Amazon Web Services ブログ
Amazon EMR、Amazon SageMaker、および AWS Service Catalog で Intuit Data Lake をプロビジョニングする
この投稿では、Intuitの学習内容と AWS 上でのデータレイクの推奨事項を共有します。Intuit Data Lake は、Intuit データプラットフォームの数多くのチームにより構築され、運営されています。Tristan Baker (チーフアーキテクト)、Neil Lamka (プリンシパル製品マネージャー)、Achal Kumar (開発マネージャー)、Nicholas Audo、および Jimmy Armitage のフィードバックとサポートに感謝いたします。
データレイクとは、あらゆる規模で構造化データと非構造化データを保存する、一元化されたリポジトリです。Intuit では、未加工データのパイルなどを作成することは、容易です。しかし、より興味深い課題がその中に存在しています。
- AWS アカウントを整理する方法
- 使用する取得方法 アナリストの必要とするデータの検索方法
- データの保存場所 アクセスの管理方法
- Intuit の機密データを保護するために必要なセキュリティ措置
- このエコシステムで自動化できる部分
この投稿では、Intuit で採用されるアプローチを概説します。ただし、データレイクを構築するには多くの方法 (例: AWS Lake Formation) があることを覚えておくことは重要です。
高いレベルで Intuit Data Lake を作成する際に含まれる技術やプロセスを取り上げます。これには、全体的な構造とアカウントやリソースのプロビジョニングに使用される自動化を含みます。Intuit Data Lake を協力して構築した他のチームやエンジニアから寄せられたシステムの特定の局面でより詳細なブログ投稿について、今後もこのスペースをご覧ください。
アーキテクチャ
アカウント構造
データレイクは一般的にデータソースへのアクセスをコントロールする共有サービスを含むハブアカウントにより、hub-and-spoke モデル に従います。この投稿の目的で、ハブアカウントを Central Data Lake と呼びます。
このパターンでは、Central Data Lake へのアクセスは、Processing Account と呼ばれるスポークアカウントに割り当てられます。このモデルでは、エンドユーザー間の分離を維持し、、異なるビジネスユニット間で請求を分割できるようにします。
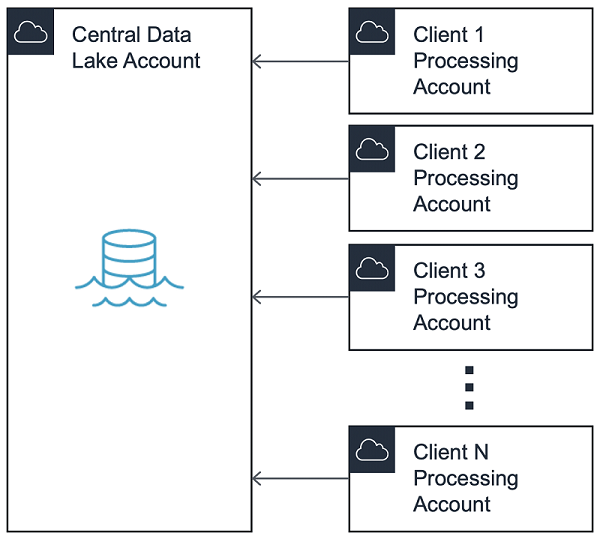
通常は、本番前 (Pre-Prod) と本番 (Prod) の 2 つのエコシステムを維持します。これにより、データレイク管理者は Pre-Prod と Prod の間の接続性を防止することで、データにサイロアクセスできるようにします。
実験とテストを可能にするために、Pre-Prod アカウント内でdev、qa、および e2e などの個別の VPC ベース環境を維持することをお薦めします。Processing Account VPC はその後、Central Data Lake の対応する VPC に接続されます。
最初に、アカウントを VPC ピアリング 経由でアカウントに接続したことにご注意ください。しかし、規模が大きくなるにつれて、すぐに125 個の VPC ピアリング接続のハードリミットに近づき、AWS Transit Gateway に移行することが必要になります。ここでは、複数の新しい Processing Account に毎週接続します。

Central Data Lake
ハブアカウントで実行中の多くのサービスがある場合がありますが、このブログに最も関連のある面に焦点を当てました。つまり、取り込み、サニテーション、保管、データカタログです。
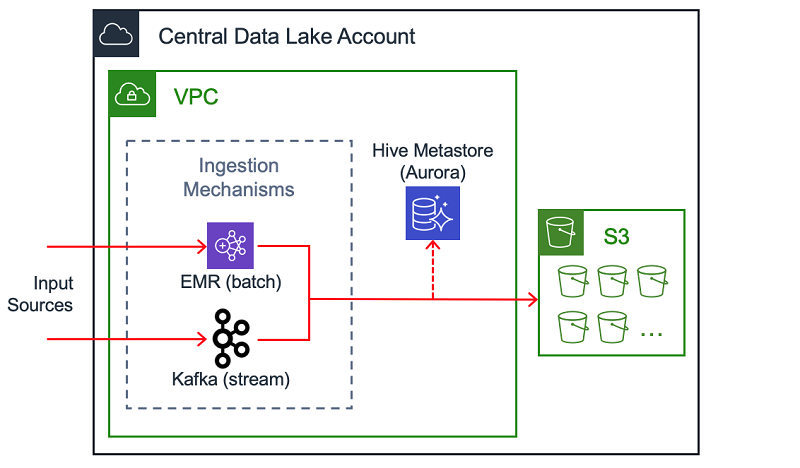
取り込み、サニテーション、および保管
Central Data Lake の重要なコンポーネントは、ストリーミングデータの均一の取り込みパターンです。1 つの例として、Amazon EC2 で実行される Apache Kafka クラスターがあります。(別のAWS ブログ で Intuit エンジニアがこれを行う方法についてお読みになることができます。) 数百のデータソースを扱う際に、AWS PrivateLink 経由で取り込みメカニズムにアクセスすることをできるようにしました。
注: Amazon Managed Streaming for Apache Kafka (Amazon MSK) は、Amazon EC2 で Apache Kafka を実行する代替方法ですが、Intuit の移行の開始時には利用可能ではありませんでした。
ストリーム処理に加えて、取り込みの別の方法は Amazon EMR でジョブを実行するなどの一括処理です。データがこれらの方法の 1 つで取り込まれた後で、更に処理し、分析するために Amazon S3 に保管できます。
Intuit は大量のカスタマーデータを扱い、それぞれのフィールドが機密レベルの点で注意深く考察され分類されています。レイクを入力するすべての機密データは、ソースで暗号化されます。取り込みシステムは暗号化されたデータを取得し、それをレイクに移動します。S3 にそれが書き込まれる前に、そのデータは独自の RESTful サービスによりサニタイズされます。データレイク内で運営するアナリストとエンジニアは、このマスクされたデータを消費します。
データカタログ
データカタログは、エンドユーザーにデータに関する情報とそれが常駐する場所の情報を与える一般的な方法です。1 つの例は、Amazon Aurora に支えられた Hive Metastore が挙げられます。もう一つの方法は、AWS Glue データカタログ です。
Processing Account
Processing Account がエンドユーザーに配布されるとき、全く同一のリソースを含みます。Processing Account の自動化を以下で取り上げますが、主なコンポーネントは次のとおりです。
- Transit Gateway 経由の Central Data Lake への接続性
- Bastion host for SSH は Amazon EMR クラスターにアクセスする
- IAM ロール、S3 バケット、および AWS Key Management Service (KMS) のキー
- 設定管理ツール経由のセキュリティ フレームワーク
- Amazon EMR および Amazon SageMaker のプロビジョニングを促進するための AWS Service Catalog 製品

お客様への配送時の Processing Account の構造
データストレージメカニズム
1 つの正当な質問は、すべてのデータが Central Data Lake に常駐すべきか、複数アカウントにわたってデータを分散することが許可されるのか、ということです。データレイクは 2 つのアプローチの組み合わせを採用し、データの保存場所をプライマリまたはセカンダリとして分類します。
プライマリロケーションのデータは Central Data Lake で、以前話し合った通り、取り込みパイプライン経由でそこに到着します。Processing Account はプライマリソースから、取り込みパイプラインまたは S3 からのいずれかから直接、読み込まれます。Processing Account は変換されたデータを Central Data Lake (プライマリ) に戻すか、それを独自のアカウント (セカンダリ) に保管することができます。適切なストレージの場所は、データのタイプ、それを消費する人に応じて異なります。
施行する価値のある 1 つのルールは。クロスアカウントの書き込みを許可するべきではないということです。言い換えると、IAM 原理 (ほとんどの場合、IAM ロールはインスタンスプロファイル経由で EC2 により想定される) は、宛先の S3 バケットと同じアカウントでなければなりません。これは、クロスアカウント委託がサポートされていない、つまり Central Data Lake の S3 バケットポリシーが Processing Account B のロールにより書き込まれたオブジェクトへの Processing Account A のアクセスを付与できないためです。
EMR のもう一つの可能性は、カスタムの資格情報プロバイダー (この AWS ブログを参照) 経由で異なる IAM ロールを想定するが、多くの EMR ジョブを書き換える必要があるため、Intuit ではこのパスを採用しないことにしました。
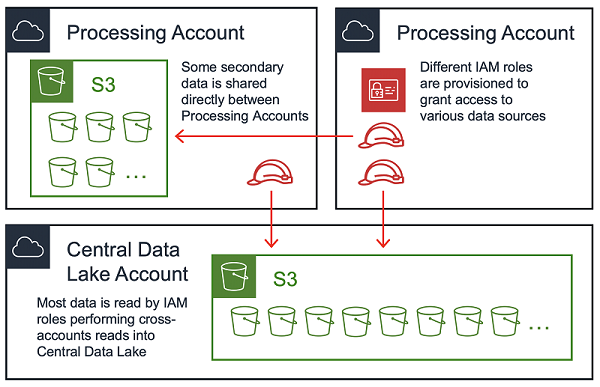
データアクセスパターン
大多数のエンドユーザーは、S3 に常駐するデータに興味を持っています。Central Data Lake と一部の Processing Account では、多くの 読み取り専用の S3 バケットのセットがある可能性があります。データレイクエコシステムの任意のアカウントは、このタイプのバケットからデータを読み取ることができます。
読み取り専用のバケットに対する S3 アクセスのマネジメントを促進するために、S3 バケットのポリシーをコントロールするメカニズムを構築して、コード経由で全体を管理します。当社のデプロイメントパイプラインはアカウントメタデータを使用して、アカウントのタイプ (Pre-Prod または Prod) に基づいて正しい S3 バケットポリシーを動的に生成します。これらのポリシーは、可聴性とマネジメントのしやすさのために当社のコードリポジトリに戻りコミットします。
当社は KMS キーポリシーの管理のために同じメソッドを採用します。S3 の保存中の暗号化 に対して カスタマーが管理したカスタマーマスターキー (CMK) で KMS を使用するためです。
読み取り専用のバケットに対して精製される S3 バケットポリシーの例は、次のとおりです。
当社は明示的なプリンシパル IAM を使用するのではなく、アカウントレベルでアクセスを付与することにご留意ください。読み取りはクロスアカウントであるため、アクセス許可もまた Processing Account で IAM プリンシパルに必要です。このレベルの粒度で、自動化を使用してこれらのポリシーを維持することは、大規模では不可能です。さらに、特定の IAM プリンシパル ARN を使用すると、外部アカウントへの外部依存関係が作成されます。 たとえば、Central Data Lake の S3 バケットポリシーで参照されている IAM ロールを Processing Account が削除すると、バケットポリシーを保存できなくなり、デプロイパイプラインが中断します。
セキュリティ
セキュリティはいずれのデータレイクに対しても最重要です。使用しているコントロールのサブセットについて取り上げますが、とくに掘り下げて見ていきません。
暗号化
暗号化は、複数の方法を使用して、転送中と保管中の両方で実施できます。
- レイク内のトラフィックでは、最新バージョンの TLS (本書作成時点で 1.2) を使用する必要があります。
- データはアプリケーションレベル (クライアント側) の暗号化で暗号化することができます。
- KMS キーを使用して、S3、EBS、および RDS の保管中の暗号化を使用できます。
イングレスとエグレス
イングレスとエグレスへのアプローチに異常はありませんが、次のとおり、重要であることがわかった標準パターンに言及する価値があります。
- セキュリティグループで Bastion ホストを SSHトラフィックを適切なCIDR 範囲に制限する
- ネットワークアクセスコントロールリスト (ACL) で不必要なデータエグレスを避ける
- S3 バケットへのアクセスをVPC エンドポイント経由でルートして、公共インターネットに進むことを避ける
イングレスとえぐレスを制限するポリシーは、データレイクが質 (イングレス) を保証し、損失 (エグレス) を保証することができるプライマリポイントです。
認可
Intuit Data Lake へのアクセスは IAM ロールを通じてコントロールされます。つまり、IAM ユーザー(長期間の認証情報を持つ)は作成されないことを意味します。エンドユーザーには、AWS アカウントへのロールベースのフェデレーションアクセスを管理する内部サービスを経由してアクセスが付与されます。定期的な見直しが実施され、重要ではないユーザーを削除します。
設定マネジメント
Cloud Custodian の内部フォークを使用します。これは、Amazon CloudWatch Events と AWS Config ルールで構成される予防、検出、および応答のコントロールのスイートです。それが報告し、(任意に) 緩和する違反には次のものがあります。
- インバウンドのセキュリティグループルールの未承認の CIDR
- パブリック S3 バケットポリシーと ACL
- IAM ユーザーコンソールアクセス
- 暗号化されていない S3 バケット、EBS ボリューム、および RDS インスタンス
最後に、Amazon GuardDuty はすべての Intuit Data Lake アカウントで有効になり、Intuit Security によりモニタリングされます。
自動化
Intuit Data Lake を構築して学んだことが 1 つあるとすれば、すべてを自動化することです。
このブログで取り上げる 4 つの自動化があります。
- Processing Account の作成
- Processing Account オーケストレーションパイプライン
- Processing Account Terraform パイプライン
- Service Catalog 経由の EMR および SageMaker のデプロイ
Processing Account の作成
Processing Account の作成の第一歩は、社内ツールを通じてリクエストを作成することです。これは正しいビジネスユニットの元で Intuit をスタンプした AWS アカウントをプロビジョニングする自動化をトリガーします。

注: AWS Control Tower の Account Factory は一連の作業の最初には使用できませんでしたが、セキュアな環境のベストプラクティスのセルフサービスの方法で、AWS アカウントをプロビジョニングするために利用できます。
アカウント設定にはまた、Service Catalogを使用した完全に自動化されたVPCの自動作成 (オプションの VPN を使用して) も含まれます。エンドユーザーはサブネットのサイズを指定するだけです。
Intuit は、イングレスセキュリティグループ、VPC エンドポイント、VPC ピアリングなど、他の一般的なパターンのセルフサービスデプロイに Service Catalog を活用していることに注意する価値があります。ポートフォリオ例を示します。

Processing Account オーケストレーションパイプライン
アカウント作成と VPC プロビジョニングの後で、Processing Account オーケストレーションパイプラインが実行されます。このパイプラインは Processing Account に必要な 1 回のみのタスクを実行します。これらのタスクには、次のものが含まれます。
- さらなる設定管理で使用するための IAM ロールのブートストラッピング
- S3、EBS、RDS 暗号化のための KMS キーの作成
- 新しいアカウントの 変数ファイル の作成
- アカウントメタデータによるマスタ設定ファイルの更新
- Terraformパイプラインをオーケストレーションするためのスクリプトの生成については、以下で取り上げます
- Resource Access Managerを通じた移行ゲートウェイの共有
Processing Account Terraform パイプライン
このパイプラインは、IAM ロール、S3 バケットとバケットポリシー、KMS キーポリシー、セキュリティグループ、NACL、Bastion ホストなど、頻繁に更新されるダイナミックなリソースのライフサイクルを管理します。
すべての処理アカウントに 1 つのパイプラインがあり、各パイプラインは一連のパラメーター化されたデプロイジョブを使用して、アカウントに一連のレイヤーをデプロイします。レイヤーは Terraform モジュールと AWS リソースの論理的なグループ分けであり、Terraform 状態ファイルを縮小し、特定のリソースの再デプロイが必要な場合の影響半径を減らします。
Service Catalog 経由の EMR および SageMaker のデプロイ
AWS Service Catalog は、Amazon EMR と Amazon SageMaker のプロビジョニングを容易にし、エンドユーザーが組み込みセキュリティで EMR クラスターと SageMaker ノートブックインスタンスを起動できるようにします。
Service Catalog はデータサイエンティストやデータエンジニアがセルフサービス形式でユーザーフレンドリーなパラメータを使用して EMR クラスターを開始することができるようにし、次のものを提供します。
- Central Data Lake でサービスへの接続性を有効にするブートストラップアクション
- S3、KMS、その他の粒度のアクセス許可をコントロールする EC2 インスタンスプロファイル
- 保存中および移行中の暗号化を有効jにするセキュリティ設定
- オプションの EMR パフォーマンスのための設定分類
- モニタリングとロギングを有効にした暗号化された AMI
- LDAP へのカスタムの Kerberos 接続
SageMaker の場合、Service Catalog を使用して接続をセットアップするか、Hive Metastore、Kerberos、セキュリティ、Splunk ロギング、OpenDNS を初期化するカスタムライフサイクル設定でノートブックインスタンスを起動します。このAWS ブログでライフサイクル設定に関する詳細をお読みください。ベストプラクティス設定で SageMaker ノートブックインスタンスを起動することは、次のとおり容易です。

まとめ
この投稿は Intuit Data Lake を作成するために使用される構築ブロックを説明しています。当社のソリューションはまったく独自のものではなく、Intuit の数十人のエンジニアから収集した常識的なアプローチから構成されており、数十年の経験を表しています。これらのプラクティスにより、ペタバイト単位のデータをレイクにプッシュし、さまざまなニーズを持つ数百の Processing Account にサービスを提供することができました。まだ構築中ですが、このストーリーがデータレイクのジャーニーに役立つことを願っています。
この記事の内容および意見は第三者の作者によるものであり、AWS はこの記事の内容または正確性について責任を負いません。
著者について
 Michael Sambol は AWS のシニアコンサルタントです。彼はジョージア工科大学でコンピューターサイエンスの修士号を取得しています。Michael の趣味はエクササイズ、テニス、旅行、そして洋画鑑賞です。
Michael Sambol は AWS のシニアコンサルタントです。彼はジョージア工科大学でコンピューターサイエンスの修士号を取得しています。Michael の趣味はエクササイズ、テニス、旅行、そして洋画鑑賞です。
 Ben Covi は Intuit のスタッフソフトウェアエンジニアです。 いつでも、彼はおそらく Catan のゲームに負けているでしょう。指定された時点で、Cantan のゲームを
Ben Covi は Intuit のスタッフソフトウェアエンジニアです。 いつでも、彼はおそらく Catan のゲームに負けているでしょう。指定された時点で、Cantan のゲームを