O blog da AWS
Nova funcionalidade no AWS DataSync: Mova dados entre a AWS e outros locais públicos
Hoje, adicionamos ao DataSync a capacidade de migrar dados entre os serviços de armazenamento da AWS e o Google Cloud Storage ou o Microsoft Azure Files. Dessa forma, você pode simplificar as tarefas de processamento de dados ou consolidação de armazenamento. Isso também ajuda se você precisar importar, compartilhar e trocar dados com clientes, fornecedores ou parceiros que usam o Google Cloud Storage ou o Microsoft Azure Files. O DataSync fornece segurança de ponta a ponta, incluindo criptografia e validação de integridade, para garantir que seus dados cheguem com segurança, intactos e prontos para uso.
Vamos ver como isso funciona na prática:
Preparando o agente DataSync
/aws/service/datasync/ami:
Usando o console do EC2, inicio uma instância do EC2 com o ID da AMI especificado na propriedade Value do parâmetro. Para configuração de rede, utilizo uma sub-rede pública e a opção de atribuir automaticamente um endereço IP público. A instância do EC2 precisa de acesso tanto a rede de origem quanto a rede de destino para a tarefa de transferência de dados. Outro requisito para a instância é poder receber tráfego HTTP do DataSync para ativar o agente.
Ao usar o AWS DataSync em uma nuvem privada virtual (Amazon VPC) é uma boa prática usar endpoints VPC para conectar o agente ao serviço AWS DataSync. No console VPC, seleciono Endpoints no painel de navegação e, em seguida, Create endpoint. Insiro um nome para o endpoint e seleciono a categoria de serviços da AWS.
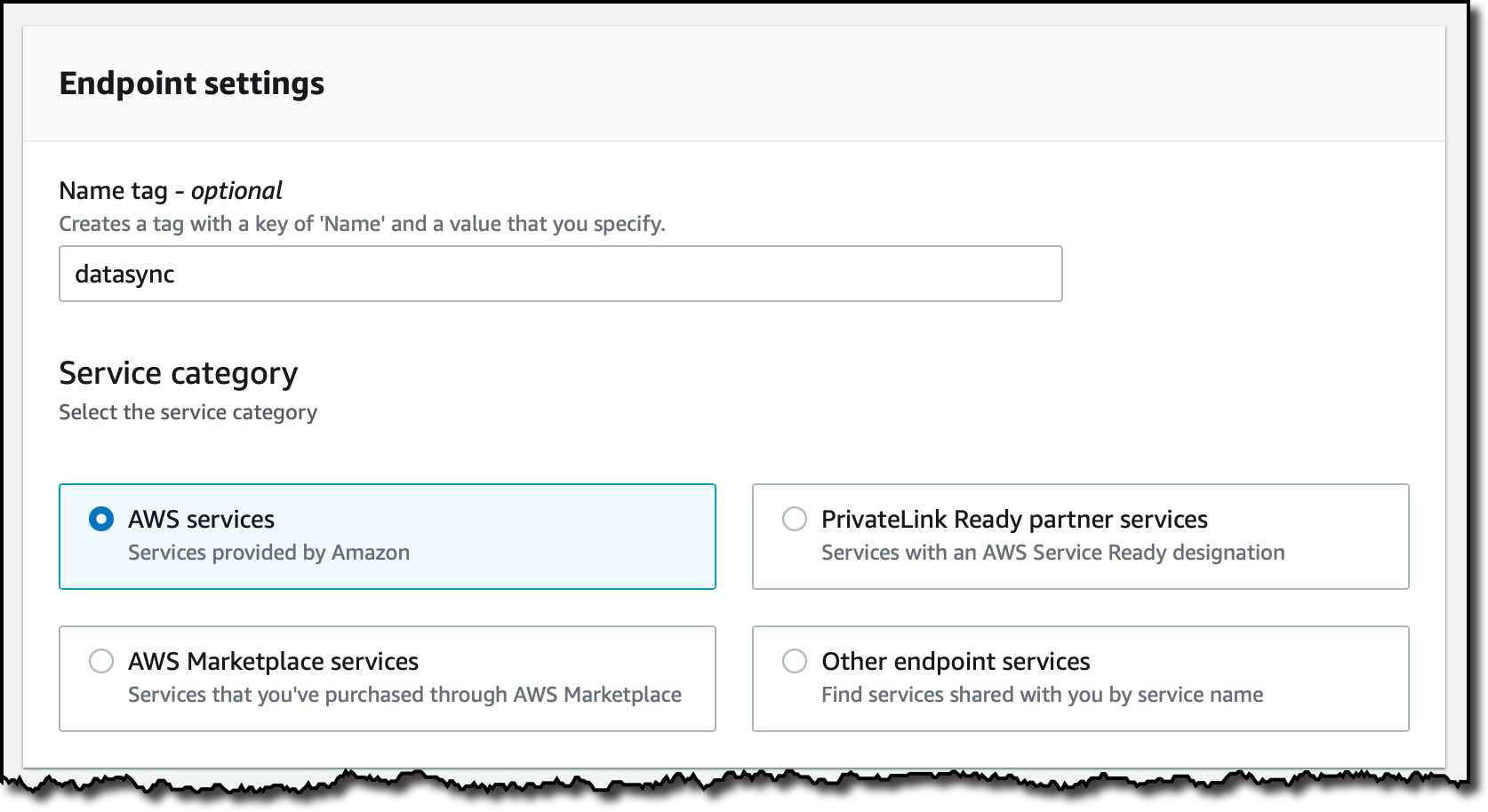
Na seção Serviços, procuro o DataSync.

Em seguida, seleciono a mesma VPC em que iniciei a instância do EC2.

Para reduzir o tráfego entre as zonas de disponibilidade (Cross-AZ), eu escolho a mesma sub-rede usada para a instância do EC2.

O agente do DataSync em execução na instância do EC2 precisa de acesso de rede ao endpoint VPC. Para simplificar, eu uso o grupo de segurança padrão da VPC para ambos. Então, crio o endpoint VPC e, após alguns minutos, ele está pronto para uso.

No console do AWS DataSync, seleciono Agentes (Agents)no painel de navegação e, em seguida, Criar agente (Create agente). Depois, seleciono Amazon EC2 para Hipervisor (Hypervisor).
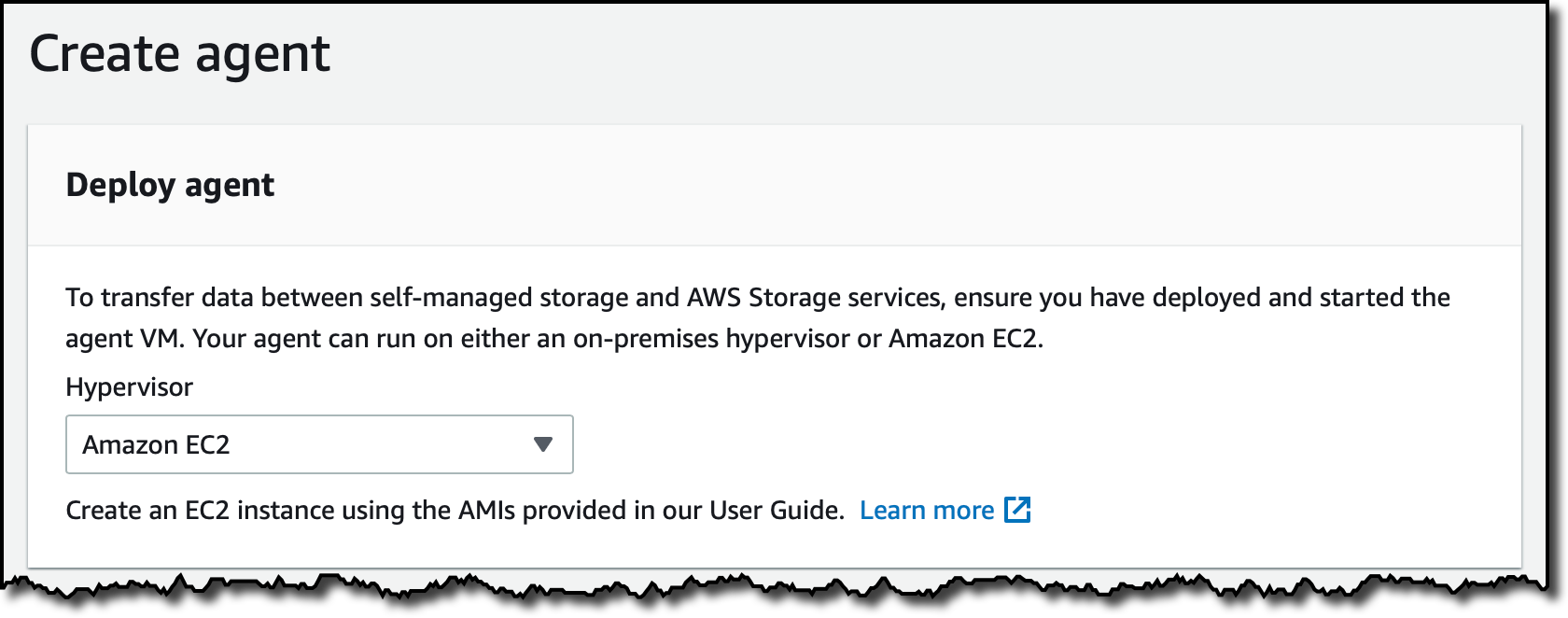
Em Tipo de Endpoint (Endpoint Type), seleciono Endpoints da VPC usando o AWS PrivateLink (VPC endpoints using AWS PrivateLink). A seguir, seleciono o endpoint VPC que criei anteriormente, bem como, a mesma sub-rede e grupo de segurança utilizado para o endpoint VPC.
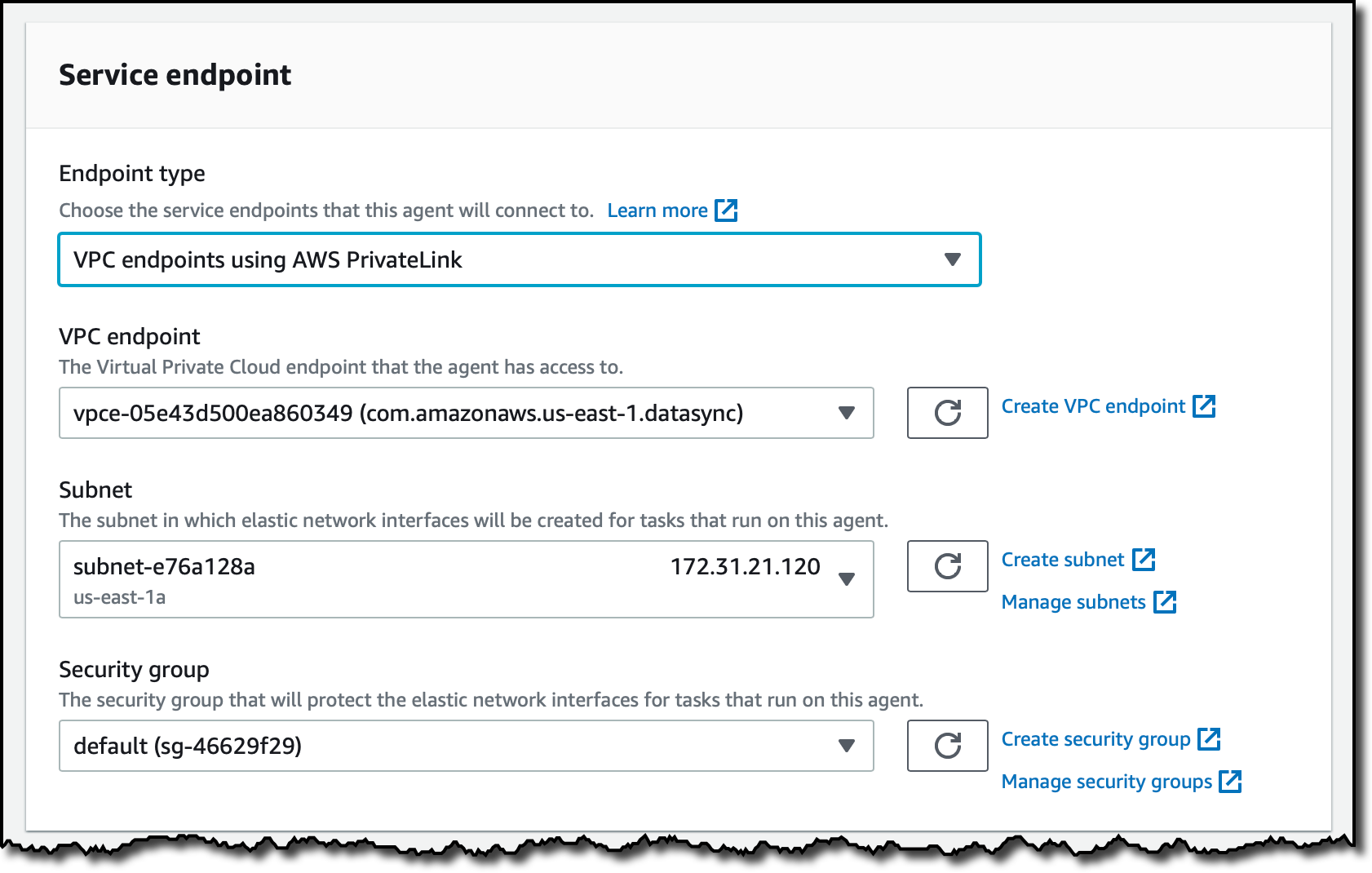
Eu escolho a opção Obter automaticamente a chave de ativação de seu agente (Automatically get the activation key from your agent) e digito o IP Público da instância EC2 no campo Endereço do agente (Agent address). Em seguida, clico em Obter chave (Get key).

Depois que o agente DataSync é ativado, não preciso mais do acesso HTTP e o removo dos grupos de segurança da instância do EC2. Agora que o agente do DataSync está ativo, posso configurar tarefas e locais para mover meus dados.
Transferência de dados do Google Cloud Storage para o Amazon S3
Tenho algumas imagens em um bucket do Google Cloud Storage e quero sincronizar esses arquivos com um bucket do S3. No console do Google Cloud, abro a configuração do bucket, crio uma conta de serviço com permissões do Storage Object Viewer e anoto as credenciais (chave de acesso e segredo) para acessar o bucket de forma programática.
De volta ao console do AWS DataSync, seleciono Tarefas e, em seguida, Criar tarefa.
Para configurar a origem da tarefa, eu crio um local. Seleciono Armazenamento de objetos (Object Storage) para o tipo de localização (Location Type) e escolho o agente que acabei de criar. Para o servidor (server), eu uso storage.googleapis.com. Em seguida, insiro o nome do bucket (Bucket Name) do Google Cloud e a pasta (Folder) em que minhas imagens estão armazenadas.

Na seção Autenticação (Authentication), insiro a chave de acesso (access key) e o segredo (secret) que anotei quando criei a conta de serviço. Então, escolho Avançar (Next).

Para configurar o destino da tarefa, crio outro local. Desta vez, seleciono Amazon S3 como o Tipo de localização (Location Type). Eu escolho o bucket S3 de destino e entro em uma pasta que será usada como prefixo para os arquivos transferidos para o bucket. Eu uso o botão Gerar automaticamente (Autogenerate) para criar o perfil do IAM (IAM role) que concederá permissões ao AWS DataSync para acessar o bucket do S3.
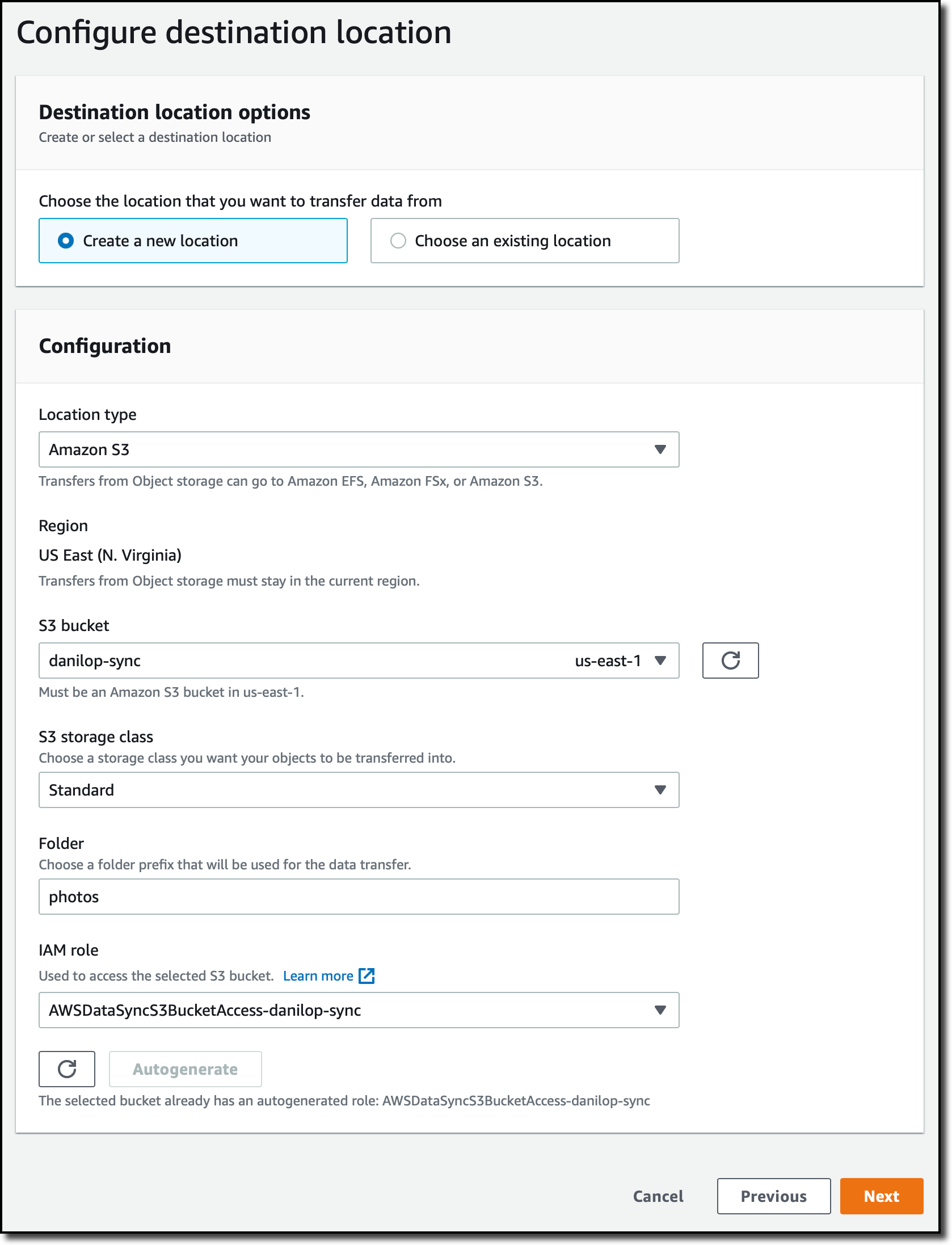
Na próxima etapa, defino as configurações da tarefa. Eu insiro um nome para a tarefa (Task Name) e, opcionalmente, posso ajustar a forma como o AWS DataSync verifica a integridade dos dados transferidos (Verify Data) ou alocar a largura de banda (Set bandwidth limit) para a tarefa.
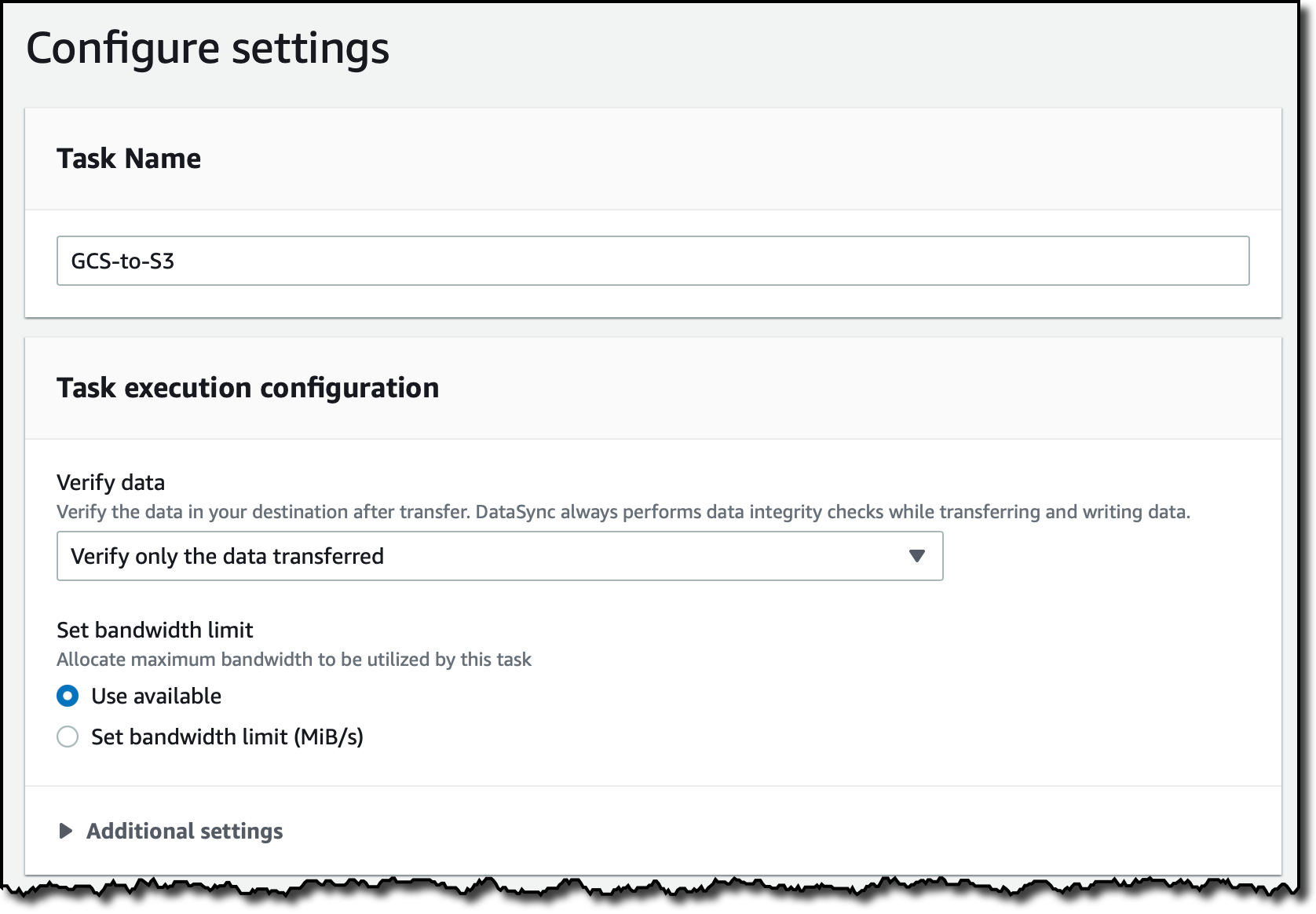
Também posso escolher quais dados digitalizar e quais transferir. Por padrão, todos os dados de origem são escaneados e somente os dados alterados são transferidos. Na seção Configurações adicionais (Additional settings), eu desativo a opção Copiar tag do objeto (Copy object tags) porque o Google Cloud Storage atualmente não oferece suporte a tags.

Posso selecionar o cronograma que será utilizado para executar essa tarefa. Por enquanto, estou deixando em Não agendado (Not scheduled) e vou iniciá-lo manualmente.
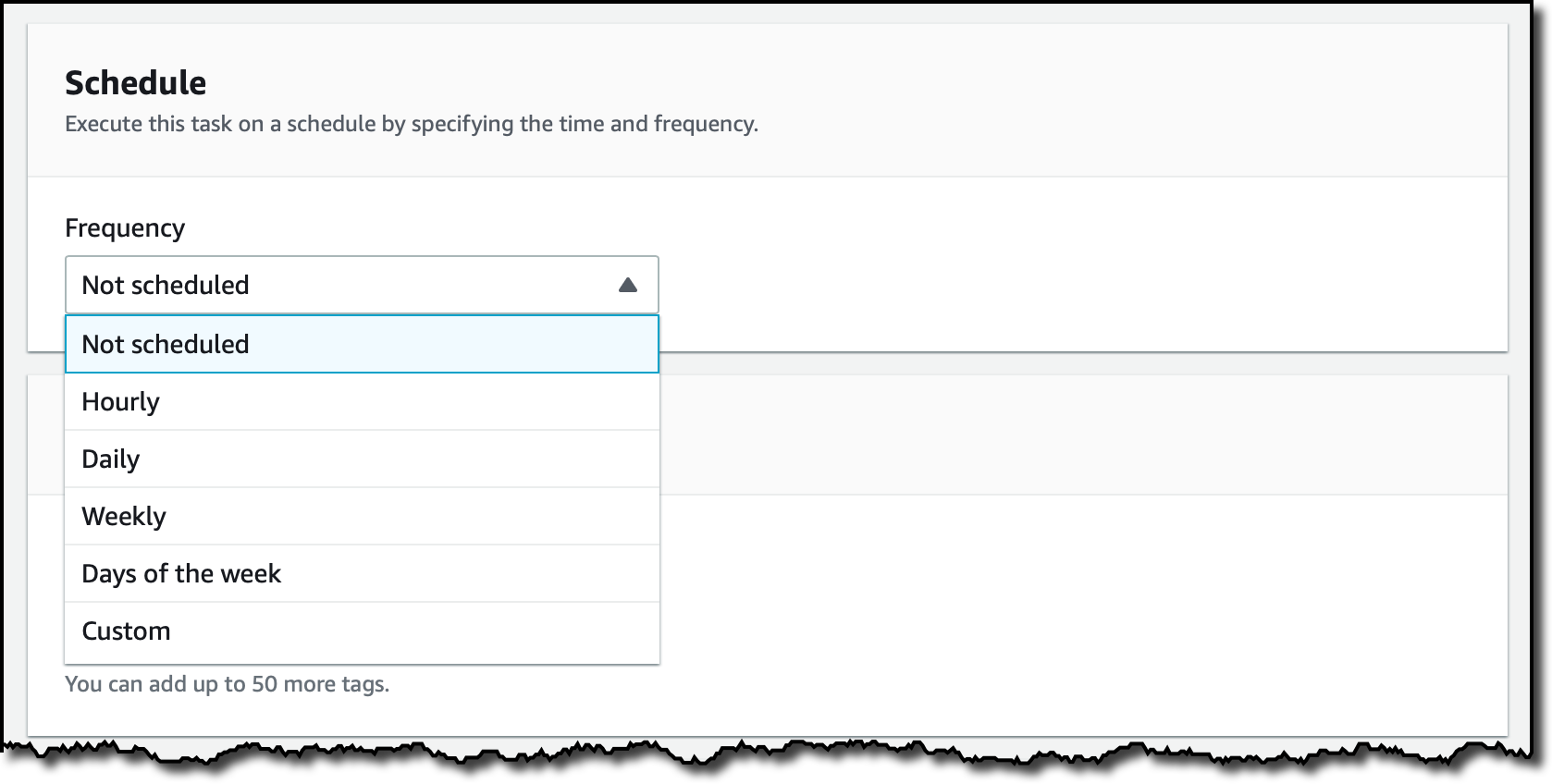
Para registrar os logs, eu uso o botão Gerar automaticamente (Autogenerate) para criar um grupo de registros de logs para o AWS DataSync. Então, escolho Avançar (Next).

Eu reviso as configurações e crio a tarefa. Agora, eu inicio a tarefa de transferir dados pela console. Depois de alguns minutos, os arquivos são sincronizados com meu bucket do S3 e eu posso acessá-los no console do S3.
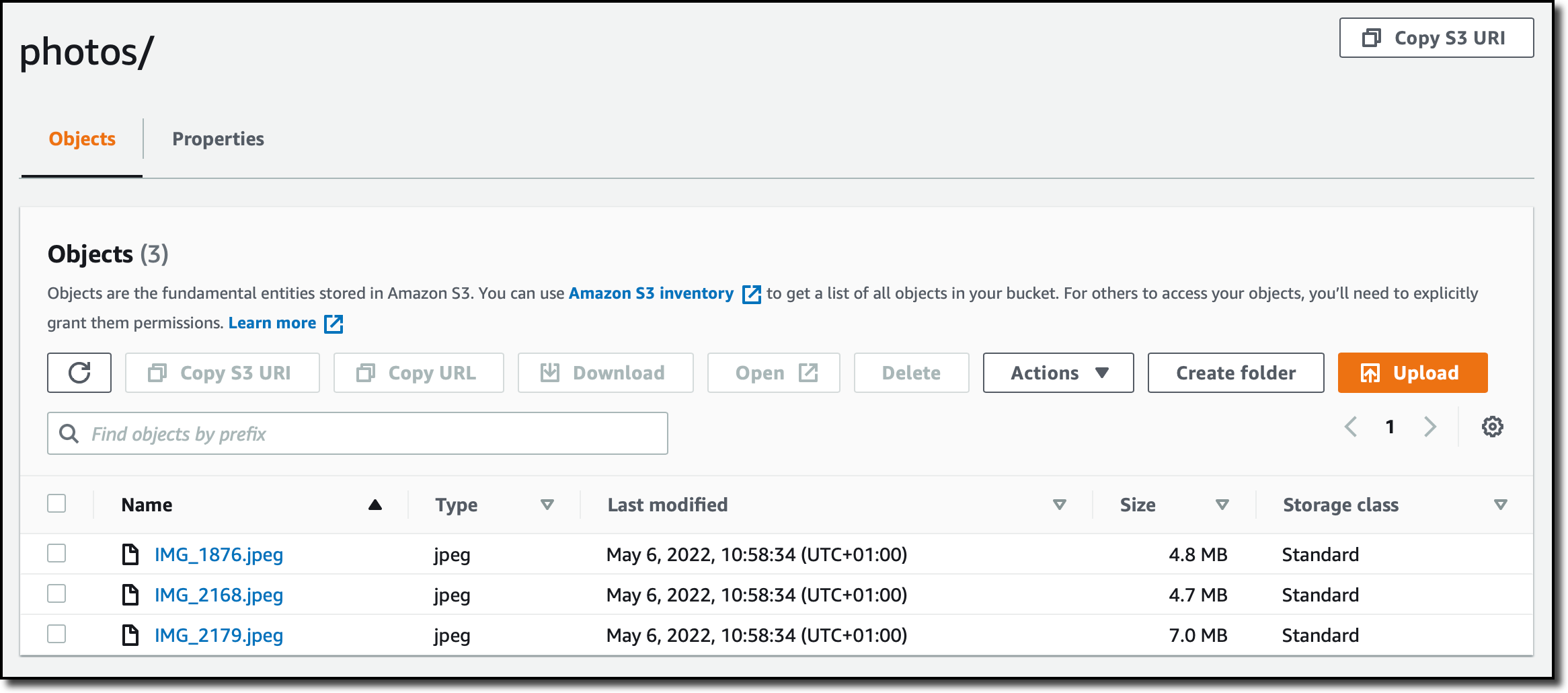
Movendo dados dos arquivos do Azure para o Amazon FSx for Windows File Server
Eu tiro muitas fotos e também tenho algumas imagens em um compartilhamento de arquivos do Azure (Azure File Share) e quero sincronizar esses arquivos com um sistema de arquivos Amazon FSx para Windows. No console do Azure, seleciono o compartilhamento de arquivos e clico no botão Conectar (Connect) para gerar um script do PowerShell que verifica se essa conta de armazenamento pode ser acessada pela rede.
A partir desse script, obtenho as informações necessárias para configurar a localização do DataSync:
- Servidor SMB (SMB Server)
- Nome do compartilhamento (Share Name)
- Usuário (User)
- Senha (Password)
De volta ao console do AWS DataSync, seleciono Tarefas e, em seguida, Criar tarefa.
Para configurar a origem da tarefa, eu crio um local. Seleciono o Bloco de Mensagens do Servidor (Server Message Block – SMB) para o Tipo de Local (Location Type) e o agente que criei anteriormente. Em seguida, uso as informações que encontrei no script para inserir o endereço do servidor SMB (SMB Server), o nome do compartilhamento (Share Name) e o usuário/senha (user/password) que usarei para autenticação.
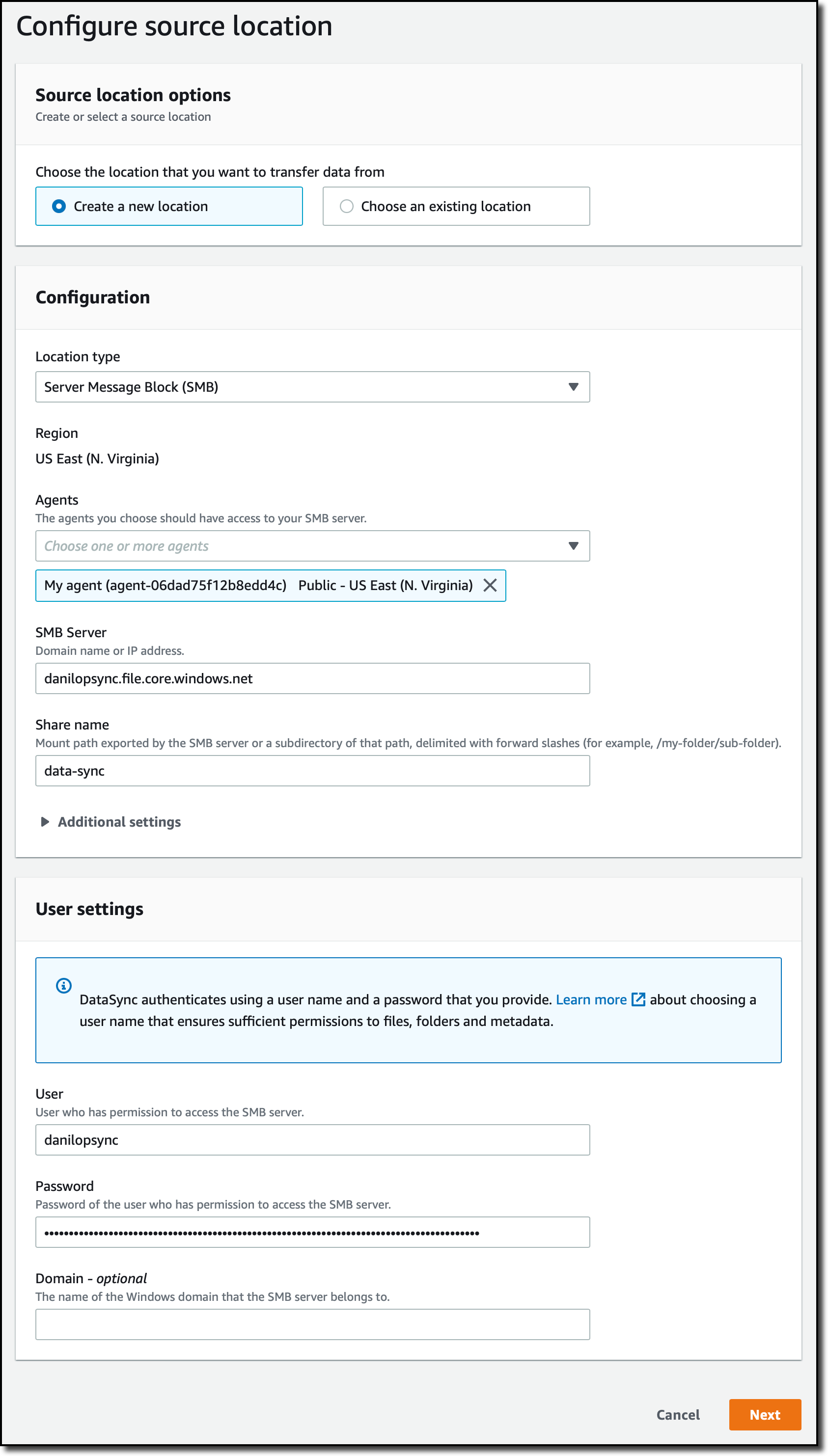 Para configurar o destino da tarefa, eu crio um outro novo local. Desta vez, escolho o Amazon FSx para o tipo de localização (Location Type). Eu seleciono o sistema de arquivos FSx para Windows que eu criei anteriormente e uso o nome padrão do recurso compartilhado (Share Name). Utilizo o grupo de segurança padrão para me conectar ao sistema de arquivos. Como eu uso o AWS Directory Service for Microsoft Active Directory com FSx for Windows File Server, utilizo as credenciais de um usuário que é membro dos grupos de “Administradores de domínio” (Domain Admins) e “AWS Delegated FSx Administrators”. Para obter mais informações, consulte em nossa documentação: Criação de um local FSx para o Windows File Server.
Para configurar o destino da tarefa, eu crio um outro novo local. Desta vez, escolho o Amazon FSx para o tipo de localização (Location Type). Eu seleciono o sistema de arquivos FSx para Windows que eu criei anteriormente e uso o nome padrão do recurso compartilhado (Share Name). Utilizo o grupo de segurança padrão para me conectar ao sistema de arquivos. Como eu uso o AWS Directory Service for Microsoft Active Directory com FSx for Windows File Server, utilizo as credenciais de um usuário que é membro dos grupos de “Administradores de domínio” (Domain Admins) e “AWS Delegated FSx Administrators”. Para obter mais informações, consulte em nossa documentação: Criação de um local FSx para o Windows File Server.

Na próxima etapa, insiro um nome para a tarefa (Task Name) e deixo todas as outras opções com seus valores padrão da mesma forma que fiz para a tarefa anterior.
Então, reviso as configurações e crio a tarefa. Agora eu inicio a tarefa de transferir dados pelo console. Depois de alguns minutos, os arquivos são sincronizados com meu recurso compartilhado pelo sistema de arquivos FSx para Windows. Monto o sistema de arquivos compartilhado em uma instância Windows do EC2 e vejo que minhas imagens estão lá:

Ao criar uma tarefa, eu posso reutilizar os locais existentes. Por exemplo, se eu quiser sincronizar arquivos do Azure Files com meu bucket do S3, posso selecionar rapidamente os dois locais correspondentes que criei para esta publicação.
Disponibilidade e preços
Você pode mover seus dados usando o console do AWS DataSync, a interface de linha de comando (CLI) da AWS ou os SDKs da AWS para criar tarefas que transferem dados entre o serviço de armazenamento da AWS e os buckets do Google Cloud Storage ou os sistemas de arquivos do Azure Files. Enquanto as tarefas estão em execução, você pode monitorar o progresso pelo console do AWS DataSync ou por meio do Amazon CloudWatch.
Não há mudanças nos preços do DataSync com esses novos recursos. A transferência de dados de e para o Google Cloud ouo Microsoft Azure mantém o mesmo custo de todas as outras fontes de dados compatíveis com o AWS DataSync atualmente.
Entretanto, o Google Cloud ou o Microsoft Azure podem aplicar custos na transferência de dados de saída (transfer out). Como o DataSync compacta os dados copiando-os entre o agente e a AWS, você pode reduzir estes custos de saída implementando o agente DataSync em um ambiente do Google Cloud ou Microsoft Azure.
Ao usar o DataSync para transferir dados da AWS para o Google Cloud ou o Microsoft Azure, você será cobrado pela transferência de dados do EC2 para a Internet. Consulte os preços do Amazon EC2 para obter mais informações.
Sobre o autor
 Danilo Poccia trabalha com start-ups e empresas de qualquer tamanho para apoiar sua inovação. Como evangelista-chefe (EMEA) na Amazon Web Services, ele usa sua experiência para ajudar as pessoas a concretizar suas ideias, com foco em arquiteturas sem servidor e programação baseada em eventos, bem como no impacto técnico e comercial do aprendizado de máquina e da computação de ponta. Ele é o autor de AWS Lambda in Action, de Manning.
Danilo Poccia trabalha com start-ups e empresas de qualquer tamanho para apoiar sua inovação. Como evangelista-chefe (EMEA) na Amazon Web Services, ele usa sua experiência para ajudar as pessoas a concretizar suas ideias, com foco em arquiteturas sem servidor e programação baseada em eventos, bem como no impacto técnico e comercial do aprendizado de máquina e da computação de ponta. Ele é o autor de AWS Lambda in Action, de Manning.
Tradutor
 Marcelo Ahuerma participou de vários projetos de migração para a nuvem da AWS, em suas funções como líder em áreas de tecnologia e segurança de TI durante sua carreira profissional no México. Atualmente, ele é arquiteto de soluções no setor público da Amazon Web Services, onde apoia e orienta principalmente clientes do setor de tecnologia educacional (EdTech) nos Estados Unidos, a otimizar suas cargas de trabalho aproveitando os serviços da AWS.
Marcelo Ahuerma participou de vários projetos de migração para a nuvem da AWS, em suas funções como líder em áreas de tecnologia e segurança de TI durante sua carreira profissional no México. Atualmente, ele é arquiteto de soluções no setor público da Amazon Web Services, onde apoia e orienta principalmente clientes do setor de tecnologia educacional (EdTech) nos Estados Unidos, a otimizar suas cargas de trabalho aproveitando os serviços da AWS.
Revisor
 Maxwell Castro atua com infraestrutura há 12 anos, participando também de vários projetos de migração e está focado em nuvem pelos últimos 3 anos. Atualmente, é arquiteto de soluções da AWS Brasil e participa da equipe de Cloud Sales Center, e também membro da comunidade técnica de Migrations e Modernization da AWS
Maxwell Castro atua com infraestrutura há 12 anos, participando também de vários projetos de migração e está focado em nuvem pelos últimos 3 anos. Atualmente, é arquiteto de soluções da AWS Brasil e participa da equipe de Cloud Sales Center, e também membro da comunidade técnica de Migrations e Modernization da AWS