Amazon Web Services 한국 블로그
Amazon S3 Select 및 Glacier Select – 원하는 객체 기반 데이터 질의 기능 출시
Amazon S3(Simple Storage Service)는 다양한 기업들이 사용하는 수백만 애플리케이션을 위한 대용량 데이터를 저장하며, 대부분 고객은 안전하고 지속성이 우수하며 경제적인 백업 아카이브 스토리지를 위해 Amazon Glacier를 사용하고 있습니다. S3를 사용하면 원하는 만큼 많은 객체를 저장할 수 있으며, 개별 객체의 크기는 5테라바이트까지 가능합니다. 객체 스토리지의 데이터는 일반적으로 하나의 완전한 개체로 액세스되었습니다. 즉, 5기가바이트 객체를 한 개 요청하면 5기가바이트를 모두 받게 됩니다. 이것은 객체 스토리지의 속성입니다.
오늘 Amazon S3 및 Glacier를 위한 두 가지 새로운 기능을 발표하여 새로운 데이터 분석 패러다임을 제공합니다. 표준 SQL 질의를 사용하여 여기에 저장된 객체에서 필요한 정보만 가져올 수 있는 기능입니다. 이렇게 하면 S3 또는 Glacier의 객체를 액세스하는 모든 애플리케이션 성능이 근본적으로 향상됩니다.
Amazon S3 Select 미리 보기
Amazon S3 Select는 간단한 SQL 식을 사용하여 애플리케이션이 객체에서 일부 데이터만 가져올 수 있도록 하는 서비스입니다. S3 Select를 사용하여 애플리케이션에서 필요한 데이터만 가져옴으로써, 상당한 성능 향상을 이룰 수 있습니다. 대부분의 경우 이러한 성능 향상은 최대 400%에 이릅니다.
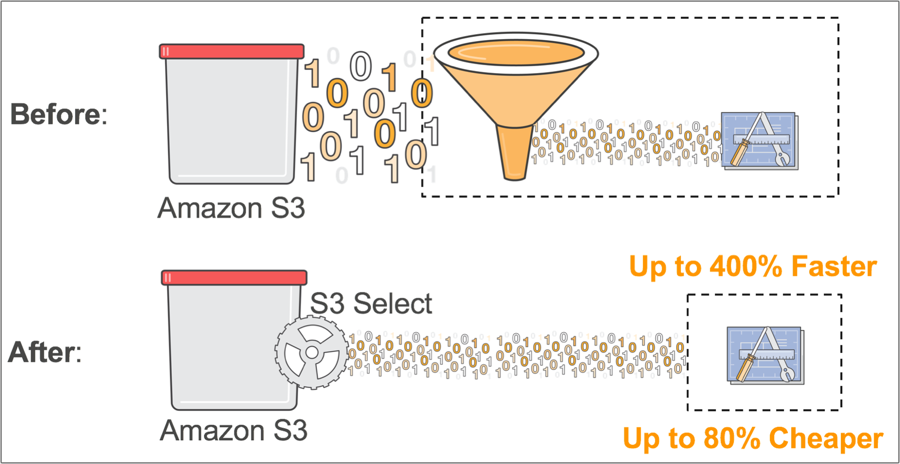
대형 소매 기업의 개발자가 한 매장의 주간 판매 데이터를 분석해야 하는데, 매일 200개 매장 모두의 데이터가 새로운 GZIP 압축 CSV로 저장되고 있는 상황을 생각해 보십시오. S3 Select가 없으면 전체 CSV를 다운로드하여 압축을 풀고 처리하여 필요한 데이터를 가져와야 합니다. S3 Select를 사용하면, 전체 객체를 가져오는 대신 해당 매장의 데이터만 반환하는 간단한 SQL 식을 사용할 수 있습니다. 즉, 최소한의 데이터만 처리하면 되며 결과적으로 기반 애플리케이션의 성능이 향상됩니다.
Python 예제를 간단히 살펴보겠습니다.
import boto3
from s3select import ResponseHandler
class PrintingResponseHandler(ResponseHandler):
def handle_records(self, record_data):
print(record_data.decode('utf-8'))
handler = PrintingResponseHandler()
s3 = boto3.client('s3')
response = s3.select_object_content(
Bucket="super-secret-reinvent-stuff",
Key="stuff.csv",
SelectRequest={
'ExpressionType': 'SQL',
'Expression': 'SELECT s._1 FROM S3Object AS s'',
'InputSerialization': {
'CompressionType': 'NONE',
'CSV': {
'FileHeaderInfo': 'IGNORE',
'RecordDelimiter': '\n',
'FieldDelimiter': ',',
}
},
'OutputSerialization': {
'CSV': {
'RecordDelimiter': '\n',
'FieldDelimiter': ',',
}
}
}
)
handler.handle_response(response['Body'])이렇게 하기 위해 S3 Select는 이진 유선 프로토콜을 사용하여 객체를 반환합니다. 현재 이를 위해서는 역직렬화를 지원하는 작은 라이브러리를 추가로 사용해야 합니다.
고객들은 S3 Select를 사용하여 모든 종류의 애플리케이션 속도를 향상시킬 수 있을 것으로 기대됩니다. 예를 들어 일부 데이터를 가져오는 이 기능은 AWS Lambda를 사용하여 만든 서버리스 애플리케이션에 특히 유용합니다. 서버리스 MapReduce 참조 아키텍처를, S3 Select를 사용하여 필요한 데이터 가져오도록 수정했을 때, 성능은 2배 향상했고 비용은 80% 감소했습니다.
또한, S3 Select 팀은 쿼리를 변경하지 않고 Amazon EMR에 대한 성능을 즉시 높일 수 있는 Presto 커넥터를 개발했습니다. S3에서 가져온 데이터의 약 99%를 필터링하는 복합 쿼리를 실행하여 이 커넥터를 테스트했습니다. S3 Select를 사용하지 않을 경우 Presto는 S3의 전체 객체를 스캔하여 필터링해야 했지만, S3 Select를 사용하면 S3 Select를 통해 쿼리에 필요한 데이터만 가져왔습니다.
[hadoop@ip-172-31-19-123 ~]$ time presto-cli --catalog hive --schema default --session hive.s3_optimized_select_enabled=false -f query.sql
"31.965496","127178","5976","70.89902","130147","6996","37.17715","138092","8678","135.49536","103926","11446","82.35177","116816","8484","67.308304","135811","10104"
real 0m35.910s
user 0m2.320s
sys 0m0.124s
[hadoop@ip-172-31-19-123 ~]$ time presto-cli --catalog hive --schema default --session hive.s3_optimized_select_enabled=true -f query.sql
"31.965496","127178","5976","70.89902","130147","6996","37.17715","138092","8678","135.49536","103926","11446","82.35177","116816","8484","67.308304","135811","10104"
real 0m6.566s
user 0m2.136s
sys 0m0.088sS3 Select를 사용하지 않은 경우 이 쿼리는 35.9초 걸렸고, S3 Select를 사용했을 때는 6.5초밖에 걸리지 않았습니다. 5배 빠른 속도입니다.
알아둘 사항
- S3 Select 프리뷰 버전은 GZIP으로 압축되거나 압축되지 않은 CSV 또는 JSON 파일을 지원합니다. 프리뷰 버전에서는 저장 시 암호화된 객체를 지원하지 않습니다.
- S3 Select 프리뷰 버전은 무료입니다.
- Amazon Athena, Amazon Redshift, Amazon EMR을 비롯하여 Cloudera, DataBricks, Hortonworks 등의 파트너들은 모두 S3 Select를 지원합니다.
Glacier Select 정식 출시
금융 서비스, 의료 등 규제가 엄격한 업종의 일부 기업에서는 SEC 규정 17a-4 또는 HIPAA 등과 같은 규정을 준수하기 위해 Amazon Glacier에 직접 데이터를 쓰고 있습니다. 많은 S3 사용자들은 더 이상 정기적으로 액세스하지 않는 데이터를 Glacier로 옮김으로써 스토리지 비용을 절약하도록 설계된 수명 주기 정책을 사용합니다. 온프레미스 테이프 라이브러리 등과 같은 기존의 아카이브 솔루션은 대부분 데이터 검색 처리량에 제한이 많아서 신속한 분석이나 처리에는 부적합합니다. 이러한 테이프 중 하나에 저장된 데이터를 사용하려면 유용한 결과를 얻기까지 몇 주씩 기다려야 할 수도 있습니다. 반면에 Glacier에 저장된 콜드 데이터는 단 몇 분만에 쉽게 쿼리할 수 있습니다.
따라서 아카이브된 데이터를 활용하여 새롭고 가능성 있는 비즈니스 가치를 창출할 수 있습니다. Glacier Select를 사용하면 표준 SQL 문을 사용하여 Glacier 객체에 대해 직접 필터링을 수행할 수 있습니다.
Glacier Select는 다른 검색 작업과 마찬가지로 수행되지만 다른 점은 초기 작업 요청에 전달할 수 있는 SelectParameters 파라미터 집합을 제공한다는 사실입니다.
다음은 간단한 예제입니다.
import boto3
glacier = boto3.client("glacier")
jobParameters = {
"Type": "select", "ArchiveId": "ID",
"Tier": "Expedited",
"SelectParameters": {
"InputSerialization": {"csv": {}},
"ExpressionType": "SQL",
"Expression": "SELECT * FROM archive WHERE _5='498960'",
"OutputSerialization": {
"csv": {}
}
},
"OutputLocation": {
"S3": {"BucketName": "glacier-select-output", "Prefix": "1"}
}
}
glacier.initiate_job(vaultName="reInventSecrets", jobParameters=jobParameters)
알아둘 사항
Glacier Select는 모든 상용 리전에서 오늘 부터 사용할 수 있습니다. Glacier는 3가지 측정량으로 요금이 책정됩니다.
- 스캔한 데이터량(GB)
- 반환된 데이터량(GB)
- Select 요청 수
각 측정량에 대한 요금은 원하는 결과 반환 속도에 따라 정해지며, 고속(1-5분), 일반(3-5시간), 대량(5-12시간)으로 구분됩니다. 곧 다가오는 2018년에 Athena는 Glacier Select를 사용하여 Glacier와 통합됩니다.
이러한 기능을 활용하여 애플리케이션 속도를 높이거나 새로운 성과를 달성하시기 바랍니다.
– Randall;
이 글은 AWS re:Invent 2017 신규 서비스 소식으로 S3 Select and Glacier Select – Retrieving Subsets of Objects 의 한국어 번역입니다.