Amazon Web Services ブログ
InfoJobs (Adevinta) が AWS Inferentia と Amazon SageMaker で NLP モデル予測のパフォーマンスをどのように向上させたか
この記事は、Adevinta Spain 社の ML エンジニアである Juan Francisco Fernandez と、AWS AI/ML スペシャリストソリューションアーキテクトの Antonio Rodriguez と João Moura が共同執筆したゲスト投稿 How InfoJobs (Adevinta) improves NLP model prediction performance with AWS Inferentia and Amazon SageMaker を翻訳したものです。
Adevinta グループの子会社である InfoJobs は、次の職を探している求職者と、募集要項を満たす最適な人材を探している雇用主との間に、完璧なマッチングを提供します。この目的のため、PyTorchを通して BERT などの自然言語処理(NLP)モデルを使用して、ユーザーがポータルに履歴書をアップロードした瞬間に、関連情報を自動的に抽出します。
一般的な CPU ベースのインスタンスでは、フィールドの複雑さと多様性を考慮すると、NLP モデルによる推論に数秒かかることがあります。これは、求人情報ポータルサイトのユーザーエクスペリエンスに影響を与えます。また、GPU ベースのインスタンスはこれらのモデルをホストするとコストがかかるため、我々のビジネスにとって実現不可能なソリューションです。このソリューションでは、コストを最小限に抑えながら、予測のレイテンシを最適化する方法を探していました。
この課題を解決するために、私たちは当初、2つの軸に沿ったいくつかの解決策を検討しました。
- より大きな汎用インスタンスや GPU 搭載インスタンスを使用した垂直スケーリング
- 量子化などのオープンな技術手法や ONNX などのオープンツールを使用したモデル最適化
どちらのオプションも、単独でも組み合わせても、必要なパフォーマンスを手頃な価格で提供することはできませんでした。AWS AI/ML スペシャリストの協力を得て、あらゆる選択肢をベンチマークした結果、AWS Neuron で PyTorch モデルをコンパイルし、 AWS Inferentia を使って Amazon SageMaker エンドポイントにホストすると、初期の最良の選択肢と比較して、予測レイテンシーを最大 92% 削減し、75% のコスト削減を実現しました。言い換えれば、CPU コストで最高の GPU パワーを手に入れたようなものでした。
Amazon Comprehend は、機械学習を使用してテキスト内の価値のある洞察や関連性を自動的に発見する、プラグアンドプレイのマネージド NLP サービスです。しかし、今回のケースでは、この特定のタスクに細かく調整されたモデルを使用したいと考えました。
この投稿では、実施したベンチマークの概要と、SageMaker を使用した AWS Inferentia による NLP モデルのコンパイルとホスティングの事例を紹介します。また、InfoJobs がこのソリューションを利用して、NLP モデルの推論パフォーマンスを最適化し、コスト効率の高い方法でユーザーの履歴書から重要な情報を抽出している様子も紹介します。
ソリューションの概要
まず、NLP モデルをホストするためのパフォーマンスとコストの最適なバランスを見つけるために、AWS で利用可能なさまざまなオプションを評価する必要がありました。次の図は、リアルタイム推論の最も一般的な選択肢をまとめたものです。そのほとんどは、AWS との共同作業中に検討されました。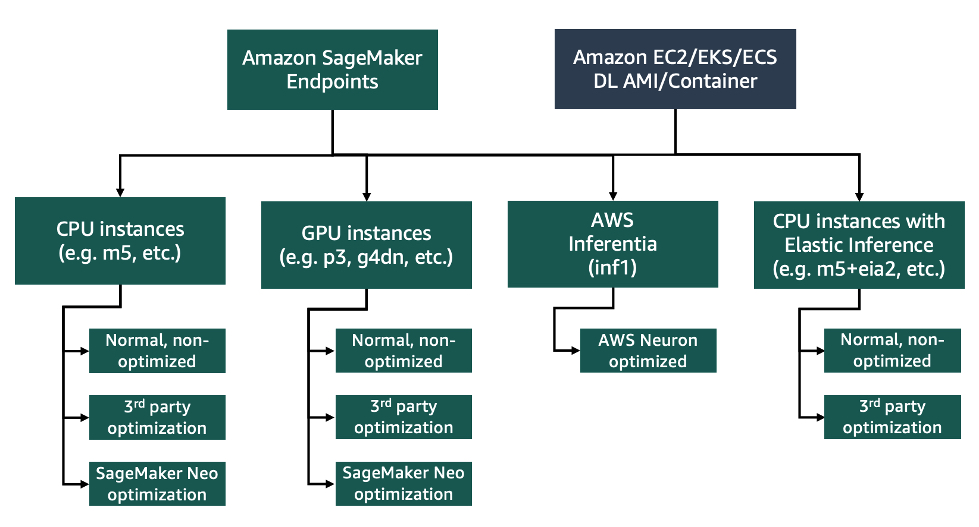
SageMaker のホスティングオプションベンチマーク
私たちは、 Hugging Face model hub で公開されている事前トレーニング済みモデル bert-base-multiingual-uncased を使ってテストを開始しました。これは、InfoJobs の CVキー値抽出モデルで使用されるものと同じベースモデルです。このモデルを CPU ベース、GPU ベース、また AWS Inferentia ベースとインスタンスタイプの組み合わせを変えて、 SageMaker エンドポイントにデプロイしました。また、 Amazon SageMaker Neo による最適化と、必要に応じて AWS Neuron でのコンパイルについても検討しました。
このシナリオでは、AWS Inferentia インスタンスを使用して SageMaker エンドポイントにモデルをデプロイすると、同じコストと仕様の範囲では、CPU インスタンスと比較して推論時間が 96% 、GPU インスタンスと比較して、44% 高速になりました。これにより、CPU インスタンスを使用する場合の 15 倍、GPU インスタンスを使用する場合の 4 倍の推論リクエストに対して同じコストで応答できます。
この結果を受けて、次に InfoJobs で実際に使われているモデルで検証を行いました。これは、パフォーマンス向上のために PyTorch による量子化が必要な、より複雑なモデルであるため、 bert-base-multilingual-uncased を使用した標準的なケースと比較して、結果が悪くなることが予想されました。このモデルに対するテスト結果は、次の表にまとめています (2022 年 2 月 20 日現在の us-east-1 リージョンでの価格に基づく)。
| カテゴリー | モード | インスタンスタイプの例 | p50 推論レイテンシー (ミリ秒) | TPS | 1 時間あたりのコスト (米ドル) | 1 時間あたりの推論 | 推論 100万回あたりのコスト (米ドル) |
| CPU | ノーマル | m5.xlarge | 1400 | 2 | 0.23 | 5606 | 41.03 |
| CPU | 最適化済み | m5.xlarge | 1105 | 2 | 0.23 | 7105 | 32.37 |
| GPU | ノーマル | g4dn.xlarge | 800 | 18 | 0.736 | 64800 | 11.36 |
| GPU | 最適化済み | g4dn.xlarge | 700 | 21 | 0.736 | 75600 | 9.74 |
| AWS Inferentia | コンパイル済み | inf1.xlarge | 57 | 33 | 0.297 | 120000 | 2.48 |
次のグラフは、InfoJobs モデルのリアルタイム推論応答時間を示しています (値が小さいほど良い)。この場合、推論レイテンシは CPU または GPU の両方のオプションと比較して 75 ~ 92% 高速化されています。

これは、次の推論 100万回あたりのコストのグラフに示すように、CPU または GPU のオプションと比較して、推論実行にかかるコストが 4 ~ 13 倍削減できることを意味します。
 このテストでは、推論コードにさらなる最適化が行われなかったことを強調しておきます。しかし、AWS Inferentia を使用することで得られるパフォーマンスとコストのメリットは、当初の予想を上回り、本番稼働に踏み切ることができました。今後は、 NeuronCoreパイプラインや Pytorch 固有の DataParallel API など、Neuronの他の機能を使って最適化を進めていく予定です。ぜひ、ご自身のユースケースやモデルに合わせた結果を調査し、比較してみてください。
このテストでは、推論コードにさらなる最適化が行われなかったことを強調しておきます。しかし、AWS Inferentia を使用することで得られるパフォーマンスとコストのメリットは、当初の予想を上回り、本番稼働に踏み切ることができました。今後は、 NeuronCoreパイプラインや Pytorch 固有の DataParallel API など、Neuronの他の機能を使って最適化を進めていく予定です。ぜひ、ご自身のユースケースやモデルに合わせた結果を調査し、比較してみてください。
SageMaker Neo で AWS 推論のためにコンパイルする
モデルをコンパイルして AWS Inferentia インスタンスでホストできるように、Neuron SDK を直接使用する必要はありません。
SageMaker Neo は、クラウドインスタンスやエッジデバイスで推論する機械学習 (ML) モデルを、精度を損なうことなく高速に実行するために自動的に最適化します。特に、Neo はバックグラウンドで Neuron SDK を利用して、さまざまな transformer ベースのモデルをコンパイルすることが可能です。これにより、使い慣れた SageMaker SDK と統合された API を利用することで、コンテキストスイッチ不要で、AWS Inferentia の恩恵を受けることができます。
このセクションでは、Neo を使用し、AWS Inferentia に対して BERT モデルをコンパイルする方法を例として紹介します。次に、そのモデルを SageMaker エンドポイントにデプロイします。プロセス全体を詳細に説明したサンプルノートブックは GitHub にあります。
まず、PyTorch でモデルをトレースするためのサンプル入力を作成し、モデルのみを格納した tar.gz ファイルを作成する必要があります。これは、Neo にモデルアーティファクトをコンパイルさせるために必要なステップです (詳しくは、Prepare Model for Compilation をご覧ください)。デモンストレーションの目的で、このモデルは、タスクに対してまったく微調整されていないシーケンス分類用の模擬モデルとして初期化されます。実際には、モデル識別子を Hugging Face model hub から選択したモデル、またはローカルに保存されたモデルアーティファクトに置き換えます。次のコードをご覧ください。
import transformers
import torch
import tarfile
tokenizer = transformers.AutoTokenizer.from_pretrained("distilbert-base-multilingual-uncased")
model = transformers.AutoModelForSequenceClassification.from_pretrained(
"distilbert-base- multilingual-uncased", return_dict=False
)
seq_0 = "This is just sample text for model tracing, the length of the sequence does not matter because we will pad to the max length that Bert accepts."
seq_1 = seq_0
max_length = 512
tokenized_sequence_pair = tokenizer.encode_plus(
seq_0, seq_1, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt"
)
example = tokenized_sequence_pair["input_ids"], tokenized_sequence_pair["attention_mask"]
traced_model = torch.jit.trace(model.eval(), example)
traced_model.save("model.pth")
with tarfile.open('model.tar.gz', 'w:gz') as f:
f.add('model.pth')
f.close()Neuron コンパイルは、辞書ベースのモデル出力をサポートしていないため、事前トレーニング済みモデルを読み込むときは return_dict パラメーターを False に設定することが重要です。model.tar.gz ファイルを Amazon Simple Storage Service (Amazon S3) にアップロードし、その場所を traced_model_url という名前の変数に保存します。
次に、 PyTorchModel SageMaker API を使用してモデルをインスタンス化し、コンパイルします。
from sagemaker.pytorch.model import PyTorchModel
from sagemaker.predictor import Predictor
import json
traced_sm_model = PyTorchModel(
model_data=traced_model_url,
predictor_cls=Predictor,
framework_version="1.5.1",
role=role,
sagemaker_session=sagemaker_session,
entry_point="inference_inf1.py",
source_dir="code",
py_version="py3",
name="inf1-bert-base-multilingual-uncased ",
)
compiled_inf1_model = traced_sm_model.compile(
target_instance_family="ml_inf1",
input_shape={"input_ids": [1, 512], "attention_mask": [1, 512]},
job_name=’testing_inf1_neo,
role=role,
framework="pytorch",
framework_version="1.5.1",
output_path=f"s3://{sm_bucket}/{your_model_destination}”
compiler_options=json.dumps("--dtype int64")
)コンパイルには数分かかる場合があります。ご覧のとおり、モデル推論への entry_point は inference_inf1.py スクリプトです。このスクリプトは、モデルがどのように読み込まれるか、入力と出力の前処理方法、および予測に使用する方法を決定します。GitHub でスクリプトの全容を確認してください。
最後に、AWS Inferentia インスタンスの SageMaker エンドポイントにモデルをデプロイし、そこからリアルタイムで予測を取得できます。
from sagemaker.serializers import JSONSerializer
from sagemaker.deserializers import JSONDeserializer
compiled_inf1_predictor = compiled_inf1_model.deploy(
instance_type="ml.inf1.xlarge",
initial_instance_count=1,
endpoint_name=f"test-neo-inf1-bert",
serializer=JSONSerializer(),
deserializer=JSONDeserializer(),
)
payload = seq_0, seq_1
print(compiled_inf1_predictor.predict(payload))このように、SageMaker SDK の標準フローを補完するシンプルな API を利用することで、SageMaker で AWS Inferentia インスタンスを利用するメリットをすべて得ることができました。
最終的なソリューション
次のアーキテクチャは、AWS にデプロイされたソリューションを示しています。

この投稿で紹介しているすべてのテストおよび評価分析は、SageMaker と AWS Inferentia の使いやすさのおかげで、AWS AI/ML スペシャリストソリューションアーキテクトの協力のもと、 3 週間内ですべて完了しました。
まとめ
この投稿では、InfoJobs (Adevinta) が SageMaker エンドポイントで AWS Inferentia を使用して、NLP モデル推論のパフォーマンスを費用対効果の高い方法で最適化し、推論時間を最大 92% 削減し、当初の最良の代替案よりも 75% 低いコストを実現した方法を共有しました。SageMaker、Neuron SDK for PyTorch、および AWS Inferentia を使用して、独自のモデルを簡単にコンパイルしてデプロイするためのプロセスとコードを流用することができます。
AWS AI/ML スペシャリストソリューションアーキテクトと InfoJobs エンジニアの間で行われたベンチマークテストの結果は、InfoJobs の環境でも検証されました。このソリューションは現在本番環境にデプロイしており、ユーザーが InfoJobs ポータルにアップロードしたすべての履歴書の処理をリアルタイムで行っています。
次のステップとして、 SageMakerと Hugging Face 統合や SageMaker Training Compiler などの機能を活用して、モデルのトレーニングや SgaeMaker で ML パイプラインを最適化する方法を検討する予定です。
SageMaker で AWS Inferentia を試し、AWS と連携して特定の ML のニーズについて議論することをお勧めします。SageMaker と AWS Inferentia のその他の例については、 GitHub 上の SageMaker examples と AWS Neuron チュートリアルもご覧ください。
________________________________________
翻訳はアンナプルナラボの常世が担当しました。