ฐานข้อมูลแบบเชิงสัมพันธ์และไม่สัมพันธ์แตกต่างกันอย่างไร
ฐานข้อมูลแบบเชิงสัมพันธ์และไม่สัมพันธ์แตกต่างกันอย่างไร
ฐานข้อมูลแบบเชิงสัมพันธ์และไม่สัมพันธ์คือวิธีการเก็บข้อมูลสำหรับแอปพลิเคชันสองรูปแบบ ฐานข้อมูลแบบเชิงสัมพันธ์ (หรือฐานข้อมูล SQL) จะเก็บข้อมูลในรูปแบบตารางที่มีแถวและคอลัมน์ โดยคอลัมน์จะมีข้อมูลแอตทริบิวต์ ส่วนแถวจะมีค่าของข้อมูลต่างๆ คุณสามารถเชื่อมโยงตารางในฐานข้อมูลแบบเชิงสัมพันธ์เพื่อรับข้อมูลเชิงลึกในการเชื่อมต่อระหว่างจุดข้อมูลที่หลากหลายได้ ในทางกลับกัน ฐานข้อมูลแบบไม่สัมพันธ์ (หรือฐานข้อมูล NoSQL) จะใช้รูปแบบข้อมูลที่หลากหลายเพื่อการเข้าถึงและการจัดการข้อมูล โดยได้รับการปรับปรุงประสิทธิภาพสำหรับแอปพลิเคชันที่ต้องใช้ข้อมูลปริมาณมาก มีเวลาแฝงต่ำ และมีโมเดลข้อมูลที่ยืดหยุ่นโดยเฉพาะ ซึ่งเกิดขึ้นโดยการผ่อนปรนข้อจำกัดความสอดคล้องกันของข้อมูลในฐานข้อมูลอื่นๆ
ฐานข้อมูลแบบเชิงสัมพันธ์มีวิธีเก็บข้อมูลอย่างไร
ฐานข้อมูลแบบเชิงสัมพันธ์จะเก็บข้อมูลในตารางที่มีคอลัมน์และแถว แต่ละคอลัมน์จะแสดงถึงแอตทริบิวต์ข้อมูลเฉพาะ และแต่ละแถวแสดงถึงอินสแตนซ์ของข้อมูลนั้น
คุณให้คีย์หลักแก่แต่ละตาราง ซึ่งคือคอลัมน์ตัวระบุที่ระบุตารางโดยไม่ซ้ำกัน คุณใช้คีย์หลักเพื่อสร้างความสัมพันธ์ระหว่างตาราง คุณใช้เพื่อเชื่อมโยงแถวระหว่างตารางเป็นคีย์นอกในตารางอื่น
เมื่อเชื่อมต่อตารางสองตารางแล้ว คุณจะได้รับข้อมูลจากตารางทั้งสองด้วยการสืบค้นครั้งเดียว คุณเขียนแบบสอบถาม SQL เพื่อโต้ตอบกับฐานข้อมูลแบบเชิงสัมพันธ์
ตัวอย่างข้อมูลที่เก็บไว้
ตัวอย่างเช่น สมมติว่าผู้ค้าปลีกสร้างตารางสำหรับผลิตภัณฑ์ทั้งหมดของพวกเขา โดยคุณสามารถมีคอลัมน์สำหรับชื่อผลิตภัณฑ์ คำอธิบาย และราคาอยู่ในตารางนี้ อีกตารางหนึ่งมีข้อมูลเกี่ยวกับลูกค้า ชื่อ และสิ่งที่พวกเขาซื้อ
ตารางต่อไปนี้จะแสดงให้เห็นถึงข้อมูลตามวิธีการที่กล่าวมา
|
Product_id (คีย์หลัก) |
Product_name |
Product_cost |
|
P1 |
Product_A |
100 USD |
|
P2 |
Product_B |
50 USD |
|
P3 |
Product_C |
80 USD |
|
Customer_id |
Customer_name |
Item_purchased (คีย์นอก) |
|
C1 |
Customer_A |
P2 |
|
C2 |
Customer_B |
P1 |
|
C3 |
Customer_C |
P3 |
ฐานข้อมูลแบบที่ไม่สัมพันธ์มีการเก็บข้อมูลอย่างไร
ระบบฐานข้อมูลแบบไม่สัมพันธ์มีอยู่หลายระบบเนื่องจากมีความผันแปรของวิธีการจัดการและจัดเก็บข้อมูลแบบไม่ใช้สคีมา ข้อมูลที่ไม่มีสคีมาเป็นข้อมูลที่จัดเก็บโดยไม่มีข้อจำกัดที่ฐานข้อมูลแบบเชิงสัมพันธ์ต้องการ
ในลำดับต่อไป เราจะอธิบายถึงประเภททั่วไปของฐานข้อมูลแบบไม่สัมพันธ์
ฐานข้อมูลแบบคีย์-ค่า
ฐานข้อมูลแบบคีย์-ค่าจะเก็บข้อมูลเป็นชุดของคู่คีย์-ค่า ในคู่ คีย์จะทำหน้าที่เป็นตัวระบุเฉพาะ ทั้งคีย์และค่าสามารถเป็นอะไรก็ได้ตั้งแต่อ็อบเจกต์ธรรมดาไปจนถึงอ็อบเจกต์แบบผสมที่ซับซ้อน
อ่านเกี่ยวกับฐานข้อมูลแบบคีย์-ค่า »
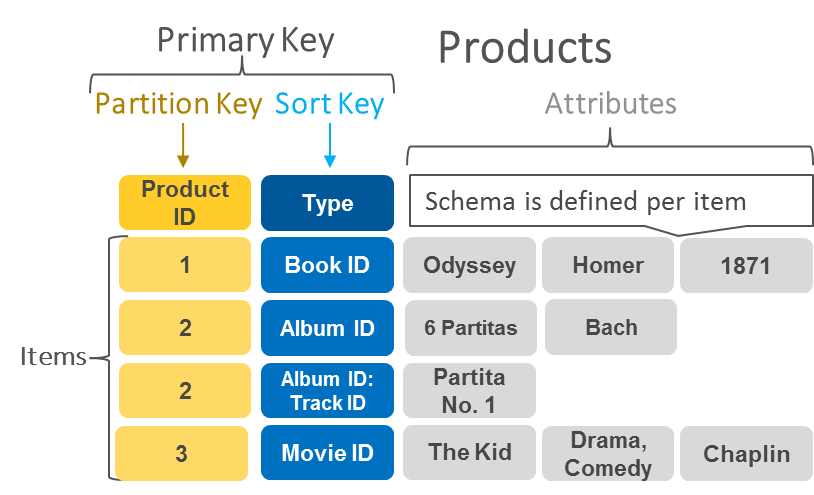
ฐานข้อมูลแบบโครงสร้างเอกสาร
ฐานข้อมูลเชิงเอกสารจะมีรูปแบบโมเดลเอกสารเดียวกันกับที่นักพัฒนาใช้ในโค้ดของแอปพลิเคชัน พวกเขาจะจัดเก็บข้อมูลเป็นอ็อบเจกต์ JSON ที่มีความยืดหยุ่น กึ่งมีโครงสร้าง และมีลักษณะเป็นลำดับชั้น
ตัวอย่างต่อไปนี้จะแสดงให้เห็นถึงลักษณะของข้อมูลที่จัดเก็บในฐานข้อมูลแบบโครงสร้างเอกสาร
|
{ company_name: "AnyCompany", address: {street: "1212 Main Street", city: "Anytown"}, phone_number: "1-800-555-0101", industry: ["food processing", "appliances"] type: "private", number_of_employees: 987 } |
อ่านเกี่ยวกับฐานข้อมูลแบบโครงสร้างเอกสาร »
ฐานข้อมูลกราฟ
ฐานข้อมูลแบบกราฟจะถูกสร้างตามวัตถุประสงค์เพื่อการจัดเก็บและนำทางความสัมพันธ์ ฐานข้อมูลชนิดนี้จะใช้โหนดเพื่อจัดเก็บเอนทิตีข้อมูลและ Edge เพื่อจัดเก็บความสัมพันธ์ระหว่างเอนทิตี
Edge มักจะมีโหนดเริ่มต้น โหนดปลายทาง ชนิด และทิศทาง ตัวอย่างเช่น มันจะสามารถอธิบายถึงความสัมพันธ์ระหว่างตัวหลักและตัวย่อย การกระทำ และความเป็นเจ้าของ
อ่านเกี่ยวกับฐานข้อมูลแบบกราฟ »

ความแตกต่างที่สำคัญระหว่างฐานข้อมูลแบบเชิงสัมพันธ์และแบบไม่สัมพันธ์
ฐานข้อมูลแบบเชิงสัมพันธ์และแบบไม่สัมพันธ์จะจัดเก็บและจัดการข้อมูลแตกต่างกันมาก ส่วนต่อไปนี้จะกล่าวถึงความแตกต่างแบบเฉพาะเจาะจง
โครงสร้าง
ฐานข้อมูลแบบเชิงสัมพันธ์จะจัดเก็บข้อมูลในรูปแบบตารางและปฏิบัติตามกฎที่เข้มงวดเกี่ยวกับการเปลี่ยนแปลงข้อมูลและความสัมพันธ์ของตาราง ซึ่งช่วยให้คุณสามารถประมวลผลการสืบค้นที่ซับซ้อนเกี่ยวกับข้อมูลที่มีโครงสร้างได้ ในขณะที่รักษาความสมบูรณ์และความสอดคล้องของข้อมูลไปด้วย
ฐานข้อมูลแบบไม่สัมพันธ์นั้นมีความยืดหยุ่นและมีประโยชน์มากกว่าสำหรับข้อมูลที่มีข้อกำหนดความต้องการด้านการเปลี่ยนแปลง คุณสามารถใช้ฐานข้อมูลชนิดนี้เพื่อจัดเก็บรูปภาพ วิดีโอ เอกสาร และเนื้อหากึ่งมีโครงสร้างและไม่มีโครงสร้างอื่นๆ ได้
กลไกความสมบูรณ์ของข้อมูล
Atomicity, Consistency, Isolation และ Durability (ACID) หมายถึงความสามารถของฐานข้อมูลในการรักษาความสมบูรณ์ของข้อมูลแม้จะมีข้อผิดพลาดหรือการขัดจังหวะในการประมวลผลข้อมูล
โมเดลฐานข้อมูลแบบเชิงสัมพันธ์นั้นเป็นไปตามคุณสมบัติของ ACID ที่เข้มงวด ซึ่งหมายความว่าชุดการดำเนินการที่ตามมาจะเสร็จสมบูรณ์พร้อมกันเสมอ หากการดำเนินการล้มเหลวรายการเดียว การดำเนินการทั้งชุดจะล้มเหลวด้วย ซึ่งวิธีนี้จะรับประกันความถูกต้องของข้อมูลอยู่ตลอดเวลา
ในทางตรงกันข้าม ฐานข้อมูลแบบไม่สัมพันธ์จะมีรูปแบบ Basic Availability Soft-State และ Eventually Consistent (BASE) ที่ยืดหยุ่นกว่า
ฐานข้อมูลแบบไม่สัมพันธ์จะรับประกันความพร้อมใช้งาน แต่จะไม่ได้สอดคล้องกันในทันที สถานะของฐานข้อมูลสามารถเปลี่ยนแปลงได้ตลอดเวลาและในที่สุดก็จะสอดคล้องกัน ฐานข้อมูลแบบไม่สัมพันธ์บางฐานข้อมูลอาจมีการปฏิบัติตามข้อกำหนดของ ACID กับประสิทธิภาพการทำงานหรือการแลกเปลี่ยนอื่นๆ
ประสิทธิภาพ
ประสิทธิภาพของฐานข้อมูลแบบเชิงสัมพันธ์นั้นขึ้นอยู่กับระบบย่อยของดิสก์ เพื่อปรับปรุงประสิทธิภาพของฐานข้อมูล คุณสามารถใช้ SSD และปรับดิสก์ให้เหมาะสมได้โดยการกำหนดค่าด้วยอาร์เรย์ดิสก์อิสระ (RAID) ที่ซ้ำซ้อน คุณต้องปรับดัชนี โครงสร้างตาราง และแบบสอบถามให้เหมาะสมด้วย เพื่อให้ได้ประสิทธิภาพที่สูงสุด
ในทางตรงกันข้าม ประสิทธิภาพของฐานข้อมูล NoSQL จะขึ้นอยู่กับเวลาแฝงของเครือข่าย ขนาดคลัสเตอร์ของฮาร์ดแวร์ และแอปพลิเคชันการเรียกใช้ วิธีในการปรับปรุงประสิทธิภาพของฐานข้อมูลแบบไม่สัมพันธ์มีอยู่สองสามวิธีดังนี้
- เพิ่มขนาดของคลัสเตอร์
- ลดเวลาแฝงของเครือข่าย
- ดัชนีและแคช
ฐานข้อมูล NoSQL มอบประสิทธิภาพและความสามารถในการปรับขนาดที่สูงขึ้นสำหรับกรณีการใช้งานเฉพาะเมื่อเปรียบเทียบกับฐานข้อมูลแบบเชิงสัมพันธ์
ขนาด
โครงสร้างที่เข้มงวดของระบบฐานข้อมูลแบบเชิงสัมพันธ์สามารถนำเสนอความท้าทายในระดับต่างๆ ได้ โดยทั่วไปแล้ว คุณจะปรับขนาดในแนวตั้งโดยเพิ่มทรัพยากร CPU หรือ RAM ให้กับเซิร์ฟเวอร์ นอกจากนี้ คุณยังสามารถปรับขนาดในแนวนอนได้ด้วย โดยการทำซ้ำข้อมูลข้ามเซิร์ฟเวอร์สำหรับเวิร์กโหลดแบบอ่านอย่างเดียว อย่างไรก็ตาม การปรับขนาดแนวนอนสำหรับเวิร์กโหลดแบบอ่าน-เขียนจะต้องใช้กลยุทธ์พิเศษ เช่น การแบ่งพาร์ทิชันและการแบ่งส่วนข้อมูล
อ่านเกี่ยวกับการแบ่งส่วนฐานข้อมูล »
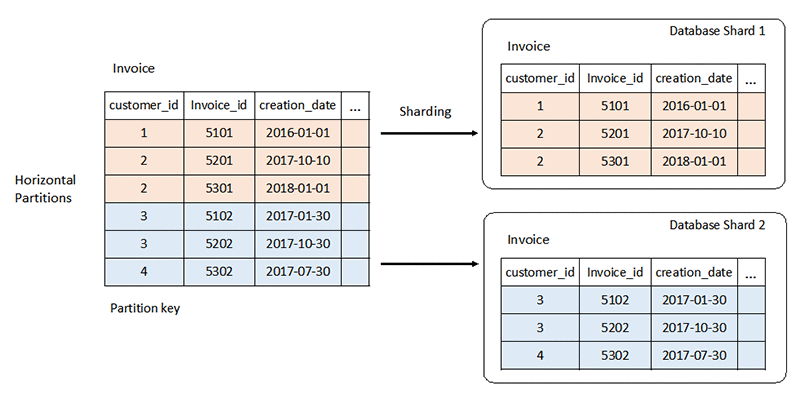
ในทางตรงกันข้าม ฐานข้อมูล NoSQL จะสามารถปรับขนาดได้สูง คุณสามารถกระจายเวิร์กโหลดไปยังโหนดต่างๆ ได้ง่ายขึ้น ฐานข้อมูลเหล่านี้สามารถประมวลผลข้อมูลปริมาณมากโดยการแบ่งพาร์ทิชันเป็นชุดที่เล็กลงและกระจายชุดไปยังหลายๆ โหนด

เมื่อใดควรใช้ฐานข้อมูลแบบเชิงสัมพันธ์เทียบกับแบบไม่สัมพันธ์
ฐานข้อมูลแบบเชิงสัมพันธ์เป็นตัวเลือกที่ดีที่สุดหากข้อมูลของคุณสามารถคาดเดาได้ในแง่ของขนาด โครงสร้าง และความถี่ในการเข้าถึง นอกจากนี้ คุณอาจต้องการระบบจัดการฐานข้อมูลแบบเชิงสัมพันธ์ หากความสัมพันธ์ระหว่างเอนทิตีมีความสำคัญ ตัวอย่างเช่น หากคุณมีชุดข้อมูลขนาดใหญ่ที่มีโครงสร้างและมีความสัมพันธ์ที่ซับซ้อน และคุณต้องการให้ความสัมพันธ์นั้นโดดเด่นในด้านการวิเคราะห์และใช้งานง่าย
ในทางตรงกันข้าม โมเดลแบบไม่สัมพันธ์จะทำงานได้ดีกว่าสำหรับการจัดเก็บข้อมูลที่มีรูปร่างหรือขนาดที่ยืดหยุ่น หรืออาจจะมีการเปลี่ยนแปลงในอนาคต
นอกจากนี้ ในบางกรณี ความสัมพันธ์ของข้อมูลก็ไม่เหมาะสมกับรูปแบบคีย์หลักและคีย์นอกแบบตาราง ตัวอย่างเช่น หากต้องการสร้างแบบจำลองของเพื่อนและความสัมพันธ์ในเครือข่ายโซเชียลมีเดีย คุณจะต้องใช้ตารางที่มีหลายร้อยแถวในฐานข้อมูลแบบเชิงสัมพันธ์
ในทางตรงกันข้าม ในฐานข้อมูลแบบไม่สัมพันธ์จะมีการแสดงเป็นบรรทัดเดียว ตัวอย่างต่อไปนี้จะแสดงถึงรายการข้อมูลสำหรับสมาชิกที่มีเพื่อนสี่คนในฐานข้อมูลแบบไม่สัมพันธ์
|
Member_id Friend_id M1 M2 M1 M3 M1 M4 M1 M5 |
{member name: “member 1” member friends: “member 2, member 3, member 4, member 5”} |
สรุปความแตกต่างระหว่างฐานข้อมูลแบบเชิงสัมพันธ์กับฐานข้อมูลแบบไม่สัมพันธ์
|
หมวดหมู่ |
ฐานข้อมูลแบบเชิงสัมพันธ์ |
ฐานข้อมูลแบบไม่สัมพันธ์ |
|
โมเดลข้อมูล |
แบบตาราง |
คีย์-ค่า เอกสาร หรือกราฟ |
|
ประเภทข้อมูล |
มีโครงสร้าง |
มีโครงสร้าง กึ่งมีโครงสร้าง และไม่มีโครงสร้าง |
|
การบูรณาการข้อมูล |
การปฏิบัติตามข้อกำหนด ACID อย่างเต็มที่และสูงสุด |
โมเดลความสอดคล้องของข้อมูลขั้นสุด |
|
ประสิทธิภาพ |
ปรับปรุงจากการเพิ่มทรัพยากรเพิ่มเติมให้กับเซิร์ฟเวอร์ |
ปรับปรุงจากการเพิ่มโหนดเซิร์ฟเวอร์เพิ่มเติม |
|
การปรับขนาด |
การปรับขนาดในแนวนอนต้องใช้กลยุทธ์การจัดการข้อมูลเพิ่มเติม |
การปรับขนาดแนวนอนนั้นเป็นแบบตรงไปตรงมา |
AWS จะสนับสนุนข้อกำหนดความต้องการด้านฐานข้อมูลแบบเชิงสัมพันธ์และแบบไม่สัมพันธ์ของคุณได้อย่างไร
Amazon Web Services (AWS) มีบริการมากมายสำหรับความต้องการฐานข้อมูลแบบเชิงสัมพันธ์และแบบไม่สัมพันธ์
บริการของ AWS สำหรับฐานข้อมูลแบบเชิงสัมพันธ์
Amazon Relational Database Service (Amazon RDS) คือชุดของบริการที่มีการจัดการที่ทำให้การตั้งค่า ใช้งาน และปรับขนาดฐานข้อมูลแบบเชิงสัมพันธ์ในระบบคลาวด์ได้อย่างง่ายดาย ฐานข้อมูลบนระบบคลาวด์มีประโยชน์อย่างมากมายในด้านประสิทธิภาพ ขนาด และความคุ้มค่า คุณสามารถใช้กลไกฐานข้อมูลแบบเชิงสัมพันธ์ได้ดังต่อไปนี้
- Amazon RDS สำหรับ SQL Server เพื่อปรับใช้ SQL Server หลายรุ่น (2014, 2016, 2017 และ 2019)
- Amazon RDS สำหรับ MySQL เพื่อรอง รับ MySQL Community Edition รุ่น 5.7 และ 8.0
- Amazon RDS สำหรับ MariaDB เพื่อรองรับเซิร์ฟเว อร์ MariaDB เวอร์ชัน 10.3, 10.4, 10.5 และ 10.6
นอกจากนี้ Amazon RDS สำหรับ Oracle ยังมีใบอนุญาตสองรุ่นที่แตกต่างกันซึ่งหมายความว่าคุณไม่จำเป็นต้องมีใบอนุญาต Oracle ที่ซื้อแยกต่างหากหากคุณไม่มีใบอนุญาต
บริการของ AWS สำหรับฐานข้อมูลแบบไม่สัมพันธ์
นอกจากนี้ AWS ยังมีบริการฐานข้อมูล NoSQL มากมายที่ตอบสนองความต้องการสำหรับ NoSQL ทั้งหมดของคุณ ดังตัวอย่างต่อไปนี้
- Amazon DynamoDB เป็น บริการฐานข้อมูลมูลค่ากุญแจที่ให้เวลาแฝงมิลลิวินาทีตัวเลขเดียวที่สม่ำเสมอสำหรับโหลดงานในทุกขนาด
- Amazon DocumentDB (พร้อมความเข้ากันได้ MondoDB) เป็นฐานข้อมูลที่เน้นเอกสารยอดนิยมพร้อม API ที่ทรงพลังและใช้งานง่ายสำหรับการพัฒนาที่ยืดหยุ่นและซ้ำ
- Amazon MemoryDB เป็นบริการฐานข้อมูลแบบใช้หน่วยความจำที่ทนทาน มีเวลาแฝงในการอ่านและเขียนระดับไมโครวินาทีเพื่อประสิทธิภาพที่รวดเร็วเป็นพิเศษ
- Amazon Neptune เป็น บริการฐานข้อมูลกราฟที่มีการจัดการอย่างสมบูรณ์เพื่อสร้างและเรียกใช้แอปพลิเคชันกราฟประสิทธิภาพสูง
- Amazon OpenSearch Service สร้างขึ้นโดยวัตถุ ประสงค์เพื่อมอบการแสดงภาพและการวิเคราะห์ข้อมูลที่สร้างขึ้นโดยเครื่องจักรใกล้เรียลไทม์
เริ่มต้นใช้งานฐานข้อมูลเชิงสัมพันธ์และไม่สัมพันธ์บน AWS โดยการ สร้างบัญชีวันนี้
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages