Amazon Web Services ブログ
AWS のインダストリアルデータプラットフォームを始める
この記事は Dennis Schmidt によって投稿された Getting Started with the Industrial Data Platform on AWS(記事公開日:2022 年 6 月 29 日)を翻訳したものです。
データはデジタルトランスフォーメーションと Industry 4.0を実現する鍵です。
製造業では、データを用いて統一的な可視化を実現し、生産活動に役立つ情報(インサイト)を引き出すことができます。
これらのインサイトは、生産品質の向上、リアルタイムの予測、およびコスト削減に活用できます。 ビッグデータ分析技術は、パフォーマンスの測定やメンテナンス、さらにプロセス改善に関連するこれまでにない力を発揮できます。
製造業では、さまざまなソースからデータを収集し、各ソースは独自の(サイロ化された)データベースに保存され、アドホックなレポートまたは分析システムを使用してアクセスします。 時間が経つにつれて、これらのサイロと分析システムはより分離してゆき、サポートが困難になります。また、 従来のデータウェアハウスは、構造化データを迅速かつ効率的にクエリ、変換、分析できます。しかし、非構造化データや半構造化データには最適ではないことが多く、Industry4.0 の要求を満たすように効率的に拡張できない場合があります。
製造データから運用上のインサイトを得るために、企業はインダストリアルデータプラットフォームを実装しています。 このブログでは、これまでのソリューションで直面する課題の概要を説明し、それを解決するための堅牢で回復力のあるアーキテクチャを AWS を用いて構築する方法を説明します。
インダストリアルデータプラットフォームを取り巻く課題
産業データの収集と分析には複数の課題があります。
- データのリンクが困難 — データは異なるソースから取得され、意味のあるインサイトを引き出すにはデータの質向上とカタログ化が必要になることがよくあります。
- 低すぎるデータの収集頻度 — センサーとデータの記録は頻繁に行われていたとしても、アドホックなデータ収集ツールの使用やデータストアへの統合は、時々しか行われない場合があります。 これにより、人工知能や機械学習(AI/ML)を使用してリアルタイム分析や予測を行うことが不可能になります。
- アクセスが困難なデータ — アプリケーションが、異なる物理ネットワークに存在したり、異なるデータベースエンジンを必要としていたり、異なるデータ構造を持っている場合があります。 各アプリケーションからのデータを、アクセス可能にするためには、異なるツールセットを使用してそれぞれのアプリごとのデータ変換を必要とする場合があります。
- スケーリングと柔軟性 — より多くのデータを生成したり、データソースを追加したりすると、運用上のオーバーヘッドと費用が増大することがよくあります。
一般的な解決策
産業用データプラットフォームとして展開される一般的な解決法は2つあります。個別にデータサイロを持つことと、エンタープライズデータウェアハウスです。
データサイロ
データサイロとは、単一の目的のみを果たすデータベースです。例えば、 PLC データの収集や ERP システムの情報の保存などをそれぞれ構えることです。 企業は時間の経過とともにデータサイロを構築します。組織が新しいプロセスやアプリケーションを追加すると、新しいデータサイロが作成されます。 サイロごとに異なる管理、セキュリティ、および承認アプローチが必要になる場合があり、そのすべてが運用コストとリスクを増大させます。 データサイロには利用可能なデータ、データの保存場所やデータへのアクセス方法を示す統一的なカタログはありません。 特定の分析ワークロードに必要なデータは、複数のサイロに跨っておりアクセスできない場合があります。 このプラットフォームは、データの需要に応じて、拡大、縮小することができます。 それぞれのサイロは、規模が拡大するにつれてコストパフォーマンスが見合わなくなる場合があります。

図 1: データサイロ
データウェアハウス
エンタープライズデータウェアハウス (EDW) は中央集権的なデータリポジトリであり、従来は大量の構造化データを含んでいます。 トランザクションシステム、リレーショナルデータベース、その他のソースから定期的にデータウェアハウスにデータが連携されます。 このデータのクエリと分析には、ビジネスインテリジェンス (BI) ツール、 SQL クライアント、およびその他の分析アプリケーションが使用されます。 エンタープライズ向けデータウェアハウスをインダストリアルデータプラットフォームまたは製造データレイクとして使用する場合、すべてのデータを 1 か所に保存することで、データサイロで発生する問題を解決しようとします。 データの発生源は、決められたスキーマを使用して構造化データとしてデータを保存します。このスキーマは、ニーズの変化に応じて慎重に管理・維持する必要があります。 データを特定のスキーマで管理することは、すべてのアプリケーションまたはすべてのタイプのデータで機能するとは限らず、結果として得られるリレーショナルデータセットは、すべての分析プラットフォームで使用できない場合があります。 事業を行う際に発生する全てのデータに対して統一的なスキーマを作成することは、データソースの追加や変更が増えるにつれて、技術的に困難になり管理上の負担になる可能性があります。 プラットフォームを拡張するには、追加のコンピューティング、ストレージ、さらにはライセンスをデータウェアハウスに追加する必要があります。そして、そのためのメンテナンス中にサービスが利用できなくなる可能性があり、コストとダウンタイムの増加につながります。

図 2: エンタープライズデータウェアハウス
機能的なギャップ
上記2つのソリューションには、次のような機能上のギャップがあります。
- グローバルにアクセス可能な一元化されたプラットフォームの欠如 — データサイロは製造データを分散させ、データへのアクセス、検索、分析を困難にします。 エンタープライズデータウェアハウスは構造化データを効率よく処理できますが、さまざまなアプリケーションやソースによって生成された非構造化データや半構造化データを保存および分析するには最適な選択肢ではない場合があります。 アナリストは、インサイトを引き出すために、すべての企業データ、運用上発生するデータに単一の場所からアクセスすることを求めています。
- データ取込みの柔軟性の欠如 — 完全なデータの保管庫を構築するには、履歴データ、エネルギー消費、 ERP システム、 IoT センサーからのストリーミングデータなど、あらゆる種類のデータを取り込む必要があります。 このような柔軟性を実現するためのスケーリングも重要です。スケーリングができずストレージやコンピューティングが利用できなくなってしまうと、データの保存ができなくなってしまいます。
- 分析に対するサポートが限定的 — データサイロとデータウェアハウスは、SQL ベースのクエリと分析のみをサポートしている場合があります。 データを最大限に活用するには、インダストリアルデータプラットフォームが、予測的なインサイトを得るための高度な分析と機械学習をサポートする必要があります。
- 分析結果をあらゆるものにシームレスに届ける必要がある — 分析を共有する中央的なプラットフォームがなければ、データサイロは他のデータセットで実行された分析にアクセスできないでしょう。分析結果とインサイトは、最初に適切なスキーマに再フォーマットしない限り、エンタープライズデータウェアハウスに取り込むことはできません。
アーキテクチャ上のアプローチ
現在のソリューションの機能的なギャップを克服するために、多くのお客様は既存のデータサイロやエンタープライズデータウェアハウスを拡張するために時間や労力、そして資金を費やしています。 上記のようなソリューションはサポートが困難な場合が多く、データセットの増加に必要な将来に渡る柔軟性を持っていません。 Industry4.0 に移行する組織には、単一の場所からデータにアクセスできるインダストリアルデータプラットフォームが必要です。 また、データの利用者が入手可能なデータを簡単に識別できるように、データのカタログ化が必要です。 さらに、インダストリアルデータプラットフォームは、構造化、非構造化、または半構造化など、現在あるいは将来利用する可能性のある様々なタイプの生データ形式に対応するために、時間の経過とともに拡張または縮小する必要があります。
インダストリアルデータプラットフォーム
以下の図 (図 3) は、AWS のインダストリアルデータプラットフォームを概念的に表したものです。

図 3: インダストリアルデータプラットフォーム
大まかに言うと、データは、さまざまなデータソース(製造現場のアプリケーションや生産プロセス、MES 、エンタープライズアプリケーションなど)を各種のコネクタ、エッジアプリケーション、または IT/OT 接続のための計画図(用途ごとに固有のアーキテクチャパターンを持つプロセス)を介してプラットフォームに取り込まれます。データが収集されると、統合されたデータバックボーンに保存され、処理されます。ここは下流のシステムで利用するために、データが変換、モデル化、およびコンテキスト化される場所です。柔軟性のあるデータアクセスレイヤーは、運用ダッシュボード、サードパーティアプリケーション、高度な分析サービスなど、ビジネスインサイトを得るためのアプリケーションへの柔軟なデータアクセスを提供します。セキュリティと自動化の仕組みは、データが生成される場所から、エンドユーザーがレポートやダッシュボードを介したデータの利用を行うまで、すべてのレイヤーに組み込まれています。
モダンデータアーキテクチャ
インダストリアルデータプラットフォームの中心にはデータレイクがあります (図4)。 データレイクは、あらゆる規模で構造化データと非構造化データをすべて保存できる一元化されたリポジトリです。 基幹システムのリレーショナルデータや、モバイルアプリ、IoT デバイス、ソーシャルメディアなどの非リレーショナルデータを格納するために使用できます。 データレイクは、データを構造化したり明確に定義されたスキーマを必要としません。このことにより、データが生成される際に、将来どのようにクエリされるかを意識する必要なくデータを保存することができます。さまざまなタイプのデータに対して ダッシュボードや見える化、ビッグデータ処理、リアルタイム分析、機械学習まで、簡単に分析することができ、価値のあるインサイトを得ることができます。
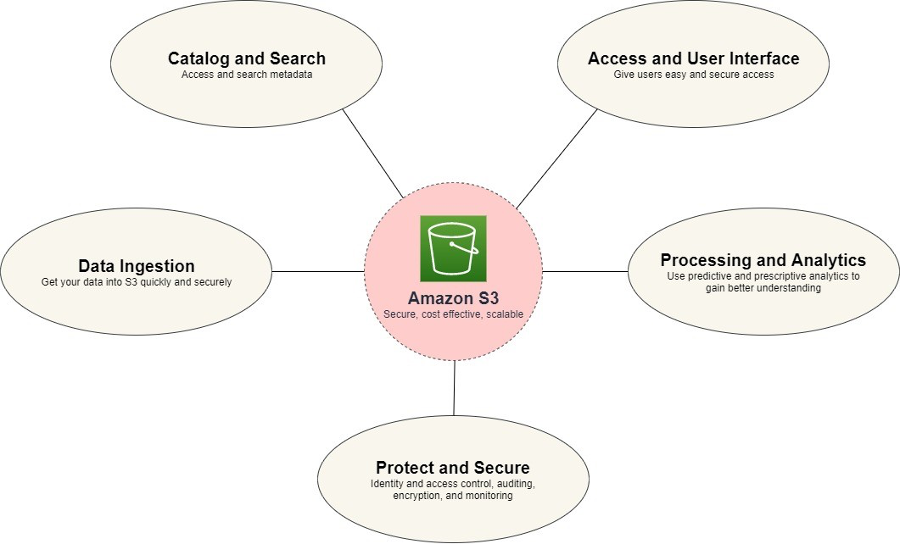
図 4: データレイク
AWS で構築されたデータレイクの中心となるコンポーネントは、Amazon Simple Storage Service (Amazon S3) です。優れた耐久性、可用性、パフォーマンス、およびスケーラビリティにより、ストレージとして最適な選択肢です。 Amazon S3 は、さまざまなタイプのデータ取り込み方法、分析ツール、サービスと統合されています。 データを安全に保つために、Amazon S3 では保管時の暗号化、包括的なアクセス制御、および監査が可能です。 データレイクから取得されるデータは、列レベルと行レベルの両方で制限することができ、データにアクセスする際のセキュリティに対するきめ細かなアプローチを提供します。
インダストリアルデータプラットフォーム内のデータから最大限の価値を引き出すためには、データレイクの周辺に最新のデータアーキテクチャを展開していきます (図5)。 データレイク、データウェアハウス、その他すべての専用サービス(データサイロ)に対してすべて一貫して接続できます。 データレイクを使用することで分析の対象をデータレイクという単一のデータソースに限定することができます。また、データレイクのための分析サービスは、リアルタイムダッシュボードやログ分析などの特定のユースケースに必要な速度を提供します。 モダンデータアーキテクチャでは、データとインサイトが相互に接続され、さらなる分析が可能になります。

図 5: データレイクを取り巻くモダンデータアーキテクチャ
リファレンス実装
AWS 上に構築された最新のインダストリアルデータプラットフォームをイメージしやすくするために、製造におけるリファレンスアーキテクチャ (図 6 と 7) を検討してみましょう。 中核となるのは、Amazon S3 に支えられたセキュアなデータレイクです。 データサイロ同士が接続され、データはデータレイクに取り込まれます。さまざまなアプリケーションによる利用や分析が行われ、その分析から得られたインサイトはデータレイクに再び保存されます。そして、そのインサイトをデータレイクに接続された他のサービスが利用する、最新のデータアーキテクチャではそういったことが可能になります。
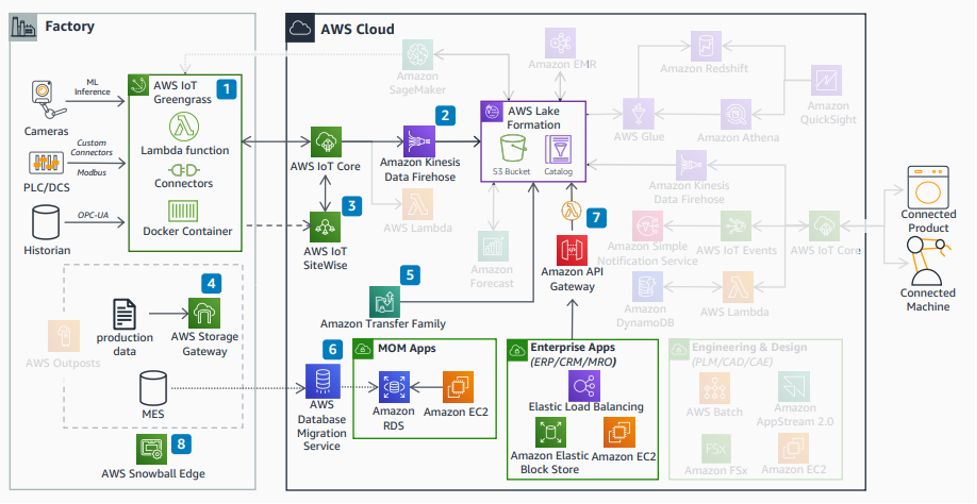
図 6: データインジェスト
価値あるインサイトをタイムリーに得るためには、インダストリアルデータプラットフォームへ効率的にデータを取り込むことが不可欠です (図6)。 産業用デバイスは、エッジゲートウェイ上で実行される AWS IoT Greengrass を使用してクラウドに接続されます [1]。産業データは、 Amazon Kinesis Data Firehose [2] を使用してデータレイクにストリーミングされます。 AWS IoT SiteWise は、アセットのモデル化、テレメトリデータからのメトリクスの計算、および AWS IoT SiteWise Monitor を使用したデータの可視化に使用できます [3]。 非構造化データは、 AWS Storage Gateway [4] を使用してデータレイクに同期できます。 製造で利用されるアプリケーション用のインターフェイスとして、 Amazon Transfer Family を使用してファイルをデータレイク [5] に転送します。 AWS Database Migration Service を使用すると、製造用のデータベースのデータを Amazon RDS [6] に同期できます。 エンタープライズアプリケーションに対しては、Amazon API Gateway と AWS Lambda 関数を使用して、データをエクスポートすることで Data Lake にインポートするインターフェイスを構築できます [7] 。大規模なデータセットは、AWS Snowball Edge を使用してデータをデータレイク [8] に移行できます。
統合されたデータバックボーンとビジネスインサイト
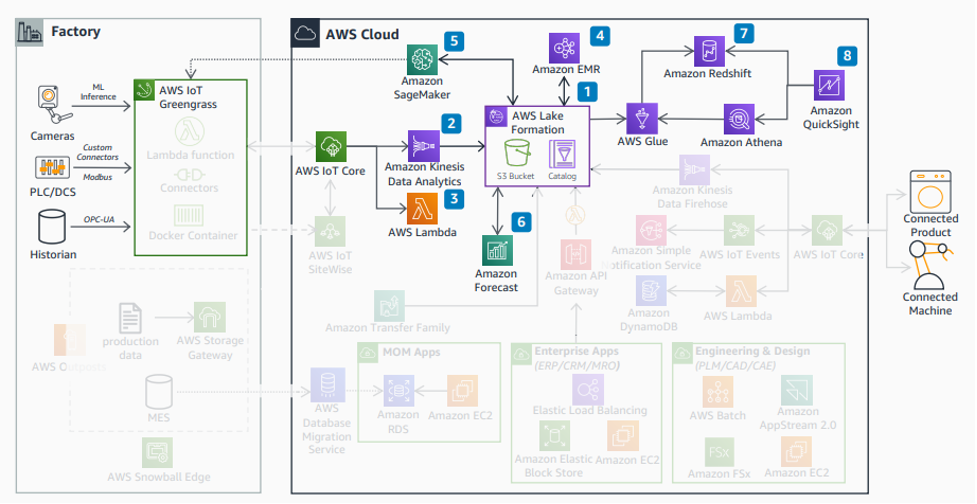
図 7: 統合データバックボーン
インダストリアルデータプラットフォームの統合されたデータバックボーン (図 7) を構築するために、AWS Lake Formation を使用して Amazon S3 にセキュアなデータレイクを確立できます [1]。AWS IoT Core を介して取り込まれた産業用 IoT およびFA 機器データについては、Amazon Kinesis Data Analytics で異常検出などのストリーミング分析を実行できます [2]。リアルタイムに近い分析を行うには、AWS Lambda を使用して分析用の関数を実行します [3]。Amazon EMR は、データレイク [4] でデータを処理、変換、分析するために使用できます。Amazon SageMaker は、機械学習のモデルを開発、学習、デプロイできます [5]。Amazon Forecast は、需要予測のユースケース [6] に使用できます。構造化データセットと分析結果は、Amazon Redshift [7] を使用してデータウェアハウスに保存し、効率的にクエリできます。Amazon Redshift、Amazon S3 、および Amazon Athena のデータを使用して、BI レポートを作成し、Amazon QuickSight でデータを視覚化します [8]。
得られる効果
AWS の インダストリアルデータプラットフォーム は、データを管理および保存するための、グローバルにアクセス可能な一元化されたプラットフォームを提供します。インサイトを得るために必要なデータの取り込み、保存、モデリングのための単一のハブを提供します。 アプリケーションが、あらゆるソース、あらゆる種類のデータをインダストリアルデータプラットフォームにストリーミングまたはロードできるため、インダストリアルデータの分析者は利用可能なすべての企業データや運用データに一元的にアクセスできます。 データは取り込まれるときに厳密なスキーマに強制されません。 AWS の インダストリアルデータプラットフォーム は、新しい入力に合わせて簡単にスケーリングし、無限に近い
の
ストレージ機能を提供し、標準的な SQL クエリから予測インサイトを得るための高度な AI/ML まで、ほぼすべての種類の分析ツールをサポートします。 分析によって得られたインサイトはシームレスにプラットフォームに戻すことができ、データをさらに充実させ、運用を可能にします。
実装のアプローチ
既存のデータサイロ、データウェアハウス、分析ソリューションを統合し、AWS 上にインダストリーデータプラットフォームを構築することは非常に難しいのでは、と感じてしまう方もいらっしゃるかもしれません。 以下に一般的なガイドラインを示しますので、インダストリアルデータプラットフォーム構築のプロジェクトを開始する際に参考にしてください。
- 重要なのは、リファレンスアーキテクチャの全てのコンポーネントをすべての人が必要とするわけではないということです。まず、データレイクを構築し、少数のデータソースと分析ワークフローを追加します。
- インダストリアルデータプラットフォームの価値を主要な関係者に示すには、ビジネスに有意義な影響を与えるユースケースや課題からインダストリアルデータプラットフォームの利用を始めましょう。
- 時間の経過とともに、新しいデータソースを徐々にプラットフォームに追加していきます。 データソースが追加されたら、分析とレポートを通じてより多くのインサイトを得ていきます。
- 従来のインダストリープラットフォームから徐々に移行し、使われていないデータサイロの利用をやめていくことにより、技術的負債を解消します。
- AWS ソリューションライブラリで利用可能なソリューションを確認し、Machine to Cloud 接続フレームワーク、Machine Downtime Monitor on AWS 、Virtual Andon on AWS など、「 製造 & 産業 」のソリューションを試してみてください。 これらのパッケージ化されたソリューションは、さまざまな問題解決を加速させるかもしれません。
結論
インダストリアルデータプラットフォームは、データサイロを統合し、従来のデータウェアハウスの機能を拡張して、高度な分析と機械学習を可能にし、生産活動に役立つインサイトを得るために使用できます。 AWS の インダストリアルデータプラットフォーム は、あらゆるタイプのデータを管理および保存するための、グローバルにアクセス可能な一元管理されたプラットフォームを提供します。 簡単に拡張でき、ほぼ無限のストレージ機能を提供し、標準的な SQL クエリから予測的なインサイトを得るための高度な AI/ML まで、ほぼすべての種類の分析ツールをサポートします。
さらに詳細に知りたい方は、 お客様が AWS のサービスをどのように使用してデータからインサイトを得て、製造の最適化を図っているか(ケーススタディ1 、 ケーススタディ2)についてご覧になり産業における AWS の取組について情報収集してください!
翻訳はソリューションアーキテクトの黒田が担当しました。原文はこちらです。