Amazon Web Services ブログ
データメッシュで作る消費財企業向けモダンデータレイクのアーキテクチャ
COVID-19 パンデミック以来、世界中でオンラインショッピングと消費者向け直販(Direct To Consumer; DTC)への劇的なシフトが見られます。消費財(Consumer Packaged Goods; CPG)業界がどの業界よりもこの変化を感じていることは間違いないでしょう。Statista 社によると「小売ウェブサイトへの訪問者数は全世界で、2020年1月の160億7000万回から、2020年6月には約 220 億回に増加」しました。ウェブサイトへのトラフィックが半年間で27% 増加したことで、データ企業、特に消費財企業にとって管理すべきデータ量が急激に増えました。
これまで消費財企業の多くは消費者と直接的な接点を持ってきませんでした。そのためデータは、小売業者との間の発注や出荷といった内部情報など最小限しかなかったのです。今や優れた消費財企業はエンドユーザーである消費者の行動と、検索分析やソーシャルメディアにおけるセンチメントといった外部データをトラッキングしています。このブログ投稿では、データを大規模に管理するというテーマを深く掘り下げ、なぜ消費財企業がデータメッシュによるデータ管理という新しいアプローチを検討する必要があるのか、その理由について解説します。
消費財企業組織を横断するデータフロー
データエコシステムの概要から始めましょう。競争優位性の観点からデータは重要な要素となって来たため、多くの企業は、あらゆるビジネスレベルで、アナリティクスと機械学習を利用してデータを消費・変換・拡張できるようにしており、データを進化し拡大する資産として扱っています。データに基づき製品開発やマーケティング意思決定を行う消費財ブランドマネージャーにとって、これは特に重要なことです。
モダンなデータエコシステムには3つの主要な登場人物がいます:
- データプロデューサー – システムあるいは、(注文、請求書、在庫などの)入力データソースを所有するドメインエキスパート
- データプラットフォームビルダー – 多様なデータスキルを持つ IT チーム(企業の成熟度による)
- データコンシューマー – データを利用してビジネスを最適化し、意思決定を行い、戦略を策定するアナリストとオペレーター
消費財企業におけるデータレイクの課題と制約
データレイクは一般的に、急速なデータ増加を管理するために利用されます。この一元化されたリポジトリには、構造化データと非構造化データが格納されます。データはバッチあるいは、リアルタイムストリーミングを介して取り込むことができます。しかし、多数のデータソースからのデータがペタバイトにスケーリングしていくと、この実績のあるテクノロジーにはいくつかの制限が生じてきます:
- セキュリティ上の課題 – 大規模にきめ細かなセキュリティを管理することが難しい
- 汎用化したアプローチ – 「1つのサイズで全てを満たす(one-size-fits-all)」のアプローチでは、特定のデータセットに対してデータレイクを最適化できない
- 完全性の課題 – 多くの場合、データレイクに投入されたデータがコンテキストを失ってしまう
- マニュアル作業による保守 – 異なる、矛盾したデータセットに対するマニュアル作業が必要
こういった制限は、データレイクにデータを取り込み、そこから意味のある情報を取り出す上で、開発サイクルの長期化やボトルネックにつながります。つまり、消費財企業の IT 部門の多くが大規模なデータの維持とマイニングに苦労しているのです。一方で、データコンシューマーにとっても、エンタープライズデータへのアクセスと分析は複雑で、フラストレーションの多いものになり得ます。
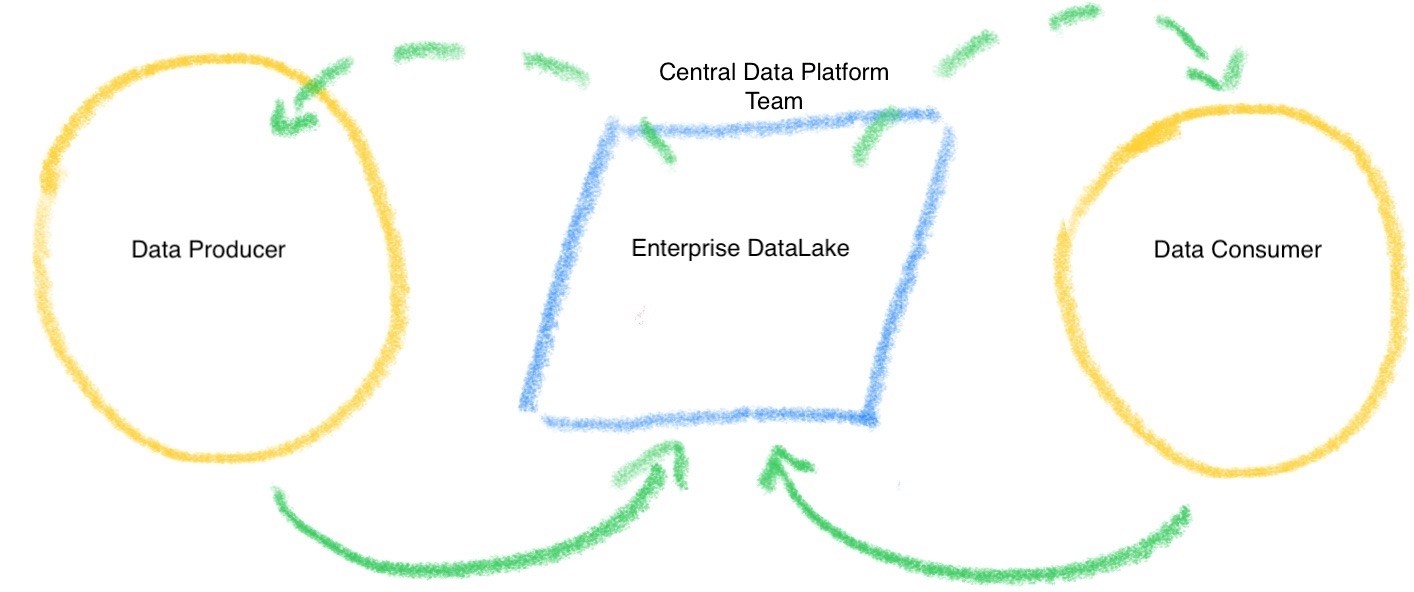
データレイクモデルでは、データはエンタープライズデータレイクに取り込まれます。中央管理プラットフォームチームは、セキュリティ、データ取り込み、変換、アクセスおよび、データの可用性を管理します。データプロデューサーとデータコンシューマーは、データを保存、アクセスするためにはこの中央管理チームを経由する必要があります。
モノリスから管理可能な形へ: ソフトウェアとの類似
中央管理 IT 部門が管理するデータレイクは、1990 年代のモノリシックソフトウェアに似ています。柔軟性の欠如、相互依存性の高さ、開発サイクルの遅さといった要素が、ソフトウェア開発におけるマイクロサービス革命の原動力となりました。これによって、スケーラビリティ、開発サイクルの短縮、セキュリティの分離、管理容易性がもたらされたのです。
では、このマイクロサービスの設計原則をデータにどのように適用すればよいのでしょうか。消費財業界(あるいはその他の業界でも)において、その答えがデータメッシュです。
データメッシュは、比較的最近提唱されるようになったアーキテクチャ設計であり、モノリシックなデータレイクアーキテクチャの欠点に着目し、ソフトウェア設計におけるマイクロサービスと同様の利点を提供します。データメッシュでは、データそのものがプロダクト(商品)であり、ドメインに依存しない、セルフサービスのデータインフラストラクチャによって支えられています。データメッシュは、以下の方法で従来のデータレイクの持つモノリシックな性質を打開します:
- データをプロダクトとして扱う – 典型的なデータレイクでは、データレイクとデータパイプラインがプロダクトです。 データメッシュの場合、データと、データを収集して公開するドメインおよびプロデューサーの専門知識とが、プロダクトとなります。
- 所有権を分散する – IT によって中央管理されるデータレイクと異なり、データメッシュは所有権を分散化しています。それぞれのビジネスドメイン(データプロデューサー)が、所有するデータのライフサイクルをキュレートし、検証、公開、維持および、管理する責任を持ちます。
- 適切な粒度で、大規模なアクセス制御を行う – データメッシュでは、データはプロデューサーによって所有されるため、データの粒度に基づいて、アクセス、ガバナンス、保持のポリシーとその他カスタムアクセスポリシーを指定します。責任とアクセス制御ポリシーをデータ所有者に持たせることで、データレイクにおける一元化されたアクセス制御というボトルネックが解消されます。
- スケーラブルにデータを発見する – データメッシュでは、データコンシューマーがドメイン、粒度、品質、頻度などに基づいてデータを発見、識別、サブスクライブ(訳注: 定期的に最新を入手)できるようになります。これにより、データコンシューマーは、スケーラブルなアクセスと発見が可能になり、中央管理チームに依存しなくてよくなります。
データメッシュでデータプロデューサーがデータを公開すると、次のプロパティを使用してイミュータブルな(不変の)データコントラクトが作成されます:
- データ型
- 物理スキーマ
- ビジネス特性
- 配信頻度
- データ品質保証
- ライフサイクルポリシー
データコントラクトは、企業内を横断してデータを検出できるようにするメカニズムです。 コントラクトプロパティは、ライフサイクルの初めから終わりまでデータに関連付けられており、データコンシューマーは特定のデータコントラクトプロパティを発見、サブスクライブできます。
データメッシュアーキテクチャでは、データは生成された場所でローカルに保存されます。中央管理プラットフォームチームは、セキュリティを管理し、コントラクトが確実に遂行されるようにし、ツールと自動化を提供します。データプロデューサーとデータコンシューマーは、企業データ全体へのアクセスと可視化が可能で、相互に通信できます。

データメッシュリファレンスアーキテクチャおよび、消費財業界での利用
以下は典型的なデータメッシュの実装例です:

この設計では pub/sub モデルを採用しています。このソリューションでは AWS Lake Formation を利用しているため、データレイクの作成は簡素化できますが、データソース、アクセス、セキュリティポリシーは手動で定義する必要があります。AWS Glue を利用してデータカタログ内のデータを発見することもでき、またコントラクトで定義されたプロパティを使用してメタデータを発見することもできます。
分離されたマイクロサービスデータセットをデータメッシュで管理する
近年、消費財企業はマイクロサービスとコンテナによるアーキテクチャで、オンラインインフラストラクチャをモダナイズするべく多額の投資を行っています。この新しいデザインパターンでは、各マイクロサービス(検索、チェックアウト、注文、商品など)によって新たに作成されるデータの量は指数関数的に増加します。それぞれの固有のデータストリームは、それぞれのデータプロデューサーによって所有され、それぞれの品質、ガバナンス、ライフサイクルプロパティを有しています。データプロデューサーは、リアルタイムあるいはバッチでデータプラットフォームにアップロードできるようにデータストリームを構成できます。このマイクロサービスの設計は、データメッシュ概念の実装パターンに自然に適合します。
消費財業界におけるマイクロサービスの詳細については、Danny Yin のブログ投稿「消費財業界におけるマイクロサービスアーキテクチャに移行するための成功戦略」をぜひお読みください。
消費財データポイントとしてのデータスチュワードを任命する
データメッシュアーキテクチャがスケーラブルであるために、組織にデータスチュワードを任命するのが一般的です。データスチュワードは、データプロデューサーがデータを生成し、データそのもののコントラクトプロパティ、ユーザーアクセス制御、データの品質、予期されるデータコンシューマーの利用パターンについて深い知識を持つために、頼るべき人物です。データスチュワードの仕事は、データのライフサイクル全体を通してデータコントラクトの整合性を確保し、コントラクトの変更管理を支援することです。
データクリーンルームで保護された消費財データの発掘
この新たなユースケースでは、PII (Personally Identifiable Information、個人を特定できる情報)や POS トランザクションデータなどの生データはクリーンルームに保存され、プライバシー制限の対象として扱われるかもしれません。クリーンルームでは、データコンシューマーは、プライバシー保護のため十分に匿名化された情報に対してクエリを実行することができます。データコンシューマーは匿名化されたデータと、制限されていないデータとを結合し、プライバシー要件を遵守しながら情報を分析することもできます。データメッシュアーキテクチャでは、データコントラクトの制約を適用することにより、クリーンルームの要件をネイティブにサポートできます。
各国が OECD ガイドラインや欧州における GDPR といった厳格なデータプライバシー規則の採用が進むにつれて、データの維持、保護、利用、破棄の方法を管理する規則もより複雑になります。データメッシュアーキテクチャでは、データを適切に分離し、セキュリティポリシーを適用し、データへのアクセスを許可できます。データファースト設計とデータメッシュのきめ細かいアクセス制御により、コストのかかる企業全体にわたるデータプロジェクトを必要とすることなく、データプライバシー要件をサポートするネイティブメカニズムが提供されます。
データメッシュで消費財関連ベンダーと協業する
多くの消費財企業は、原材料や完成品を取り扱うサプライチェーンや物流などの外部委託業者にまで横断して、オペレーションを最適化しようとしています。データメッシュは、消費財企業とベンダー間のコラボレーションをネイティブにサポートするようにゼロから設計されています。内部および外部のデータプロデューサーとデータコンシューマーは、合意されたコントラクトを通じて自由にデータを交換でき、データの不変性はマルチベンダーシステムが効果的に動作するための整合性を提供します。
まとめ
データメッシュアーキテクチャは、モノリシックなデータレイクとデータウェアハウスに対するモダンなアプローチであり、消費財企業がデータを大規模に管理できるようにします。データを企業価値に変えるためにAWS がどのようにサポートできるのか、すぐにでも AWS アカウントチームに連絡して聞いてみてください。あるいは AWS 消費財サイトにアクセスして詳細を確認してください。
リファレンスとリソース: 「How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh」
著者について
Ilan Raab
Ilan Raab は、AWS 消費財(CPG)業界のワールドワイドテクノロジーリーダーです。Ilan は2019年に AWS に参加し、Make/Move/Market の全てのビジネスエリアにおいて消費財に焦点を当てたソリューションを構築し、企業における消費財テクノロジー戦略の定義と実行を担当しています。これまで多くの消費財業界のお客様と協業し、最先端の AWS テクノロジーと Thought Leadership を発揮してビジネスの変革を支援してきました。AWS に参加する以前は、エンタープライズソフトウェアおよびネットワーキング分野のいくつかのスタートアップ企業においてエンジニアリング担当副社長であり、共同創設者でした。
Marco Chiapusso
Marco Chiapusso は、2020年1月に EMEA のソリューションアーキテクチャマネージャーとして AWS に参加しました。グローバルエンタープライズのお客様と協業して、ベストプラクティス、テクノロジー、戦略を共有し、クラウドによっていかにお客様のスピード、俊敏性の向上に寄与できるのかと同時に、彼らの顧客により多くの時間を費やすことができるのかを発信してきました。AWS に参加する以前は、シニアテクノロジーのポジションを歴任し、組織を最新のテクノロジー対応企業に変革するための大規模イニシアチブを複数主導あるいは、共同で主導してきました。1 PB超のデータを有する最新のデータプラットフォームの開発と展開の案件では、顧客のインサイトを向上させ、大規模な機械学習ができるよう強化しました。アディダス社の在職期間は、アーキテクチャ、開発、サポート、データ、AI や IoT を含むイノベーション、組織開発など、さまざまな分野で活動しました。
翻訳は Solutions Architect 杉中が担当しました。原文はこちらです。