Amazon Web Services ブログ
Category: Amazon SageMaker

AWS Weekly Roundup: Amazon Bedrock の Claude Sonnet 4.6、Kiro in GovCloud リージョンの Kiro、新しいエージェントプラグインなど (2026 年 2 月 23 日)
2026 年 2 月 16 日週、私のチームは米国サンノゼで開催された Developer Week で大勢の […]

カスタム Amazon Nova モデル用の Amazon SageMaker Inference の発表
AWS New Summit 2025 で Amazon SageMaker AI の Amazon Nova […]
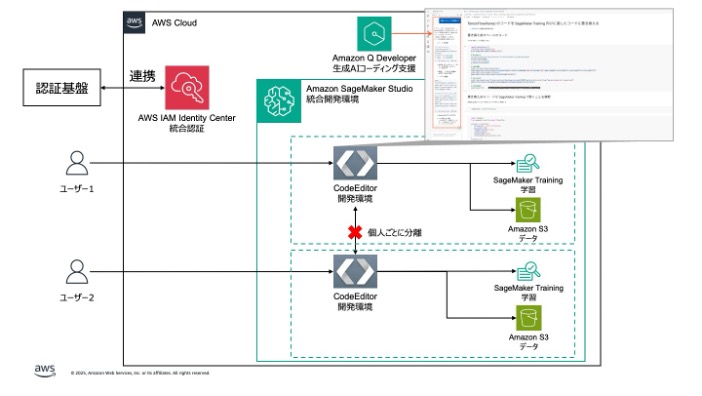
寄稿: JFE スチールが挑むインテリジェント製鉄所への道 – Amazon SageMaker AI による CPS 開発実行基盤の構築
JFE スチール株式会社における Amazon SageMaker AI を中核とした CPS 開発実行基盤の構築事例をご紹介します。ブログの中では、プロジェクトの背景、開発体制、AWS の活用方法、そして今後の AWS IoT Greengrass によるエッジ配信基盤の展開についても解説します。

Agentic workflowを使用したAmazon Nova Premierによるコード移行の効率化
多くの企業は、保守と拡張が困難になった古いテクノロジーで構築されたレガシーシステムに悩まされています。 この投 […]
自動車および製造業界むけ AWS re:Invent 2025 のダイジェスト
AWS の年次フラッグシップイベントである AWS re:Invent 2025 は、 2025 年 12 月 […]

サーバーレス MLflow で Amazon SageMaker AI を使用して AI 開発を加速
2024 年 6 月に MLflow を搭載した Amazon SageMaker AI を発表して以来、弊社 […]

Amazon FSx for NetApp ONTAP が Amazon S3 と統合され、シームレスなデータアクセスが可能になりました
2025 年 12 月 2 日、Amazon Simple Storage Service (Amazon S […]
Amazon S3 クライアントを使用した ML トレーニングにおけるデータ読み込みベストプラクティスの適用
この記事では、Amazon S3 汎用バケットから直接データを読み取る ML トレーニングワークロードのスループットを最適化するための実用的な技術と推奨事項を紹介します。ここで説明するデータ読み込み最適化技術の多くは、さまざまなストレージ基盤に広く適用できます。

Amazon Nova Forge の紹介: Nova を使用して独自のフロンティアモデルを構築
組織は、生成 AI の使用をビジネスのあらゆる部分で急速に拡大しています。深い専門知識や特定のビジネスコンテキ […]

AWS Glue Data Catalog での Apache Iceberg テーブルのカタログフェデレーションの紹介
Apache Iceberg は、大規模で堅牢かつ信頼性の高い分析を求める組織にとって、オープンテーブルフォーマットの標準的な選択肢となっています。しかし、企業は異なるカタログシステムを持つ複雑なマルチベンダー環境をますます多く扱うようになっています。マルチベンダー環境で運用する組織にとって、これらのシステム間でデータを管理することは大きな課題となっています。この断片化は、特にアクセス制御とガバナンスに関して、運用上の複雑さを大幅に増加させます。Amazon Redshift、Amazon EMR、Amazon Athena、Amazon SageMaker、AWS Glue などの AWS 分析サービスを使用して AWS Glue Data Catalog 内の Iceberg テーブルを分析しているお客様は、リモートカタログのワークロードでも同じ価格性能を得たいと考えています。これらのリモートカタログを単純に移行または置き換えることは現実的ではなく、チームはシステム間でメタデータを継続的に複製する同期プロセスを実装・維持する必要があり、運用上のオーバーヘッド、コストの増加、データの不整合のリスクが生じます。