- AWS Solutions Library
- Guidance for Renewables Data Lake and Analytics on AWS
Guidance for Renewables Data Lake and Analytics on AWS
Overview
How it works
Part 1
This diagram shows different scenarios for renewable energy operators to consider when ingesting data from different edge configurations, such as supervisory control and data acquisitions (SCADAs) and legacy applications. The configurations or applications communicate data over a secure virtual private network (VPN) connection to an AWS internet of things (IoT) connectivity solution.
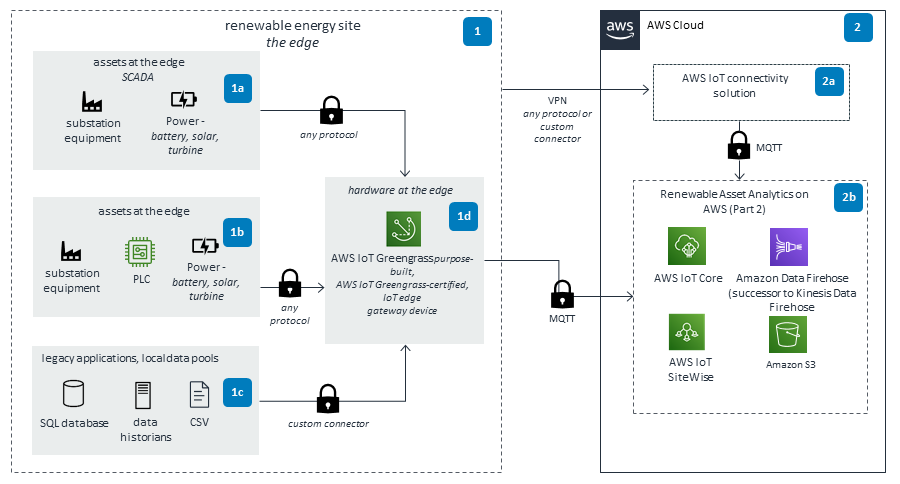
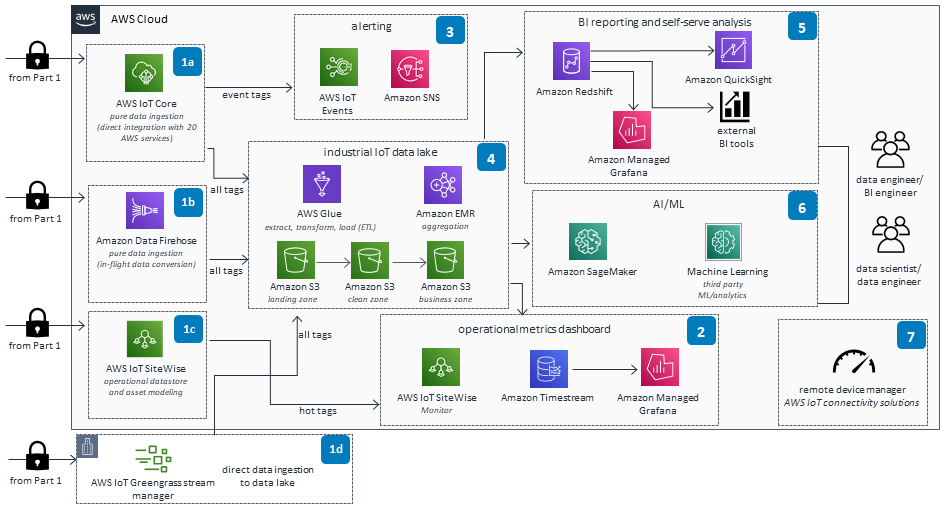
Part 2
The AWS IoT connectivity solution can help operators build a modern, complete, edge-to-cloud solution to ingest near real-time data from renewable assets such as wind turbines, solar farms, and hydro dams. An industrial IoT data lake is created where advanced analytics can be performed. Operators can derive insights from their asset data by using machine learning, near real-time dashboards, alert management, business intelligence (BI) reporting, and comprehensive device management.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
You can safely operate this Guidance and respond to events with Firehose that integrates with Amazon CloudWatch alarms. Set these alarms to invoke when metrics exceed buffering limits.
Amazon EMR logs files to identify cluster issues such as failures or errors. You can archive log files in Amazon S3 to troubleshoot issues even after your Amazon EMR cluster terminates. Amazon EMR integrates with CloudWatch to track performance metrics. You can configure alarms based on different metrics. For example, “IsIdle” tracks if a cluster is active and not running tasks. And “HDFSUtilization” monitors the clusters' capacity to see if it requires resizing to add more core nodes.
AWS IoT SiteWise allows you to set alarms to identify equipment performance issues. The alarms can be integrated with Amazon Simple Queue Service (Amazon SQS) and Amazon SNS to perform additional actions based on the alarm.
Implementing least privilege access is fundamental in reducing security risk and the impact that could result from errors or malicious intent. We therefore recommend implementing least privilege access for all resources.
The producer and client applications must have valid credentials to access Firehose delivery streams. We recommend you use AWS Identity and Access Management (IAM) roles to manage temporary credentials for producer and client applications.
Amazon EMR allows you to encrypt data in-transit and at-rest. At-rest, encryption can be done by using encrypted Amazon Elastic Block Store (Amazon EBS) or enabling encryption on Amazon S3 (or both) when using Elastic MapReduce File System (EMRFS). You can also use the Hadoop Distributed File System (HDFS) transparent encryption if you are using HDFS instead of EMRFS.
AWS IoT SiteWise stores data in the AWS Cloud and on a gateway. The data stored in other AWS services is encrypted by default. Encryption at rest integrates with AWS Key Management Service (AWS KMS) to manage the encryption key used to encrypt the asset.
The AWS IoT SiteWise gateway running on AWS IoT Greengrass relies on Unix file permissions and full-disk encryption to protect data at rest. Full-disk encryption can be enabled.
With Firehose , you can backup source data in an Amazon S3 bucket. This allows you to go back to the source data in case a failure occurs downstream.
Amazon EMR monitors nodes in the cluster and automatically terminates and replaces an instance in case of a failure.
Firehose allows dynamic partitioning of streaming data. Partitioning the data minimizes the amount of data scanned and optimizes performance. This makes it easier to run high performance and cost-efficient analytics on streaming data in Amazon S3 using Amazon EMR and Quicksight .
Amazon EMR cluster nodes can be monitored and optimized based on your workload. For some workloads, the primary node needs to be more powerful, for other situations, the core and task nodes will need to run on higher CPU instances.
This Guidance relies on serverless AWS services that are fully-managed and auto scale according to workload demand. As a result, you only pay for what you use.
Firehose allows you to create interface VPC endpoints. This prohibits the traffic between the VPC and Firehose from leaving the AWS network, and it also reduces data transfer cost. With Firehose , you can use tags to categorize delivery streams, allowing you to view the usage and cost by the custom tags.
Amazon EMR makes it easy to use Amazon EC2 Spot Instances , saving you both time and money. You could configure the ‘task nodes’ in the Amazon EMR cluster to use Spot Instances. This allows you to reduce cost without losing data if those Spot Instances are lost.
Firehose allows you to convert input data from JSON to Apache Parquet before storing into Amazon S3 , saving space and enabling faster queries. These efficiencies reduce the total amount of hardware needed to manage the data.
To further minimize hardware usage, you can use Amazon EMR Serverless . This helps you focus on the workload and not the underutilization of primary, core, or task nodes.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages