Amazon Web Services ブログ
Kubernetes as a platform vs. Kubernetes as an API
はじめに
Kubernetes とは何ですか?私はこの技術に初期から取り組んできましたが、8 年経っても、この問いにハッキリと答えられません。Kubernetes をコンテナオーケストレーターとして定義する人もいますが、その定義は果たして、Kubernetes を正しく表現できていると言えるでしょうか。私はそう思いません。この記事では、Kubernetes について、従来の考え方にとらわれない考え方や、技術の伸びしろを探ってみたいと思います。
Amazon Elastic Kubernetes Service (Amazon EKS) は、お客さまに代わって、Kubernetes クラスターを運用をする AWS のマネージドサービスであり、非常に大規模で幅広いお客様にご愛用いただいております。彼らのようなお客様が、Amazon EKS をどのように活用しているか、またどのように考えているかという価値観はさまざまです。Kubernetes を「プラットフォーム」として考えている人もいれば、AWS サービスを管理するためのファサードと考えている人もいます。
つまり、完全に自分達の中でコントロールするという意見から、完全なマネージドサービスであるという意見まで、幾つもの考え方が存在します。
それでは、これからそれぞれの考え方について詳しく見ていきましょう。そのために、バックエンドのデータベースを持つ簡単なアプリケーションを AWS 上の Kubernetes へデプロイするために使用できるさまざまなモデルを探ります。また、この記事の最後には、表現された概念を着地させ、実践的に実証するためのデモがあります。
Kubernetes がコントロールプレーンとデータプレーンの全てを担う
このモデルでは、広く利用可能な主要な基本的インフラストラクチャ (すなわち、計算、ストレージ、ネットワーク) のみを使用し、その上で動作するあらゆるサービスを Kubernetes というプラットフォーム上に構築することを選択します。これらの利用者は、オープンソースソフトウェア (OSS) の部品をつなぎ合わせて独自にこのプラットフォームを構築しているか、(多かれ少なかれ) ベンダーのソフトウェアを使用して実装しているのです。いずれにせよ、このようなプラットフォームを展開し、維持し、運用するためには、強力なプラットフォームエンジニアリングチームが必要です。次の図は、このモデルの背後にある考え方を捉えたものです。
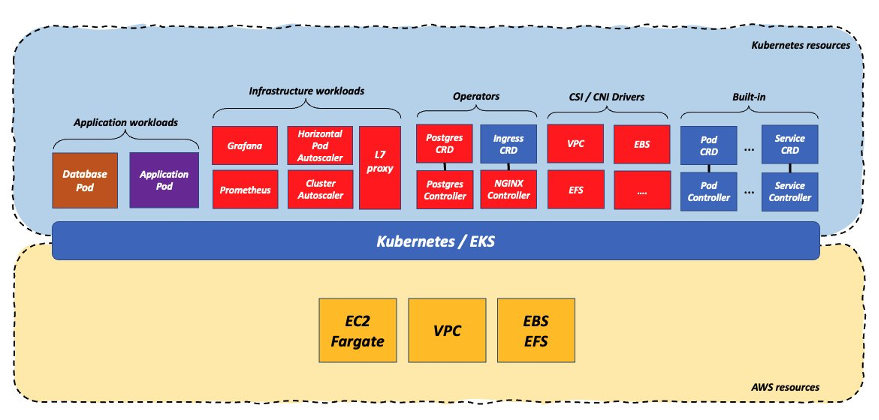
このモデルの利用者は以下を使用します。
- 主要な基本的インフラストラクチャへのインターフェイスとして、Container Network Interface (CNI) と Container Storage Interface (CSI)
- アプリケーションとインフラストラクチャの主要なコンポーネントをサポートする Kubernetes のビルトインオブジェクト (Pod、Deployment など) 。
- オペレーターパターンを使用して構築されたカスタムオブジェクトのコントロールプレーン ( データベース、ロードバランサーなど、特定のワークロードのカスタム展開を自己修復するために使用される Kubernetes カスタムリソース定義 (CRD) と Kubernetes コントローラーの組み合わせ)
注:この図の例は、データベースと相互作用する単純な負荷分散アプリケーションに限定されています。Kubernetes と主要なインフラストラクチャの最も基本的なものの上にすべてのワークロードを構築する全体的なアプローチは、潜在的に、これよりもはるかに複雑な管理になる可能性があります。例えば、Kubeflow のようなより高度なワークロードをクラスターにデプロイすれば、これらのコンポーネントはこの図のようになります。
このシナリオでは、ワークロードは Kubernetes クラスタに偏っており、事実上、ワークロードのデータプレーンとなります。このアプローチの長所は、利用者がインフラストラクチャから大きく切り離されるため、プラットフォーム全体の移植性が向上することです。一方、この方法の短所は、多大な労力を必要とすることです。この作業量は、利用者が構築しようとしているプラットフォームの深さと幅に比例して増大します。
Kubernetes がコントロールプレーンの一部とデータプレーンの一部を担う
先ほどのアプローチは少し極端でした。実際、多くの利用者は手間のかからないクラウドサービスを利用するアプローチを採用していると考えています。これにより、利用者はインフラストラクチャの運用という差別化につながらない重労働の一部を AWS にオフロードし、重要なサービス ( ロードバランサー、データベース、場合によってはキューサービスなど ) の一部についてよりマネージドな体験を得ることができます。この図は、これらの利用者が何をするのかを捉えようとするものです。
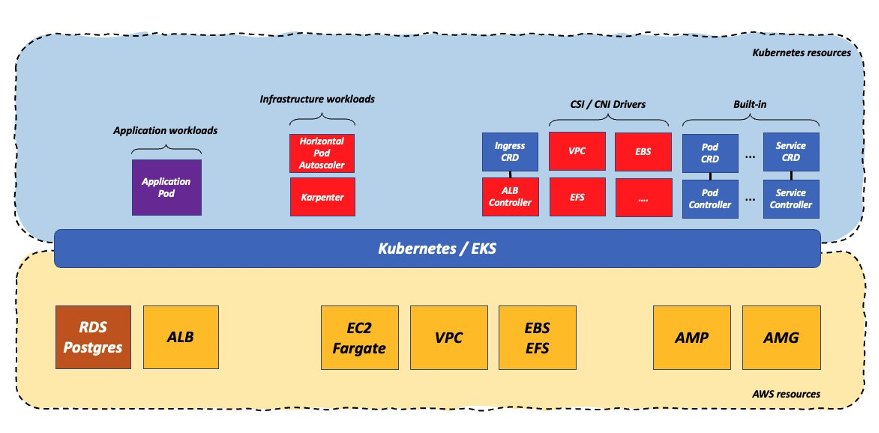
この例では、利用者は Postgres データベースの管理を Amazon Relational Database Service ( Amazon RDS )にオフロードし、データベースインフラの運用負荷を軽減しました ( 以前は Postgres オペレータを利用していました ) 。また、AWS Application Load Balancer (ALB) の利用も決定しており、Kubernetes コントローラは必要ですが、クラスタ上で動作する L7 ロードバランサのデータプレーンを所有・維持する必要性は軽減されます。さらに、一部の利用者は、Prometheus と Grafana の実装もマネージドサービス ( AWS の場合は、Amazon Managed Service for Prometheus と Amazon Managed Grafana ) にオフロードすることを選択するでしょう。
このシナリオでは、ワークロードの重力は Kubernetes クラスターと AWS が管理するクラウドサービスの間に集中します。多くの利用者にとって、この塩梅は、最適な選択肢であり、Kubernetes とオープンソーステクノロジーを標準化しつつ、ビジネス的な差別化につながらない運用作業の一部を AWS にオフロードできます。
広く利用可能なオープンソースの技術 (例:Postgres) を使用することで、利用者は十分な柔軟性を得ることができます。しかし、サーバーレスな運用モデルをフルに活用したい利用者の中には、Amazon DynamoDB、Amazon EventBridge、AWS Step Functions、Amazon SQS などのクラウドサービスを好む場合もあります。
Kubernetes がコントロールプレーンの全てとデータプレーンの一部を担う
上記のモデルでは、利用者がクラスター内のワークロードを管理する方法 (Kubernetes の yaml で記述されたマニフェスト、Helm Chart、GitOps など )と、AWS のリソースを管理する方法 (AWS CloudFormation, Terraform, AWS Cloud Development Kit [Amazon CDK], Pulumi など )がバラバラになっています。AWS リソースをサポートする従来の Infrastructure as Code (IaC)ツールを使って Amazon RDS データベースをデプロイする必要がありますが、一方 Kubernetes 上で動作するアプリケーションは、Kubernetes のメカニズムを使ってデプロイする必要があります。もし、1 つのデプロイメントメカニズムで全てを行うことができたら、しかもそれが、Kubernetes のメカニズムを使って全てのデプロイを行うことができたら素晴らしいと思いませんか?それを、AWS Controllers for Kubernetes ( ACK ) がかなえてくれるのです。
ACK の Web サイトより引用します。”AWS Controllers for Kubernetes ( ACK ) を使用すると、Kubernetes から直接 AWS リソースを定義して使用できます。ACK を使えば、クラスタの外でリソースを定義したり、データベースやメッセージキューのようなサポート機能を提供するサービスをクラスタ内で実行する必要がなく、Kubernetes アプリケーションで AWS が管理するサービスを利用できます」とあります。
そのためには、Kubernetes プラットフォーム内から制御したいサービスに応じて、クラスタ上に 1 つまたは複数のコントローラをデプロイする必要があります。今回のケースでは、Amazon RDS のコントローラが必要になります。
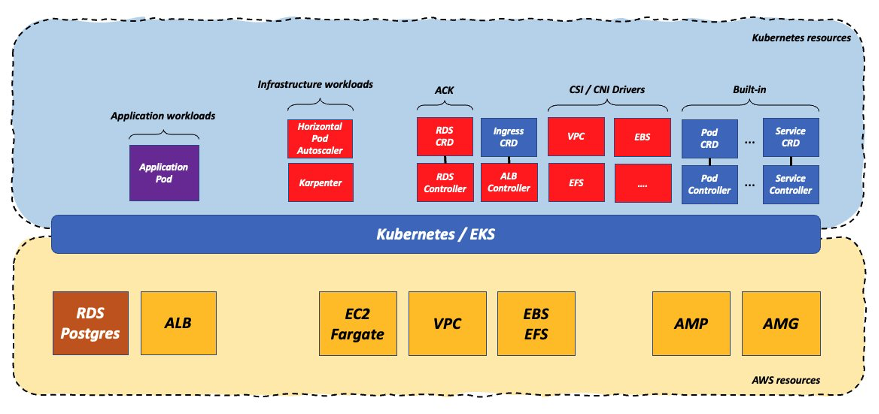
このシナリオでは、ワークロードの重力は大きく変わっていません( Kubernetes クラスターとネイティブ AWS サービスの間に中心があることに変わりはありません ) が、Kubernetes API という単一の API で全てのデプロイを制御できるようになりました。
Postgres オペレータの代わりに Amazon RDS ACK コントローラを利用することで、利用者は 2 つの次元で複雑さを簡素化できます。1 つ目は、Amazon RDS を利用すれば、データプレーン (データベースコードを実行する実際の Pod )と、スケーラビリティ、セキュリティ、パフォーマンスの最適化、信頼性などの多く点でそれに関連するすべてのものを管理しなくなることです。もう 1 つは、ACK コントローラは一般的に非常に簡素で、単にクラウドサービスの CRUD ( 作成、読み取り、更新、削除 ) のみを実装しています。ACK コントローラは、特定のサービスを実行するために関連するすべての操作をマネージドサービスにオフロードします。逆に、Postgres オペレータ ( またはその他の DB オペレータ ) では、データベースに関連するすべての操作 ( バックアップ、リカバリ、スケーリングなど ) に責任を負います。
要するに、フルマネージドな AWS サービスを利用した ACK コントローラを実行する場合、クラスタ内で同様のサービスを実行するためのオペレータを管理する必要がある場合に比べ、利用者にとっての作業 ( およびメンテナンス ) は、はるかに少なくて済むということである。
しかし、私が気にするのが複雑さと差別化につながらない重労働を減らすことだけなら、これで十分でしょうか?利用者は複雑さの多くを AWS のマネージドレイヤーにオフロードしていますが、Kubernetes クラスタ上でアプリケーションを実行しているということは、満たすべき要件や維持すべき依存関係がたくさんあることを意味しています。このスタックを管理するのは、かなりの作業量になります。これらの要件と依存関係のいくつかを見てみましょう。
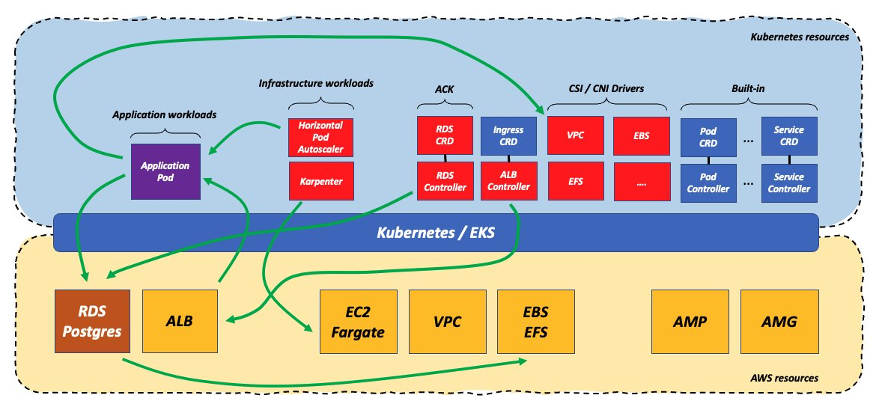
まず何よりも、利用者は Kubernetes クラスタ上でアプリケーションを実行するので、そのスケーラビリティに気を配る必要があります (おそらく Horizontal Pod Autoscaler を使用します )。同様に、Amazon Elastic Compute Cloud ( Amazon EC2 ) を使用している場合、そのインフラを拡張するために Cluster Auto Scaler や Karpenter のようなものを用意する必要があります。Kubernetes 上で動作する Pod ( 複数可 ) に ALB を配線する必要があるため、クラスタ上に ALB コントローラを設置し、維持する必要があります。データベースを AWS のマネージドサービス側に移したことで、CSI ドライバの重要性は下がりましたが、高度なネットワーク機能を必要とするアプリケーションポッドを実行しているため、CNI プラグインはクラスタ内スタックで重要な役割を担っていることに変わりはありません。お客様によっては、AWS Secrets Manager とのインターフェイスのための External Secrets Operator のような追加のオペレータを実行する必要があるかもしれません ( 前の図には表示されていませんが ) 。最後に、技術的な理由から、CoreDNS のようないくつかのコンポーネントは、アプリケーションの Pod と一緒にデータプレーンで実行されなければならないため、クラスタ内で維持するためのインフラストラクチャーソフトウェアのワークロードが増えることになります。
これらの問題は、クラウド・プロバイダーがクラスタ内で動作するすべてのコンポーネントを完全に所有することで解決できるという誤解があることに注意してください。理論的にはこれは健全かもしれませんが、実際には、Kubernetes クラスタは、クロスバージョンの依存関係の大きなセットを作成するソフトウェア ( アプリケーションワークロードまたはインフラストラクチャワークロードのいずれか ) を実行し続けることになります。言い換えれば、誰がこれらのコンポーネントを管理するかということではなく、( プロバイダーと利用者の間の ) 責任共有モデルにおいて、どのようにして動作するソフトウェアのバージョンを見つける ( そして維持する ) かが問題になります。例えば、クラウドプロバイダーがクラスタのアップグレードを所有しているという事実があっても、利用者が実行するコンポーネントが、任意の時点で実行されている Kubernetes のバージョンと互換性があることを確認する必要があることに変わりはありません。この問題は、大規模なマルチテナントクラスターで作業する場合、依存関係が大きく複雑になるため、明らかにエスカレートし、悪化しています。
Kubernetes がコントロールプレーンの全てを担うが、データプレーンは担わない
もし、利用者がクラスタ上で実行されるワークロードと構成を簡素化する道を歩んでいるとしたら、どうして全てをオフロードせずに、アプリケーションだけはそのままなのでしょうか。アプリケーションを含む全てを AWS マネージドサービスに移動させても、Kubernetes API をを使ったインフラストラクチャの管理を維持できるのでしょうか?
ある人は、Kubernetes を「よく設計され、プログラマティックな Reconciliation Loop を備えた拡張可能な API で、そこにたまたまコンテナオーケストレータも組み込まれているもの」と特徴付けています。私はその考え方が好きです。もし利用者が、コンテナ化されたアプリケーションさえも、常時アップグレードやソフトウェアバージョンのキュレーションを必要としない、より管理されたバージョンレス環境にオフロードできるとしたらどうでしょうか。言い換えれば、Kubernetes がコンテナというバッテリーを含んだ、汎用的なコントロールプレーンであると考えれば、これらのバッテリーを取り外し、他のタイプのバッテリーと交換できるのではないでしょうか。
その世界を、仮に Amazon ECS ACK コントローラーで表現するとこうなります。
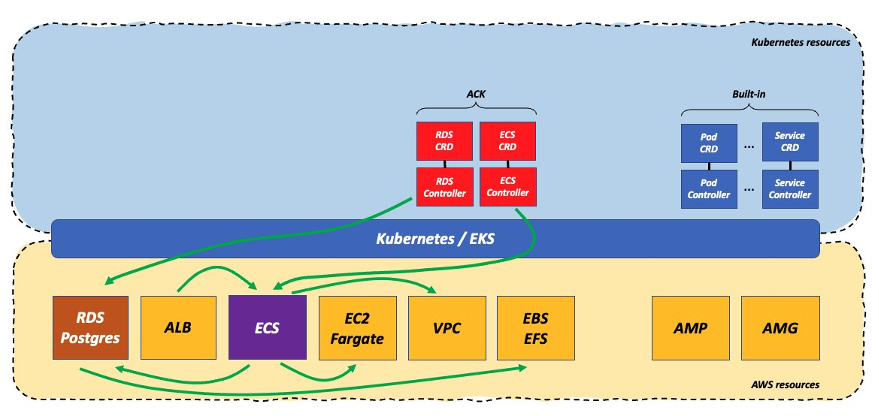
このシナリオでは、ワークロードの重力は、Kubernetes というコントロールプレーンに対してデータプレーンとして機能する、Kubernetes / EKS の線の下にあるマネージドな AWS ネイティブサービスに移っています
アプリケーションと他のインフラ機能・能力との間の論理的な相互作用は、すべて劇的に変化していないことに注意してください。変わったのは、それらのやり取りを管理する人です。この仮説のコンテキストでは、これらの相互作用はすべて Kubernetes ラインの下で起こり、それらの統合の負担のほとんどは AWS にあります。繰り返しますが、このシナリオの最も重要な部分は、誰がこの統合を管理するかということではなく、この統合が完全にバージョンレスであり、動き続けるという事実です。ドライバはなく、考慮する必要のあるバージョンも一切ありません。この理論の良い実例は、Kubernetes クラスタの上で Istio を実行するのと、Amazon ECS Service Connect をそのまま利用するのとでは、労力的に大きな違いがあることです。
このようなシナリオでは、利用者は結局、クラスタ上で動作するソフトウェアのバージョン依存性がかなり低くなります ( Kubernetes 上で動作するソフトウェアが単に少ないため ) 。確かに、利用者はクラスタ上で動作する ACK コントローラを管理しなければなりませんが、コントローラの要件はクラスタのバージョンに対する感度が非常に低く、依存関係も少なくなります。そしてこれは、Kubernetes クラスタ自体のメンテナンス、特にそのアップグレードを劇的に簡単、迅速、かつリスクの少ない方法で実行することを可能にします。
はい、ソフトウェアベースの統合は、信じられないほどの柔軟性を提供します。実際、EKS は CSI と CNI ドライバを通じて、同じ主要なビルディングブロックで ECS が行うよりも多くの統合をサポートしています。しかし、そのような極めて高い柔軟性を必要としない場合、ソフトウェアベースの統合は、誰が管理するかにかかわらず、ビジネスを可能にするのではなく、むしろ阻害する要因になりかねません。
なぜこんなことをしようと思ったのか?
利用者は、Kubernetes のバックグラウンドを持っていて、Kubernetes を愛しているが、運用コストが割に合わない場合にこのモデルを検討できます。このモデルは、彼らが愛したインターフェイスを維持しながら、より多くのものを AWS にオフロードして管理させることを可能にするものです。「どこでもスクリプトを実行できる」から「どこでも自分のスキルを適用できる」へと急速に変化している世界において、このソリューションは、Kubernetes 中心の世界観を維持しつつ、運用負荷を軽減できるという良いバランスを生み出すかもしれません。Amazon ECS はバージョンレスでサーバーレスであるため、Kubernetes クラスタのアップグレードに伴う依存性が軽減されます。このソリューションが Kubernetes の熱心な利用者にとって魅力的であるもう一つの理由は、Amazon ECS では利用できるが Amazon EKS では ( まだ ) 利用できない AWS Fargate 機能にアクセスできることです。これらの機能の例としては、Graviton のサポート、Spot のサポート、Windows のサポートが挙げられます。
また、このやり方は何も新しいものではないことに注意してください。例えば、Lambda 用の ACK コントローラは既に用意されているので、同様のことが可能です。ACK ECS コントローラーの特徴は、プログラミングモデルと EKS コンテナと ECS コンテナのパッケージングが同じであるため、Kubernetes データプレーンでワークロードを実行することから ECS データプレーンで同じワークロードを実行することへの移行がより簡単で透明性が高い可能性があります ( ECS のタスクやサービスの記述方法と、Kubernetes の Pod や Deployment の記述方法に対して YAML の構文を変えるだけです ) 。
このように、Amazon ECS の ACK コントローラーは、「自分の武器になる CRD がまた一つ増えた」と、お客様には思っていただけるはずです。
このモデルを検討するための 2 つ目の道筋は、利用者が Amazon ECS のバックグラウンドから来ており、Amazon ECS と AWS にすべて入っているが、戦術的または戦略的に、Kubernetes インターフェースを採用することにメリットを見出している場合です。これは、会社全体で Kubernetes を採用することが決められているが、フルマネージド AWS の利点を手放したくないことからきているかもしれません。また、Kubernetes のエコシステムで利用できるプラクティスやツールのうち、Amazon ECS の運用にうまく適用できるものを採用したい ( 例えば、GitOps や Helm のパッケージングサポートなど)という理由も考えられます。このような経路から来る利用者は、本質的に Amazon ECS ACK コントローラを「これは ECS ワークロードのための新しいデプロイメントツールである」と見るでしょう。
次の図は、この仮想的なソリューションで実現できる可能性があることを表しています。

結論
この投稿では、Kubernetes の柔軟性を紹介しました。ここで紹介したものは間違いなく、とても極端な選択肢であり現実では存在しません。 ( Amazon ECS ACK コントローラは利用できませんが、興味を持たれた方はこのロードマップ案をサムアップしてみてください。 )
もし何かが証明されたとすれば、それは Kubernetes が多くの異なる人たちにとって多くのことを示しており、その定義は依然として未完成であることを意味します ( 少なくとも私の頭の中では )。
このブログは、従来の「Amazon EKS vs Amazon ECS」の議論が誤解を招く可能性があることを示唆することも目的としています。Kubernetes の本当の姿は、最終的には、利用者が使用するアプローチによって、クラウドサービス全体の再構築もしくはプロキシであり、このブログ記事で概説しようとしたものです。
今日、多くのユーザーが、一部のアプリケーションをクラスターで実行し、他の多くのインフラストラクチャーコンポーネントをネイティブクラウドで実行するというハイブリッドアプローチをとっている事実は、ほとんど偶発的なものです。利用者が実装する Kubernetes の状態は、多くの変数の関数であり、正しいか間違っているかはありません。結局のところ、それはトレードオフであり、「ワークロードの重力」はその極めて特殊な状況に応じて大きく変化します。例えば、最後に紹介したシナリオを Kubernetes 中心の利用者からは広く採用されると思いませんが、複数の独立したチームが自律的に製品を決定している大企業などでは魅力的かもしれません。こうしたチームの中には、中央集権的なプラットフォーム・チームが提唱する ( あるいは方針付けられた )「Kubernetes」標準に準拠しながら、完全なサーバーレスおよびバージョンレスの運用モデルを採用するサービスを使用することを好む人もいるでしょう。
「Kubernetes がコントロールプレーンの全てを担うが、データプレーンは担わない」セクションで、私が言及したコンセプトのいくつかを、実際の生活でどのように見えるか興味がある方は、ここで短いデモをご覧ください。このビデオでは、ECS ACK コントローラのプロトタイプを使用しています ( Amine さん、ありがとうございます! )。このコントローラのコードは、デモのために潜在的な全機能のサブセットを実装しているだけなので、この執筆時点では一般に公開されていません。
翻訳は Tech Training Specialist の 山田 が担当しました。原文はこちらをご覧ください。