AWS for Industries
How to Create a Modern CPG Data Architecture with Data Mesh
Since the COVID-19 pandemic we’ve seen a seismic shift around the world to online shopping and direct-to-consumer sales. Arguably, the consumer packaged goods (CPG) industry felt this shift more than any other industry. According to Statista, “Retail websites generated almost 22 billion visits in June 2020, up from 16.07 billion global visits in January 2020.” This massive 27% increase in website traffic in six months accelerated the amount of data companies, CPGs in particular, need to manage.
Historically, most CPGs have not communicated directly with consumers, so data was minimal and represented mostly internal information like order and shipping details with retail partners. Now, savvy consumer product companies are tracking end-user customers and external data like search analytics and social media sentiment. In this blog post, we’ll dive deep into the subject of managing data at scale and explain why CPGs should consider a new approach to data management with a data mesh.
Data Flow Across CPG Organizations
Let’s start with an overview of the data ecosystem. Because data has become an important point of competitive differentiation, many companies allow people at every business level to consume, transform, and augment data with analytics and machine learning—treating data as an evolving, expanding asset. This is especially important for CPG brand managers who use data to drive their product development and marketing decisions.
There are three core groups in a modern data ecosystem:
- Data producers – The domain experts who own the systems or sources of incoming data (orders, invoices, inventory, and so on).
- Data platform builders – A segment of the IT team with diverse data skills, depending on the company’s maturity.
- Data consumers – Analysts and operators who use data to optimize the business, make decisions, and define strategies.
Challenges and Limitations of Data Lakes for CPGs
Data lakes are commonly used to manage rapid data growth. This centralized repository stores structured and unstructured data. You can ingest information in batches or through real-time streaming. However, when data scales to petabytes with numerous data sources, this proven technology has a few limitations:
- Security challenges – Granular security at scale is difficult.
- Generic approach – A one-size-fits-all approach doesn’t allow you to optimize the data lake for specific datasets.
- Integrity issues – Typically, data loses context after it’s fed into the data lake.
- Manual maintenance – Different, conflicting datasets require manual effort.
These limitations translate into long development cycles and bottlenecks to get data into the data lake and extracting meaningful information from it, meaning many CPG IT departments are struggling to maintain and mine data at scale. Meanwhile, for data consumers, accessing and analyzing enterprise data can be complex and frustrating.

In a data lake model, data is ingested into an enterprise data lake. The central platform team manages security, ingestion, transformation, access, and data availability. Data producers and consumers need to go through the centralized team to store and access data.
From Monolith to Manageable: A Software Analogy
Data lakes managed by a central IT department are similar to the monolithic software products of the 1990s. The rigidness, interdependencies, and slow development cycles were the driving force behind the microservices revolution in software development, which offers scalability, shorter development cycles, isolated security, and easier management.
So how do we apply the same microservices design principles to data? The answer for the CPG industry (and other industries) is a data mesh.
Data mesh is a relatively recent architectural design that addresses the drawbacks of the monolithic data lake architecture and provides benefits similar to microservices in software design. In a data mesh, the data itself is the product, and it is backed by a domain-agnostic, self-service data infrastructure. A data mesh breaks the monolithic nature of traditional data lakes in the following ways:
- Data as a product – In a typical data lake, the data lake and data pipelines are the product. In a data mesh, the data and the domain and producer expertise that gathers and publishes the data, are the product.
- Decentralized ownership – Unlike data lakes that are centrally managed by IT, a data mesh has decentralized ownership. The different business domains (data producers) are responsible for curating, validating, publishing, maintaining, and managing the lifecycle of the data they own.
- Granular, scalable access control – Because data is owned by producers in a data mesh, they specify access, governance, and retention policies and any custom access policies based on data granularity. This eliminates the centralized access control bottleneck of data lakes by pushing responsibility and access control policies to the data owners.
- Scalable data discovery – A data mesh allows consumers to discover, identify, and subscribe to data based on domain, granularity, quality, frequency, and so on. This allows scalable consumer access and discovery and removes the dependence on a centralized team.
When producers publish data in a data mesh, they create an immutable data contract with these properties:
- Data type
- Physical schema
- Business characteristics
- Delivery frequency
- Data quality assertion
- Lifecycle policy
The data contract is a mechanism that ensures data is discoverable across the enterprise. The contract properties are associated with the data throughout its lifecycle, and data consumers can discover and subscribe to specific data contract attributes.
In a mesh architecture, data can be stored locally where it is produced. The central platform team manages security, ensures contracts are enforced, and provides tooling and automation. Data producers and consumers have access and visibility into all the data across the enterprise and can communicate between each other.

Data Mesh Reference Architecture and Usages for CPG
Here is an example of a typical data mesh implementation:
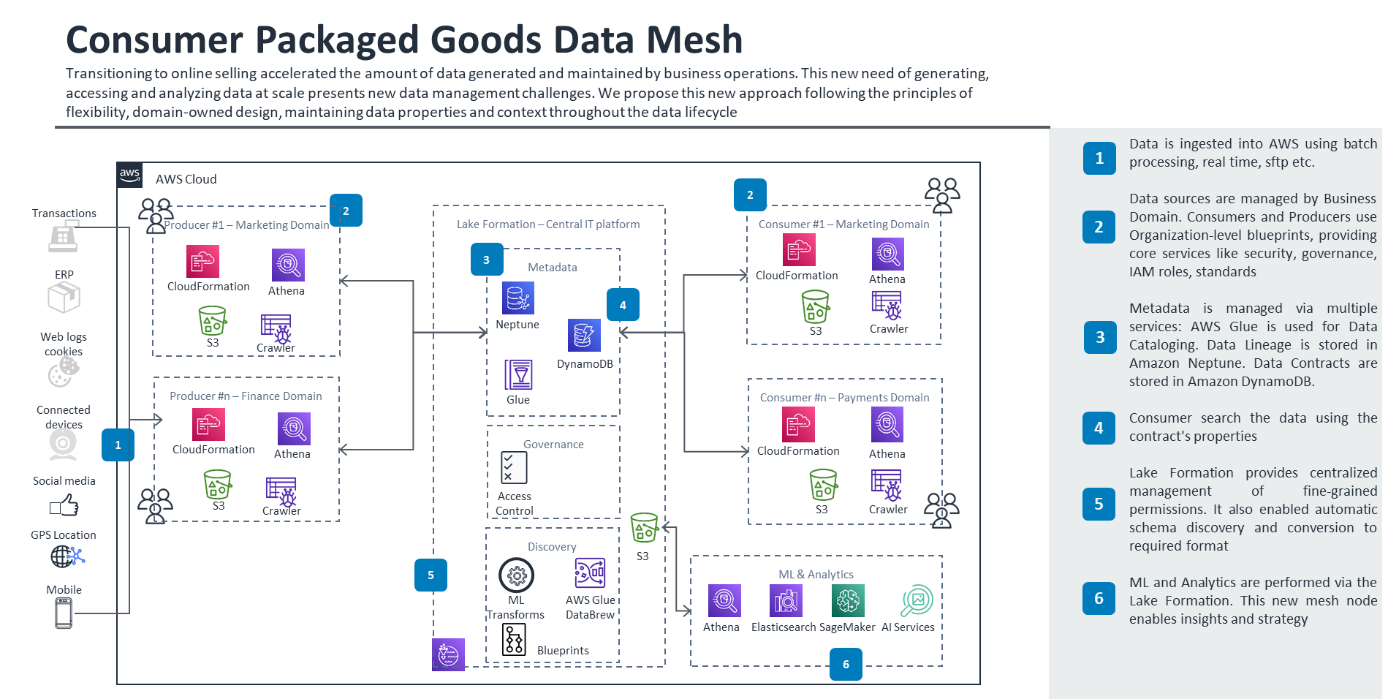
This design uses a pub/sub model. Although the solution uses AWS Lake Formation, which simplifies the work of creating a data lake, you need to manually define data sources, access, and security policies. You can use AWS Glue to discover data in the data catalog and you can discover metadata by using the properties defined in the contract.
Manage Separate Microservices Datasets with Data Mesh
In recent years, CPGs have invested heavily to modernize online infrastructure with microservices and container architectures. In this new design pattern, each microservice creates separate datasets (search, checkout, ordering, products, and so on) and the amount of new disparate data multiplies exponentially. Each unique data stream is owned by a different data producer and has different quality, governance, and lifecycle properties. Producers can configure data streams to upload into the data platform in real time or batch. This microservice design is a natural fit to the data mesh concept implementation pattern.
For more information about microservices in the CPG industry, be sure to read Danny Yin’s blog post, Success Strategies for Moving to a Microservice Architecture in CPG.
Appoint a Data Steward as the Data Point Person in a CPG
To ensure the data mesh architecture is scalable, organizations typically appoint a data steward, a go-to person who has deep knowledge about how producers generate data, the contract properties of the data itself, user access controls, data cleanliness, and expected consumer usage patterns. It’s the data steward’s job to ensure the contract integrity of the data throughout its lifecycle and to help manage any contract modifications.
Mine Restricted CPG Data in a Data Clean Room
In this emerging use case, a clean room contains raw data, such as PII or POS transaction data, that might by subject to privacy restrictions. In the clean room, data consumers can run aggregated queries with sufficient anonymization. Consumers can also join the anonymized data with nonrestricted data and analyze the information, while adhering to privacy requirements. A data mesh architecture natively supports clean room requirements by enforcing the data’s contract restrictions.
As countries adopt strict data privacy rules, such as OECD guidelines or GDPR in Europe, the rules governing how data is maintained, protected, used, and disposed of become more complex. A data mesh architecture can properly segregate data, enforce security policies, and grant access to data. The data-first design and granular access control of a data mesh provides a native mechanism to support data privacy requirements, without requiring costly enterprise-wide data projects.
Collaborate with CPG-Related Vendors with a Data Mesh
Many CPGs are attempting to optimize operations across third-party providers, like supply chain and logistics vendors who deliver raw materials and finished goods. A data mesh is designed from the ground up to natively support collaborations between CPGs and vendors. Internal and external data producers and consumers can freely exchange data through the agreed-upon contracts, and data immutability provides the integrity for a multi-vendor system to operate efficiently.
Conclusion
A data mesh architecture is the modern approach to monolithic data lakes and data warehouses, allowing CPGs to manage data at scale. Ask how AWS can support your data transformation. Contact your AWS account team today to get started or visit our Consumer Packaged Goods page to learn more.
Reference and resource for more information: How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh.