- Generative AI
- Amazon Bedrock
- Evaluations
Amazon Bedrock Evaluations
Evaluate foundation models, including custom and imported models, to find models that fit your needs. You can also evaluate your retrieval or end-to-end RAG workflow in Amazon Bedrock Knowledge Bases.
Overview
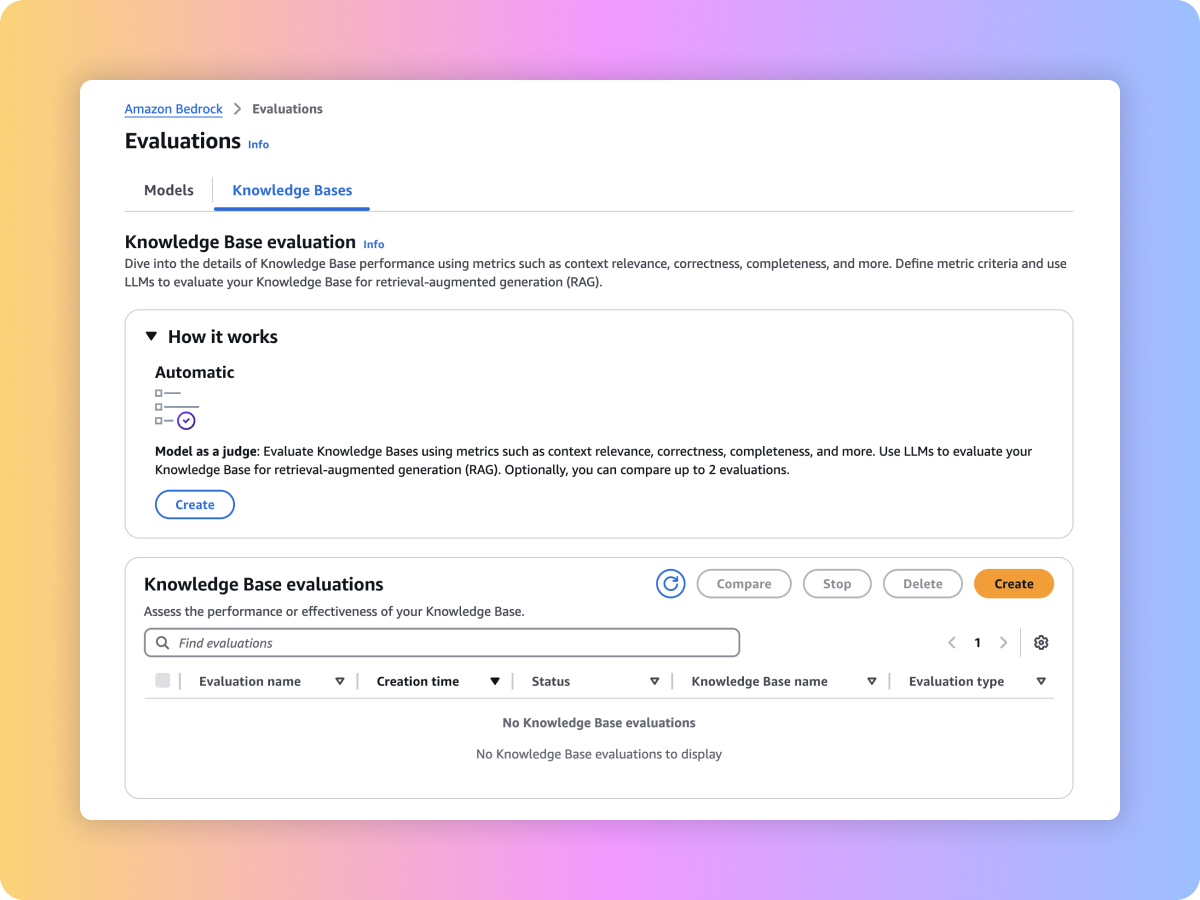
Amazon Bedrock provides evaluation tools for you to accelerate adoption of generative AI applications. Evaluate, compare, and select the foundation model for your use case with Model Evaluation. Prepare your RAG applications for production that are built on Amazon Bedrock Knowledge Bases or your own custom RAG systems by evaluating the retrieve or retrieve and generate functions.
Evaluation types
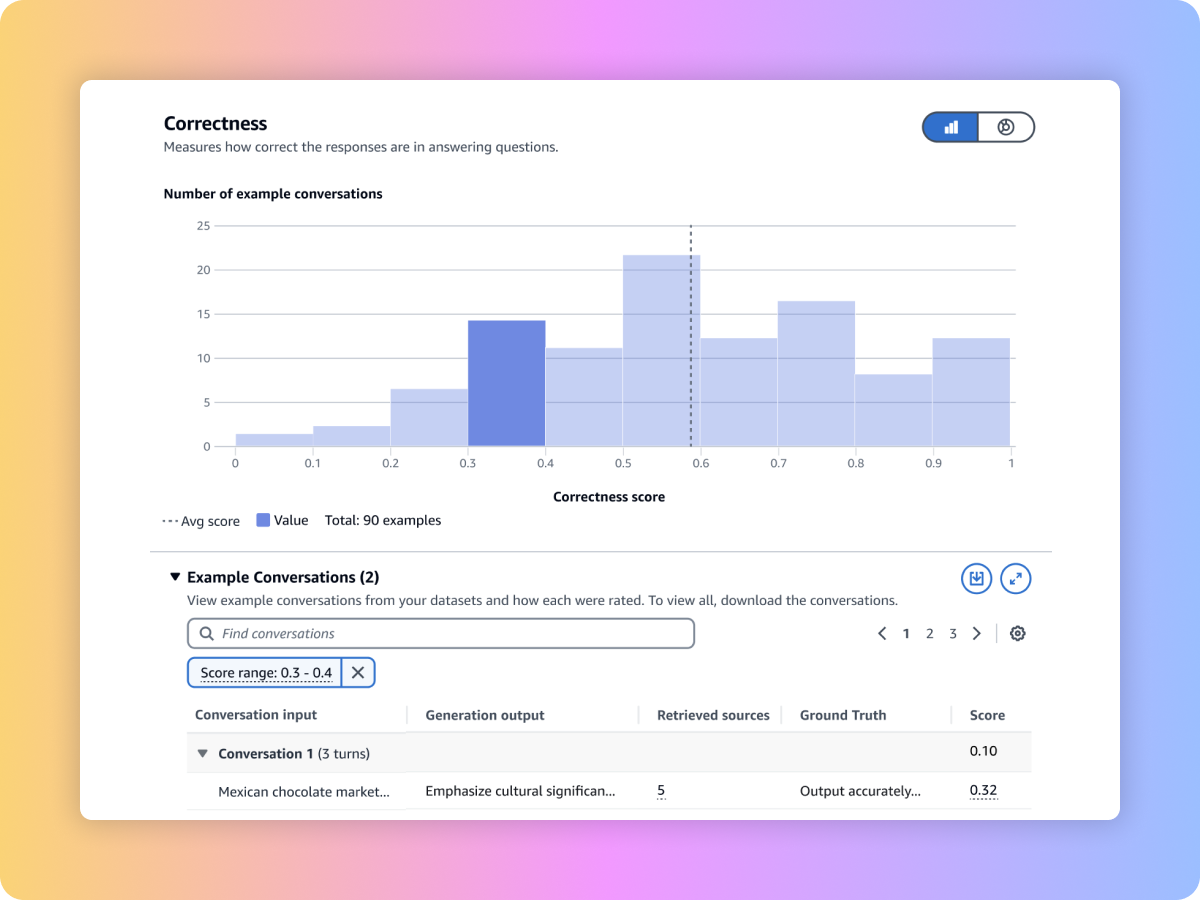
Use an LLM as a Judge to evaluate model outputs using your custom prompt datasets with metrics such as correctness, completeness, and harmfulness.
Evaluate model outputs using traditional natural language algorithms and metrics like BERT Score, F1, and other exact matching techniques, using built-in prompt datasets or bring your own.
Evaluate model outputs with your own workforce or have AWS manage your evaluations on responses to your custom prompt datasets with built-in or custom metrics.
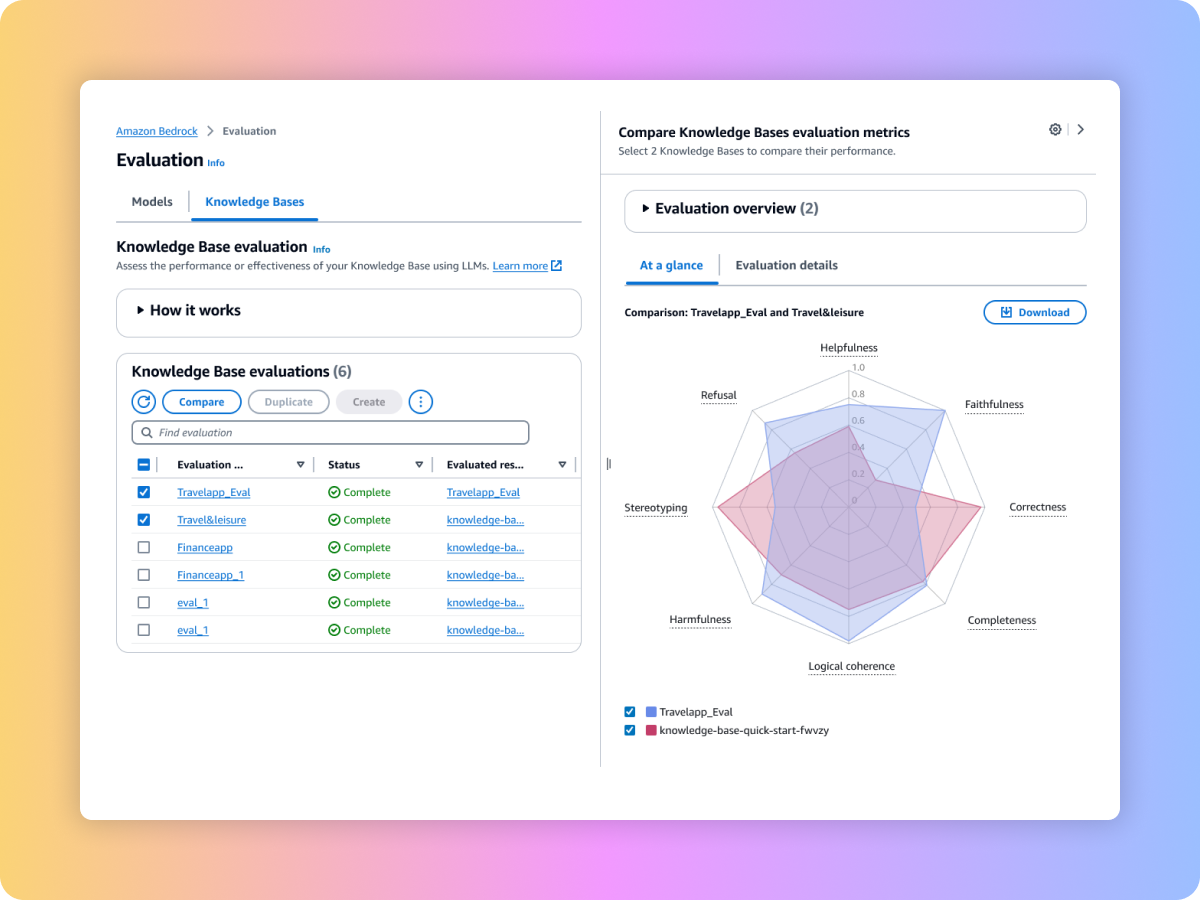
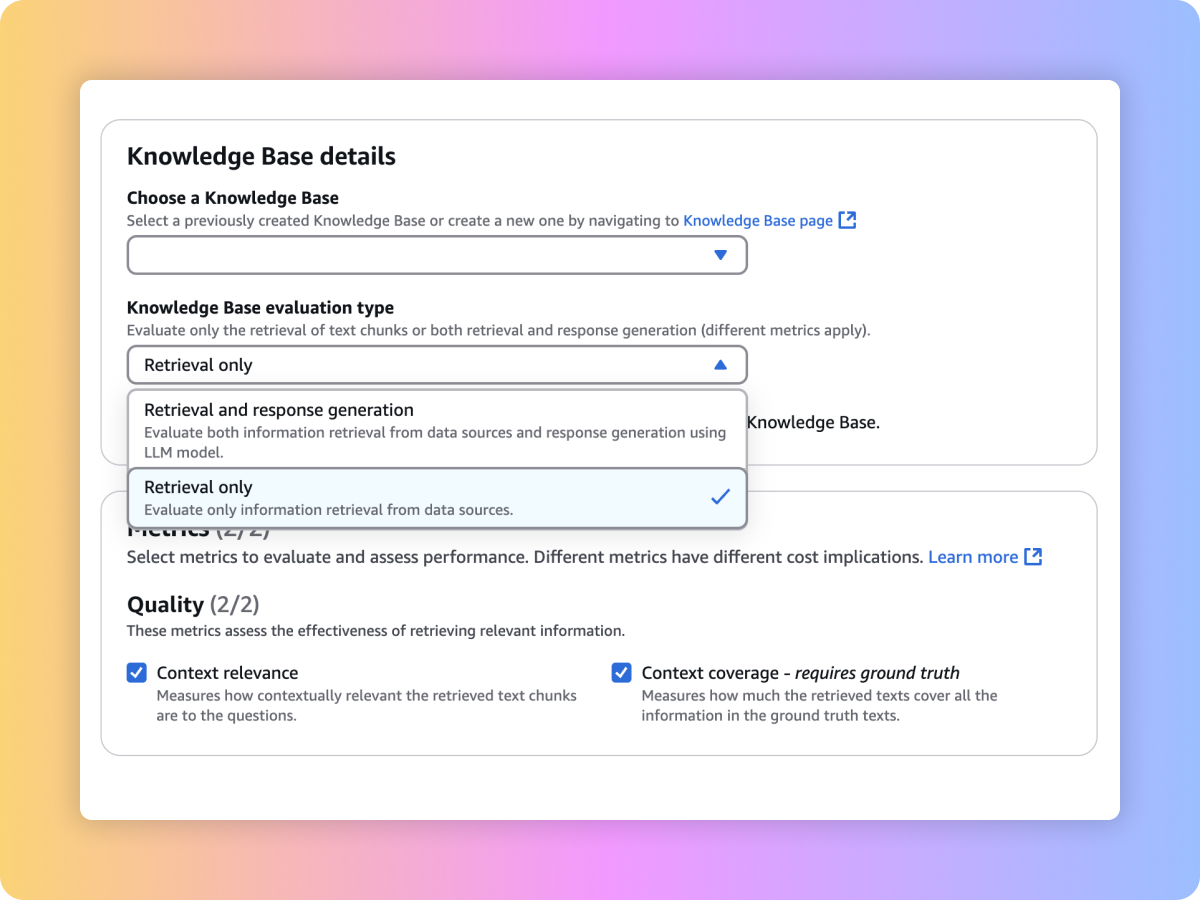
Evaluate the retrieval quality of your custom RAG system or Amazon Bedrock Knowledge Bases with your prompts and metrics such as context relevance and context coverage.
Evaluate the generated content of your end-to-end RAG workflow from either your custom RAG pipeline or Amazon Bedrock Knowledge Bases. Use your own prompts and metrics such as faithfulness (hallucination detection), correctness, and completeness.
Evaluate your end-to-end RAG workflow
Ensure complete and relevant retrieval from your RAG system
Evaluate FMs to select the best one for your use case
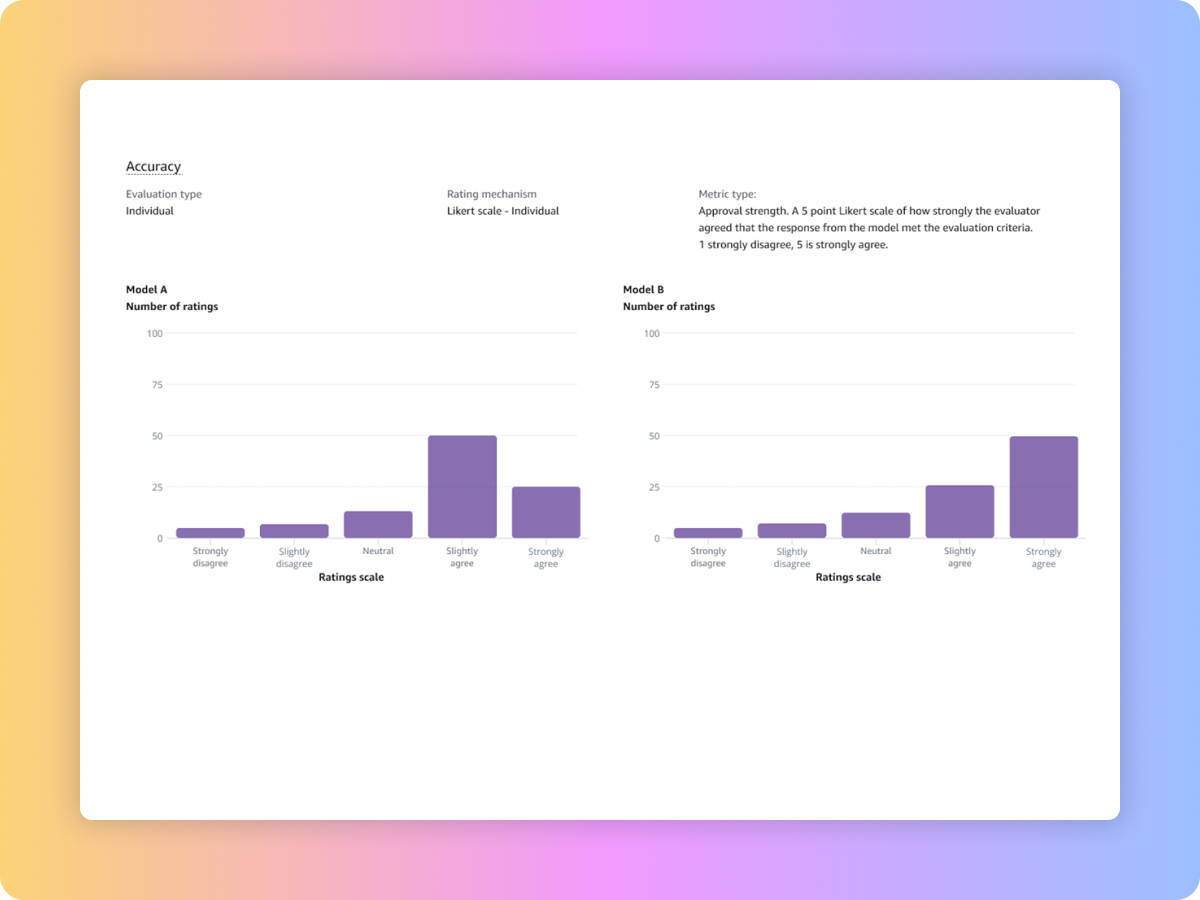
Compare results across multiple evaluation jobs to make decisions faster