Amazon Web Services ブログ
Oracle から PostgreSQL へ移行する際に、よく直面する課題を解決する方法
企業は年々データが急激に増加するのを目の当たりにしています。データベースとハードウェアインフラストラクチャをスケーリングし続けることは、ますます困難になっています。ワークロードが非リレーショナルデータストアに適していない場合に、基盤となるインフラストラクチャの管理に膨大な費用を費やすことなく、スケーリングの課題をどのように克服したらいいでしょうか?
Amazon RDS for PostgreSQL と Amazon Aurora with PostgreSQL により、コスト効率の高い方法で PostgreSQL クラウドのデプロイを簡単にセットアップ、運用、拡張することができます。昨年、私たちは (数百 GB から数 TB に及ぶ) 100 を超える Oracle データベースを Amazon Aurora PostgreSQL と Amazon RDS for PostgreSQL に移行しました。
この記事では、移行中に持ち上がった最も一般的な問題のいくつかについて説明します。皆さんは AWS Database Migration Service (AWS DMS) を使用して、あるデータベースから別のデータベースにデータを移動させた経験があることでしょう。私も AWS Schema Conversion Tool (AWS SCT) をかなり使い込みました。手始めに、データ抽出プロセスで直面する可能性のある問題を取り上げます。次に、データの移行中に起こる問題について取り上げます。最後に、移行後に PostgreSQL で観察するパフォーマンスの問題について説明します。
抽出フェーズの問題
このフェーズで一般的に直面する問題は、大きなテーブルのデータ抽出が遅くなり、ソース DB で ORA-01555 エラー (スナップショットが古すぎます) が発生することです。経験上、500 GB を超えるテーブルの場合にその問題が頻繁に発生するようです。相対的にはそうですが、環境に依存するところもあります。次のセクションでは、ORA-01555 のエラーと、抽出プロセスを高速化するためにエラーを回避する方法について説明します。
ソースからデータを抽出しているときに発生する ORA-01555
問題の説明 – Oracle から大きなテーブルまたはテーブルパーティションを移行する場合、抽出クエリの実行時間が長くなるため、クエリが ORA-01555 エラーで失敗することがあります。Oracle をよく使われている方は、過去にこのエラーが発生したのを見たことがあるだろうと思われます。クエリは、作成できないブロックの古いイメージを要求しています。そのイメージの作成に必要なアンドゥ情報はすでに上書きされています。ターゲットデータベースのスループットが制限されていると、ORA-01555 エラーが発生して抽出による全体的な移行時間が増加する可能性があります。
ソリューション – この問題を解決するには他にもアプローチがあります。考えられるアプローチは次のいずれかです。
- ソース DB 内のクエリを最適化して、抽出クエリのランタイムを削減する。
- ソースが、抽出クエリランタイムよりも長いデータの古いイメージを保持していることを確認する。
このエラーを回避する方法はいくつかあります。
- 抽出クエリのチューニング: パフォーマンスの向上により、ORA-01555 エラーが発生する可能性が減ります。したがって、抽出クエリがより速く実行されるように、ソースに適切なインデックスがあることを確認してください。場合によっては、移行のために固有の新しいインデックスを作成できます。移動させるデータ量を考慮してください。すべてのデータ (テーブルのすべての行) を転送する必要がありますか? 必要ない場合は、移行を開始する前に DMS を使用してデータをフィルタリングするか、ソース内のデータをパージする選択肢もあります。これは、不要なデータの移行に時間を費やさないようにするための重要なステップです。
- 抽出クエリを改善した後も ORA-01555 エラーが発生している場合、他にとれる一般的な解決策はソース DB のアンドゥ保持サイズを増やすことです。たとえば、データベース内で最長の抽出クエリが 1 時間実行されている場合、アンドゥの保持を 1 時間以上に設定すると、このエラーを回避できるかもしれません。データの変更率が高い場合には、アンドゥ保持期間が切れる前に、期限切れになっていないアンドゥブロックが上書きされてしまうこともあります。このような場合、アンドゥの保持サイズを増やすことは役に立ちません。また、抽出が非常に長い時間かかる場合、アンドゥ保持サイズを増やしても上手くいかない可能性があります。アンドゥ保持サイズを増やすとパフォーマンスに影響が出る可能性があり、開発環境でテストした後で徐々に増やす必要があることを念頭に置いておいてください。
- 次のステップは、クエリを高速化するための手段は他にないかを調べることです。低速抽出の原因がレプリケーションインスタンスからの I/Oが制限されていること である場合は、より大きいレプリケーションインスタンスを使用すると役立ちます。より多くのディスクストレージを持つより大きいレプリケーションインスタンスは、I/O 帯域幅が増加します。これにより、移行が高速化され、ソースの抽出時間が短縮され、ORA-01555 エラーが発生する可能性が減少します。
- source-filter オプションを検討するのも一つの手です。テーブルサイズに応じて、異なるレプリケーションインスタンスの異なるフィルタを使用してタスクを実行できます。これにより、負荷をより多くの計算能力で分散して処理し、抽出を高速化して、ORA-01555 エラーの発生を回避するのに役立ちます。
- そのような高いデータ変更率で、上記のソリューションのいずれもがご自身のユースケースで機能していない場合は、Active DataGuard (読み取り専用の物理スタンバイ) を作成してレプリケーションから取り外します。レプリケーションが停止し、データの静的コピーを取得したら、スタンバイデータベースから全ロード処理を開始します。開始タイムスタンプは、後でプライマリデータベースから変更データキャプチャ (CDC) を開始するために使用できるので、書き留めておいてください。この方法を使用すると、静的データコピーに対して全ロードを実行しているため、ORA-01555 エラーに陥る可能性が最小限に抑えられます。
要するに、ご自身のユースケースに最適なソリューションを見つけることです。たとえば、テーブルを移行していて、90〜95% のデータをコピーした後に全ロードが失敗した場合、この問題を修正するには、アンドゥ保持サイズを増やすことが適切であるかもしれません。ただし、アンドゥ保持サイズがある程度あるときに、20% のデータをコピーした後に全ロードが失敗した場合、データパージ、ソースフィルタ、またはバイスタンダーなどの他の選択肢を検討してみてください。
移行段階の問題
これは、スキーマ変換とデータ移行が組み合わされた最も難しい段階です。データ型変換の問題、文字セットの不一致問題、ラージオブジェクトの移行などの問題に対処する必要があります。以下、最も一般的な問題のいくつかを取り上げます。
データ型変換の問題
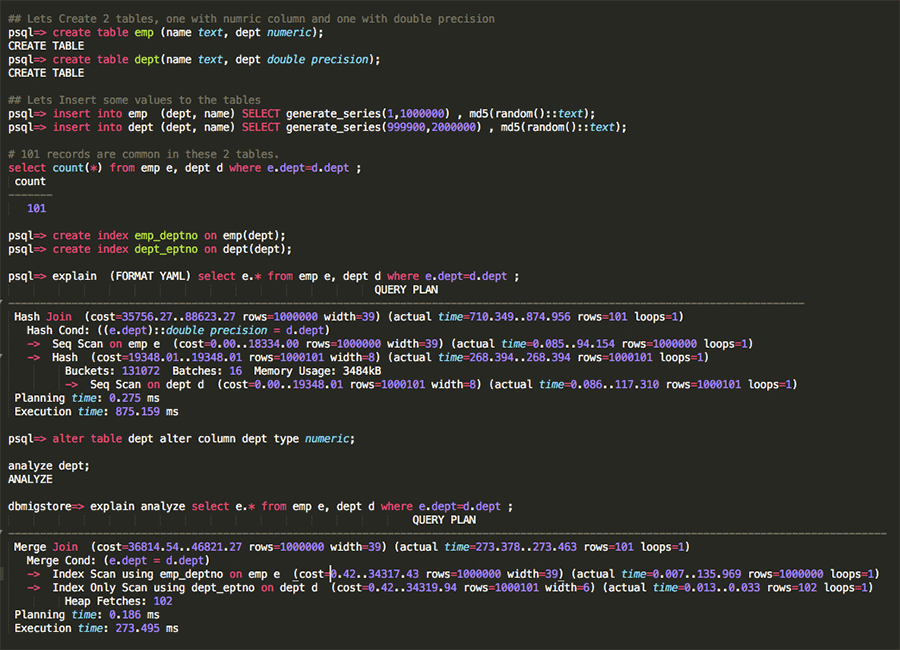
問題の説明 – スキーマ変換時に、SCT は number データ型 (精度なし) を PostgreSQL の double precision データ型に変換し、number データ型 (精度あり) は numeric (p) として残します。これらの列に対して結合を実行すると、PostgreSQL オプティマイザーはこれらの列のインデックスを活用できないため、パフォーマンスが低下します。
ソリューション – この問題を説明するために、PostgreSQL に 2 つのテーブルを作成しました。1 つは numeric 列、もう 1 つは double precision です。これらの 2 つの列にもインデックスを追加しました。下記の実行計画からわかるように、オプティマイザーは、テーブルが numeric 列と double precision 列で結合されている場合に、Seq Scan を選択します。dept テーブルで列のデータ型を double precision から numeric に変更すると、オプティマイザーは適切な実行計画、つまり Index Scan を選択します。移行中に列の精度に注意を払い、number 列 (精度なし) を numeric に上書きするようにしてください。
これに加えて、PostgreSQL で正しい数値データ型を選択することが非常に重要です。本書の後半の point#4 でそれについて省察します。
PostgreSQL の空白文字と null
問題の説明 – Oracleとは異なり、空文字は PostgreSQL では null とはされません。Oracle は自動的に空文字を null 値に変換しますが、PostgreSQL では null 値に変換しません。アプリケーションで空文字を挿入し、Oracle で null 値として扱う場合は、PostgreSQL に移行する前に、アプリケーションがデータを挿入または抽出する方法を変更します。ユースケースでこれをよりよく理解できます。
作業 – Oracle と PostgreSQL が null 値と空文字をどのように扱うかを並べて比較しました。下の例では、Oracle、PostgreSQL で全く同じテーブルを作成しています。両方のデータベースに、名前列が null の行と名前列が空文字を持つ行を挿入しています。

見てわかるとおり、null は両方のデータベースで同じものとして扱われます。ただし、空文字を挿入すると、Oracle ではこれを null として格納します。そして述語「where is null 」を使用してクエリを実行すると、両方の値が表示されます。一方、同じ述語「where name is null」を使用してクエリを実行しても、PostgreSQL では空文字を含む行が表示されません。PostgreSQL で行を見つけるには、「=」演算子を使ってクエリを実行し、述語で空文字を探します。
結論 – 空文字を挿入し、空文字を null 値として扱う場合は、PostgreSQL でアプリケーションの結果が異なります。PostgreSQL に移行する前に、すべての null 値 (空文字ではなく) に null を追加するか、すべての選択クエリを変更して null とともに空文字に「like」演算子を含めるかを確認して、アプリケーションが PostgreSQL にデータを挿入する方法を変更する必要があります。したがって、Oracle の null 動作をレプリケートするために、クエリは [select * from emp where name is null or name like ”] のような感じになります。
複合一意インデックスの null 動作
PostgreSQL が Oracle と異なり null をどのように処理するかに基づいてクエリやアプリケーション設計を変更する必要がある点は、強調しきれないぐらい重要です。Oracle から移行する場合は、null の問題が発生する可能性があります。AWS のアプリケーションの多くは、Oracle が null を処理する方法に従って null を処理するように設計されています。PostgreSQL に移行する他の DB プラットフォームについても同じことがいえるでしょう。
複合一意インデックスがあるときに、それらの列の 1 つに null を挿入する場合に何が起こるかを調べるために、さらに詳しく見ていきます。ここでも、Oracle と PostgreSQL の動作を並べて比較しています。
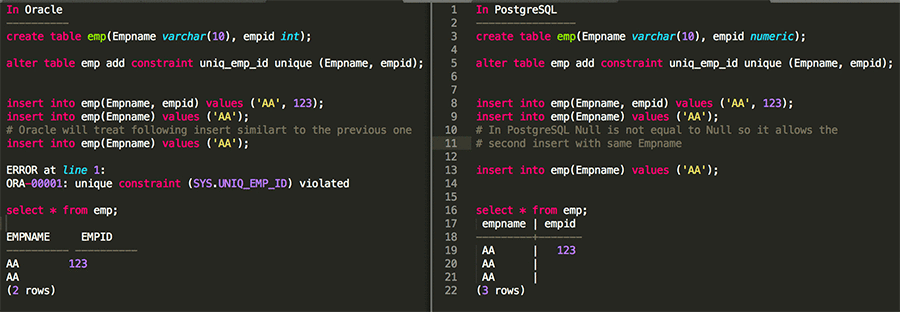
上のユースケースからわかるように、Empname、empid 列に複合一意制約を追加しました。ここで、最初の列 Empname の重複値を empid が null の「AA」として挿入しようとすると、Oracle は例外 (一意制約違反) をスローします。しかし、PostgreSQL では 2 つの null が等しくないので、2 番目の列 (empid) が異なると考え、重複した「AA」値を許容します。PostgreSQL では、null 値は未知の値を表し、2 つの未知の値が等しいかどうかを判断することはできません。
Oracle の動作を複製する方法の 1 つは、PostgreSQL で部分インデックスを使用することです。部分インデックスの使用法を示すスニペットを次に示します。

また、null 問題を扱い、アプリケーションコードが null 比較で「=」演算子を用いている場合は、PostgreSQL のマニュアルでパラメータ Transform_ null _equals を読むことをお勧めします。それは永続的な修正ではなく、一時的な回避策としてのみ使用してください。それをそのままにしておくのは好ましくありません。
PostgreSQL の numeric データ型の選択 (numeric と BIGINT の比較)
これは、Oracleから PostgreSQL への移行中に私が見たよくある間違いです。デフォルトでは、多くの DBA は、Oracle のすべての number 列を変換するために、smallint、integer、bigint より PostgreSQL の numeric データ型を選択します。これには多くの理由がありますが、移行中にエラーが発生するものにのみ注意を払います。PostgreSQL のドキュメントには、必要な範囲でのみ触れます。たぶん私は特定の RDBMS で作業することに慣れているため、その RDBMS で実行できるオプションについて考える傾向があるかもしれません。
私の疑問は、Oracle の number と PostgreSQL の numeric は同じか、という点にあります。 両者とも数値を保持しているため同じようなものかもしれませんが、大きな違いが 1 点あります。Oracle では、最大の数値データ型は 38 桁保持できますが、PostgreSQL では 131,072 桁保持できるという点です。PostgreSQL には、smallint、integer、bigint など、いくつかの数値データ型が用意されています。範囲、パフォーマンス、およびストレージの最適なバランスを見つけて、最適な数値データ型を選択します。
bigint や interger の代わりに numeric を選択すると、パフォーマンスが犠牲になってしまいます。それは並べて比較することで見つけることができます。
次のスニペットでは、2 つの異なる PostgreSQL データ型を並べて比較しています。実際には、bigint、integer、numeric という 3 つのデータ型を比較しました。integer は bigint と同様に動作していたので、この図では削除しました。
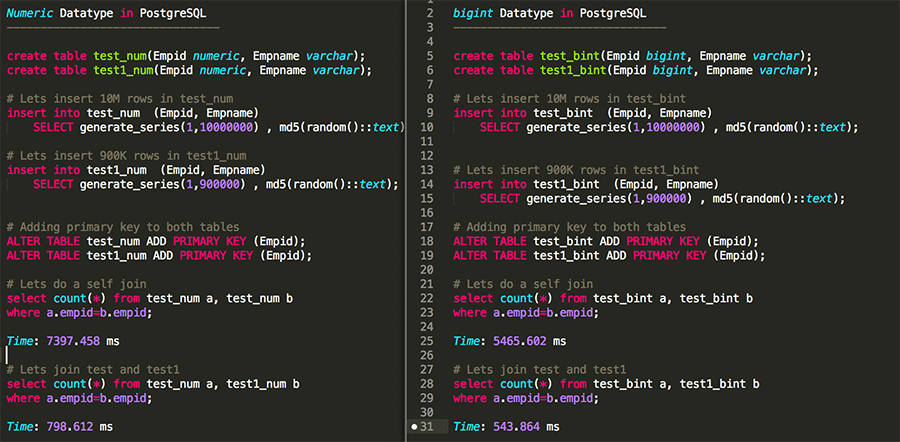
テストを見てわかるように、numeric の代わりに bigint を使用すると、小さなデータセットでも 30〜35% の大幅なパフォーマンスの向上を実現できます。
PostgreSQL の SEQUENCE キャッシュ動作
問題の説明 – PostgreSQL のシーケンス値はエンジンプロセスによってキャッシュされ、シーケンスのキャッシュ値が 1 より大きく、複数のセッションで同時に使用すると予期しない結果になることがあります。
作業 – 問題を説明するために、Oracle と PostgreSQL でシーケンス値がどのように生成されるかを比較します。次のスニペットでは、シーケンスが 100 から始まり、キャッシュサイズは 20 です。セッション A とセッション B は、同じシーケンスを使用して Oracle と PostgreSQL で次の値を生成しています。

Oracle (スニペットの左半分) では、セッション A とセッション B がデータベースオブジェクトにアクセスしてシーケンスの次の値を生成するため、異なるセッションによって生成されたシーケンス番号が順番になります。
PostgreSQL では、セッション A は 100〜120 の値をキャッシュし、セッション B は 121〜140 の値をキャッシュします。したがって、セッション B は 120 以上の値を生成し、セッション A は 100〜119 の値を生成し続けます。
PostgreSQL のセッションベースのキャッシュを見てわかるように、シーケンス値は順不同であり、両方のセッションが同時に同じテーブルに挿入されている場合、セッション B の値 121 をセッション A の値 102 の前に挿入できます。これは、アプリケーションはシーケンスから生成される値の順序に依存している場合に問題を引き起こします。
ソリューション – アプリケーションにこのような依存性がある場合は、アプリケーション設計を変更するか、すべてのシーケンスのキャッシュサイズを 1 にします。
最終切り替えと移行後の問題
PostgreSQL への最終切り替え前の問題の 1 つは、読み込みを PostgreSQL に切り替えた後にテキスト検索中に発生する可能性があるパフォーマンスへの影響をどう管理するか、という点です。このセクションでは、この問題について詳述します。
PostgreSQL でのプレーンテキスト検索のパフォーマンス上の問題
問題の説明 – PostgreSQL データベースではフルテキスト検索が他のいくつかの RDBMS と比較して全体的に遅く、通常の Btree インデックスを使ってもテキスト検索に役立たない可能性があります。たとえば、「like」演算子を使用して実行している SQL は、Oracle でのインデックススキャンと違い、エンジンクエリオプティマイザーがフルテーブルスキャン (seq スキャン) を実行するため、速度が大幅に低下する可能性があります。
ソリューション – PostgreSQL でテキスト検索を高速化するために、汎用転置 (GIN) インデックスと汎用検索ツリー (GiST) インデックスを使用できます。GIN インデックスは、フルテキスト検索を行う必要がある場合に役立ちます。GIN インデックスまたは GiST インデックスを使用するには、pg_trgm 拡張機能をインストールします。拡張機能を追加すると、GIN インデックスをすばやく作成できます。この記事では GIN インデックスのみを扱っていますが、GIN インデックスと GiST インデックスの長所と短所を踏まえ、環境内で実装することをお勧めします。要約すると、GIN は静的データに適していて、検索は高速ですが更新は遅く、GiST は動的データに適していて、更新は高速ですが検索は遅くなります。
作業 – 問題を説明するために、従業員テーブル (emp) を作成します。ここではランダムな md5 を使用してテーブルにデータを入力し、フルテキスト検索に like 演算子を使用しています。以下に示すように、オプティマイザーはすべての行をフィルタリングし、Seq Scan を使用します。自然の流れとして、インデックスはありません。
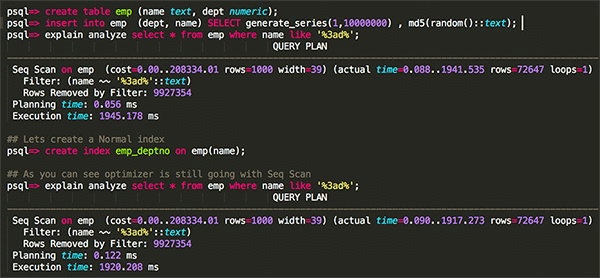
次のステップでは、Btree インデックスを追加して何が変わるかを調べます。
少し待ってください。オプティマイザーは依然として Index Scan とは対照的な Seq Scan を選択していますね? わずか 10M のレコードと小さな行の長さで、1 回の実行で約 1900 ミリ秒もかかっています。実際の運用環境では、ログをスキャンしてテキストの一致を調べる必要がある場合、この操作にはかなりの時間がかかり、たいていのビジネスユースケースでは受け入れられないでしょう。では、どのようにそのようなクエリを高速化したらいいでしょうか?
GIN (汎用転置) インデックスを見てください。GIN インデックスの主な目的は、PostgreSQL で非常にスケーラブルなテキスト検索をサポートすることです。そのため、テキストログファイル内の単語やパターンを検索する場合、GIN インデックスは検索を高速化するのに役立ちます。

以下に示すように、GIN インデックスを作成した後、オプティマイザーは Index Scan を使用して最適なプランを選択します。クエリの全体的な実行時間は、〜1900 ミリ秒から ~83 ミリ秒に減少しました。
この場合、検索に 3 文字 (「%3ad%」) 使用しています。検索条件で文字の数を (特定の数まで) 増やすと、パフォーマンスが向上します。検索条件に 6 文字 (「3adfgk」) を使用するとどうなるか、予想がつきますね。

上記からわかるように、この場合、クエリはより高速に実行されます (0.129 ミリ秒)。適切な検索条件を追加すると、優れたパフォーマンスが得られる可能性があることに留意してください。
ほとんどの場合、検索条件の文字数が多いほど実行時間が短くなりますが、検索条件に 3 文字以下の文字を使用するとどうなるか疑問に思ったでしょうか? ここに、その答えがあります。

上記のクエリは全くインデックスを使用していませんが、なぜでしょうか? このケースでオプティマイザーがインデックスを選択しなかった理由を理解するため、まず GIN インデックスの作成中に使用された gin_trgm_ops 演算子について見ていきたいと思います。
ここでは trigram インデックスを作成するために、gin_trgm_ops 演算子クラスが使用されています。trigram は、基本的に 3 文字のシーケンスに分解されたテキストです。したがって、オプティマイザーがインデックスを使用するためには、少なくとも 1 つの trigram が必要です。検索条件 (%3a%) で 2 文字のみを使用すると、trigram が使用できないため trigram インデックスを使用できません。したがって、trigram インデックスを利用するには、少なくとも 3 文字を検索パターンに含めることが重要です。
スペースはトリグラムでもカウントされます。「%a %」(a の後に 2 つのスペース) は trigram であり、オプティマイザーはこの条件に基づいて検索している場合は GIN インデックスを使用します。次のコマンドを実行すると、特定の単語の trigram を簡単に見つけることができます。
GIN インデックスの検索はより高速ですが、その更新速度はより遅くなります。したがって、それを使用する前にワークロードに対して慎重にベンチマークしてください。GIN インデックスは静的な種類の作業負荷に最適です。また、検索パターンが固定されている場合は、通常の Btree インデックスを使用することができます (たとえば、「abc%」など)。固定されていない検索パターン「%abc%」についてのみ、Btree インデックスはその検索パターンに役立たないため、最良の結果を得るには、GIN/GiST インデックスを使用する必要があります。
結論
この記事では、Oracle から RDS PostgreSQL への移行時に直面する可能性がある最も一般的な問題の概要を見てきました。
移行プロセスについてさらに詳しく知りたい方は、「Migrate-your-oracle-database-to-PostgreSQL/」を読むことをお勧めします。また、Oracle から Amazon Aurora に移行するための移行プレイブックもチェックしてみてください。このプレイブックは、移行要件に応じて調整できるステップバイステップの手順について説明していて、役に立ちます。
AWS DMS のベストプラクティスと移行の最新バージョンのレプリケーションインスタンスに従ってください。けれども問題に直面した場合は、問題を緩和し、正しい方向性を示すのにこの記事がお役に立てれば幸いです。ご不明な点がございましたら、コメントをお寄せください。幸運を祈ります!
著者について
 Abhinav Sarin は Amazon の ビッグデータテクノロジーチームのデータベースマネージャーです。彼は、Amazon の内部顧客と協力して、いくつかものサービスをオンプレミスの Oracle から Aurora、RDS PostgreSQL、RDS MySQL データベースへ移行しています。
Abhinav Sarin は Amazon の ビッグデータテクノロジーチームのデータベースマネージャーです。彼は、Amazon の内部顧客と協力して、いくつかものサービスをオンプレミスの Oracle から Aurora、RDS PostgreSQL、RDS MySQL データベースへ移行しています。
原文は How to solve some common challenges faced while migrating from Oracle to PostgreSQL。