Phép nhúng trong máy học là gì?
Phép nhúng trong máy học là gì?
Nhúng là biểu diễn số của các đối tượng trong thế giới thực mà hệ thống học máy (ML) và trí tuệ nhân tạo (AI) sử dụng để hiểu các lĩnh vực kiến thức phức tạp như con người. Ví dụ: các thuật toán điện toán hiểu điểm khác biệt giữa 2 và 3 là 1 đơn vị, cho thấy mối quan hệ gần gũi giữa 2 và 3 so với 2 và 100. Tuy nhiên, dữ liệu trong thế giới thực bao gồm các mối quan hệ phức tạp hơn. Ví dụ: tổ chim và hang sư tử là những cặp từ tương tự, trong khi ngày-đêm là các thuật ngữ trái ngược. Phép nhúng chuyển đổi các đối tượng trong thế giới thực thành các phép biểu diễn toán học phức tạp, trong đó ghi lại các thuộc tính vốn có và các mối quan hệ giữa dữ liệu trong thế giới thực. Toàn bộ quá trình được tự động hóa, trong đó các hệ thống AI tự tạo phép nhúng trong quá trình đào tạo và sử dụng phép nhúng này khi cần thiết để hoàn thành các nhiệm vụ mới.
Tại sao phép nhúng quan trọng?
Phép nhúng cho phép các mô hình học sâu hiểu các miền dữ liệu thực tế hiệu quả hơn. Phép này đơn giản hóa cách biểu diễn dữ liệu thực tế, trong khi vẫn giữ lại các mối quan hệ ngữ nghĩa và cú pháp. Điều này cho phép các thuật toán máy học trích xuất và xử lý các loại dữ liệu phức tạp và tạo điều kiện cho các ứng dụng AI sáng tạo. Các phần sau đây mô tả một số yếu tố quan trọng.
Giảm kích thước dữ liệu
Các nhà khoa học dữ liệu sử dụng phép nhúng để biểu diễn dữ liệu đa chiều trong không gian ít chiều. Trong khoa học dữ liệu, thuật ngữ chiều thường chỉ một đặc trưng hoặc thuộc tính của dữ liệu. Dữ liệu đa chiều hơn trong AI chỉ các tập dữ liệu có nhiều đặc trưng hoặc thuộc tính xác định từng điểm dữ liệu. Số lượng có thể là hàng chục, hàng trăm hoặc thậm chí hàng nghìn chiều. Ví dụ: một hình ảnh có thể được coi là dữ liệu đa chiều vì mỗi giá trị màu điểm ảnh là một chiều riêng biệt.
Khi được trình bày bằng dữ liệu đa chiều, các mô hình học sâu cần nhiều năng lực điện toán và thời gian hơn để học, phân tích và suy luận chính xác. Phép nhúng làm giảm số lượng chiều bằng cách xác định các điểm chung và mẫu giữa nhiều đặc trưng khác nhau. Do đó giảm tài nguyên điện toán và thời gian cần thiết để xử lý dữ liệu thô.
Đào tạo mô hình ngôn ngữ lớn
Nhúng cải thiện chất lượng dữ liệu khi đào tạo các mô hình ngôn ngữ lớn (LLM). Ví dụ: các nhà khoa học dữ liệu sử dụng phép nhúng để làm sạch dữ liệu đào tạo không còn bất thường ảnh hưởng đến quá trình học của mô hình. Các kỹ sư ML cũng có thể tái sử dụng các mô hình được đào tạo trước bằng cách thêm các phép nhúng mới để học chuyển giao, đòi hỏi phải tinh chỉnh mô hình nền tảng với các tập dữ liệu mới. Với phép nhúng, các kỹ sư có thể tinh chỉnh mô hình cho các tập dữ liệu tùy chỉnh từ thế giới thực.
Xây dựng ứng dụng sáng tạo
Nhúng cho phép các ứng dụng học sâu mới và trí tuệ nhân tạo (generative AI). Các kỹ thuật nhúng khác nhau được áp dụng trong kiến trúc mạng nơ-ron cho phép phát triển, đào tạo và triển khai các mô hình AI chính xác trong nhiều lĩnh vực và ứng dụng khác nhau. Ví dụ:
- Với phép nhúng hình ảnh, kỹ sư có thể xây dựng các ứng dụng thị giác máy tính có độ chính xác cao để phát hiện đối tượng, nhận dạng hình ảnh và thực hiện các tác vụ liên quan đến hình ảnh khác.
- Với phép nhúng từ, phần mềm xử lý ngôn ngữ tự nhiên có thể hiểu bối cảnh và mối quan hệ của các từ một cách chính xác hơn.
- Phép nhúng biểu đồ trích xuất và phân loại thông tin có liên quan từ các nút được kết nối với nhau để hỗ trợ phân tích mạng.
Các mô hình thị giác máy tính, chatbot AI và hệ thống giới thiệu AI đều sử dụng nhúng để hoàn thành các tác vụ phức tạp bắt chước trí thông minh của con người.
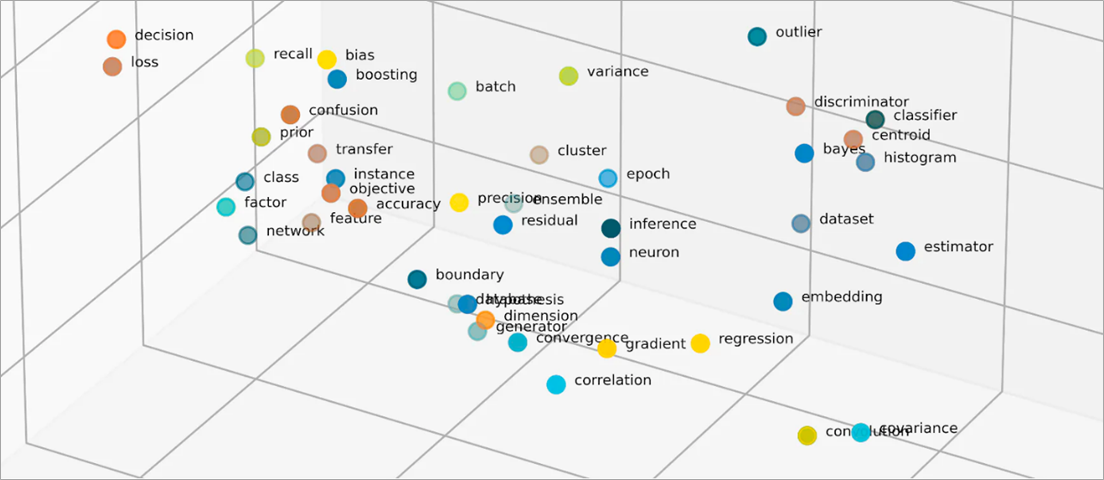
Véc-tơ trong phép nhúng là gì?
Các mô hình ML không thể diễn giải thông tin sao cho dễ hiểu ở định dạng thô và yêu cầu đầu vào là dữ liệu dạng số. Các mô hình này sử dụng phép nhúng mạng nơ-ron để chuyển đổi thông tin thực tế sang biểu diễn dạng số được gọi là véc-tơ. Véc-tơ là các giá trị số biểu diễn thông tin trong một không gian đa chiều. Véc-tơ giúp các mô hình ML tìm điểm tương đồng giữa các mục phân tán thưa thớt.
Mỗi đối tượng mà mô hình ML học được đều có nhiều đặc điểm hoặc đặc trưng khác nhau. Một ví dụ đơn giản là hãy xem xét các bộ phim và chương trình truyền hình sau đây. Mỗi bộ phim/chương trình được nêu đặc trưng qua thể loại, loại và năm phát hành.
The Conference (Kinh dị, 2023, Phim)
Upload (Hài, 2023, Chương trình truyền hình, Mùa 3)
Tales from the Crypt (Kinh dị, 1989, Chương trình truyền hình, Mùa 7)
Dream Scenario (Kinh dị-Hài, 2023, Phim)
Mô hình ML có thể diễn giải các biến dạng số như năm nhưng không thể so sánh các biến không phải dạng số như thể loại, loại, tập và tổng số mùa. Các véc-tơ nhúng mã hóa dữ liệu không phải dạng số thành một loạt các giá trị mà mô hình ML có thể hiểu và liên hệ. Ví dụ: sau đây là một phép biểu diễn giả định của các chương trình truyền hình được liệt kê trên đây.
The Conference (1,2, 2023, 20,0)
Upload (2,3, 2023, 35,5)
Tales from the Crypt (1,2, 1989, 36,7)
Dream Scenario (1,8, 2023, 20,0)
Số đầu tiên trong véc-tơ tương ứng với một thể loại cụ thể. Mô hình ML sẽ thấy rằng The Conference và Tales from the Crypt có cùng thể loại. Tương tự như vậy, mô hình sẽ tìm thấy nhiều mối quan hệ hơn giữa Upload và Tales from the Crypt dựa trên số thứ ba, đại diện cho kịch bản, mùa và tập. Khi sử dụng nhiều biến hơn, bạn có thể tinh chỉnh mô hình để cô đọng nhiều thông tin hơn trong một không gian véc-tơ nhỏ hơn.
Phép nhúng hoạt động như thế nào?
Phép nhúng chuyển đổi dữ liệu thô thành các giá trị liên tục mà mô hình ML có thể diễn giải. Các mô hình ML thường sử dụng mã hóa one-hot để ánh xạ biến phân loại thành các dạng mà mô hình có thể học. Phương pháp mã hóa chia từng danh mục thành các hàng và cột rồi gán các giá trị nhị phân cho các hàng và cột đó. Hãy xem xét các danh mục sản phẩm sau đây kèm theo giá.
|
Trái cây |
Giá |
|
Apple |
5,00 |
|
Cam |
7,00 |
|
Cà rốt |
10,00 |
Biểu diễn các giá trị bằng kết quả mã hóa one-hot trong bảng sau.
|
Apple |
Cam |
Lê |
Giá |
|
1 |
0 |
0 |
5,00 |
|
0 |
1 |
0 |
7,00 |
|
0 |
0 |
1 |
10,00 |
Bảng được biểu diễn toán học dưới dạng véc-tơ [1,0,0,5,00], [0,1,0,7,00] và [0,0,1,10,00].
Mã hóa one-hot mở rộng các giá trị cơ bản là 0 và 1 mà không cung cấp thông tin giúp các mô hình liên hệ giữa các đối tượng khác nhau. Ví dụ: mô hình không thể tìm thấy điểm tương đồng giữa táo và cam, mặc dù đều là trái cây, cũng như không thể phân biệt cam và cà rốt là trái cây và rau củ. Khi thêm nhiều danh mục vào danh sách, việc mã hóa dẫn đến các biến phân tán thưa thớt với nhiều giá trị trống chiếm không gian bộ nhớ khổng lồ.
Phép nhúng véc-tơ hóa các đối tượng vào một không gian ít chiều bằng cách biểu diễn điểm tương đồng giữa các đối tượng bằng giá trị số. Phép nhúng mạng nơ-ron đảm bảo vẫn quản lý được số lượng chiều bằng đặc trưng đầu vào mở rộng. Các đặc trưng đầu vào là đặc điểm của các đối tượng cụ thể mà thuật toán ML được giao nhiệm vụ phân tích. Giảm kích thước tạo điều kiện cho phép nhúng giữ lại thông tin mà các mô hình ML sử dụng để tìm điểm tương đồng và khác biệt từ dữ liệu đầu vào. Các nhà khoa học dữ liệu cũng có thể hình dung phép nhúng trong một không gian hai chiều để hiểu rõ hơn về mối quan hệ của các đối tượng phân tán.
Mô hình nhúng là gì?
Mô hình nhúng là các thuật toán được đào tạo để gói gọn thông tin thành các phép biểu diễn mật độ cao trong không gian đa chiều. Các nhà khoa học dữ liệu sử dụng mô hình nhúng để cho phép mô hình ML hiểu và suy luận với dữ liệu đa chiều. Đây là những mô hình nhúng phổ biến được sử dụng trong các ứng dụng ML.
Phân tích thành phần chính
Phân tích thành phần chính (PCA) là một kỹ thuật giảm kích thước nhằm rút gọn các loại dữ liệu phức tạp thành các véc-tơ ít chiều. Kỹ thuật này tìm các điểm dữ liệu có điểm tương đồng và nén thành các véc-tơ nhúng phản ánh dữ liệu gốc. Mặc dù PCA cho phép các mô hình xử lý dữ liệu thô hiệu quả hơn nhưng có thể xảy ra mất thông tin trong quá trình xử lý.
Phân tích giá trị suy biến
Phân tích giá trị suy biến (SVD) là một mô hình nhúng chuyển đổi một ma trận thành các ma trận suy biến. Các ma trận thu được giữ lại thông tin ban đầu, đồng thời cho phép các mô hình hiểu rõ hơn các mối quan hệ ngữ nghĩa của dữ liệu được biểu diễn qua các ma trận đó. Các nhà khoa học dữ liệu sử dụng SVD để kích hoạt nhiều tác vụ ML khác nhau, bao gồm nén hình ảnh, phân loại văn bản và đề xuất.
Word2Vec
Word2Vec là một thuật toán ML được đào tạo để liên kết và biểu diễn các từ trong không gian nhúng. Các nhà khoa học dữ liệu cung cấp các tập dữ liệu văn bản khổng lồ cho mô hình Word2Vec để cho phép hiểu ngôn ngữ tự nhiên. Mô hình này tìm điểm tương đồng trong các từ bằng cách xem xét bối cảnh và các mối quan hệ ngữ nghĩa.
Có hai biến thể của Word2Vec là Túi từ liên tục (CBOW) và Skip-gram. CBOW cho phép mô hình dự đoán một từ từ ngữ cảnh nhất định, trong khi Skip-gram suy ra ngữ cảnh từ một từ cụ thể. Mặc dù là kỹ thuật nhúng từ hiệu quả nhưng Word2Vec không thể phân biệt chính xác những điểm khác biệt về ngữ cảnh của cùng một từ được sử dụng để ám chỉ các ý nghĩa khác nhau.
BERT
BERT là một mô hình ngôn ngữ dựa trên bộ chuyển đổi, được đào tạo với các tập dữ liệu khổng lồ để hiểu ngôn ngữ như con người. Giống như Word2Vec, BERT có thể tạo các phép nhúng từ từ dữ liệu đầu vào đã dùng để đào tạo mô hình. Ngoài ra, BERT có thể phân biệt ý nghĩa ngữ cảnh của các từ khi áp dụng cho các cụm từ khác nhau. Ví dụ: BERT tạo các phép nhúng khác nhau cho từ “play” (chơi) như trong “I go to a play” (Tôi đi xem kịch) và “I like to play” (Tôi thích đi chơi).
Phép nhúng được tạo ra như thế nào?
Các kỹ sư sử dụng mạng nơ -ron để tạo nhúng. Mạng nơ-ron bao gồm các lớp nơ-ron ẩn đưa ra các quyết định phức tạp lặp đi lặp lại. Khi tạo phép nhúng, một trong các lớp ẩn học cách phân vùng các tính năng đầu vào thành véc-tơ. Quy trình này diễn ra trước các lớp xử lý đặc trưng. Quá trình này được các kỹ sư giám sát và hướng dẫn với các bước sau:
- Các kỹ sư cung cấp cho mạng nơ-ron một số mẫu véc-tơ được chuẩn bị thủ công.
- Mạng nơ-ron học hỏi từ các mẫu được phát hiện trong mẫu và sử dụng kiến thức để đưa ra dự đoán chính xác từ dữ liệu không nhìn thấy.
- Đôi khi, các kỹ sư có thể cần tinh chỉnh mô hình để đảm bảo phân phối các tính năng đầu vào vào không gian chiều thích hợp.
- Theo thời gian, các phép nhúng hoạt động độc lập, cho phép các mô hình ML tạo ra đề xuất từ các phép biểu diễn véc-tơ hóa.
- Các kỹ sư tiếp tục theo dõi hiệu năng của phép nhúng và tinh chỉnh với dữ liệu mới.
AWS có thể hỗ trợ các yêu cầu nhúng của bạn như thế nào?
Amazon Bedrock là một dịch vụ được quản lý đầy đủ cung cấp sự lựa chọn các mô hình nền tảng hiệu suất cao (FM) từ các công ty AI hàng đầu, cùng với một loạt các tính năng để xây dựng các ứng dụng trí tuệ nhân tạo tạo (generative AI). Amazon Nova là một thế hệ mới của các mô hình nền tảng (FM) hiện đại (SOTA) mang lại trí thông minh tiên tiến và hiệu suất giá cả hàng đầu trong ngành. Đây là những mô hình mạnh mẽ, đa năng được xây dựng để hỗ trợ nhiều trường hợp sử dụng khác nhau. Bạn có thể sử dụng các mô hình này theo nguyên trạng hoặc tùy chỉnh bằng dữ liệu của riêng bạn.
Titan Embeddings là LLM dịch văn bản thành phép biểu diễn bằng số. Mô hình Titan Embeddings hỗ trợ truy xuất văn bản, tương đồng về ngữ nghĩa và phân cụm. Văn bản đầu vào tối đa là mã thông báo 8K và độ dài véc-tơ đầu ra tối đa là 1536.
Các nhóm học máy cũng có thể sử dụng Amazon SageMaker để tạo nhúng. Amazon SageMaker là trung tâm nơi bạn có thể xây dựng, đào tạo và triển khai các mô hình ML trong một môi trường an toàn và có thể điều chỉnh quy mô. Trung tâm này cung cấp một kỹ thuật nhúng được gọi là Object2Vec mà các kỹ sư có thể sử dụng để véc-tơ hóa dữ liệu đa chiều trong một không gian ít chiều. Bạn có thể sử dụng các phép nhúng đã học để tính mối quan hệ giữa các đối tượng cho các tác vụ hạ nguồn như phân loại và hồi quy.
Bắt đầu với việc nhúng trên AWS bằng cách tạo tài khoản ngay hôm nay.
Các bước tiếp theo trên AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages