Amazon Web Services ブログ
Amazon Redshift ML が一般公開されました — SQL を使用して機械学習モデルを作成し、データから予測を行う
Amazon Redshift では SQL を使用して、データウェアハウス、運用データベース、データレイク全体で、エクサバイトの構造化データと半構造化データをクエリし、組み合わせることができます。AQUA (Advanced Query Accelerator) の一般提供が開始されたので、追加コストやコードの変更なしで、クエリのパフォーマンスを最大で 10 倍向上させることができます。実際、Amazon Redshift は、他のクラウドデータウェアハウスよりも最大で 3 倍優れたコストパフォーマンスを提供します。
しかし、さらに一歩進んで、このデータを処理して機械学習 (ML) モデルをトレーニングし、ウェアハウス内のデータからのインサイト生成にこれらのモデルを使用したい場合は、どうしたらよいでしょうか。 たとえば、収益の予測、顧客のチャーン予測、異常の検出などのユースケースを実装するには? 以前なら、トレーニングデータを Amazon Redshift から Amazon Simple Storage Service (Amazon S3) バケットにエクスポートし、機械学習トレーニングプロセス (たとえば Amazon SageMaker を使用します) を設定してから、始めなければなりませんでした。このプロセスには、さまざまなスキルがいくつも必要で、完了するには何人も必要になります。もっと簡単にできないでしょうか。
現在、Amazon Redshift MLが一般公開されており、Amazon Redshift クラスターから直接、機械学習モデルを作成、トレーニング、デプロイすることができます。機械学習モデルを作成するには、シンプルな SQL クエリを使用して、モデルのトレーニングに使用するデータと、予測する出力値を指定します。たとえば、マーケティング活動の成功率を予測するモデルを作成するには、1 つ以上のテーブルで、顧客のプロフィールと、前回のマーケティングキャンペーンの結果を含む列を選択して入力を定義し、さらに予測を出力する列を定義します。この例では、顧客がキャンペーンに関心を示したかどうかを示す列が、出力列になります。
SQL コマンドを実行してモデルを作成すると、Redshift ML は指定されたデータを Amazon Redshift から S3 バケットに安全にエクスポートし、Amazon SageMaker Autopilot を呼び出してデータを準備します (事前処理および特徴エンジニアリング)。さらに適切な事前構築済みのアルゴリズムを選択し、モデルトレーニングにアルゴリズムを適用します。オプションで、使用するアルゴリズム (XGBoost など) を指定できます。

Redshift ML は、Amazon Redshift、S3、および SageMaker の間の、トレーニングとコンパイルに関するステップを含んだすべてのインタラクションを処理します。モデルがトレーニングされると、Redshift ML は Amazon SageMaker Neo を使用してモデルをデプロイ用に最適化し、SQL 関数として使用できるようにします。SQL 関数を使用すると、クエリ、レポート、ダッシュボードのデータに、機械学習モデルを適用できます。
Redshift ML には、Amazon Virtual Private Cloud (VPC) のサポートなど、プレビューのときには利用できなかった、多くの新機能が追加されています。例:
- Amazon Redshift クラスターへの SageMaker モデルのインポートが可能になりました (ローカル推論)。
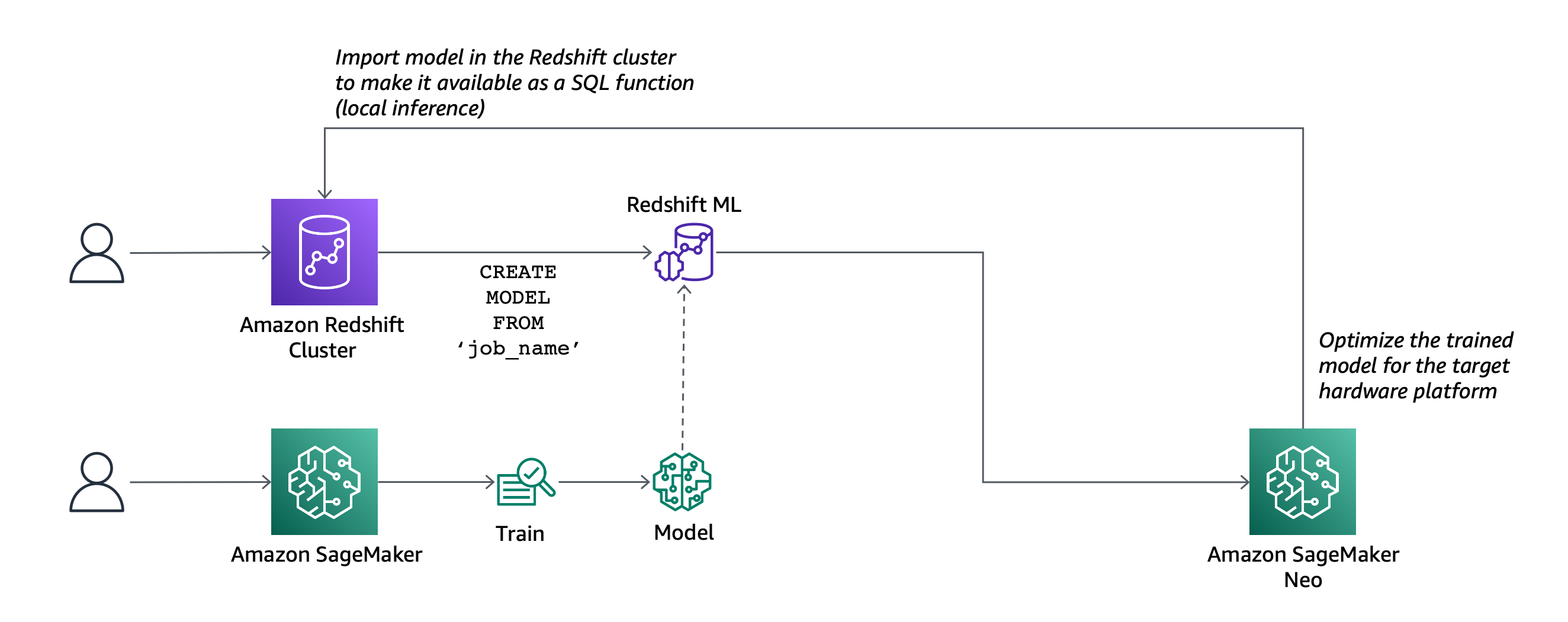
- 既存の SageMaker エンドポイントを使用して予測を行う SQL 関数を作成することもできます (リモート推論)。この場合、Redshift ML は処理を高速化するために、エンドポイントへの呼び出しをバッチ処理しています。

これらの新機能を実際に使用する方法について調べる前に、AWS データベースと分析サービスにおける、Redshift ML と類似機能の違いを見てみましょう。
| 機械学習の機能 | データ | SQL によるトレーニング
|
SQL 関数を使用した予測
|
| Amazon Redshift ML |
データウェアハウス S3 データレイク (Redshift Spectrum を使用) |
はい、次のものを使用しています。
Amazon SageMaker Autopilot |
はい。Amazon Redshift クラスター内でモデルをインポートして実行することも、SageMaker エンドポイントを使用して呼び出すこともできます。 |
| Amazon Aurora ML | リレーショナルデータベース
(MySQL または PostgreSQL との互換性) |
なし |
はい、SageMaker エンドポイントを使用します。 感情分析のための Amazon Comprehend とのネイティブ統合も可能です。 |
| Amazon Athena ML |
S3 データレイク 他のデータソースは、Athena Federated Query 経由で使用できます。 |
なし | はい、SageMaker エンドポイントを使用します。 |
Redshift ML を使用した機械学習モデルの構築
マーケティングオファーを顧客が受け入れるか、それとも拒否するかを予測するモデルを構築しましょう。
S3 と SageMaker との間のやりとりを管理するには、これらのリソースにアクセスするためのアクセス許可が Redshift ML に必要です。ドキュメントで説明されているように、AWS Identity and Access Management (IAM) ロールを作成します。ロール名は RedshiftML とします。ロールの信頼ポリシーにより、Amazon Redshift と SageMaker の両方がロールを引き受けて、他の AWS のサービスとやり取りできるようになります。
Amazon Redshift コンソールから、クラスターを作成します。クラスターのアクセス許可で、RedshiftML IAM ロールを関連付けます。クラスターが利用可能になったら、同僚の Julien が SageMaker Autopilot が発表されたときに書いた、この非常に興味深いブログ記事で使用したのと同じデータセットをロードします。
私が使用しているファイル (bank-additional-full.csv) は CSV 形式です。各行は、顧客とのダイレクトマーケティング活動を表します。最後の列 (y) は、活動の結果を示します (販売したサービスを顧客がサブスクライブした場合)。
ファイルの最初の数行は次の通りです。最初の行には、ヘッダーが含まれています。
S3 バケットの 1 つに、ファイルを格納します。S3 バケットは、データをアンロードし、SageMaker トレーニングアーティファクトを保存するために使用されます。
次に、コンソールで Amazon Redshift クエリエディターを使用して、データをロードするテーブルを作成します。
CREATE TABLE direct_marketing (
age DECIMAL NOT NULL,
job VARCHAR NOT NULL,
marital VARCHAR NOT NULL,
education VARCHAR NOT NULL,
credit_default VARCHAR NOT NULL,
housing VARCHAR NOT NULL,
loan VARCHAR NOT NULL,
contact VARCHAR NOT NULL,
month VARCHAR NOT NULL,
day_of_week VARCHAR NOT NULL,
duration DECIMAL NOT NULL,
campaign DECIMAL NOT NULL,
pdays DECIMAL NOT NULL,
previous DECIMAL NOT NULL,
poutcome VARCHAR NOT NULL,
emp_var_rate DECIMAL NOT NULL,
cons_price_idx DECIMAL NOT NULL,
cons_conf_idx DECIMAL NOT NULL,
euribor3m DECIMAL NOT NULL,
nr_employed DECIMAL NOT NULL,
y BOOLEAN NOT NULL
);COPY コマンドを使用して、データをテーブルにロードします。同じ S3 バケットを使用してデータのインポートとエクスポートをしているので、以前に作成したのと同じ IAM ロール (RedshiftML) を使用できます。
ここで、新しい CREATE MODEL ステートメントを使用して、SQL インタフェースからモデルを直接作成します 。
CREATE MODEL direct_marketing
FROM direct_marketing
TARGET y
FUNCTION predict_direct_marketing
IAM_ROLE 'arn:aws:iam::123412341234:role/RedshiftML'
SETTINGS (
S3_BUCKET 'my-bucket'
);この SQL コマンドでは、モデルの作成に必要なパラメータを指定します。
FROM—direct_marketingテーブルのすべての行を選択しますが、テーブルの名前をネストされたクエリに置き換えることができます (以下の例を参照)。TARGET— これが予測したい列 (この場合はy) です。FUNCTION— 予測を行う SQL 関数の名前です。IAM_ROLE— モデルの作成、トレーニング、デプロイを行うために Amazon Redshift と SageMaker が引き受ける IAM ロールです。S3_BUCKET— トレーニングデータが一時的に保存される S3 バケットです。また、モデルのアーティファクトのコピーを保持するように選択した場合は、モデルアーティファクトが保存される S3 バケットです。
ここでは、CREATE MODEL ステートメントのためにシンプルな構文を使用しています。上級ユーザーは、他にも次のようなオプションも利用できます。
MODEL_TYPE— XGBoost や多層パーセプトロン (MLP) など、特定のモデルタイプをトレーニングに使用します。このパラメータを指定しない場合、SageMaker Autopilot は適切なモデルクラスを選んで使用します。PROBLEM_TYPE— 解決する問題のタイプ (回帰、バイナリ分類、またはマルチクラス分類) を定義します。このパラメータを指定しないと、問題のタイプは、トレーニング中にデータに基づいて検出されます。OBJECTIVE— モデルの品質の測定に使用される、目標メトリクスです。トレーニング中にこのメトリクスは最適化され、データから最適な見積もりを提供します。メトリックを指定しない場合、デフォルトの動作では、回帰には平均二乗誤差 (MSE)、バイナリ分類には F1 スコア、マルチクラス分類には精度が使用されます。その他の使用可能なオプションは、F1Macro (マルチクラス分類に F1 スコアリングを適用するため) と曲線下面積 (AUC) です。目標メトリクスの詳細については、SageMaker のドキュメントを参照してください。
モデルの複雑さとデータの量によっては、モデルが利用可能になるまでに時間がかかることがあります。SHOW MODEL コマンドを使用して、いつ利用可能になるのか確認します。
コンソールでクエリエディタを使用してこのコマンドを実行すると、次の出力が得られます。

予想どおり、モデルは現在 TRAINING の状態です。
このモデルを作成したとき、テーブル内のすべての列を、入力パラメータとして選択しました。入力パラメーターを少なくしてモデルを作成すると、どうなるでしょうか。 クラウド上にいて、リソースが限られているために遅くなっているわけではないので、テーブルの列のサブセットを使用して、別のモデルを作成します。
CREATE MODEL simple_direct_marketing
FROM (
SELECT age, job, marital, education, housing, contact, month, day_of_week, y
FROM direct_marketing
)
TARGET y
FUNCTION predict_simple_direct_marketing
IAM_ROLE 'arn:aws:iam::123412341234:role/RedshiftML'
SETTINGS (
S3_BUCKET 'my-bucket'
);しばらくすると、最初のモデルの準備ができ、SHOW MODEL からこの出力が得られます。コンソールの実際の出力は複数のページにわたりますので、結果をマージしてフォローしやすくしました。

出力から、モデルが BinaryClassification として正しく認識され、F1 が目的として選択されていることがわかります。F1 スコアは、適合率と再現率の両方を考慮した指標です。これは、1 (完全な適合率と再現率) と0 (可能な限り低いスコア) の間の値を返します。モデルの最終スコア (validation:f1) は 0.79 です。この表では、モデル用に作成された SQL 関数 (predict_direct_marketing) の名前、パラメータとそのタイプ、およびトレーニングコストの見積もりも表示されます。
2 番目のモデルが準備できたら、F1 のスコアを比較します。2 番目のモデルの F1 スコアは、最初のモデルよりも低い (0.66) です。ただし、パラメーターの数が少ないほど、SQL 関数は新しいデータに適用しやすくなります。機械学習ではよくあることですが、複雑さと使いやすさとの間でバランスをとらなければなりません。
Redshift ML を使用して予測する
モデルを 2 つ準備できたので、SQL 関数を使用して予測することができます。最初のモデルで、トレーニングに使用したものと同じデータにモデルを適用したときの、偽陽性 (間違った陽性予測) と偽陰性 (間違った陰性予測) の数をチェックします。
SELECT predict_direct_marketing, y, COUNT(*)
FROM (SELECT predict_direct_marketing(
age, job, marital, education, credit_default, housing,
loan, contact, month, day_of_week, duration, campaign,
pdays, previous, poutcome, emp_var_rate, cons_price_idx,
cons_conf_idx, euribor3m, nr_employed), y
FROM direct_marketing)
GROUP BY predict_direct_marketing, y;クエリの結果は、モデルが肯定的な結果よりも負の予測の方が優れていることを示しています。実際、真陰性の数が真陽性よりもはるかに大きい場合でも、偽陰性よりもはるかに多くの偽陽性があります。結果の意味がはっきりと分かるように、次のスクリーンショットに緑と赤のコメントを追加しました。

2 番目のモデルを使用すると、どれくらいの顧客がマーケティングキャンペーンに興味があるのかを確認できます。理想を言えば、トレーニングに使用したものと同じデータではなく、新しい顧客データに対してこのクエリを実行するべきです。
SELECT COUNT(*)
FROM direct_marketing
WHERE predict_simple_direct_marketing(
age, job, marital, education, housing,
contact, month, day_of_week) = true;素晴らしい、7,000 もの潜在顧客が結果に表示されました。

利用可能なリージョンと料金
Redshift ML は本日から、米国東部 (オハイオ)、米国東部 (バージニア北部)、米国西部 (オレゴン)、米国西部 (サンフランシスコ)、カナダ (中部)、欧州 (フランクフルト)、欧州 (アイルランド)、欧州 (パリ)、欧州 (ストックホルム)、アジアパシフィック (香港)、アジアパシフィック (東京)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、南米 (サンパウロ) の AWS リージョンでご利用いただけます。詳細については、AWS リージョン別のサービスリストをご覧ください。
Redshift ML では、使用した分に対してのみお支払いいただきます。新しいモデルをトレーニングする場合、Redshift ML で使用する Amazon SageMaker Autopilot と S3 リソースの料金をお支払いいただきます。予測を行う場合は、この記事で使用した例のように、Amazon Redshift クラスターにインポートされたモデルについての追加のコストは必要ありません。
Redshift ML では、既存の Amazon SageMaker エンドポイントを使用して推論を行うこともできます。その場合は、リアルタイム推論の、通常の SageMaker の料金が適用されます。ここでは、Redshift ML を使用してコストを管理する方法について、いくつかヒントをご紹介します。
詳細については、Redshift ML がプレビューで発表された時の、こちらのブログ記事と、ドキュメントを参照してください。
Redshift ML を使用して、データから、より優れたインサイトを得ましょう。
– Danilo