Amazon Web Services ブログ
新機能 – Amazon Redshift 向け AWS Data Exchange
2019 年に AWS Data Exchange について説明し、データ製品の検索、サブスクライブ、および使用方法について説明しました。現在では、次の 10 のカテゴリで 3600 を超えるデータ製品を選択できます。

導入記事では、データ製品をサブスクライブし、そのデータセットを Amazon Simple Storage Service (Amazon S3) バケットにダウンロードする方法を説明しました。次に、AWS Lambda 関数、AWS Glue クローラ、 Amazon Athena クエリなど、さらなる処理のためのさまざまなオプションを提案しました。
今回は、Amazon Redshift 向け AWS Data Exchange の導入により、サードパーティデータの検索、サブスクライブ、使用がさらに簡単にします。
サブスクライバは、それ以上の処理を行うことなく、プロバイダのデータを直接使用でき、抽出変換ロード (ETL) プロセスを必要としません。処理を行う必要がないため、データは常に最新であり、Amazon Redshift クエリで直接使用できます。Amazon Redshift 向け AWS Data Exchange が、エンタイトルメントと支払いの管理すべてを担当し、すべての料金がお客様の AWS アカウントに請求されます。
プロバイダが、データのライセンスを取得し、顧客に使用できるようにする新しい方法が登場しました。
この記事を書いているうちに、いかに多くの Redshift と、Data Exchange の既存の側面が中心的な役割を果たしたかを実感するのは感慨深いことでした。Redshift はストレージとコンピューティングを明確に分離し、組み込みのデータ共有機能を備えているため、データプロバイダはストレージの割り当てと支払いを行い、データサブスクライバはコンピューティングの割り当てと支払いを行います。プロバイダは、加入者ベースのサイズに比例してクラスタを拡張する必要はなく、データの取得と提供に集中できます。
この機能を、データ製品のサブスクライブとデータ製品の公開という 2 つの視点から見てみましょう。
Amazon Redshift 向け AWS Data Exchange – データ製品へのサブスクライブ
データサブスクライバは、AWS Data Exchange カタログを閲覧し、自分のビジネスに関連するデータ製品を見つけてサブスクライブすることができます。
データプロバイダは、プライベートオファーを作成し、AWS Data Exchange コンソール経由でアクセスできるように拡張することもできます。[My product offers] (自分の製品オファー) をクリックし、拡張されたオファーを確認します。[サブスクリプションを続行する] をクリックして続行します。

次に、オファーとサブスクリプション条件を確認し、取得するデータセットを確認して、[サブスクライブ] をクリックしてサブスクリプションを完了します。
サブスクリプションが完了すると、通知が届き、次に進むことができます。
Redshift コンソールで [Datashares] (データ共有) をクリックし、[From other accounts] (他のアカウントから) を選択すると、サブスクライブされたデータセットが表示されます。

次に、サブスクライブされたデータ共有を指すデータベースを作成して、1 つ以上の Redshift クラスターに関連付けます。テーブル、ビュー、ストアドプロシージャを使用して Redshift クエリとアプリケーションを強化します。
Amazon Redshift 向け AWS Data Exchange – データ製品の公開
データプロバイダは、AWS Data Exchange 製品に Redshift のテーブル、ビュー、スキーマ、およびユーザー定義関数を含めることができます。単純化するために、Redshift テーブルを 1 つだけ含む製品を作成します。
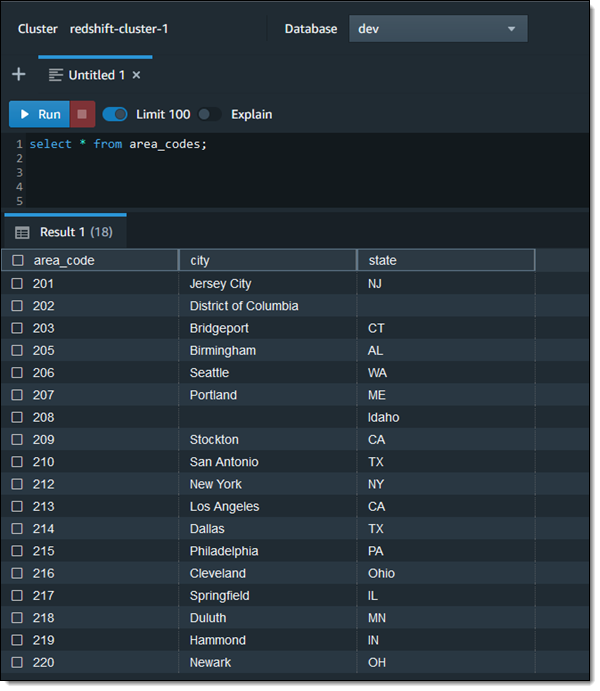
高品質の新しい Redshift クエリエディタ V2 を使用して、米国の市外局番を都市と州にマッピングするテーブルを作成します。
次に、Redshift クラスターの既存のデータ共有のリストを調べ、[Create datashare] (データ共有の作成) をクリックして新しいデータ共有を作成します。
次に、データ共有の作成のための通常のプロセスを見ていきます。[AWS Data Exchange datashare] (AWS Data Exchange データ共有) を選択し、名前 (area_code_reference) を割り当て、クラスター内のデータベースを選択し、パブリックにアクセス可能なクラスターからデータ共有にアクセスできるようにします。
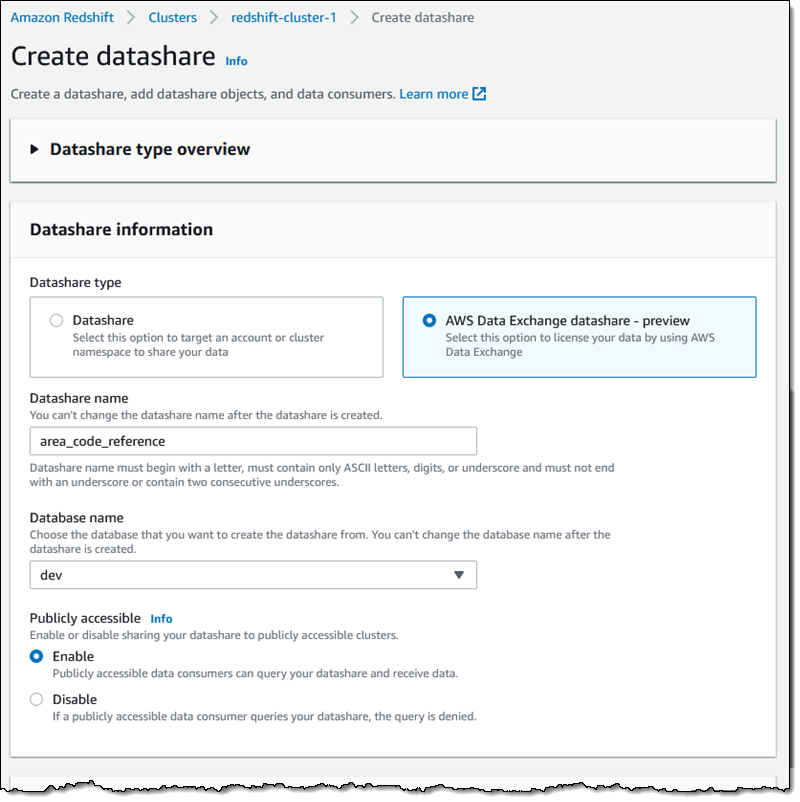
次に、スクロールダウンして [追加] をクリックして進みます。

自分のスキーマ(パブリック)を選択し、データ共有にテーブルとビューのみを含めることを選択し、area_codes テーブルを追加します。
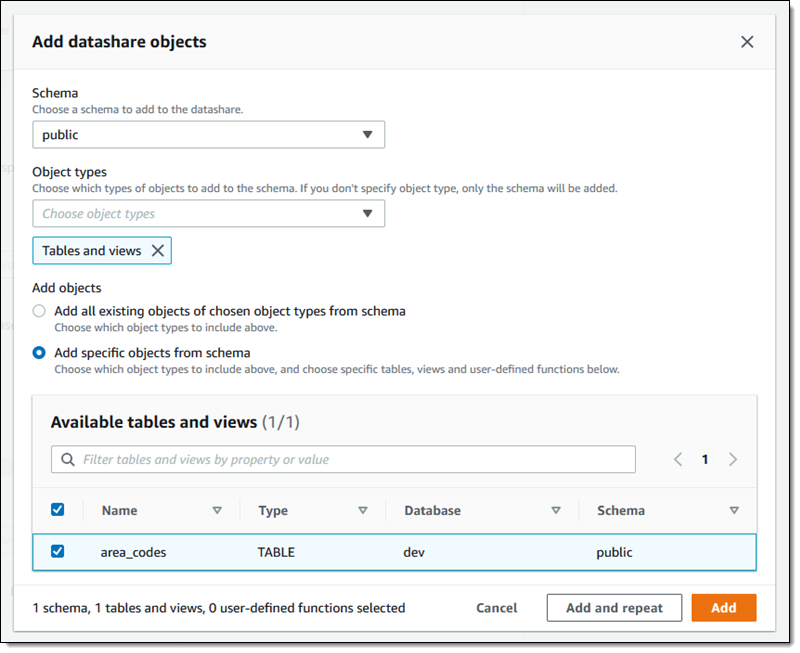
この時点で、[追加] をクリックして終了することも、[Add and repeat] (追加して繰り返し) をクリックして、追加のオブジェクトを含むより複雑な製品を作成することもできます。
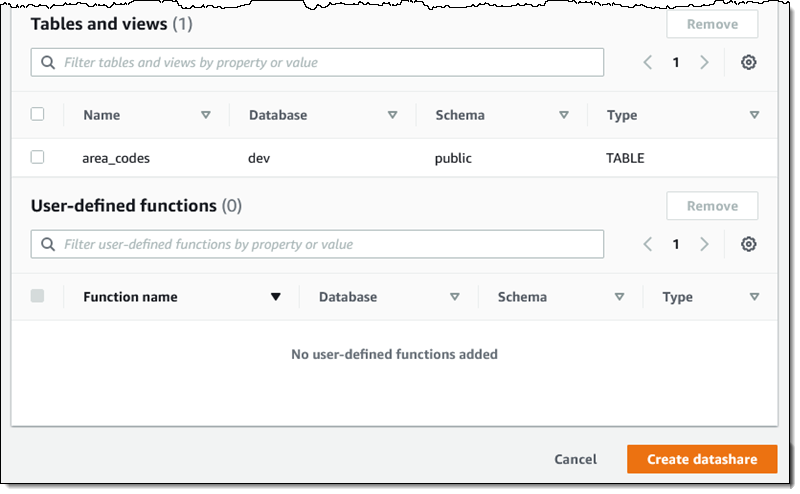
データ共有アのテーブルが含まれていることを確認し、[Create datashare] (データ共有の作成) をクリックして次に進みます。
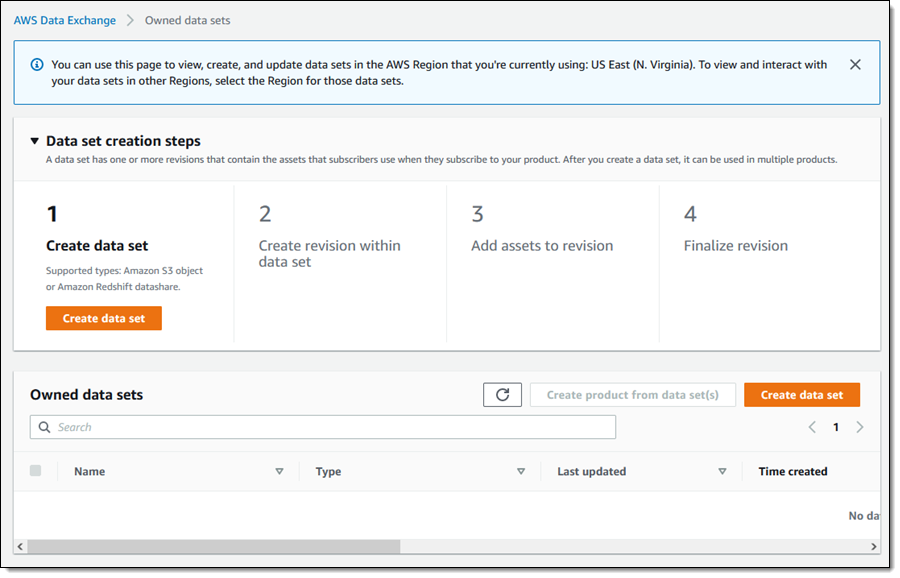
これで、データの公開を開始する準備が整いました。 AWS Data Exchange コンソールにアクセスし、左側のナビゲーションを展開して、[所有データセット] をクリックします。

[データセット作成のステップ] を確認し、[データセットを作成] をクリックして次に進みます。
[Amazon Redshift datashare] (Amazon Redshift データ共有) を選択し、データセットに名前 (United States Area Codes) を付け、説明を入力し、[データセットを作成] をクリックして続行します。
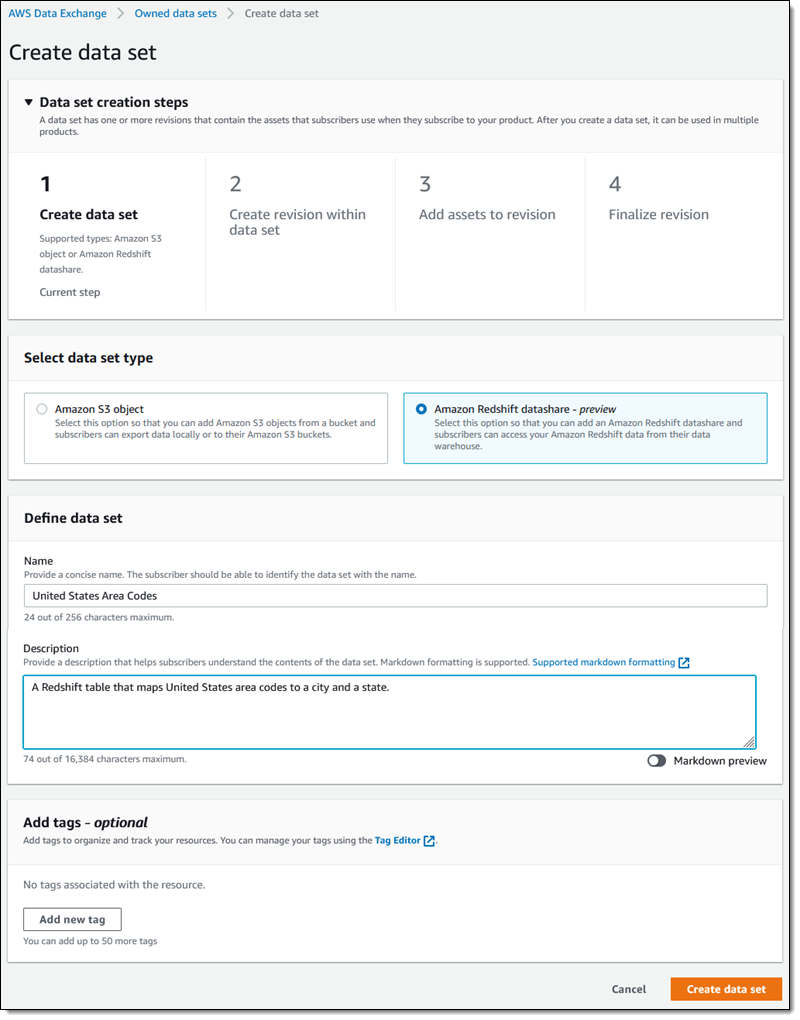
v1 というリビジョンを次のように作成します。

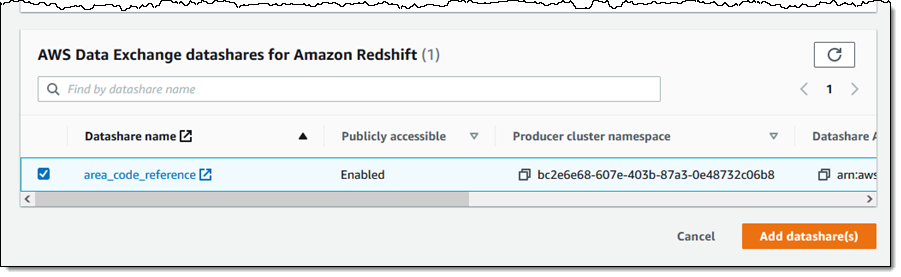
次のように自分のデータ共有を選択し、[Add datashare(s)] (データ共有の追加) をクリックします。
次に、次のようにリビジョンを確定します。

データ共有とデータセットの作成方法、およびコンソールを使用した製品の公開方法を説明しました。複数の製品を公開したり、定期的に改訂したりする場合は、 AWS コマンドラインインターフェイス (CLI) と Amazon Data Exchange API を使用して、これらすべてのステップを自動化できます。
初期データ製品
複数のデータプロバイダが、Amazon Redshift 向け AWS Data Exchange を通じてデータ製品を利用できるように取り組んでいます。初期のオファリングと公式の説明の一部は次のとおりです。
- FactSet Supply Chain Relationships – FactSet Revere Supply Chain Relationships データは、世界中の企業間のビジネス関係の相互接続を公開するために構築されています。このフィードは、年次申告書、投資家向けプレゼンテーション、プレスリリースから収集された、企業の主要顧客、サプライヤー、競合他社、戦略的パートナーの複雑なネットワークへのアクセスを提供します。
- Foursquare Places 2021: ニューヨーク市のサンプル – このトライアルデータセットには、Redshift データ共有としてアクセス可能な Foursquare のニューヨーク市向け統合型 Places (POI) データベースが含まれています。Foursquare の Places データを Redshift テーブルに瞬時に読み込み、さらなる処理と分析を行うことができます。Foursquare のデータはプライバシーに準拠し、独自の情報を元にしていて、Uber、Samsung、Apple などのトップ企業から信頼されています。
- Mathematica Medicare Pilot Dataset – Medicare HCC数と有病率を州、郡、支払人別に集計し、2017年から2019年までの糖尿病患者集団を対象に絞り込んでいます。
- カナダでの COVID-19 ワクチン接種 – このリストには、カナダでの COVID-19 ワクチン接種データのサンプルデータセットが含まれています。
- Revelio Labs の労働力の構成と傾向データ (トライアルデータ) – あらゆる企業の労働力の構成と傾向を理解します。
- Facteus – 米国カード消費者決済 – CPG Backtest – 米国全土の 9,000 戸を越える都市部のコンビニエンスストアと雑貨店で販売されている数百の消費者向けパッケージ商品の現金およびカード取引を元にした、SKU レベルの一連の取引詳細のサンプル履歴。
- Decadata Argo サプライチェーントライアルデータ – 米国の食料品小売業者に製品を配送する CPG 企業のサプライチェーンデータ。
– Jeff;