Amazon Web Services ブログ
AWS Step Functions と AWS Glue を使用して Amazon DynamoDB テーブルを Amazon S3 にエクスポートする方法
従来の AWS のやり方で、AWS Glue チームが DynamoDB テーブルからネイティブに読み取る AWS Glue クローラおよび AWS Glue ETL ジョブの機能をリリースしたときは、AWS ビッグデータブログで Goodreads はどのように Amazon DynamoDB テーブルを Amazon S3 にオフロードし、Amazon Athena を使用してクエリを実行するのかを公開してから一週間も経っていませんでした。おかげで私はかなりわくわくしていました。コードがより少ないということは、バグもより少ないことを意味します。元のアーキテクチャは少なくとも 18 か月前からあり、作業を少し加えると大幅に簡素化できます。
データパイプラインのリファクタリング
前回のブログ投稿で概説した AWS Data Pipeline アーキテクチャは、現在まだ 2 年が経っていません。致命的な開発者エラーが発生した場合に Amazon DynamoDB データを Amazon S3 にバックアップする方法としてデータパイプラインを使用しました。ただし、DynamoDB のポイントインタイムリカバリでは、より優れたネイティブの災害復旧メカニズムを備えています。さらに、データパイプラインでは、一時的であってもクラスターに関連付けられた操作を保持しています。クラスターで Amazon EMR の最新リリースに対応して、未解決のバグを軽減することが共通の課題です。もう 1 つの課題は、DynamoDB テーブルごとに EMR クラスターをスピンアップする際の非効率性です。
私は一歩後退して、次の反復で必要な機能を一覧表示することにしました。
- EMR の代わりに AWS Glue を使用してテーブルをエクスポートします。
- AWS Glue は、基となるインフラストラクチャについて心配することのない、サーバーレスの ETL 環境を提供します。これにより、EMR リリースタグに追いつくなどの運用タスクを最小限に抑えられます。
- AWS Glue や Amazon Athena などのサービス間で機能するワークフローソリューションを使用します。
- 最初の反復では、ワークフローがさまざまなサービスに分散されました。頭の中に全体のパイプラインを描いていない限り、パイプラインの進歩方法に対する鳥瞰図を得ることは困難でした。
- 異なる形式を選択する機能です。
- データエンジニアリングに関しては、私は Apache Parquet を好んで使用します。しかし、お客様は違う形式を好まれるかもしれません。
- エクスポートしたデータを Athena に追加します。
- データのクエリが簡単になるほど、データが使用される可能性が高くなります。
アーキテクチャの概要
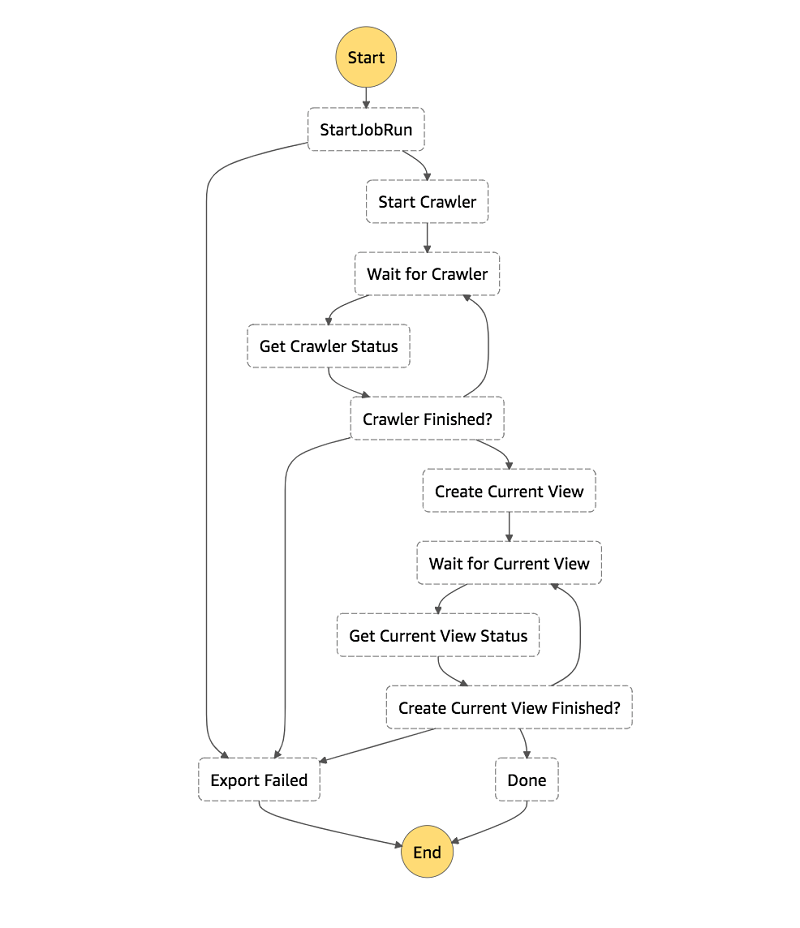
高レベルでのアーキテクチャは、次の通りです。
- ワークフローエンジンとして AWS Step Functions を使用しています。
- 各ステップは、組み込みの Step Functions 状態、サービス統合、または単純な Python AWS Lambda のいずれかに関するものです。たとえば、ドキュメントで説明されているように、GlueStartJobRun は同期的なジョブ実行サービス統合を使用しています。
- パイプライン全体を視覚的に表したものです。
- すぐに新しい開発者を採用することができます。
- Amazon CloudWatch Events のイベント開始が無効になっています。次のものを含む JSON ペイロードを使用して Step Functions ステートマシンをトリガーします。
- AWS Glue のジョブ名
- エクスポート先
- DynamoDB テーブル名
- 希望する読み取り率
- AWS Glue クローラ名
- AWS Glue は、お望みの形式の DynamoDB テーブルを snapshots_your_table_name として S3 にエクスポートします。データは snapshot_timestamp によって分割されます。
- AWS Glue クローラは、AWS Glue Data Catalog でデータのスキーマとパーティションを追加または更新します。
- 最後に、最新のエクスポートスナップショットからのデータのみを保持する Athena ビューを作成します。
簡単な AWS Glue ETL ジョブ
私が作成したスクリプトでは、テーブル名、読み取りスループット、出力、および形式に対する AWS Glue ETL ジョブ引数を受け入れます。AWS Glue はバックグラウンドで DynamoDB テーブルをスキャンします。DynamoDB のドキュメントで説明されているように、どれほど属性がスパースであっても、AWS Glue はトップレベルの属性がすべてスキーマに含まれるようにします。
ここではそれほど多くはありません。接続タイプ dynamodb の DynamicFrameReader を作成し、テーブル名と必要な最大読み取りスループット消費量を渡します。指定された形式で S3 にテーブルを書き込む DynamicFrameWriter にデータフレームを渡します。
Athena ビュー
私のチームを含め Amazon のほとんどのチームは、複数の DynamoDB テーブルを持つアプリケーションを所有しています。現在のアプリケーションでは 5 つのプライマリテーブルを使用しています。理想としては、エクスポートワークフローの最後に、テーブルの一貫したビューにわたって単純で明白なクエリを書き込むことができます。ただし、エクスポートされた各テーブルは、テーブルがエクスポートされたときからのタイムスタンプによって分割されます。クエリのすべてのテーブルリファレンスに WHERE snapshot_timestamp = 句を追加する必要があるため、1 つ以上のテーブルに対してクエリを実行するのは非常に面倒です。さらに、それぞれのテーブルがある特定の日に対して異なる snapshot_timestamp 値を持つことがあります。
このエクスポートワークフローの最後のステップでは、WHERE 句を追加する Athena ビューを作成します。これは、エクスポートされた DynamoDB テーブルの妥当なビューのように、DynamoDB エクスポートと対話できることを意味します。
インフラストラクチャの設定
私が作成した AWS CloudFormation スタックは 2 つのスタックに分割されています。共通スタックには共有インフラストラクチャが含まれていますが、AWS リージョンごとに必要なのは 1 つだけです。テーブルスタックでは、指定された AWS リージョンでテーブル形式ごとに 1 つの組み合わせを作成できるように設計されています。これには、DynamoDB テーブルのエクスポートと変換に必要な CloudWatch イベントロジックと AWS Glue コンポーネントが含まれています。
共通スタックの作成
共通スタックにはインフラストラクチャの大部分が含まれています。これには、非同期ジョブの状態をトリガーおよび確認するための Step Functions ステートマシンおよび Lambda 関数が含まれます。また、エクスポートスタックが使用する IAM ロール、およびエクスポートを保存するための S3 バケットも含まれます。
共通スタックを作成するには、次の手順に従います。
- [起動スタック] を選択します。
- [AWS CloudFormation がカスタム名で IAM リソースを作成する場合があることを認識しています。] を選択します。
- [Create Stack] を選択します。
テーブルエクスポートスタックの作成
エクスポートする DynamoDB テーブルがない場合は、元のブログ投稿に記載されている手順に従ってください。レビュースタックの操作セクションから始めて、2 つの項目をテーブルに追加するまで続けます。それ以外の場合は、この CloudFormation スタックが、プロビジョニングされたスループットを使用しているお気に入りの DynamoDB テーブルを指すようにしてください。オンデマンドスループットを使用するテーブルは現在サポートされていません。
このアーキテクチャの多くは共有可能なので、テーブルエクスポートスタックにあるものはそれほど多くはありません。このスタックは、必要なすべてのメタデータを含む JSON ペイロードを使用して、Step Functions ステートマシンをトリガーするために使用される CloudWatch イベントを定義します。さらに、テーブルをエクスポートする AWS Glue ETL ジョブと、AWS Glue Data Catalog のメタデータを更新する AWS Glue クローラも含まれています。
技術的には、AWS Glue ETL ジョブは既にパラメータ化されているため、共通スタックで定義できます。ただし、AWS Glue ジョブの同時実行に対するデフォルト制限は 3 つまでです。制限は弱い方ですが、このアーキテクチャーでは制限を増やす前に最大 25 個のテーブルをエクスポートする余裕があります。
テーブルエクスポートスタックを作成するには、次の手順に従います。
- [起動スタック] を選択します。
- リストから出力形式を選択してください。利用可能な形式はすべて Athena によってネイティブにサポートされています。
- DynamoDB テーブル名を入力してください。
- テーブルで現在プロビジョニングされているスループットからジョブが消費する、読み取り容量単位 (RCU) の割合を入力します。この割合は、0.1 から 1.0 までの浮動小数点数として表れます。デフォルトは 0.25 (25%) です。
たとえば、テーブルの RCU が 100 に設定されていて、デフォルトの 0.25 (25%) を使用しているとします。その後、AWS Glue ジョブは実行中に 25 RCU を消費します。
- [作成] を選択する。
ステートマシンの実行開始
この仕組みを示すために、CloudWatch イベントが Step Functions に渡す JSON ペイロードを渡すことによって、DynamoDB エクスポートステートマシンを手動で実行します。
CloudWatch Events からの JSON ペイロードの取得
JSON ペイロードを取得するには、次の手順に従います。
- AWS マネジメントコンソールで CloudWatch を開きます。
- [Events] の左下にある列で、[ルール] を選択します。

- リストからお使いのルールを選択してください。AWSBigDataBlog- というプレフィックスが付けられています。
- [Actions] では、[Edit] を選択します。

- ターゲットの入力設定セクションから JSON ペイロードをコピーします。

- 編集モードを終了するには、[キャンセル] を選択します。
ステートマシンの実行開始
ステートマシンの実行を開始するには、次の手順に従います。
- コンソールで Step Functions を開きます。
- DynamoDBExportAndAthenaLoad ステートマシンを選択します。

- [実行開始] を選択します。

- JSON ペイロードを入力
 に貼り付けます。
に貼り付けます。 - [実行開始] を選択します。
実行方法にはいくつかがあります。ステップが開始および終了すると、実行イベント履歴リストにエントリが追加されます。これは、デバッグが必要な場合に備えて、どのステート (Lambda speak のイベント) が各ステップに渡されるかを確認するのに最適な方法です。
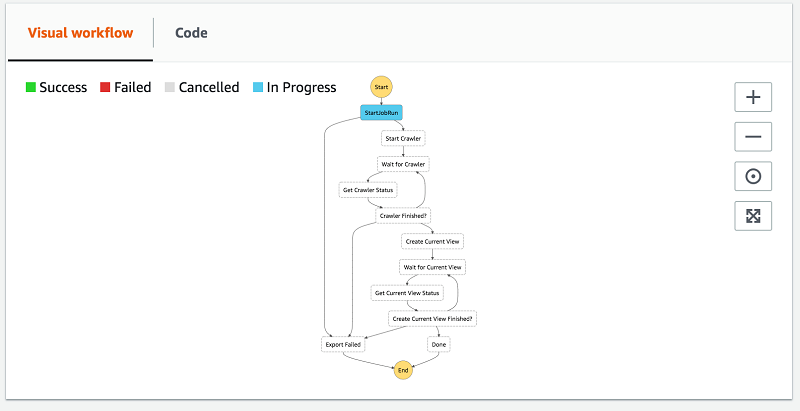
また、ビジュアルワークフローを拡張することもできます。ワークフローの進行方法を確認できる非常に高度なビューです。
ワークフローが完了すると、AWS Glue Data Catalog の dynamodb_exports データベースの下に 2 つの新しいテーブルが表示されます。DynamoDB スナップショットテーブル名の先頭に snapshots_ が付きます。スキーマは AWS Glue Data Catalog 用の形式で作成されています (小文字とハイフンはアンダースコアに変換)。AWS Glue Data Catalog 用の形式で作成された同じテーブル名のビューテーブルもありますが、snapshots_ プレフィックスは付きません。
データのクエリ
テーブルの最新のスナップショットの個別ビューテーブルがいかに便利かを示すために、前回のブログ投稿のレビューテーブルを使用します。テーブルには 2 つの項目があります。エクスポートワークフローも 2 回実行しました。テーブルをプレビューするとわかるように、合計 4 つの項目があります。これは、各スナップショットに項目が 2 つずつ含まれているためです。
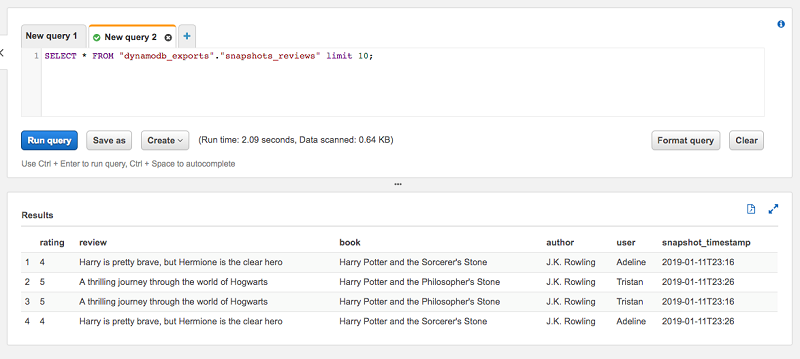
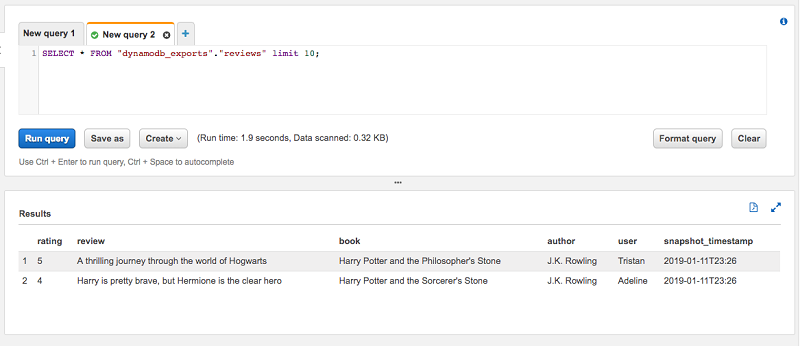
これらの項目のうち、最新の snapshot_timestamp は 2019-01-11T23:26 です。ビューテーブルのレビューに対して同じプレビュークエリを実行すると、2 つの項目しかないことがわかります。これは予想どおりの結果です。ビューが where snapshot_timestamp=… 句を指定するので、別途の処理を行う必要はありません。
まとめ
この記事では、AWS Glue の DynamoDB 統合と AWS Step Functions を使用して、DynamoDB テーブルを Parquet の S3 にエクスポートするワークフローを作成する方法について紹介しました。また、各テーブルの最新スナップショット用に Athena ビューを作成する方法も示しています。これにより、DynamoDB テーブルエクスポートの一貫したビューが得られます。
著者について
 Joe Feeney は、Amazon Go のソフトウェアエンジニアです。彼は秘密裏に何んらかの作業を行っていて、かなり満足しています。また、彼はマリオカートに真剣になりすぎて家族を困らせるのを楽しんでいます。
Joe Feeney は、Amazon Go のソフトウェアエンジニアです。彼は秘密裏に何んらかの作業を行っていて、かなり満足しています。また、彼はマリオカートに真剣になりすぎて家族を困らせるのを楽しんでいます。