Amazon Web Services ブログ
AWS で電力送配電網をグラフ化する方法
この記事は、「Graphing the utility grid on AWS」を翻訳したものです。
送配電網故障の高いコスト
電気が止まると、私たちの生活は止まってしまいます。その際、電力会社には、お客さまにご迷惑をおかけしている間にも、迅速に状況を切り分けし、対応策を策定し、実行する責任があります。危険は増大し、コストは積み上がります。電力送配電網の管理のための複数の基幹システムなしには、電力供給を維持することは容易ではありません。これらのシステムはサイロ化されていることが多く、今日の電力会社はデータであふれてしまっています。
電力送配電網の運用者は、停電の原因究明と復旧計画、停電予測、電力負荷予測、暴風雨予測、暴風雨に備えた修理品の在庫レベルの計算などのために、高度なアナリティクスと人工知能/機械学習 (AI/ML) 機能を使って、送配電網の状態監視レベルを改善し、運用効率を高める方法を常に探究しています。このようなソリューションを提供するには、複数のデータソースを単一のリポジトリにまとめ、分析と可視化を行う機能が必須となります。電気事業者の場合、これらのシステムには以下のようなものが含まれますが、これらに限定されるものではありません。
- 顧客情報システム (CIS) や企業設備管理 (EAM) などの業務システム
- 主に現場のモバイル機器から生成される、作業伝票や作業員管理データ
- 監視制御およびデータ収集 (SCADA) 、スマートメーターの計量、および、通信システム、配電管理システム (DMS) 、および、電力管理システムなどの、電力送配電網運用技術 (OT) システム
- 停電管理システム (OMS)
- 送配電設備の物理的な位置と接続方法を提供する地理情報システム (GIS)
- 気象や交通などの外部データ
- 部分的に地理情報タグが付与されたソーシャルメディアデータ
上記のシステムのほとんどは、現在もオンプレミスにデプロイされ、電気事業者によって運用されています。これらのシステムは、送配電網の監視と運用に使用される重要なデータを収集、加工、分析し、意思決定を助けています。残念ながら、これらのシステムは相互運用性を考慮して設計されていないため、システム間のレポート、分析、予測、運用シミュレーションのために、システムベンダーから新しいモジュールを追加することは、しばしば問題になります。しかし、クラウドベースのシステムは、こうしたユースケースを大規模かつ迅速に実現する、データレイクや AI/ML といった高度な機能で、送配電網管理システム強化する基盤を提供します。それだけでなく、既存の複雑な IT および OT 環境の保守やサポートのコストを削減することもできます。
送配電網分析基盤には、次の 3 つの領域が含まれます。
- 送配電網ネットワークモデル
- センサーと計測データの収集
- 分析とシミュレーション
このブログでは、送配電網ネットワークモデルのトポロジーに焦点を当てます。なぜなら、これは送配電網分析ソリューションを構築するための基礎となる重要な要素だからです。
送配電網ネットワークモデルとは何か?
送配電網分析ソリューションにおける「ネットワークモデル」は、以下の図 1 の電力系統図の例のような物理的な送配電網を構成する、設備間の接続の状態を表す論理データビューを提供します。これは、送配電網の「トポロジー」とも呼ばれます。
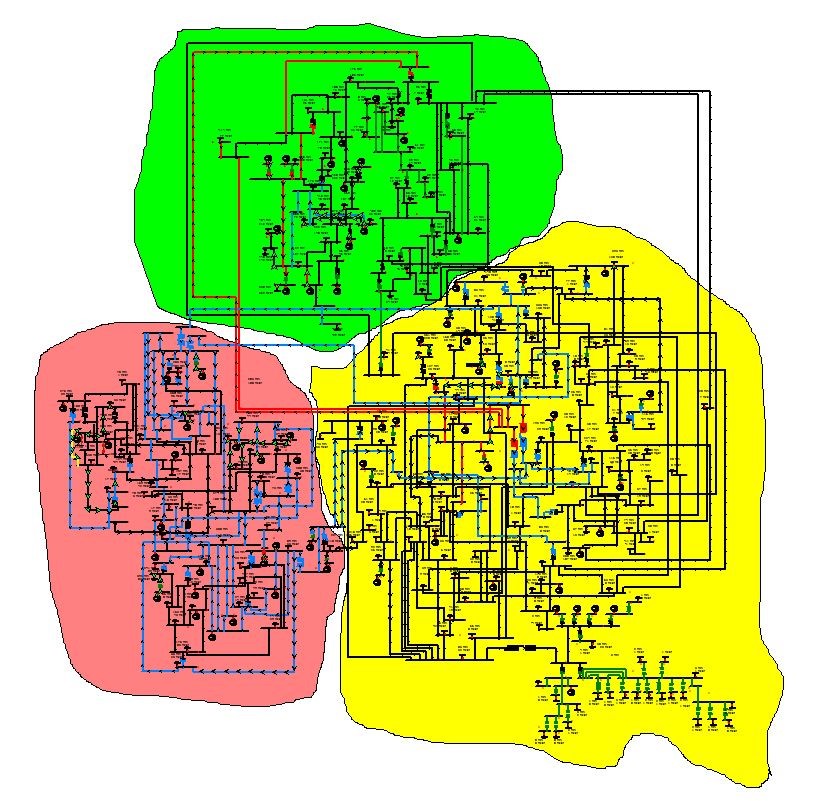
図 1 : 3 つの運用領域にまたがる IEEE の電力系統図の例で、69 台の発電機、60 台の電力負荷タップ切換器、304 本の送電線、195 台の電力負荷が含まれる
送配電網ネットワークモデルの構築は、トポロジーモデル自体を作成し、さらに他の複数のデータソースを統合することによる情報の拡充が必要です。モデルの主要なソースは GIS で、設備のトポロジーデータ (それが何で、地球上のどこにあり、何に接続されているか) を管理します。通常、電力会社では、 GIS システムには「設計時」と「構築時」の両方の送配電網トポロジーが含まれており、発電フィード、送電線、電柱、変電所、変圧器、ブレーカー、スイッチ、電力メーターなどの設備が含まれます。もう一つの重要なデータソースは EAM システムで、設備に関する非地理的な属性データ (メーカー、モデル、シリアル番号、コストデータ、テスト・メンテナンス記録など) の大部分を保有しています。顧客データは CIS から入手できます。
送配電網の「運用時」のネットワークモデルビューは、 DMS または類似の SCADA システムによって提供されます。メーターデータは、 1 つ以上のメーターシステムから提供されます。
データソースが収集、処理され、ネットワークモデルが得られると、以下の図 2 に示すように、分析、AI/ML 、および、可視化作業が進められます。

図 2 : 送配電網のモデリングと分析に使用される異なるデータソースのデータフロー
なぜグラフデータベースを使うのか?
送配電網の論理モデル (図 1) を見ると、送配電網は個々の要素の集合と複数の接続点と経路で構成されていることがわかります。これらの要素を定義するのは、その要素自身の特徴だけでなく、送配電網内の他の要素との関係です。この関係は多様で複雑かつ動的に変化します。また、送配電網の「運用時」にはこうした要素間の関係が、いわゆる「高度に結びついたデータセット」を表現しています。
グラフデータベースは、このような複雑な関係を何十億も格納し、ミリ秒単位の計算や検索をサポートできる専用のデータベースであるため、必要不可欠とは言えないまでも、有用です。一般に「グラフ」と呼ばれるのは、この高度に結びついたデータ構造のことです。グラフデータベースとリレーショナルデータベースの主な違いは、要素間の関係がどのようにモデル化され、保存されるかです。グラフデータベースは、個々のデータ要素間の関係を保存し、検索するために最適化されています。これらの関係は個々のレコードレベルで保存され、動的に変化できます。これはまさに、動的な送配電網設備の接続状態を表現し検索するために必要なものです。関係や属性は必要に応じて追加することができ、事前にモデル化しておく必要はありません。リレーショナルデータベースでは、ある要素と別の要素を関連付けるために、正確にモデル化されたテーブルにあらかじめ関係が定義されている必要があります。関係や属性は、その場で追加したり変更したりすることはできません。
更なる詳細説明の前に、グラフについていくつかの基本的な定義をします。
- グラフはノード (頂点) とエッジ (関係) から構成される
- ノード (頂点) はグラフの主要なデータの実体であり、リレーショナルデータベースの行と考えることができる
- エッジは2つのノード (頂点) を結び、それらの間の関係を表す。これは、リレーショナル・データベースにおける外部キーに相当する。プロパティと同様に、エッジは方向とラベルを持つ。方向は、どの頂点が始点 (tail) であり、どの頂点が終点 (head) であるかを決定する。ラベルは、2つの頂点の間に存在する関係の種類を決定する
- ラベル:エッジラベルは、グラフ内の関係の意味を表す。Amazon Web Services (AWS) のサービスである Amazon Neptune (高速で信頼性の高いフルマネージドグラフデータベースサービス) では、エッジラベルは、あるノードのラベルから別のノードのラベルに向かう一方向のものである。例えば、中継ノードと遠隔端末ノード間のエッジには、制御される側と制御する側という2つの一方向のラベルが適用される
- プロパティ : ノードやエッジに格納されたキーバリューペアの属性
グラフデータベースは、接続と関係をアプローチの中心に据えています。その結果、「何が何に接続されているか」を理解するための関係性に関する質問に答える、専用のデータストアとなっています。図 3 は、電力送配電網の接続をハイレベルに示したものです。

図 3 : 送配電設備とその接続関係
送配電網モデルのグラフには、ブレーカー、断路器、変圧器、バス、送配電網接続点、コンセントケーブルなど、さまざまな種類のノードが含まれています。これらの関係を理解することは、上流と下流の調査を行う上で非常に重要です。以下の図 4 に示した、送配電網内のどのノードが電力枯渇状態かあるいは電力供給中か調査するユースケースのように、条件付き検索により該当するネットワークの検索ができるのです。
図 4 : 条件付きトポロジー検索を示す。最終的にこの処理では、上流と下流の追跡用に、すべてのパスと通電中のノードが返される
電力送配電網運用システムと連携するシステム (例えば OMS や DMS) で、ネットワークトポロジーの追跡を実行する機能は、電力送配電網分析の基礎となります。グラフデータベースは関係に対する質問に答えるために構築されているため、ネットワークトポロジーの上流と下流の検索は、送配電網内のノードの関係性を知る必要があるすべてのユースケースで使用されるでしょう。ネットワークモデルを検索できることは、次のような送配電網の「what-if」分析シナリオに不可欠です。
- この設備が故障した場合、どの顧客が影響を受けるか?
- この設備が故障した場合、どの上流/下流の設備がリスクにさらされるか?
Amazon Neptune の役割を理解する
一部の電力会社では、情報交換に Common Information Model (CIM) 標準を使用しています。CIM 標準は、拡張可能なマークアップ言語 (XML) と Resource Description Framework (RDF) スキーマで表現されます。しかし、CIM の RDF は論理モデルであり、ソフトウェアにさまざまな形で実装できるため、システム間の交換形式は異なることがあります。というのも、データそのものと同様にデータ間の関係も重要であり、関係の強さや重み、あるいは質によって結果が左右されるからです。そこで、利用したいのがAmazon Neptune です。Amazon Neptune は、高速で信頼性が高く、フルマネージドのグラフデータベースサービスで、複雑な接続関係性を持つデータセットで動作するアプリケーションを簡単に構築、実行することができます。Amazon Neptune の中核となるのは、専用に構築された高性能なグラフデータベースエンジンです。このエンジンは、何十億もの関係を保存し、ミリ秒単位のレイテンシーでグラフを検索できるように最適化されています。Amazon Neptune は、一般的なグラフクエリ言語である Apache TinkerPop Gremlin および W3C の SPARQL Protocol and RDF Query Language (SPARQL) をサポートしているため、高度に結びついたデータセットを効率的に検索するクエリを構築することができます。Amazon Neptune の利用は、レコメンデーションエンジン、不正検出、ナレッジグラフ、創薬、ネットワークセキュリティなどのグラフのユースケースに対して非常に有効です。

図 5 : Amazon Neptune のハイレベルアーキテクチャ
以下の例では、AWS Glue の抽出、変換、ロード (ETL) パイプラインによって作成された、Amazon Simple Storage Service (Amazon S3) のデータのバルクローダーを使用して、サンプル電力系統データを RDF グラフとして Amazon Neptune に読み込むことが出来ました。Amazon S3 は、業界最高水準のスケーラビリティ、データ可用性、セキュリティ、パフォーマンスを提供するオブジェクトストレージサービスで、AWS Glue はサーバーレスのデータ統合サービスです。上記のように、送配電網から設備データを収集し、保存し、保守するシステムは複数存在します。適切なデータツールとプロセスにより、異なるオブジェクトとプロパティでネットワークのグラフが構築されます。その結果、分析とシミュレーションのための電力設備間の物理的な接続を記述した電力ネットワークトポロジーができあがります。送配電網分析のためのネットワークモデルサービスの目的は、接続性に関するトポロジー検索機能を提供することです。このサービスを利用するためには、電力送配電網の設計に応じたグラフモデルをグラフデータベースに作成します。以下の図 6 の SPARQL は、私たちが取り込んだ XML から RDF グラフを作成したものです。RDF グラフは、「トリプル」と呼ばれる (主語、述語、目的語) 形式のステートメントを含んでいます。トリプルは、主語と値の関連付けや、2 つの主語の間の関係の定義に使用されます。図 4 の設備管理のユースケースでは、変電所の設備が故障して停電が発生しました。原因は配電用変圧器でした。以下の図 6 は RDF トリプルを示しており、グラフの構造の概要を学ぶことができます。

図 6 : Amazon Neptune ノートブックの SPARQL または Gremlin クエリ
国際電気標準会議 (IEC) の CIM 規格では、各要素の相互接続を定義するために Terminal と ConnectivityNode が使用されます。CIM の CouductingEquipment は、CIM スキーマに基づいて1つまたは複数の Terminal を持つことができます。CIM モデルでは、電力系統の要素 (ブレーカー、負荷、送電線など) は互いに直接には関連付けられません。上記の場合、SPARQL クエリーは、共通のリンク : ConnectivityNode_X283383 を囲む Terminal 、という論理的な関係を持つ、設備の種類の関係をグラフ化します。CIM の DistributionTransformerWinding オブジェクトから上流と下流を検索する SPARQL またはGremlin クエリは、このソースに供給するすべてのオブジェクトとソースが供給するオブジェクトの一部を提供します。CIM の DistributionLineSegment および EnergyConsumers オブジェクトは、故障した配電変圧器に関連する送電線および下流の消費者を表します。
Amazon Neptune はプロパティグラフもサポートしています。上記の定義のセクションで述べたように、ラベルとプロパティは、一意の識別子と、それらを特徴付けるキーバリューのペアのセット、つまりプロパティを割り当てるために使用されます。電気事業者には、Gremlin データ形式または openCypher 形式で、 CIM 準拠のカンマ区切り値ファイル (CSV) を使用するオプションがあります。Gremlin 形式と openCypher 形式では、CSV 形式を使用したデータの場合、RDF とは異なり、頂点、辺、ノード、関係を別々のファイルで定義する必要があります。RDF では、同じ種類の関係を持つインスタンスを一意に特定できず、モデリングの変更なしにインスタンスの関係を限定できないことを考えると、プロパティグラフの利用は有用であると考えられます。Amazon Neptune は Gremlin をサポートしているので、グラフ検索から強力なソフトウェアパターンを使用して、上流の検索、下流の検索、送配電設備 「X」 についてのすべての関係の検索など、トポロジーに関するユースケースを満たすことができます。これらのパターンの例としては、以下のようなものがあります。
- 中心性
- 最小共通祖先
- 最短経路
Amazon Neptune 上での送配電網のグラフ化
さて、グラフデータベースがどのように使われるかのユースケースを説明しましたが、その実現方法について説明します。多くのデータソースが関わるので、データモデリングが鍵となります。送配電網分析のユースケースに役立つ質問をグラフデータベースに投げかけるには、ドメインを記述したデータモデルが必要です。
電力会社では、IEC 標準の CIM を採用しています。電力会社の送配電チームをサポートするデータエキスパートやエンジニアは、IEC CIM 規格 (IEC 61968 や IEC 61970 など) を使用しています。この規格は、エネルギー市場データやネットワーク運用に関連する多くのビジネス機能をサポートするデータを、データの横断的活用およびそのためのデータ交換の観点から定義しており、データ取得、機器制御、障害/停電管理、計画停電スケジュール、電気ネットワーク切り替え/再構成、故障位置、隔離、送配電の復元、などがあります。これらの標準に準拠したネットワークトポロジーグラフを作成するためには、データ準備、データ変換、そして、グラフデータベースそのものが必要です。そのために以下図 7 に示すように、Amazon S3 、AWS Glue 、Amazon Neptune 、そして新しいビジュアルデータ準備ツールである AWS Glue DataBrew を使用します。

図 7 : 送配電網トポロジー上にグラフを作成するための AWS Glue と Amazon Neptune の利用
データの準備
送配電網を正確に表現するためには、データセットの理解と整備の両方が重要です。AWS Glue DataBrew を使用すると、データのパターンを理解し、異常を検出し、修正するために、データをプロファイリングすることで、データ品質を評価できます。データレイク、データウェアハウス、データベース内のデータに直接接続することができます。AWS Glue DataBrew は、ソースシステムから入ってきた新しいデータに、保存した変換を直接適用することで、データのクリーニングや正規化を自動化するために使用することも可能です。以下の図 8 では、GIS システムから抽出された電力系統の CIM データファイルを取り込んでいます。

図 8 : AWS Glue DataBrew とコンピュータ支援設計 (CAD) 電力系統のプロファイリングメトリクス
AWS Glue DataBrew を使用して、Amazon Neptune に読み込まれるグラフのエッジとノードを作成するために使用される適切なフィールドとプロパティを各系統設備が持っているかどうか検証することができます。各オブジェクトが正しいプロパティを持つことを検証することは重要です。AWS Glue DataBrew はこれを支援します。
データ変換
複数のデータソースからデータを取り込む場合、自動化された ETL とデータのカタログ化は必須です。AWS Glue は、お客様がデータの準備と読み込みを簡単に行えるようにする、フルマネージド ETL サービスです。AWS Glue を使用することで、ソースデータの準備と Amazon Neptune グラフデータベースへのロードという極めて重要なタスクを完了することができます。AWS Management Console では、数回クリックするだけで ETL ジョブを作成・実行できます。AWS Management Console は、AWS クラウドへのアクセスと管理に必要なすべてを1つの Web インタフェースで提供しています。AWS Glue を AWS 上に格納したデータ (通常は Amazon S3) に向けるだけで、AWS Glue はデータを検出し、関連するメタデータ (例えば、テーブル定義やスキーマ) を AWS Glue Data Catalog に保存します。一度カタログ化されると、データはすぐに検索、問い合わせが可能になり、ETL に利用できるようになります。AWS Glue を使うことで、データ変換ワークフローを視覚的に構成し、AWS Glue の Apache Spark ベースのサーバーレス ETL エンジンでシームレスに実行することが可能です。以下の図 9 と図 10 は、ETL ジョブのフローを作成するための AWS Glue のビジュアルエディタを示しています。ビジュアルエディタは、送配電網リソースからすべての抽出物を読み込んで CSV ファイルを作成し、それを Amazon Neptune グラフデータベースにロードしてプロパティグラフを作成することができます。

図 9 : ネットワークトポロジーグラフで使用されるソースシステムファイルの抽出物
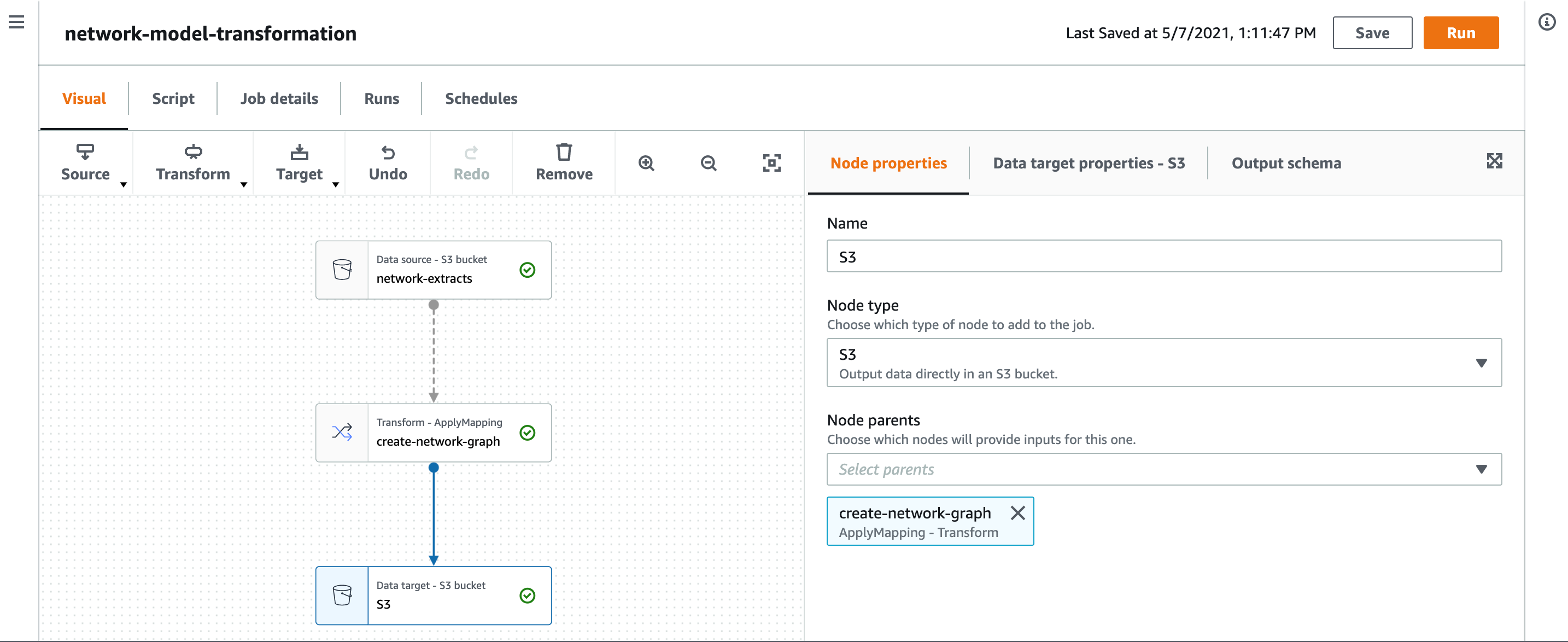
図 10 : ネットワークモデルグラフのエッジとノードを作成するフローを視覚的に示した図
AWS Glue を使用して、日次のデータパイプラインに、トポロジーストアを接続し、データを収集・整理をさせることで強化し、得られたデータをデータレイクまたは Amazon S3 に公開することができます。AWS Glue は、ApplyMapping 、RenameField 、Relationalize 、FlatMap などの組み込みの変換を持ちます。このシナリオにおいて、AWS Glue ジョブは、送配電網内のサイロ化したシステムから収集したファイルからグラフを整備する役割を担うビジネスロジックを含みます。AWS Glue ジョブは、各ソースシステムを検索し、グラフで使用できる関係を抽出し、作成するビジネスルールを実装します。これらのビジネスルールは、グラフ中の関係を作成するために、システム間の外部キーを検索し、バイナリで表されたテキストを検索できます。出力は、エッジとノードの2つのファイルになります。
図 11 : Amazon Neptune にロードされる AWS Glue ジョブで作成された CSV
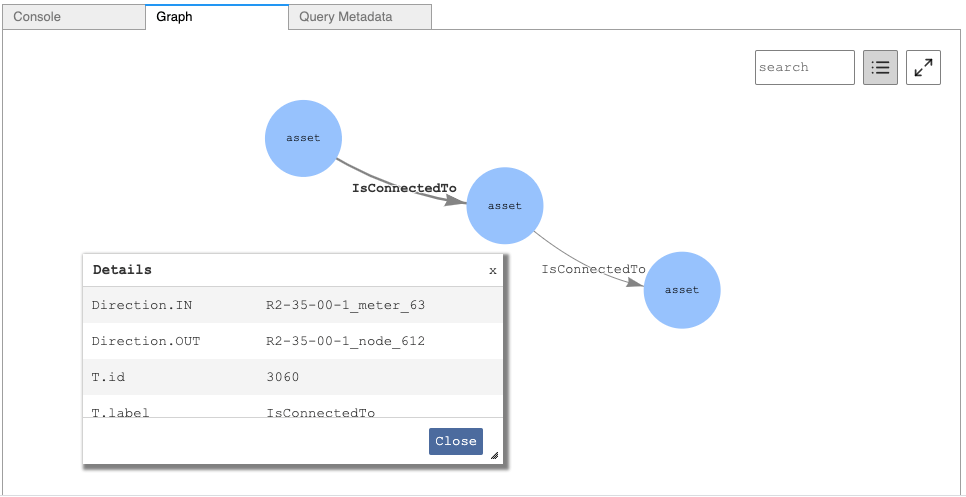
Amazon Neptune にデータをロードできたので、分析のために、スマートメーターネットワークが配電ネットワークと統合されるシナリオを見てみましょう。Gremlin クエリを実行して、メーターを配電網の電力負荷に接続するのに役立てることができます。AWS Glue ジョブでは、「asset」というラベルが作成されました。Amazon Neptune ノートブックの詳細ボタンを使用すると、中央のノードがメーターであることが確認できます。AWS Glueジョブは、エッジファイル内に「IsConnectedTo」というラベルフォームも作成しました。

各ノードをクリックすると、メーターにどのような接続が出入りするのかを確認することができます。
分析アプリケーション用に送配電網をモデル化するためには、以下のようなことができなければなりません。
- 洗練されたあるいは複雑な構造の表現
- 系統の設備の迅速かつ柔軟な接続
- 系統の設備の接続状態 (接続の意味及びさまざまな強度、重み、質) の理解に基づく質問への回答
私たちは、AWS が高度に結びついたデータセットを処理し変換するサービスを提供することで、これを実現できることをお見せしました。
より良く、より速い意思決定の実現
送配電網をベースとした分析を実現するためには、ネットワークモデルの表現が必須です。送配電網ネットワークは時間とともに進化するため、将来的に次世代送配電網分析アプリケーションを開発する際の要求を満たすために、データベースの構造を大きく変更することなく、この動的な変化をサポートできるデータストアを持つことが重要です。分散アーキテクチャを採用したグラフデータベースは、これを実現可能なソリューションです。AWS を Amazon Neptune とともににご利用いただくことで、このソリューションをサポートし、複数のデータソースをまとめて、電力会社や他の資産集約型産業がより良い迅速な意思決定を行えるようなサービスを提供します。詳細については、AWS for Industrial, Energy & Utilities をご覧ください。
本ブログは、ソリューションアーキテクトの高橋が翻訳しました。原文はこちらです。