Amazon Web Services 한국 블로그
Amazon MSK, Kinesis Data Firehose를 통해 Kafka 토픽 S3 전송 기능 출시
오늘 Amazon Managed Streaming for Apache Kafka(Amazon MSK)의 새로운 기능인 Apache Kafka 클러스터에서 Amazon Simple Storage Service(S3)으로 데이터를 지속적으로 로드할 수 있는 기능을 발표합니다. 이제 추출, 전환, 적재(ETL) 서비스인 Amazon Kinesis Data Firehose를 사용하여 Kafka 주제에서 데이터를 읽고 레코드를 변환하며 Amazon S3 대상에 씁니다. Kinesis Data Firehose는 완전 관리형으로 콘솔에서 몇 번의 클릭만으로 구성할 수 있습니다. 코드나 인프라가 필요하지 않습니다.
Kafka는 일반적으로 시스템 또는 애플리케이션 간에 대량의 데이터를 안정적으로 옮기는 실시간 데이터 파이프라인 구축에 사용됩니다. 확장성이 뛰어나고 내결함성이 있는 게시/구독 메시징 시스템을 제공합니다. 많은 AWS 고객은 Kafka를 도입하여 클릭스트림 이벤트, 트랜잭션, IoT 이벤트, 애플리케이션 및 머신 로그 같은 스트리밍 데이터를 캡처하는 기능과 실시간 분석을 수행하고, 지속적인 변환을 실행하고, 이 데이터를 데이터 레이크 및 데이터베이스에 실시간으로 배포하는 애플리케이션을 제공합니다.
그러나 Kafka 클러스터 배포에 어려움이 없는 것은 아닙니다.
첫 번째 과제는 Kafka 클러스터 자체의 배포, 구성 및 유지 관리입니다. 때문에 2019년 5월에 Amazon MSK를 출시했습니다. MSK는 프로덕션 환경에서 Apache Kafka를 설정, 확장 및 관리하는 데 필요한 작업을 줄여줍니다. 인프라를 관리하므로 사용자는 데이터와 애플리케이션에 집중할 수 있습니다.
두 번째 과제는 Kafka의 데이터를 사용하는 애플리케이션 코드의 작성, 배포 및 관리입니다. 일반적으로 Kafka Connect 프레임워크를 사용하여 커넥터를 코딩한 다음 커넥터를 실행하기 위한 확장 가능한 인프라를 배포, 관리 및 유지 관리해야 합니다. 인프라 외에도 데이터 변환 및 압축 로직을 코딩하고, 최종 오류를 관리하며, Kafka에서 전송하는 동안 데이터가 손실되지 않도록 재시도 로직을 코딩해야 합니다.
오늘 Amazon Kinesis Data Firehose를 사용하여 Amazon MSK에서 Amazon S3로 데이터를 전송하는 완전 관리형 솔루션의 출시를 발표합니다. 이 솔루션은 서버리스이므로 관리할 서버 인프라가 없으며 코드가 필요하지 않습니다. 콘솔에서 클릭 몇 번으로 데이터 변환 및 오류 처리 로직을 구성할 수 있습니다.
이 솔루션의 아키텍처는 다음 다이어그램으로 설명할 수 있습니다. Amazon MSK는 데이터 소스이고, Amazon S3는 데이터 대상이며, Amazon Kinesis Data Firehose는 데이터 전송 로직을 관리합니다.
Amazon MSK는 데이터 소스이고, Amazon S3는 데이터 대상이며, Amazon Kinesis Data Firehose는 데이터 전송 로직을 관리합니다.
이 새로운 기능을 사용하면 더 이상 Amazon MSK에서 데이터를 읽고, 변환하며, 결과 레코드를 Amazon S3에 쓰는 코드를 개발할 필요가 없습니다. Kinesis Data Firehose는 Amazon S3에 대한 읽기, 변환 및 압축, 쓰기 작업을 관리합니다. 또한 문제가 발생할 경우 오류 및 재시도 로직을 처리합니다. 시스템은 수동 검사를 위해 사용자가 선택한 S3 버킷으로 처리할 수 없는 레코드를 전달합니다. 또한 시스템은 데이터 스트림 처리에 필요한 인프라도 관리합니다. 전송할 데이터의 양에 맞게 자동으로 스케일 아웃 및 스케일 인합니다. 사용자 측에서는 프로비저닝이나 유지 관리 작업이 필요하지 않습니다.
Kinesis Data Firehose 전송 스트림은 퍼블릭 및 프라이빗 Amazon MSK 프로비저닝 또는 서버리스 클러스터를 모두 지원합니다. 또한 MSK 클러스터에서 읽고 다른 AWS 계정의 S3 버킷에 쓸 수 있는 계정 간 연결을 지원합니다. Data Firehose 전송 스트림은 MSK 클러스터에서 데이터를 읽고, 구성 가능한 임계값 크기 및 시간만큼 데이터를 버퍼링한 다음 버퍼링된 데이터를 Amazon S3에 단일 파일로 씁니다. MSK와 데이터 파이어호스는 동일한 AWS 리전에 있어야 하지만 데이터 파이어호스는 다른 리전의 Amazon S3 버킷으로 데이터를 전송할 수 있습니다.
Kinesis Data Firehose 전송 스트림은 데이터 유형을 변환할 수도 있습니다. JSON을 Apache Parquet 및 Apache ORC 형식으로 지원하는 변환 기능이 내장되어 있습니다. 이는 Amazon S3에서 스페이스를 절약하고 더 빠른 쿼리를 구현하는 컬럼형 데이터 형식입니다. JSON이 아닌 데이터의 경우 AWS Lambda를 사용해 데이터를 Apache Parquet/ORC로 변환하기에 앞서, CSV, XML 또는 구조화된 텍스트와 같은 입력 형식을 JSON으로 변환할 수 있습니다. 또한 데이터를 Amazon S3로 전송하기 전에 데이터 파이어호스에서 GZIP, ZIP, SNAPPY 등의 데이터 압축 형식을 지정하거나 데이터를 원시 형식으로 Amazon S3에 전송할 수 있습니다.
작동 방식
시작하려면 Amazon MSK 클러스터가 이미 구성되어 있고 데이터를 스트리밍하는 애플리케이션이 있는 AWS 계정을 사용합니다. Amazon MSK 클러스터를 시작하고 처음 생성하려면 자습서를 읽어 보시기 바랍니다.
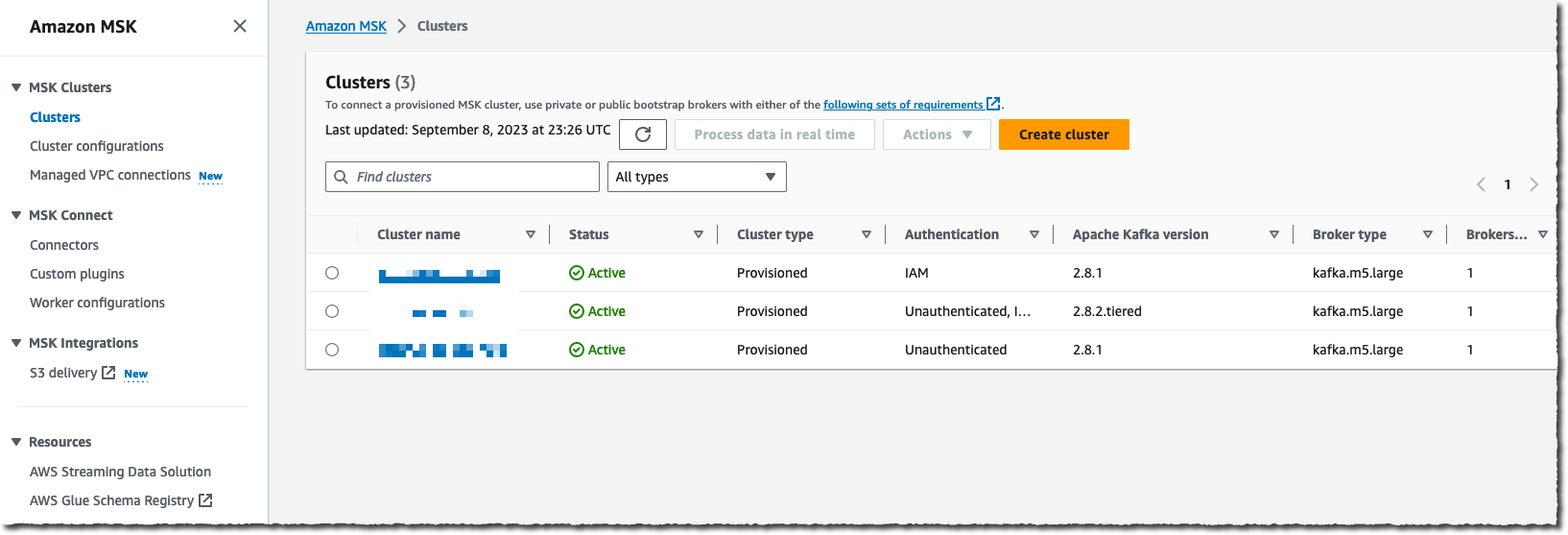
이 데모에서는 콘솔을 사용하여 데이터 전송 스트림을 생성 및 구성합니다. 또는 AWS Command Line Interface(AWS CLI), AWS SDKs, AWS CloudFormation 또는 Terraform을 사용할 수 있습니다.
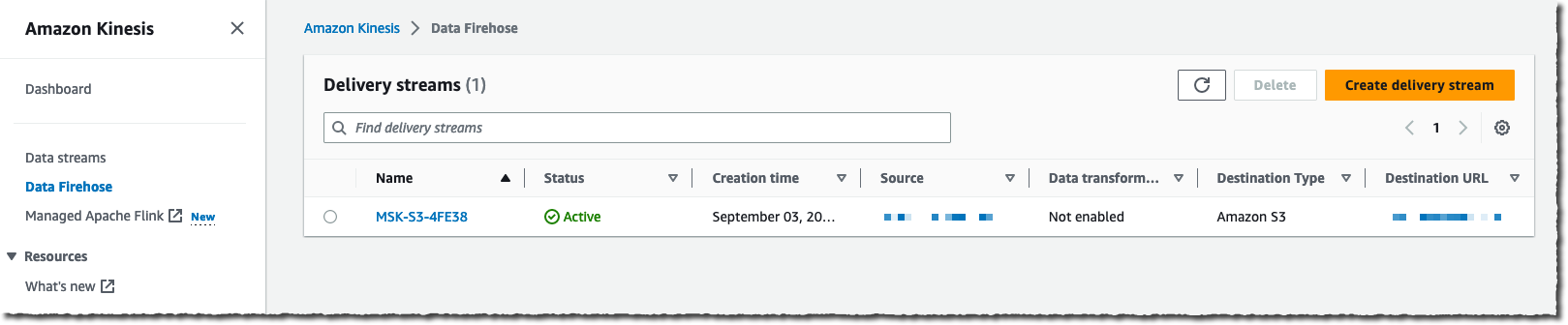
Amazon Kinesis Data Firehose 페이지를 AWS Management Console에서 탐색한 다음 전달 시스템 생성을 선택합니다.
Amazon MSK를 데이터 소스로 선택하고 Amazon S3를 전송 목적지로 선택합니다. 이 데모에서는 프라이빗 클러스터에 연결하고 싶기 때문에 프라이빗 부트스트랩 브로커를 Amazon MSK 클러스터 연결에서 선택합니다.
클러스터의 전체 ARN을 입력해야 합니다. 대부분의 사람들처럼 저도 ARN이 기억나지 않아 찾아보기를 선택하고 목록에서 클러스터를 선택합니다.
마지막으로 이 전송 스트림에서 읽을 클러스터 주제 이름을 입력합니다.

소스를 구성한 후 페이지를 아래로 스크롤하여 데이터 변환 섹션을 구성합니다.
레코드 변형 및 변환 섹션에서 자체 Lambda 함수를 제공하여 JSON 형식이 아닌 레코드를 변형할지 여부 또는 제 소스 JSON 레코드를 두 가지의 가용 내장 대상 데이터 형식 중 하나로 변환할지 여부를 선택할 수 있습니다(Apache Parquet 또는 Apache ORC).
Apache Parquet 및 ORC 형식은 Amazon S3에서 데이터를 쿼리하는 데 JSON 형식보다 더 효율적입니다. 원본 레코드가 JSON 형식인 경우 이러한 대상 데이터 형식을 선택할 수 있습니다. 또한 AWS Glue의 테이블에서 데이터 스키마를 제공해야 합니다.
이러한 기본 제공 변환은 Amazon Athena, Amazon Redshift Spectrum 또는 기타 시스템에서 다운스트림 분석 쿼리를 수행할 때 Amazon S3 비용을 최적화하고 통찰력을 얻는 시간을 단축합니다.

마지막으로 대상 Amazon S3 버킷의 이름을 입력합니다. 다시 말씀드리지만, 저는 기억이 나지 않을 때는 찾아보기 버튼을 사용하여 콘솔에서 버킷 목록을 안내하도록 합니다. 선택적으로 파일 이름에 S3 버킷 접두사를 입력합니다. 이 데모에서는 aws-news-blog를 입력합니다. 접두사 이름을 입력하지 않으면 Kinesis Data Firehose는 날짜 및 시간(UTC)을 기본값으로 사용합니다.
버퍼 힌트, 압축 및 암호화 섹션에서 버퍼링의 기본값을 수정하거나, 데이터 압축을 활성화하거나, KMS 키를 선택하여 Amazon S3에 저장 데이터를 암호화할 수 있습니다.
준비가 되면 전송 스트림 생성을 선택합니다. 잠시 후 스트림 상태가 ✅ 가능으로 변경됩니다.

소스로 선택한 클러스터로 데이터를 스트리밍하는 애플리케이션이 있다고 가정하면 이제 S3 버킷으로 이동하여 Kinesis Data Firehose가 스트리밍할 때 선택한 대상 형식으로 데이터가 나타나는 것을 확인할 수 있습니다.
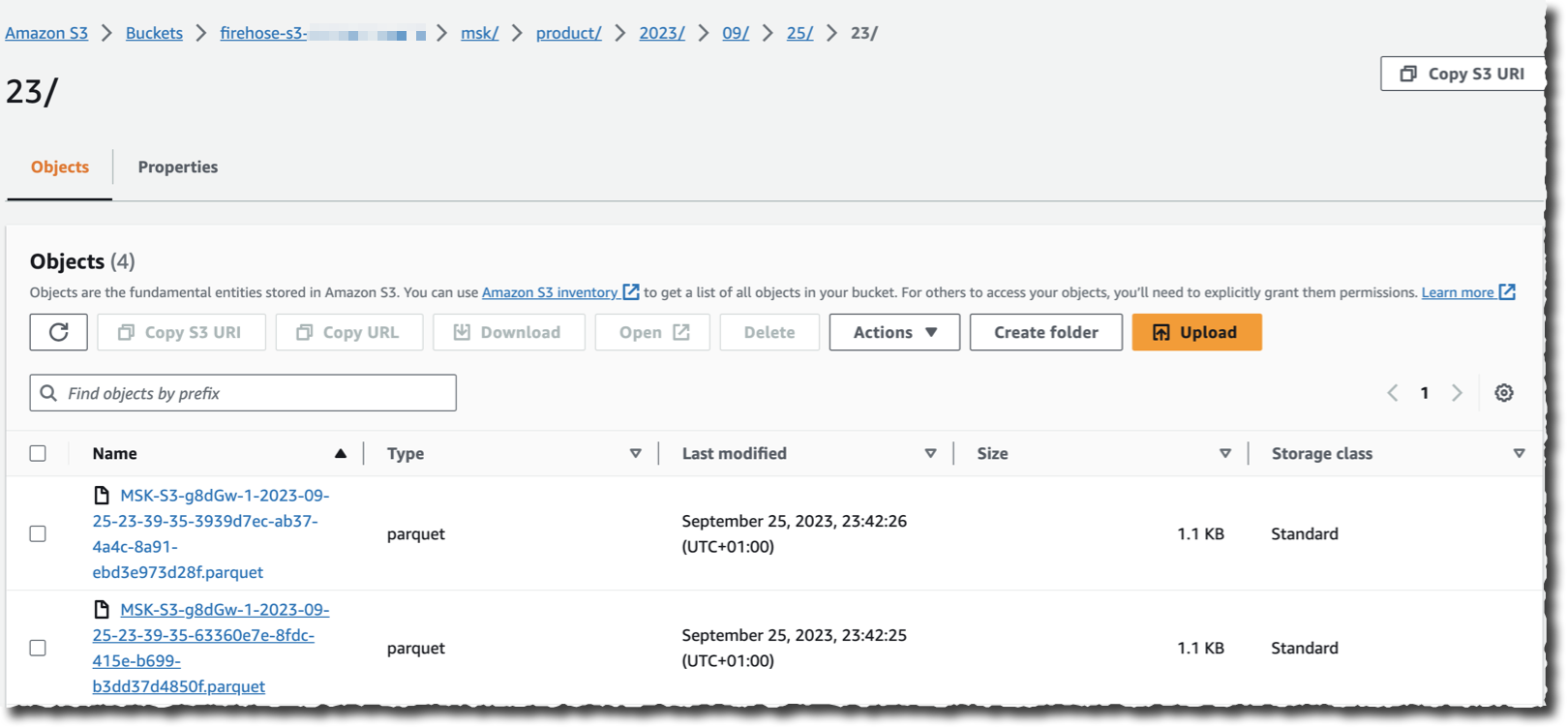
보시다시피 Kafka 클러스터에서 레코드를 읽고, 변환하고, 쓰는 데에는 코드가 필요하지 않습니다. 스트리밍 및 변환 로직을 실행하기 위해 기본 인프라를 관리할 필요도 없습니다.
요금 및 가용성.
이 새로운 기능은 현재 Amazon MSK 및 Kinesis Data Firehose를 사용할 수 있는 모든 AWS 리전에서 사용할 수 있습니다.
Amazon MSK에서 나가는 데이터 양(월 GB 단위)에 대한 요금을 지불합니다. 청구 시스템은 정확한 레코드 크기를 고려하므로 반올림이 없습니다. 평소처럼 모든 세부 정보는 요금 페이지에서 확인할 수 있습니다.
이 새로운 기능을 채택한 후 사용 중지할 인프라와 코드의 양이 기대됩니다. 이제 바로 Amazon MSK와 Amazon S3 간에 첫 번째 데이터 스트림을 구성해 보세요!