Amazon Web Services ブログ
AWS Glue Studio ビジュアルエディタから Amazon Redshift の新しい ETL / ELT 機能を試してみる
この記事は Exploring new ETL and ELT capabilities for Amazon Redshift from the AWS Glue Studio visual editor の翻訳記事です。
モダンデータアーキテクチャでは、統合分析機能によりデータの所在を意識することなく (データがデータレイクに保存されているかデータウェアハウスに保存されているかにかかわらず)、必要なデータにアクセスできます。特に、膨大なデータを大規模に分析し、複雑なクエリを実行してビジネス目標を達成するために、データを組み合わせて Amazon Redshift に統合するお客様が増えています。
Amazon Redshift でのデータ準備の最も一般的な使用例の 1 つは、さまざまなデータストアから Amazon Redshift にデータを取り込んで変換することです。これは通常、サーバーレスでスケーラブルなデータ統合サービスである AWS Glue を使用することで実現されます。これにより、複数のソースからのデータの検出、準備、移動、統合が容易になります。AWS Glue は、さまざまなデータ処理のユースケースに対応できるスケーラブルなアーキテクチャを備えており、Amazon Redshift との相性も抜群です。AWS re: Invent 2022 では、AWS Glue 4.0 で利用可能な Apache Spark との新しい Amazon Redshift インテグレーションのサポートを発表しました。これにより、ETL (抽出、変換、ロード) と ELT (データソースからそのままデータウェアハウスにデータをロードして,SQL で変換を行う方法のこと) の機能が強化され、パフォーマンスが向上しています。
本日、AWS Glue Studio ビジュアルエディターでの Amazon Redshift ETL および ELT ワークフロー用の新しく強化されたビジュアルジョブオーサリング機能を発表できることを嬉しく思います。新しいオーサリングエクスペリエンスでは、次のことが可能になります。
- AWS Glue Studio のビジュアルインターフェイスから Amazon Redshift のスキーマとテーブルを直接ブラウズすることで、ETL / ELT 開発が素早く始められます
- ソースとしての Amazon Redshift SQL のネイティブサポート、またはカスタムのプリアクションとポストアクションによる柔軟なオーサリング
- INSERT, TRUNCATE, DROP, MERGE の各コマンドが新たにサポートされることで、Amazon Redshift への一般的なデータロード操作を簡素化できます
これらの機能強化により、AWS Glue Studio の既存のトランスフォーム部品やコネクタを使用して Amazon Redshift のデータパイプラインを素早く作成できます。具体的には次のことが可能になります。1) ビジュアルインターフェイスのみを使用して、コード不要でエンドツーエンドのタスクを完了できる。2) 既存の Amazon Redshift SQL を AWS Glue 内で再利用できる。3) ビジュアルエディターのカスタムアクションでロジックを調整できる。
この投稿では、以下の加工プロセスを例に新しいユーザーインターフェイスの使用方法について詳しく説明します。
- Amazon Redshift に対してカスタム SQL 文 (JOIN ステートメント含む) を実行
- クエリ結果に対して AWS Glue Studio のビジュアルトランスフォームを適用
- トランスフォーム後に APPEND を実行して Redshift テーブルにロード
AWS CloudFormation でリソースをセットアップ
実証環境を素早く構築するために、 AWS CloudFormation テンプレートを提供しています。このテンプレートでは、次のリソースが自動的に作成されます。
- Amazon VPC、サブネット、ルートテーブル、インターネットゲートウェイ、NAT ゲートウェイ
- Amazon Redshift クラスター
- Amazon Redshift クラスターに関連付けられた AWS Identity and Access Management (AWS IAM) ロール
- AWS Glue ジョブを実行するための IAM ロール
- Amazon Redshift ETL の一時的な補完場所として使用される Amazon Simple Storage Service (Amazon S3) バケット
- Amazon Redshift クラスターのユーザー名とパスワードを保存する AWS Secrets Manager
CloudFormation スタックを起動するには、以下のステップを完了してください。
- AWS CloudFormation コンソールにサインインします。
- AWS CloudFormation コンソールで、[Create stack] を選択し、次に [With new resources (standard)] を選択します。
- [Template source] で [Upload a template file] を選択し、提供されたテンプレートをアップロードします。

- [Next] をクリックします。
- CloudFormation スタックの名前を入力して、[Next] を選択します。

- その他はデフォルトのままで最後まで進み、このスタックによって IAM リソースが作成される可能性があることを確認し、[Submit] を選択します。

- CloudFormation スタックが正常に作成されたら、ステップ 4: Amazon S3 から Amazon Redshift にデータをロードする に記載されている手順に従って、作成した Redshift クラスターにサンプルの ticket データをロードします。
Amazon Redshift のテーブルを参照する
このセクションでは、AWS Glue Studio ビジュアルエディターの新しい読み取り機能について説明し、新しい UI を使用してカスタム SQL ステートメントを実行する方法を示します。
- AWS Glue コンソールのナビゲーションペインで [ETL jobs] を選択します。

- [Visual with a blank canvas] を選択し、[Create] を選択します。

- 空白のキャンバスで、プラス記号を選択して Source タイプの Amazon Redshift ノードを追加します。
 ノードセレクターを閉じると、キャンバスに Amazon Redshift ソースノードとデータソースプロパティが表示されます。
ノードセレクターを閉じると、キャンバスに Amazon Redshift ソースノードとデータソースプロパティが表示されます。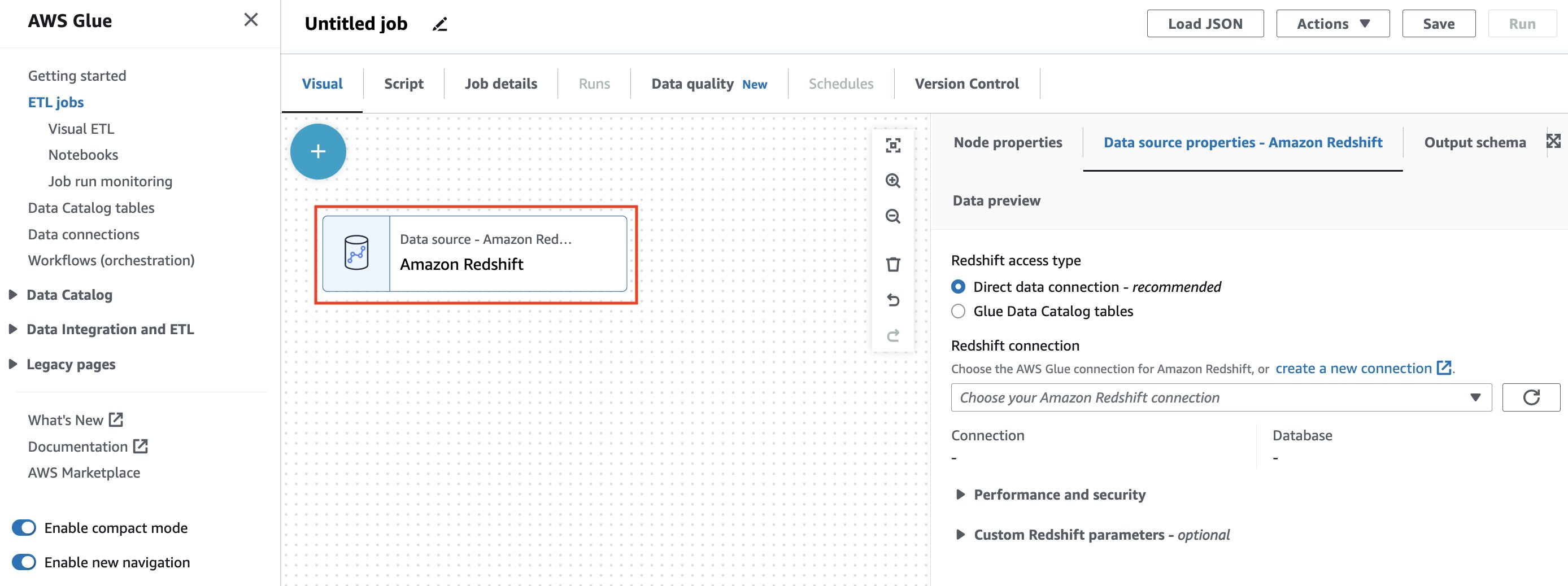
Amazon Redshift データにアクセスするには、次の 2 つの方法から選択できます。・ダイレクトデータ接続 — この新しい方法では、Amazon Redshift ソースをカタログ化しなくても接続を確立できます。
・Glue データカタログテーブル — この方法では、AWS Glue データカタログで Amazon Redshift テーブルをクロールまたは生成しておく必要があります。本投稿では、ダイレクトデータ接続オプションを使用します。 - [Redshift access type] で、[Direct data connection] を選択します。
- [Redshift connection] で、CloudFormation スタックで作成された
AWS Glue Connection redshift-demo-blog-connectionを選択してください。 接続を指定すると、接続するデータベースの名前とともに、ネットワーク関連のすべての詳細が自動的に設定されます。次に、選択した Amazon Redshift クラスターのデータベース内からデータにアクセスする方法を選択します。・単一テーブルを選択 — このオプションでは、データベースから 1 つのスキーマと 1 つのテーブルを選択できます。使用可能なすべてのスキーマとテーブルを AWS Glue Studio ビジュアルエディター自体から直接参照できるため、ソーステーブルの選択が容易になります。
接続を指定すると、接続するデータベースの名前とともに、ネットワーク関連のすべての詳細が自動的に設定されます。次に、選択した Amazon Redshift クラスターのデータベース内からデータにアクセスする方法を選択します。・単一テーブルを選択 — このオプションでは、データベースから 1 つのスキーマと 1 つのテーブルを選択できます。使用可能なすべてのスキーマとテーブルを AWS Glue Studio ビジュアルエディター自体から直接参照できるため、ソーステーブルの選択が容易になります。 ・カスタムクエリを入力 — Amazon Redshift テーブルのデータの一部に対して ETL を実行したい場合は、AWS Glue Studio UI から Amazon Redshift クエリを作成できます。このクエリは接続されている Amazon Redshift クラスターで実行され、出力されたクエリ結果は後続の AWS Glue Studio の変換部品で使用できます。本投稿では、ロードされた
・カスタムクエリを入力 — Amazon Redshift テーブルのデータの一部に対して ETL を実行したい場合は、AWS Glue Studio UI から Amazon Redshift クエリを作成できます。このクエリは接続されている Amazon Redshift クラスターで実行され、出力されたクエリ結果は後続の AWS Glue Studio の変換部品で使用できます。本投稿では、ロードされた eventテーブルとvenueテーブルのデータを結合する独自のカスタムクエリを作成します。 - [Redshift source] で、[Enter a custom query] を選択し、次のクエリをクエリエディタに入力します。
このクエリの目的は、2008-01-01 14:00:00 から 2008-01-01 15:00:00 の間にイベントが発生し、かつ
venueSeats = 0だったロケーションのvenueidを収集することです。Amazon Redshift クエリエディタから同様のクエリを実行すると、その期間内に実際にそのような場所が 5 つあることがわかります。これらの行を含めずに、このデータを Amazon Redshift にマージし直したいと考えています。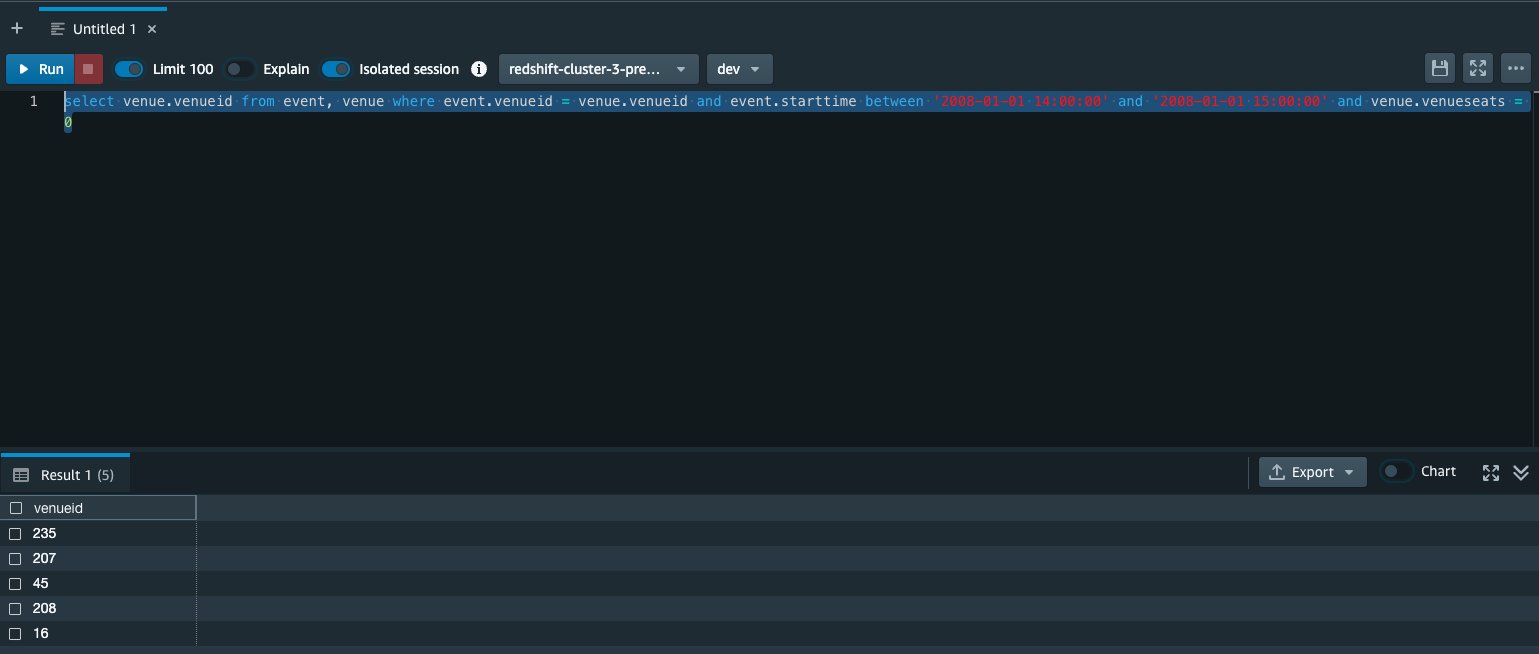
- [Infer schema] を選択します。これにより、AWS Glue Studio ビジュアルエディターがクエリから返された列のスキーマを理解できるようになります。
スキーマは [Output schema] タブで確認できます。
- [Performance and security] の [S3 staging directory] で、CloudFormation スタック (RedshiftS3TempPath) によって作成された S3 一時ディレクトリの場所を選択します。
- IAM ロールについては、CloudFormation スタックの RedShiftIamRolearn で指定されている IAM ロールを選択してください。
 次に、結合結果から重複する行を削除する変換を追加します。これにより、次の手順の MERGE 操作を実行するときにキーが競合することがなくなります。
次に、結合結果から重複する行を削除する変換を追加します。これにより、次の手順の MERGE 操作を実行するときにキーが競合することがなくなります。 - Drop Duplicates ノードを選択すると、ノードのプロパティが表示されます。

- [Transform] タブの [Drop duplicates] で、[Match specific keys] を選択します。
- [Keys to match rows] で
venueidを選択します。
 このセクションでは、カスタム JOIN クエリの出力を読み取る手順を定義しました。次に、重複するレコードを戻り値から削除しました。
このセクションでは、カスタム JOIN クエリの出力を読み取る手順を定義しました。次に、重複するレコードを戻り値から削除しました。
次のセクションでは、同じジョブの書き込みパスについて説明します。
Amazon Redshift テーブルへの書き込み
次に、送信先として Amazon Redshift テーブルに書き込むための拡張機能について説明します。このセクションでは、Amazon Redshift に書き込む際の簡略化されたオプションをすべて説明し、新しい Amazon Redshift MERGE 機能に焦点を当てていきます。
MERGE 文を使用すると、ソーステーブルからターゲットテーブルに行を条件付きでマージできます。 これまでは複数の INSERT、UPDATE、DELETE ステートメントを個別に使用しないと実現できなかった操作を MERGE 文 一本で簡略化できます。AWS Glue Studio では、カスタム MERGE オプションを使用すると、より複雑な一致条件を定義して、更新するレコードを検索できます。
- 前のセクションで使用したジョブのキャンバスページから Amazon Redshift を選択し、Target タイプの Amazon Redshift ノードを追加します。
 セレクターを閉じると、Amazon Redshift ターゲットノードが Amazon Glue Studio キャンバスに追加され、ノードのプロパティが表示されます。
セレクターを閉じると、Amazon Redshift ターゲットノードが Amazon Glue Studio キャンバスに追加され、ノードのプロパティが表示されます。 - [Redshift access type]は、[Direct data connection] を選択します。
Amazon Redshift ソースノードと同様に、ダイレクトデータ接続方式では、Amazon Redshift テーブルを AWS Glue データカタログにカタログ化しなくても Amazon Redshift テーブルに直接書き込むことができます。 - Redshift connection は、CloudFormation スタックで作成された AWS Glue 接続
redshift-demo-blog-connectionを選択してください。
- [Schema] で [public] を選択します。
- テーブルには、マージされたデータを保存する宛先の Amazon Redshift テーブルとして
venueテーブルを選択します。 - [Handling of data and target table] で、 [MERGE data into target table] を選択します。
この選択により、ユーザーには次の 2 つのオプションが表示されます。
・Choose keys and simple actions — これは MERGE 操作の使いやすいバージョンです。一致するキーを指定し、そのキーに一致する行を処理 (更新または削除) するか、一致しない行を処理 (挿入) するかを選択するだけです。
・Enter custom MERGE statement — このオプションが最も柔軟です。MERGE には独自のカスタムロジックを入力できます。本投稿では、シンプルなアクションメソッドを使用して MERGE 操作を実行します。 - 次に [Choose keys and simple actions] を選択します。
- 「Matching keys」で
venueidを選択します。
このフィールドがキーチェックの MERGE 条件になります。 - [When matched] で、テーブルの [Delete record in the table] を選択します。
- [When not matched] で、[Insert source data as a new row into the table] を選択します。
 以上で、データを挿入時に Amazon Redshift で MERGE ステートメントを実行するように AWS Glue ジョブを設定しました。また、この MERGE 操作はキーを使用し(複数のキーを選択することもできます)、ターゲットテーブルのレコードとキーが一致する場合、そのレコードは削除され、一致しない場合は、レコードを宛先テーブルに挿入します。
以上で、データを挿入時に Amazon Redshift で MERGE ステートメントを実行するように AWS Glue ジョブを設定しました。また、この MERGE 操作はキーを使用し(複数のキーを選択することもできます)、ターゲットテーブルのレコードとキーが一致する場合、そのレコードは削除され、一致しない場合は、レコードを宛先テーブルに挿入します。 - [Job details] タブに移動します。
- [Name] に、ジョブの名前を入力します。
- IAM Role ドロップダウンで、CloudFormation テンプレートを使用して作成された RedshiftIamRole ロールを選択します。
- [Save] を選択します。
- [Run] を選択し、ジョブが終了するのを待ちます。
進行状況は [Runs] タブで追跡できます。 - 実行が成功したら、Amazon Redshift クエリエディタに戻ります。
- 同じクエリをもう一度実行すると、それらの行が MERGE の仕様に従って削除されていることがわかります。

このセクションでは、MERGE 文 (ターゲットの Amazon Redshift テーブルのレコードを条件付きで更新する) を実行する AWS Glue ジョブを作成しました。また、MERGE 文が宛先の Amazon Redshift テーブルに及ぼす影響を確認しました。
その他の書き込みオプション
MERGE 以外にも、AWS Glue Studio ビジュアルエディターの Amazon Redshift ターゲットノードは、他にも多くのオペレーションをサポートしています。
- APPEND — ターゲットテーブルに追加すると、既存のレコードを更新せずに、選択したテーブルへの挿入が実行されます (重複しているレコードがある場合は、両方のレコードが保持されます)。新しい行の追加 (UPSERT 操作と呼ばれることが多い) に加えて既存の行を更新する場合は、「ターゲットテーブルの既存のレコードも更新する」オプションを選択できます。APPEND のみと UPSERT (更新を伴う追加) はどちらも、前述の MERGE 機能のより単純なサブセットであることに注意してください。
- TRUNCATE — TRUNCATEオプションは、既存のテーブルのデータをすべて消去しますが、既存のテーブルスキーマはすべて保持し、その後、空のテーブルにすべての新しいデータをAPPENDします。このオプションは、データセット全体をリフレッシュする必要があり、下流のサービスやツールがテーブルスキーマの一貫性に依存している場合によく使用されます。例えば、Amazon QuickSight ダッシュボードのデータソースとして Amazon Redshiftのテーブルが毎晩、最新の顧客情報に更新される必要があるとします。この場合、ETL開発者はTRUNCATEを選択し、データは完全に更新されるが、テーブルスキーマは変更されないことが保証されるようにします。
- DROP — このオプションは、データセット全体を更新する必要があり、スキーマやシステムに依存する下流のサービスやツールが、スキーマの変更を中断することなく処理できる場合に使用されます。
書き込み処理の裏側
Amazon Redshift コネクタは、プリアクションとポストアクションと呼ばれる 2 つのパラメータをサポートしています。 これらのパラメータを使用すると、Spark が実際に書き込み操作を実行する前後に Amazon Redshift データウェアハウスに渡される SQL ステートメントを実行できます。
AWS Glue Studio ページの [Script] タブで、実行されている SQL ステートメントを確認できます。
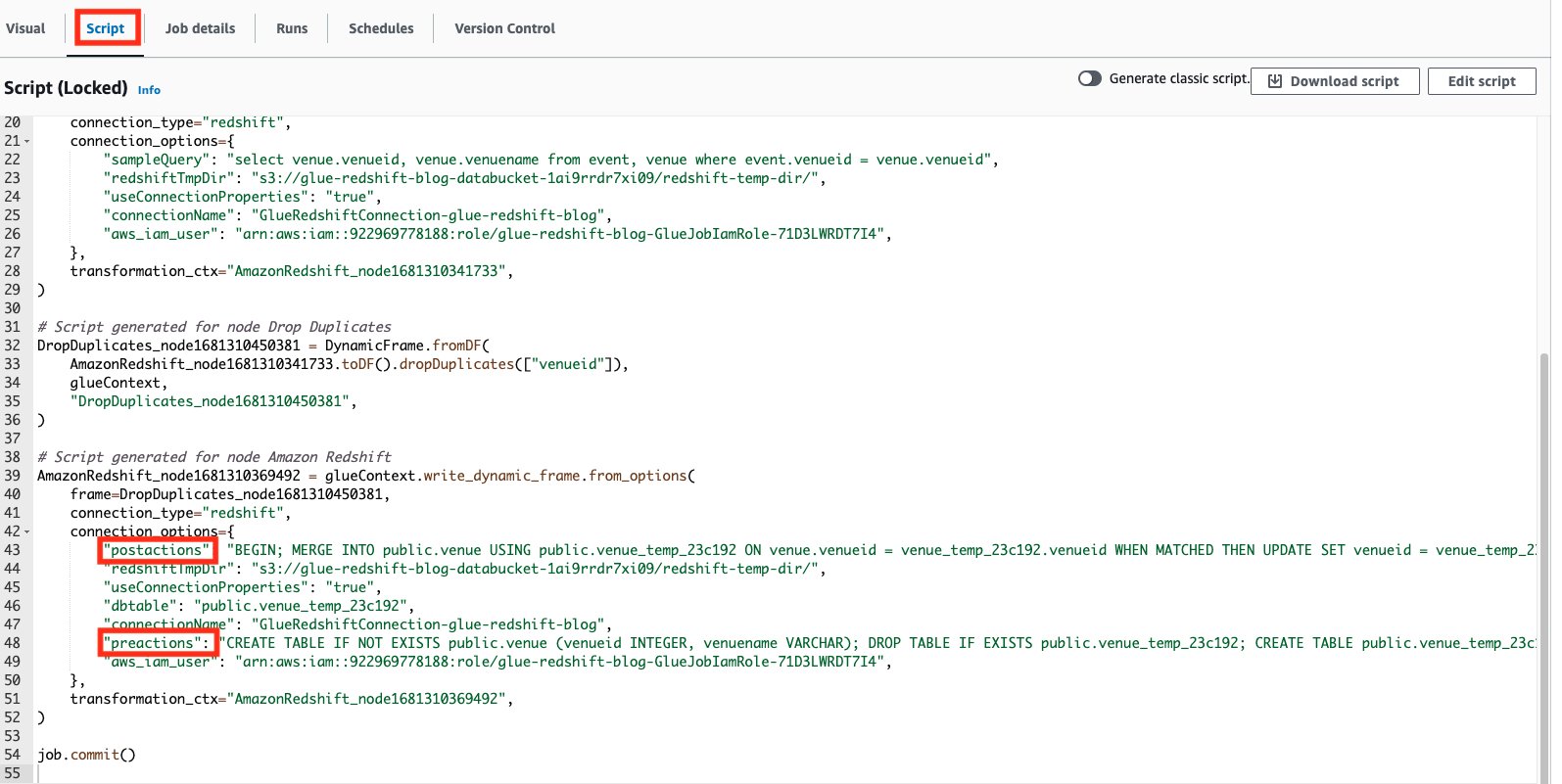
プリアクション、ポストアクションのカスタム実装
提供されているプリセットをさらにカスタマイズする必要がある場合や、Amazon Redshift に書き込むための高度な実装が必要な場合、AWS Glue Studio では Amazon Redshift への書き込み時に実行できるプリアクションとポストアクションを自由に選択することもできます。
例として、Amazon Redshift データ共有をプリアクションとして作成してから、同じデータ共有のクリーンアップを AWS Glue Studio 経由でポストアクションとして実行します。
注:このセクションは本ブログの一部として実行されたものではなく、例として提供されています。
- Amazon Redshift データターゲットノードを選択します。
- Data target properties タブで、Custom Redshift parameters セクションを展開します。
- パラメータには、以下を追加します。
a. Parameter:preactionsValue:BEGIN; CREATE DATASHARE ds1; END
b. Parameter:postactionsValue:BEGIN; DROP DATASHARE ds1; END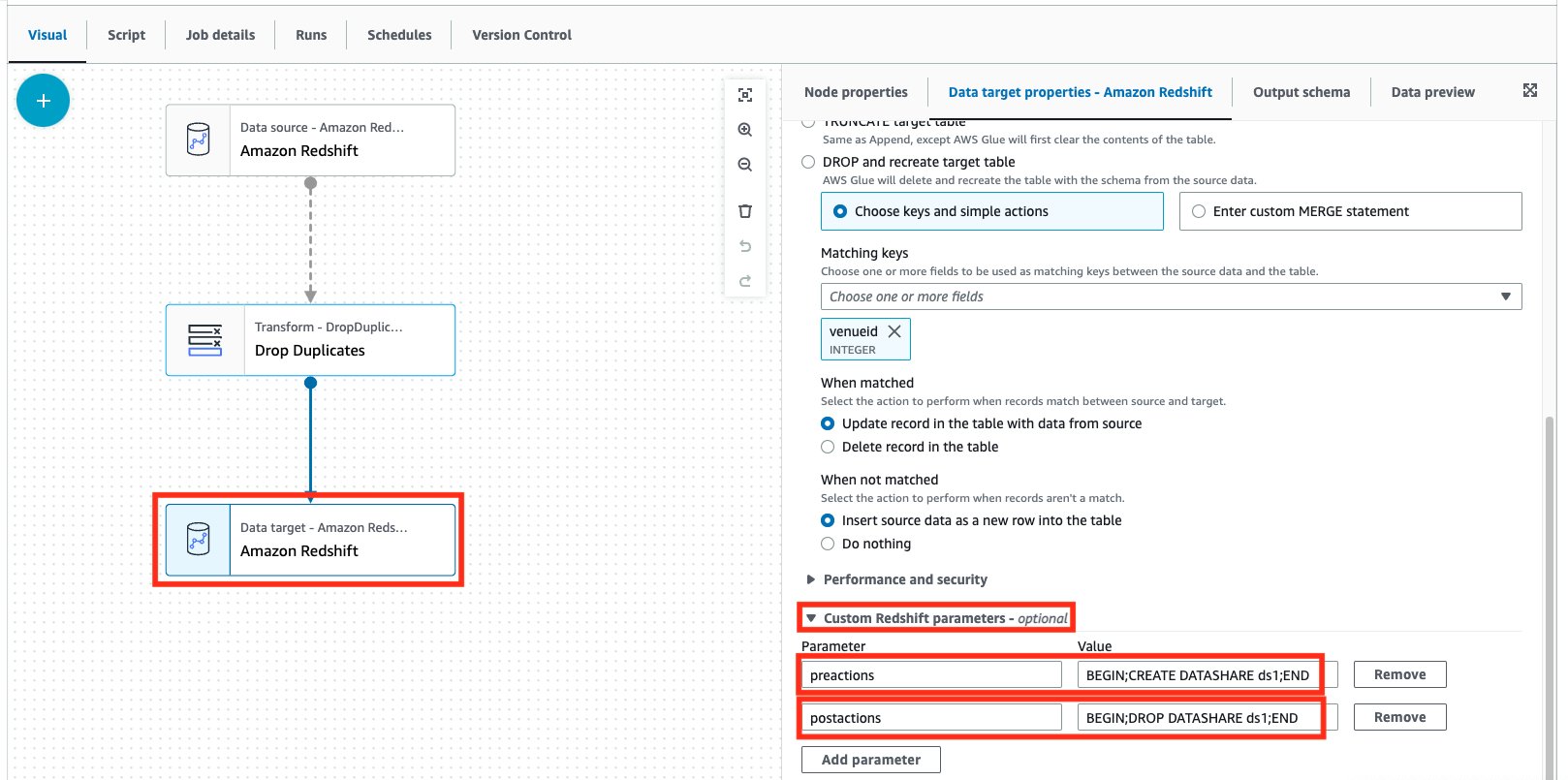 前述のとおり、
前述のとおり、 preactionsとpostactionsのパラメータ使用して、複数の Amazon Redshift ステートメントを実行できます。これらのステートメントは、指定したアクションで既存のプリアクションやポストアクションを上書きすることに注意してください。
クリーンアップ
追加費用が発生しないように、不要なリソースやファイルは必ず削除してください。
- S3 一時バケットの内容を空にして削除する
- サンプルのCloudFormationスタックをデプロイした場合は、AWS CloudFormationコンソールからCloudFormationスタックを削除します。バケットを削除する前に、必ず S3 バケットを空にしてください。
まとめ
本投稿では、Amazon Redshift からの読み取りと書き込みを実行するための新しい AWS Glue Studio のビジュアルオプションについて説明しました。また、AWS Glue Studio のビジュアルエディターから直接 Amazon Redshift テーブルをブラウズできるというシンプルさや、Amazon Redshift ソースに対して独自のカスタム SQL ステートメントを実行する方法についても説明しました。次に、数回クリックするだけで Amazon Redshift に対して簡単な ETL ロードタスクを実行する方法を探り、新しい Amazon Redshift MERGE ステートメントを紹介しました。
AWS Glue Studio ビジュアルエディタ用の新しい Amazon Redshift 統合について詳しく知るには、「AWS Glue Studio の Redshift への接続」を参照してください。