AWS 기술 블로그
Category: Database

AWS DMS의 data resync 기능을 이용한 데이터 일관성 구현하기
이 글은 AWS Database Blog에 게시된 Data consistency with AWS DMS data resync by Suchindranath Hegde, Mahesh Kansara, Sridhar Ramasubramanian을 한국어 번역 및 편집하였습니다. 이 글에서는 AWS Database Migration Service의 데이터 재동기화(Data Resync) 기능에 대해 자세히 살펴보겠습니다. 이 기능은 DMS 3.6.1버전에 도입되어 데이터베이스 마이그레이션 도중 데이터 불일치를 감지하고 해결함으로써 수동 개입을 없애 줍니다. 데이터 재동기화(Data Resync)를 […]

LINE Games의 AI Agent를 통한 게임 퍼블리싱 가속화 여정
더 재미있고 품질 좋은 게임을 빠르게 유저와 만날 수 있도록 하기 위해 외부 개발사와의 원활한 협업은 게임 퍼블리싱 비즈니스에서 필수입니다. LINE Games는 다양한 게임 개발사가 빠르게 게임을 출시할 수 있도록 인앱결제, 빌드 배포, 계정 관리 등 퍼블리싱을 위한 플랫폼을 제공하고 있습니다. 하지만 각 개발사가 처한 상황이 다르고, 사용하는 게임 엔진(Unity와 Unreal)과 프레임워크 등 다양한 환경에 […]

AWS X Remember GenAI 해커톤 사례: 영업팀을 위한 AI 솔루션 샐리(Sales:Re) 개발기
지난 10월 17일, AWS와 리멤버앤컴퍼니가 함께 진행한 GenAI Hackathon이 성황리에 마무리되었습니다. 이번 해커톤에는 총 12개 팀이 참가하여 생성형 AI를 활용한 다양한 프로젝트를 선보였습니다. 리멤버앤컴퍼니는 국내 대표 비즈니스 네트워크 서비스, ‘리멤버’를 운영하는 기업으로, 직장인들의 커리어 성장과 비즈니스 연결을 돕고 있습니다. 500만 명 이상의 회원을 보유한 리멤버는 명함 관리, 채용, 콘텐츠 등 다양한 서비스를 제공하며, 최근에는 생성형 […]

JSON 데이터베이스로서의 PostgreSQL: 고급 패턴 및 모범 사례
JSON 데이터베이스로서의 PostgreSQL: 고급 패턴 및 모범 사례 이 글은 AWS Database Blog에 게시된 PostgreSQL as a JSON database: Advanced patterns and best practices by Ezat Karimi을 한국어 번역 및 편집하였습니다. 최신 애플리케이션에는 적응형 데이터 모델이 필요합니다. 예를 들어, 전자 상거래 제품 카탈로그는 다양한 속성과 끊임없이 변화하는 요구사항을 가지고 있습니다. 이러한 문제를 마이그레이션 없이 처리할 […]

Amazon Aurora를 위한 Advanced JDBC Wrapper Driver 소개
이 글은 AWS Database Blog에 게시된 Introducing the Advanced JDBC Wrapper Driver for Amazon Aurora by Dave Cramer을 한국어 번역 및 편집하였습니다. 현대의 애플리케이션은 확장성과 복원력을 필수적으로 갖추어야 합니다. 특히 확장성이 가장 중요한데, 이는 애플리케이션이 워크로드 규모에 따라 수백만 사용자의 요청을 즉시 처리할 수 있는 능력을 의미합니다. 전자상거래, 금융 서비스, 게임과 같이 상태를 유지해야 하는(Stateful) […]

AWS advanced JDBC wrapper 플러그인 이해하기
이 글은 AWS Database Blog에 게시된 Demystifying the AWS advanced JDBC wrapper plugins by Will Leach, Nirupam Datta, and Ryan Moore을 한국어 번역 및 편집하였습니다. 2023년에 AWS는 AWS advanced JDBC wrapper를 출시해하여 기존 JDBC 드라이버의 성능을 향상 시키고 추가 기능을 추가했습니다. 이 래퍼는 기존 사용자가 선택한 PostgreSQL, MySQL 또는 MariaDB JDBC 드라이버 위에 AWS와 Amazon […]
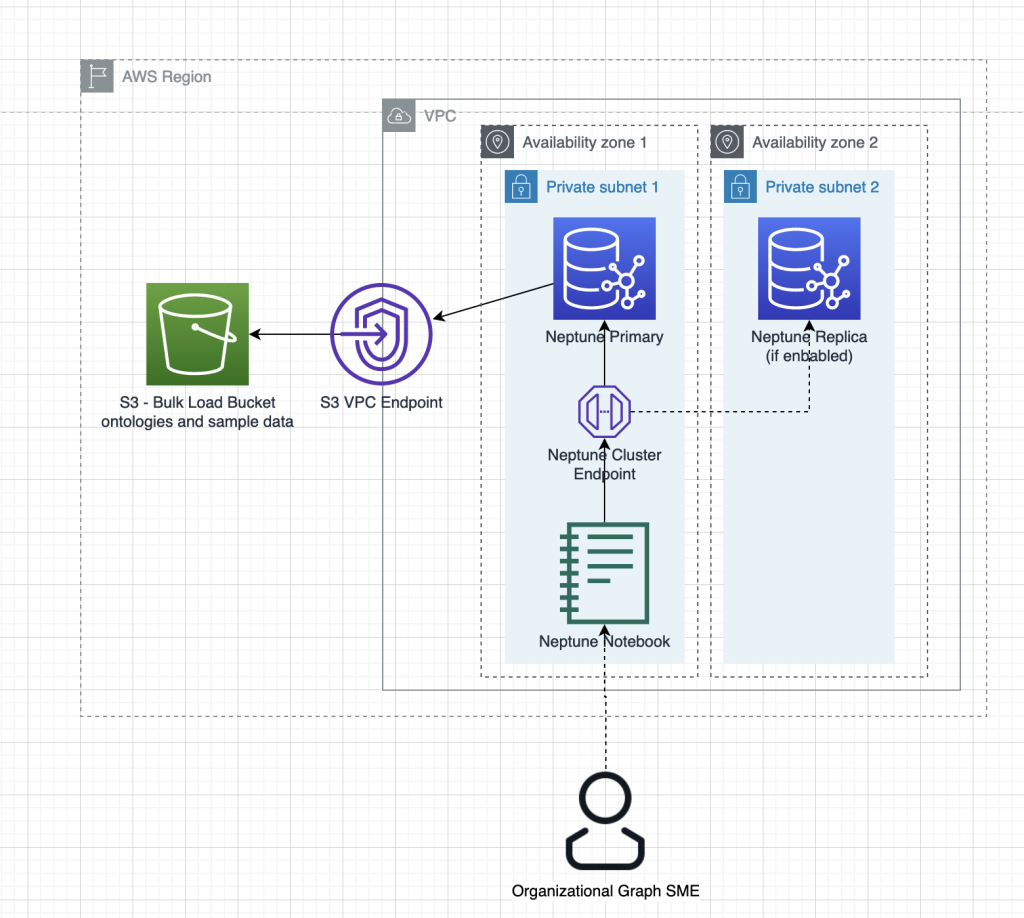
Amazon Neptune에서 온톨로지를 사용한 모델 기반 지식 그래프 만들기
본 게시글은 AWS Database Blog에 게시된 Model-driven graphs using OWL in Amazon Neptune by Mike Havey을 한국어 번역 및 편집하였습니다. Amazon Neptune은 비즈니스 객체 간의 관계를 지식 그래프로 구축하는 데 사용할 수 있는 AWS에서 제공하는 그래프 데이터베이스 서비스입니다. 지식 그래프를 구축할 때, 이러한 관계의 표현을 관리하기 위한 적합한 모델은 무엇일까요? 그래프를 즉석에서 구축하기보다는 우리를 안내할 […]

AWS와 함께하는 웅진AI Runner Challenge 4부: Amazon Q Developer CLI 활용한 보안 취약점 진단 및 조치
지난 2025년 7월 9일, AWS와 함께하는 ‘Gen AI Runner Challenge 2025’가 진행되었습니다. AI 기술이 고도화되면서, AI는 개인과 조직의 역량을 강화할 수 있는 열쇠가 되고 있습니다. 이번 AI Runner Challenge는 구성원의 상상력을 AI를 통해 직접 실현하는 자리이며, AI역량을 향상하고 실제 업무에 적용할 수 있는 기회였습니다. 본 게시글은 5부로 구성되어 있으며, 웅진의 AI Runner Challenge에 참가한 팀 […]

AWS와 함께하는 웅진AI Runner Challenge 5부: Amazon Bedrock으로 바꾼 컨택센터 상담 품질 관리
지난 2025년 7월 9일, AWS와 함께하는 ‘Gen AI Runner Challenge 2025’가 진행되었습니다. AI 기술이 고도화되면서, AI는 개인과 조직의 역량을 강화할 수 있는 열쇠가 되고 있습니다. 이번 AI Runner Challenge는 구성원의 상상력을 AI를 통해 직접 실현하는 자리이며, AI역량을 향상하고 실제 업무에 적용할 수 있는 기회였습니다. 본 게시글은 5부로 구성되어 있으며, 웅진의 AI Runner Challenge에 참가한 팀 […]

하루만에 구축한 Cedar의 AWS 기반 다문화 가정 아동 디지털 심리 진단 서비스
Overview 시더가 AWS 모.각.큐(모여서 각자 Q로 코딩)에서 개발한 다문화 아동을 위한 디지털 심리 진단 서비스 사례를 소개합니다. Amazon Bedrock과 Amazon OpenSearch Service를 활용한 RAG 기반 멀티모달 분석으로 HTP(House-Tree-Person) 그림 검사를 자동화하고, “그림을 그리는 과정” 자체를 데이터화하여 전문가 수준의 심리 분석을 제공합니다. 태블릿 기반의 자연스러운 인터페이스와 다국어 지원을 통해 다문화 가정 아동의 심리적 접근 장벽을 낮추고, […]