れるでしょう。このデータは、特に視聴履歴をまだ残していないユーザーの方に対するレコメンデーションを向上でき得るものだといえます。
次に示すグラフでは、ユーザーの性別と好みのジャンルの関連性を大まかに示しています。

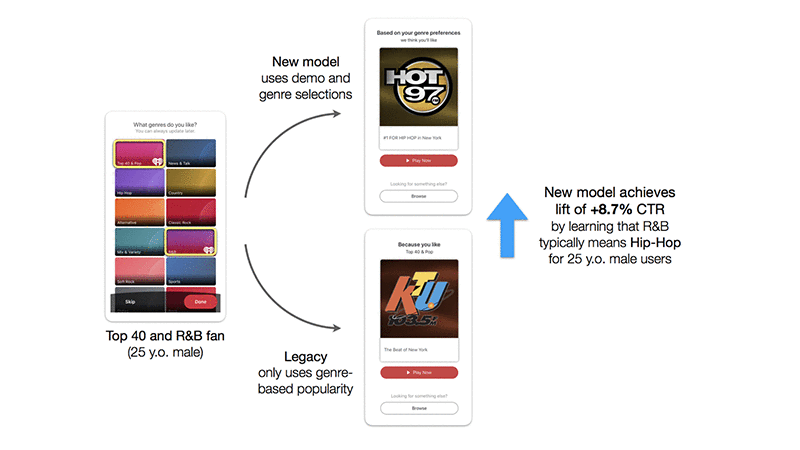
2 つめに挙げられる仮説は、同じ好みを持つユーザーの方達でも、探しているジャンルを違った表し方をするということです。さらにいうと、iHeartRadio ではジャンルの分類に対し、ユーザーの方々が認識しているものと比べて少し違う定義をしています。当然これは、一定のジャンルに関する 分析の 1 つの論拠となり得ます。たとえば、実際には当社内部で Hip Hop として分類しているものをお聞きの多くの方が、好みの音楽は R&B だとおっしゃることがあります。このことは、同じジャンルに対してでも、ユーザーの方はそれぞれ別の定義をしているという意味で、ジャンルとういものが持ついくぶん主観的な特性も示しています。
ジャンルの予測
さて、統計情報とジャンルの好みが、新規ユーザーの行動を予測する上で有用であるという分析的な確証がある程度得られたので、モデルの構築とテストに着手することにします。モデルには、統計的背景とジャンルの好みがいかに視聴行動と関係性があるかを、システム的に学習してくれることが期待されます。もし上手くいけば、新しいユーザー様が当社のプラットフォームのご利用を開始する際に、適切なジャンル分けでコンテンツを提示するため、そのモデルが利用できるでしょう。
分析段階においては、サインアップから 2 か月経ったユーザーの方が自然と選択するであろうコンテンツを提示できる、見本の予測方法を人間が定義します。結果に求めるのは、モデル用のトレーニングデータをご提供いただいた方が、当社のアプリのコンテンツを開くのに時間を割くような、活発なユーザー様となることです。従って、目標変数は、登録 2 か月後にユーザーの方が最も視聴するジャンルになります。また、その方の統計的な背景と登録段階で選択されたジャンルの組合せを特徴量として使用します。
今回もその開始時点では、多くのモデリング作業と同じく、最も基本的なモデリングテクニックである、マルチラベルのロジスティック回帰分析を使用します。トレーニングするモデルでの特徴係数のサンプリング結果と、次のヒートマップに示している視聴結果がそれらの値との間に持つ関連性とを分析します。統計学的ではないモデルは、ユーザーの方が登録の際に選択したジャンルに関するマルチホットエンコーディングを備えています。より明るい色 (より重みがある) のスクエアは、よりモデルの特徴量との関連性があり、これは、ユーザーが登録から 2 か月後に視聴しているジャンルと関係します。

明らかにここからは、いくつかの初期パターンを見出すことができます。1 つめとして、全体的にみると、ユーザーが 1 つのジャンルのみを選択している場合、結局そのジャンルを聴き続けるという点です。その一方、たとえばキッズ & ファミリーとか、Mix & バラエティー、あるいは R&B など一定のジャンル数を選択したユーザーの方においては、現れるトレンドはもっと控え目になります。2 つめのパターンは年齢に関する興味深いもので、若年層のユーザーにはトップ 40 & ポップスとかオルタナティブを好む傾向があるのに対し、年齢層が高い人は、インターナショナル、ジャズ、ニュース & トーク、そして公共ラジオなどを好むということを、今回のモデルが学習した点です。3 つめとして我々を感嘆させたのは、このモデルが、クラシック音楽を選択するユーザーの方は、同時に、ワールド音楽、公共ラジオ、国際といったジャンルを聴く傾向があると特定した点です。
この機能が、視聴行動といかに関連しているかを検証することは有用ですが、ロジスティック回帰分析にはいくつかの欠点も存在します。おそらく最も重要なのは、このモデルは 1 つ以上のジャンルが選択された場合を、自然な形で解釈しない点でしょう。何故なら、リニアモデルにおける相互性は暗黙的に加算だからです。別の言い方をすると、このモデルは、ジャンル選択間で適切に重みをつけることができません。当社にとってこれは厄介な問題です。つまり、ジャンルの好みが見て取れるユーザーは通常 1 つ以上のジャンルを選択するからで、平均の選択数は概ね 4 つ程度になります。
そこで、ツリーベースモデルやフィードフォワードニューラルネットワークなど、ロジスティック回帰分析の短所を埋め合わせるだろう、いくつかの先進的なテクニックも試してみました。ツリーベースモデルには、ニューラルネットワークと比べて複雑性に難があるものの、結果としては最良のものが得られています。このモデルでは、ロジスティック回帰分析と比較して十分な改善と、トレーニング用セットを過学習しづらいという特徴も確認できました。私たちは最終的に、速度、過学習を防止する能力、そして優れたパフォーマンスに基づいて、LightGBM を使用することにしました。
このモデルでのオフラインメトリクスが、当社のシンプルな基準に比べ、かなり良い結果を出すことに本当に感心しています。ユーザーに対するレコメンデーションの基準は、ジャンルの中で彼らが最も選択したものです。これには、統計的な属性は考慮されておらず、当社でも、歴史的にアプリのコンテンツカルーセルを、この方式で作成してきました。オフラインの履歴データに基づき、モデルが推薦する 3 つのジャンルを新規のユーザー様に提案することは、その時の彼らの真の好みを 77% 程度捉えることを可能にします。これは、基準レベルに比べたときの 15% の向上分に相当します。
予測をリアルタイムで表示する
さて、使い物になりそうなモデルが手に入ったところで、その予測をリアルタイムで表示させる方法を考えます。 これまで iHeartRadio では、ほとんどのモデルのトレーニングとスコア付けが Airflow を使用して一括 (日次、週次など) で行われており、これらは Amazon DynamoDB といった key-value データベースから提供されていました。しかしながら、今回の新しいレコメンデーションでは、スコア付けした値のみが提供され、配信はリアルタイムです。ユーザー登録の直後から、その時得られた情報に基づき適切な推薦ジャンル予測を提供できるようにしなければならず、もちろん、その情報は事前入手は不可能です。このレコメンデーションを用意するのに 1 日かかってしまうようでは遅すぎます。ここに、Amazon SageMaker が活躍する場所があります。
Amazon SageMaker を使うと、リアルタイムのモデルエンドポイントをホスティングでき、これにより、ユーザーが登録を完了した直後から予測を提供することが可能です。これにはさらに、モデルトレーニング用の便利な機能も備わっています。モデルのデプロイにもいくつかのオプションがあり、組み込み済みのアルゴリズムコンテナ (たとえば、ランダムフォレストや XGBoost など) を使用する場合から、構築済みコンテナイメージの使用、そのイメージを拡張しての使用、あるいはカスタムのコンテナイメージを構築する、といったこともできます。今回は、最後のオプションである、独自アルゴリズムをカスタムイメージにパッケージするという手法を選択しました。この執筆時点で、LightGBM 用の組み込み済みアルゴリズムコンテナが存在しないためであり、結果的に、最大の柔軟性を得ることができました。このため、独自のスコアリングコードをパッケージ化して、モデルスコアリングのために Amazon Elastic Container Registry (Amazon ECR) にプッシュされる Docker イメージを構築しました。
Amazon SageMaker エンドポイントを Amazon API Gateway の背後にマスクしておいて、外部クライアントがレコメンデーションのためにこれを ping できるようにする一方、Amazon SageMaker バックエンドはプライベートネットワーク内に置いて安全性を確保しました。パラメータの値は、API Gateway から AWS Lambda 関数に手渡され、そこで解釈された後、その値は Amazon SageMaker エンドポイントに送信されモデルの出力となります。Amazon SageMaker では、ボリュームやトラフィックに基づき、モデルスコアリング用インスタンスを自動的にスケーリングできます。定義する必要があるのは、各インスタンスに送りたい毎秒のリクエスト数と、スケールアップするインスタンスの最大数のみです。これにより、iHeartRadio 全体であらゆる種類のユースケースに、このエンドポイントの利用をロールアウトすることが容易になります。10 日間のテスト中、このエンドポイントは呼び出しエラーを 1 度も発生せず、平均的なモデルレイテンシーは、概ね 5 msec でした。
Amazon SageMaker の詳細については、「Amazon SageMaker で独自のアルゴリズムやモデルを使用する」、「Amazon SageMaker Bring Your Own Algorithm Example」、および「Call an Amazon SageMaker model endpoint using Amazon API Gateway and AWS Lambda」を参照してください。
オンラインでの使用結果
ここまでで、今回のモデルがオフラインでは上手く機能したことを示しましたが、アプリ製品に載せてのテストも行わなければなりません。このテストでは、 Amazon SageMaker でモデルのホスティングを行い、登録完了直後のアプリ上のメッセージとして、新規ユーザーの方に関連するラジオ局を推薦してみました。このモデルを、ユーザーが選択したジャンルの中から最も人気があるラジオ局を 1 つ選んで単純に推薦するというビジネスルールと比較します。均等に分けたグループ間での A/B テストを 10 日間行いました。そして、モデル予測をクリックしたユーザーグループでは、そのラジオ局でのクリックスルーレートが 8.7% 高くなることが確認できたのです。 くわえて、このクリックをしたユーザーの方においては、視聴時間も長くなると分かりました。
次の図に、基準より 8.7% CTR を向上させたリアルタイム予測の結果と、A/B テストのグループとはどのようなものになるのかを示します。
次のステップと将来の予定
ここまでで、Amazon SageMaker エンドポイントでホスティングされたジャンル予測モデルが配信する関連コンテンツに、新規ユーザーが反応を示すことを示してきました。この初期段階のコンセプト確認では、新規登録者の範囲だけに使用した例をご紹介しました。次のステップには、さらに広いユーザー層へのこのテスト結果の拡張と、まったく視聴履歴がないに等しい新規ユーザー向けのコンテンツカルーセルに、このレコメンデーションをデフォルト表示させることが含まれます。また、さまざまなコンテンツカルーセルやタイルをアプリ全体で配置するといった、他のパーソナライゼーションユースケースにも、このタイプのモデルとリアルタイム予測を拡張できればと考えております。最後に、この記事で取り上げた Amazon SageMaker だけでなく FastAPI のような、リアルタイムでのモデル予測配信をシームレスに行える技術について、当社では現在も継続的に研究中であることも付け加えておきます。
データサイエンスとデータエンジニアリングのチーム、特に Brett Vintch 氏と Ravi Theja Mudunuru 氏には、Amazon SageMaker POC 全体のテストに関するサポートならびに、この記事への有益なフィードバックをいただけたことへの謝意を表したいと思います。この記事は、iHeartMedia の Medium でもお読みいただけます。
著者について
Matt Fielder 氏は iHeartRadio の EVP エンジニアです。
Jordan Rosenblum 氏は iHeartRadio Digital のシニアデータサイエンティストです。