Containers
Lacework’s batch workloads on Amazon EKS: Lessons learned
This post was co-written with Derek Brown, Infrastructure Engineer, Lacework
Introduction
Lacework is a security platform that automatically monitors and detects misconfigurations and security vulnerabilities across our customers’ cloud environments. Lacework takes a data-driven approach to alerting and detection, consuming trillions of events from a huge list of sources including eBPF, Kubernetes Audit Logs, cloud APIs (including AWS), vulnerability scanners, and more. This data is condensed into an easy-to-understand Polygraph representation that security professionals can use to identify, investigate and fix vulnerabilities.
In order to analyze all of this data in a developer-friendly and cost-efficient way, the Lacework Engineering team partnered with Amazon Web Services (AWS) Solutions Architects to design a scalable data platform on Amazon Elastic Kubernetes Service (Amazon EKS), using resources from AWS’s Data on EKS (DoEKS) Project. This post delves into the valuable lessons learned during the design and production of this system. As a result of this collaboration, the Lacework infrastructure is substantially more resilient and can execute workloads at 30–40% of the cost of our previous solution.
Background: Lacework’s Data Infrastructure
In order to analyze customer data, Lacework needs a highly reliable, scalable, and efficient environment for executing batch workloads (such as batch processing or machine learning [ML] pipelines). The center of this infrastructure is an internal batch pipeline orchestration system called Hawkeye. In a nutshell:
- Hawkeye consumes batch workflow definitions from a Kubernetes CRD (Custom Resource Definition).
- Hawkeye materializes the workflow definition into a directed acyclic graph (DAG) of jobs to be executed for each customer.
- Hawkeye launches these jobs directly via the Kubernetes Job resource application programming interface [API].
- Hawkeye monitors the status of these jobs by making periodic GET calls to the Kubernetes API endpoint for each job.
Hawkeye was also extended to provide support for launching Spark jobs in our environment. It did this by using the Spark Operator:
- For Spark Applications, Hawkeye would create a SparkApplication CRD instead of a Job resource.
- The Spark Operator, installed in our clusters, would consume the SparkApplication CRD.
- When the Spark Operator detects a new SparkApplication CRD, it forks a spark-submit process to launch the Spark Driver container containing the user’s Spark application.
- The Spark Driver optionally launches Spark Executor containers (also by talking directly to the Kubernetes API), which perform computation for the Spark application.
Hawkeye jobs are central to the Lacework data infrastructure. Hawkeye jobs are used to consume data from various sources (including MySQL, Snowflake, Amazon Simple Storage Service [Amazon S3], and others), and produce meaningful artifacts and signals for Lacework customers (such as the Polygraph, vulnerability alerts, and more):
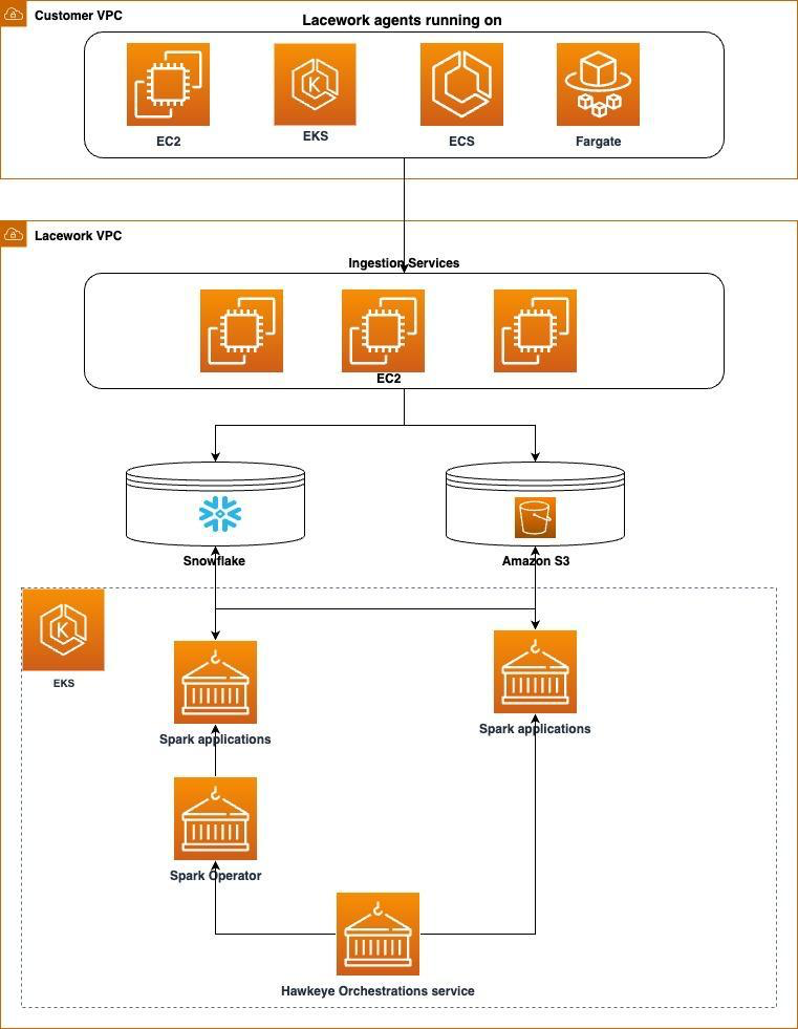
Figure 1: Flow diagram of how data is ingested and processed within the Lacework environment
The scale of these batch workloads is projected to increase exponentially over time. Lacework is rapidly gaining customers and adding capabilities to the platform. To make sure we can meet this demand in a cost-effective way, we have encouraged our internal developers to adopt batch frameworks as opposed to hard-to-optimize long-lived services.
Tipping point: Hawkeye launches a huge volume of jobs
In Spring 2023, one of our external (non-AWS) dependencies suffered an outage, requiring that we re-run nearly all of our batch pipelines for that period. This caused a service degradation. The Hawkeye orchestrator attempted to launch three times the normal number of jobs in our cluster. This also caused a corresponding increase in load to the AWS EKS control plane, as Hawkeye and other controllers and services increased the number of requests they issued to the Kubernetes API. We quickly began seeing high request latencies and rate limiting errors from the Kubernetes API server. This impacted our production services and tooling. Because of both of these conditions, the built-in Kubernetes Job controller also became overloaded. Even though pods had completed, the job resources weren’t updated with this status. This situation triggered a traffic amplification loop, causing excessive creation of jobs.
Fortunately, we were able to resolve this situation with the help of the Amazon EKS’ incident management team. On the Lacework side, we manually disabled less-critical certain workflows, and reduced the allowed concurrency in Hawkeye. The AWS team scaled our Amazon EKS control plane resources to handle the increased workload. The AWS team also tweaked parameters on the job controller to allow it to recover and better sync pod and job state.
This provided our team an impetus to better understand, refactor, and monitor Hawkeye’s integration with the Kubernetes API to make sure our cluster remained stable.
Lesson learned: Controlling Kubernetes API request behavior
To mitigate the risk of this incident recurring, we needed to break the feedback loop between the Kubernetes API server backoff mechanism and Hawkeye. Working with our AWS Technical Account Manager (TAM), we decided to deploy a custom Kubernetes PriorityLevelConfiguration in our cluster. This feature of Kubernetes allows us to assign priorities and concurrent request allocations to each Kubernetes client. By prioritizing requests from our critical infrastructure, and also reducing the number of allowed concurrent requests from our asynchronous components (including Hawkeye) we were able to mitigate the risk of overloading the cluster.
Lesson learned: Building a Proxy Service to consume the Kubernetes API efficiently
We collaborated with the AWS account team and AWS Worldwide Specialist Organization (WWSO) Container specialists. We learned we were inefficiently utilizing the Kubernetes API. To ensure our workloads could scale reliably, we built and designed an efficient proxy service for communicating with the Kubernetes API.
At the time of the incident, Hawkeye’s integration with Kubernetes was straightforward:
- Hawkeye doesn’t have any form of persistence, so it relied on Kubernetes as a source of truth for whether a job has run. Hawkeye generates a unique job identifier, then issues a GET request to Kubernetes to see if this job was already run.
- Hawkeye then periodically polled the Kubernetes API to determine if a job was completed.
- Hawkeye also had limited handling of PodStatus messages, which allows it to determine the failure mode of a job.

Figure 2: Flow diagram of how Hawkeye issues Kubernetes requests.
Shortly after the incident, our AWS TAM provided us with a Grafana Dashboard template (you can learn more in the Troubleshooting Amazon EKS API servers with Prometheus post) that helped us identify how the implementation contributed to this incident:
- The Kubernetes API tends to perform poorly in response to many concurrent requests, due to constraints of the controller manager and etcd. Hawkeye’s initial design approached these limits for SparkApplication and Job resources, which causes high latencies when communicating with the API server.
- There are also limits on the number of concurrent requests (–max-requests-inflight) that can be issued to an Kubernetes API server server/pod (i.e., 400 by default). These limits are put in place to ensure that Kubernetes backend components (such as the kube-controller-manager and etcd itself) are not overwhelmed. The high request latency caused Hawkeye to issue an increasing number of concurrent requests, eventually triggering these rate limiting protections.
- The Kubernetes JobStatus and PodStatus APIs are difficult to consume. Many fields are unschematized, which require an client to parse strings and handle dozens of potential error and edge cases. Hawkeye missed a number of these rare cases, which caused occasional retries that resulted in unnecessary spend.
To streamline our interaction with the Kubernetes API and ensure that developers follow best practices, we have developed the Ephemeral Job Controller (EJC) as a proxy layer. This service not only simplifies the process but also safeguards Kubernetes from potential overload. Here’s how it enhances the developer experience:
- Efficient status queries: For retrieving job statuses, we leverage the Kubernetes Informer library. This library efficiently tracks all Jobs and Pods within a specific namespace using the Kubernetes WATCH API. This approach enables us to handle a high volume of status queries without requiring round trips to the Kubernetes API.
- Controlled job creation and requests: To prevent overloading the API server, we created a distributed semaphore for job creation and a distributed counter to manage request volumes. These mechanisms allow us to set limits on concurrent jobs and requests sent to the API server.
- Enforcement of best practices: Our system incorporates a validation and mutation layer, ensuring the enforcement of best practices. This includes checks for ImagePullPolicy, Backoff/Restart Policies, Requests/Limits, and more.
- Automated job reaping: When jobs terminate, they are automatically reaped by an internal component, with historical data stored in MySQL. This feature enables clients to access historical job information, even when these jobs are no longer present in Kubernetes.
- Intelligent handling of failure modes: Kubernetes jobs and pods can be in a wide variety of conditions, statuses, and states. In some instances, the labeled job status doesn’t align with our specific expectations. For example, a Job containing a pod with a missing config map is not labeled as failed, even though this ConfigMap will never be created. EJC consumes a variety of status information from the Kubernetes job and pod, and returns this to callers in a schematized enum of possible states.
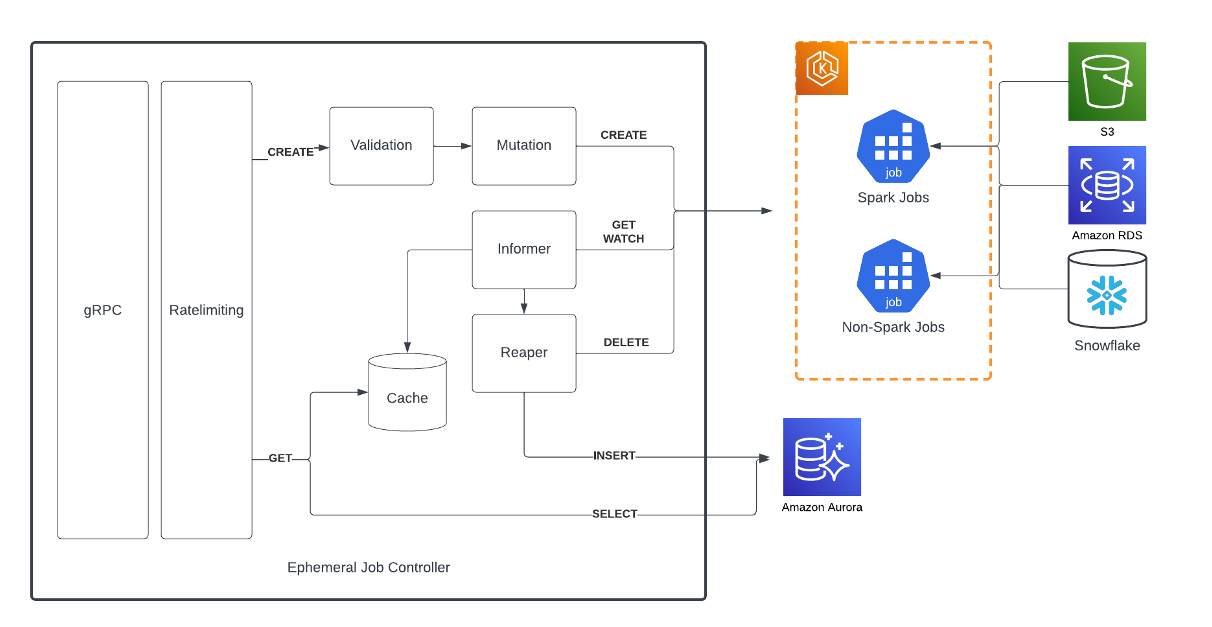
Figure 3: Component diagram of the Ephemeral Job Controller
EJC has helped us reduce the API request volume by more than 100-fold, and allowed us to scale our ephemeral job infrastructure to support our growing workloads.
Lesson learned: Launching Spark jobs
The Spark Operator suffers from some similar Kubernetes integration issues:
- Although the Spark Operator is implemented in golang, under the hood it launches Spark applications by forking to the spark-submit CLI, a utility included in the Spark binary. This leads to a few problems:
- This solution is not very performant. Spinning up the spark-submit processes is fairly slow, and the Spark Operator can only launch a limited number of these processes at a time to avoid excess memory consumption.
- Because the interface between spark-submit and the Spark Operator is stdout/stderr, no schematized information is passed between the components. This limits the ability of the Spark Operator to provide feedback to clients.
- Because the Kubernetes pods are created via the spark-submit CLI, the Spark Operator has a limited ability to customize these pods during pod creation. To get around this, the Spark Operator implements a Mutating Webhook that intercepts spark-submit requests, and modifies the underlying pod objects. We found this path to be suboptimal at production scale, resulting in pods missing critical configuration like node selectors, tolerations and volume mounts.
To address these problems, we decided to abandon the Spark Operator, and instead build the necessary Spark functionality within the Ephemeral Job Controller (EJC) itself. Users can launch a Spark Job by calling a specific Spark endpoint of the EJC proxy, which launches a Spark Driver directly as a Kubernetes Job. This has been a significant improvement:
- Latency/Resource Utilization – Because EJC is implemented entirely in Golang, EJC is much more performant than the Spark Operator. EJC creates Kubernetes jobs directly (instead of forking to spark-operator), which substantially reduces request latency. An EJC instance also consumes <100MI of RSS while managing thousands of concurrent jobs (including the in-memory job cache), compared to >8Gi for the Spark Operator for the same set of jobs.
- Better handling of failure modes- EJC can more reliably detect when Spark applications enter into failure modes and act to retry the job. This improves throughput of our batch workflows, and reduces alert noise and manual debugging effort.
- Improved correctness– Because EJC creates jobs synchronously (rather than with a webhook), we no longer see pods missing required properties; jobs are either created properly, or fail with an exception propagated appropriately to the client.
Conclusion
This investigation yielded some high-level takeaways for others operating Kubernetes Batch jobs at scale:
- Be deliberate about how clients are consuming the Kubernetes API. Kubernetes is mostly designed with the assumption that clients are well-behaved. As a result, it doesn’t have an ideal out-of-the-box configuration for protecting quality-of-service when barraged by requests from different clients. Take the time to carefully understand each of the behavior of clients (including operators, and controllers you may have downloaded from the open source) to ensure your cluster remains healthy. Additionally consider creating frameworks or services as a buffer between developers and the API.
- Don’t wait until an incident to plan for an overload scenario. Consider benchmarking your services in anticipation of increased load. Kubernetes in particular has numerous latent scaling limits, which can lead to production issues with little warning. Using a tool like Kubemark can help you to understand the API consumption footprint of your orchestration and scheduling system, prevent API consumption regressions, and anticipate when scaling will be required. Additionally, you may consider performing live “drills” to test the ability of your service to handle increased load.
- Lean on your AWS team. Our AWS team (Account Team, Containers WSSO, AWS TAM, DoEKS) partnered with us to provide a wealth of resources and knowledge gained from other customers; advice on best practices, recommended frameworks, pre-written dashboards and more. We could not have built this system without their support.
About the authors

Derek Brown, Lacework
Derek Brown is an Infrastructure Engineer at Lacework based in Mountain View, California. He is passionate about building reliable and ergonomic service infrastructure. When away from the keyboard, you can find him scuba diving, playing music, or studying for the bar exam.