Amazon Web Services ブログ
Portworx クラウドネイティブストレージを使用して、Amazon EKS で高可用性 Microsoft SQL Server コンテナを実行する
このブログ記事では、Amazon Elastic Container Service for Kubernetes (Amazon EKS) を使用したコンテナへの Microsoft SQL Server のデプロイについて説明します。ここで説明するものと同じアプローチと原則は、再利用可能で再現可能な DevOps プラクティスと組み合わせた高可用性 (HA) と耐久性を必要とする他のステートフルアプリケーションにも適用されます。ユースケースの例としては、MongoDB、Apache Cassandra、MySQL、ビッグデータ処理などがあります。
SQL Server をコンテナ内で実行するためのサポートは、SQL Server 2017 で初めて導入されました。Kubernetes (K8s と呼ばれることもあります) を使用して、Linux コンテナ内で本番用 SQL Server ワークロードを実行できます。
Microsoft SQL Server は、今日使用されている最も人気のあるデータベースエンジンの 1 つです。SQL Server は魅力的な機能と堅牢なコミュニティを数多く提供しますが、クラウドベースまたはオープンソースのデータベースソリューションよりもさらにメンテナンスを必要とするか、より高価です。組織によっては、オープンソースソリューションに移行してライセンスコストを削減することで、これらのコストを削減しようとしているところもあります。他の企業は、ワークロードを Amazon RDS for Microsoft SQL Server や Amazon Aurora などのマネージド型リレーショナルデータベース管理システム (RDBMS) サービスに移行することを選択しています。
ただし、組織が SQL Server エンジンから離れることができない (または離れたくない) 場合があるでしょう。これは、開発者、IT 管理者、エンジニアの内部チーム内での、不適切な手直しやそれに伴うコスト、あるいはスキルの不足など、さまざまな理由による可能性があります。これらのビジネスの中には、ライセンスやサポート契約、特別な技術的要件などのさまざまな理由により、マネージド型クラウドサービスを使用できない場合があるかもしれません。
このような状況では、Amazon Elastic Compute Cloud (Amazon EC2) インスタンスに SQL Server データベースをデプロイすることで、クラウドのさまざまな利点を利用することができます。このアプローチは、クラウドの多くの利点を依然として享受しながら、特別な要件を満たすために必要な柔軟性を維持します。これらの利点には、ハードウェアおよび物理インフラストラクチャからの完全な抽象化、事前のコミットメントなしの従量課金、および他のサービスとの統合などがあります。SQL Server をオンプレミスで実行するよりも優れた代替手段を提供しますが、マネージド型サービスと比較して DB インスタンス管理のオーバーヘッドが増加するため、改善の余地があります。
Kubernetes を使用して SQL Server を実行すると、次のいくつかの強力な利点があります。
- 単純さ: SQL Server ワークロードをコンテナにデプロイして維持することは、従来のデプロイモデルよりもはるかに簡単かつ迅速で、必要な労力がはるかに少なくて済みます。これは、デプロイが高速で、インストール不要で、アップグレードが新しいイメージをアップロードするのと同じくらい簡単で、コンテナがあらゆる環境で実行できる抽象化レイヤーを提供するためです。
- リソース使用の最適化: SQL Server ワークロードをコンテナ化すると、高密度が可能になり、多くの社内エンタープライズワークロードが共通のリソースプール (メモリ、CPU やストレージ) を共有できるようになります。したがって、未使用の容量が減り、インフラストラクチャの使用効率が向上します。
- より低いライセンスコスト: SQL Server をコンテナ内で高密度または低密度で実行すると、全体的なライセンスコストを削減できるシナリオがあります。これについては、後でライセンスセクションで詳しく説明します。
利用可能なコンテナサービス
現在、AWS では 次の 4 つのコンテナサービスを利用できます。
- Amazon Elastic Container Service (Amazon ECS): 他のいくつかの AWS のサービスとネイティブに統合されている、高度にスケーラブルで高性能なオーケストレーションサービス。
- Amazon Elastic Container Service for Kubernetes (Amazon EKS): AWS が提供するマネージド型サービス。Kubernetes を使用してコンテナ化されたアプリケーションを簡単にデプロイ、管理、および拡張することができます。
- AWS Fargate: サーバーまたはクラスターを管理しなくてもコンテナを実行できるようにする Amazon ECS のコンピューティングエンジン。
- Amazon Elastic Container レジストリ (Amazon ECR): 完全マネージド型の Docker コンテナレジストリ。Docker コンテナイメージを簡単に保存、管理、およびデプロイできます。
AWS でのアーキテクチャー作成の中核となる原則の 1 つは、マルチ AZ 配置であり、非常に回復力があり、高性能のワークロードを生み出します。Amazon Elastic Block Storage (Amazon EBS) ボリュームを SQL Server コンテナのストレージソリューションとして直接使用できますが、これにより、これらのコンテナは単一のアベイラビリティーゾーンで実行するように制限されます。この投稿で説明するように、Portworx がこの問題を解決するのに役立ちます。
Portworx は、AWS パートナーおよびマイクロソフトの高可用性および障害復旧パートナーです。Portworx を使用すると、EKS クラスターの一部として、SQL Server を複数の AWS アベイラビリティーゾーンにわたって高可用性モードで実行できます。Portworx は AWS Auto Scaling グループにわたって高い可用性設定でも実行できます。SQL Server インスタンスのストレージ階層として使用する場合、この機能はストレージの可用性を保証します。これは、コンテナ化された SQL Server インスタンスの高可用性に必要な条件です。
この記事では、Amazon EKS と、Amazon EBS ボリュームにバックアップされた Portworx クラウドネイティブストレージを使用して、本番環境で SQL Server ワークロードを実行する方法について説明します。デプロイプロセスを自動化し、SQL Server インスタンスを数分でデプロイできるようにするサンプルスクリプトを提供しました。
コンテナ内で SQL Server を実行することの利点
コンテナを使用することの最初のそして最も基本的な利点は、ソリューションの単純さと優雅さです。SQL Server をインストールしたり、フェイルオーバークラスターを設定したりする必要はありません。SQL Server コンテナは単一のコマンドでデプロイできます。Kubernetes は本来、SQL Server のデプロイに対して高可用性を提供します。場合によっては、Kubernetes にデプロイされたコンテナ内の SQL Server インスタンスの可用性が、フェイルオーバークラスターの上にデプロイされたワークロードの可用性よりもさらに高くなることがあります。詳細については、この記事の後半の「高可用性」のセクションを参照してください。
ただし、コンテナ内で SQL Server を実行することの主な利点は、高密度デプロイとリソース共有にあります。コンテナと仮想マシン (VM) の間の根本的な違いは、VM とは異なり、コンテナは実行されている間、一定量のリソースに制限されないことです。リソースの共有プールは、同じホスト上で並行して実行されているコンテナのグループにスローされることがよくあります。これにより、各コンテナは異なる時点でより多くの、またはより少ないリソースを消費することができます。総消費量がプールで利用可能なリソースの量より少ない限り、すべてのコンテナは必要なすべてのリソースを取得します。

上の図に示すように、100% の容量で実行されている VM は、同じホスト上で利用できるアイドル状態のリソースを使用することはできません。この例では、オンプレミスに 2 つの物理ホストがあり、8 つの CPU コアがあります。 3 つのアイドルコアが利用できるにもかかわらず、VM 4 と VM 7 はまだリソースに制約のある状態で実行されています。
それでは、利用可能なリソースをより有効に活用できる別の方法を考えてみましょう。物理ホストについてもう心配する必要がない世界を想像してください。代わりに、複数の SQL Server インスタンスなど、アプリケーションのグループを実行するために必要なすべての集合リソースを持つ仮想マシンのみをプロビジョニングできます。さらに、アプリケーションがこれらのリソースすべてを共有できるようにしながら、それらの間に競合がないようにすることもできます。Amazon EC2 インスタンスで実行されているコンテナを使用して、図の右側にこの代替方法を見ることができます。
このソリューションを使用すると、リソースに制約のあるコンテナがなくなり、全体のコア数が 8 から 6 物理コアに削減されます。同じ原則が利用可能メモリにも当てはまります。したがって、コンテナ化はインフラストラクチャの効率と有効性の両方を向上させることができます。これは、使用率が急上昇する SQL Server ワークロードに特に理想的です。
SQL Server をコンテナ内で実行することで見過ごされがちな利点は、ライセンス費用を削減する機会があることです。SQL Server は商用製品です。ライセンス条項によって課される使用制限により、純粋に技術的な観点から意思決定を妨げられたり、ビジネスコストを大幅に押し上げたりする可能性があります。Microsoft のライセンス条項が SQL Server コンテナに対して定義されている方法は、これらの問題を大幅に軽減することがあります。詳細については、この記事の後半の「SQL Server コンテナのライセンス」を参照してください。
Amazon EKS アーキテクチャ上の SQL Server
Kubernetes は、コンテナ化されたアプリケーションを大規模にデプロイおよび管理するために使用できるオープンソースソフトウェアです。これは、コンテナを実行および調整する、集中管理された分散システムです。
Kubernetes クラスターを利用できる場合は、それを使用してワークロードをデプロイするのはかなり簡単です。しかし、Kubernetes クラスター自体をデプロイして管理することが、新たな課題となる可能性があります。
Amazon EKS は、AWS で Kubernetes クラスターを実行する際の複雑さの数多くの部分を抽象化しています。Amazon EKS は、単一の AWS API を呼び出すことでプロビジョニングできる、完全マネージド型の Kubernetes コントロールプレーンを提供します。それに応じて、新しい Kubernetes クラスターに接続して使用できるようにするためのアップストリーム Kubernetes api-server エンドポイントを受け取ります。
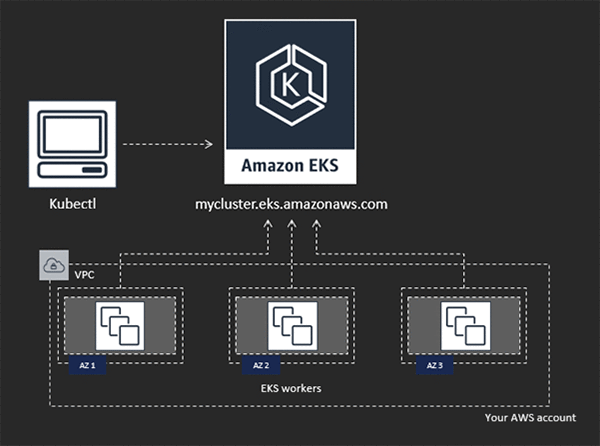
SQL Server は各ポッド内の単一のコンテナ (つまり、常に一緒に実行されるコンテナのグループ) としてデプロイされます。SQL Server の複数のインスタンスを複数のポッドとしてデプロイできます。Kubernetes は、実行に十分なリソースがあるクラスター内の任意のノードでこれらのポッドをスケジュールします。
Kubernetes で SQL Server を実行するには、Kubernetes デプロイを作成する必要があります。このデプロイにより、所有および管理される ReplicaSet が作成されます。ReplicaSet を使用すると、単一の SQL Server コンテナで構成される単一のポッドが常にクラスター上で実行されるようになります。もちろん、高密度を実現するために、同じクラスターに SQL Server の複数のインスタンスをデプロイすることもできます。
ストレージの消費量もストレージの作成から抽出されます。Kubernetes の場合、Persistent Volume (PV) は、ストレージソリューションの実装の詳細をカプセル化したオブジェクトです。これは、Amazon EBS ボリューム、ネットワークファイルシステム (NFS) の共有などのソリューションであるかもしれません。PV のライフサイクルは、それを使用するポッドのライフサイクルとは無関係です。
PV を消費するために、Persistent Volume Claim (PVC) と呼ばれる別のオブジェクトが作成されます。PVC は、特定のサイズとアクセスモード (読み取り/書き込み) のストレージを使用するためのリクエストです。PVC はストレージクラス値も指定できます。ストレージクラスは、レイテンシーや IOPS など、ストレージソリューションの他のプロパティを定義できるようにするためのもう 1 つの抽象概念です。
管理者は、AWS 汎用 GP2 EBS ボリューム、Portworx 高または中 I/Oボリュームなどの特定のストレージクラスを定義する必要があります。オペレーターは次に、そのストレージクラスに基づいて PV を作成したり、ユーザーが PVC に基づいて PV を動的に作成できるようにしたりします。アプリケーションには、PV を特定のポッドに割り当てる PVC を含めることができます。このプロセスを簡単にするために、デフォルトのストレージクラスを定義できます。たとえば、Amazon EBS General Purpose SSD (gp2) ボリュームが Kubernetes クラスターのデフォルトストレージクラスとして定義されているとします。PVC に特定のストレージクラスの注釈が含まれていなくても、Kubernetes は自動的にそれを AWS GP2 EBS ストレージクラスで注釈します。

ストレージオプション
ストレージは、SQL Server のデプロイにおける重要な部分です。AWS の SQL Server の最も一般的なストレージオプションは EBS ボリュームを使用することです。Kubernetes クラスターで EBS ボリュームを直接使用するために利用できるストレージクラスは 2 つあります。
SQL Server ファイルを EBS ボリュームに直接保存できます。ただし、多くの場合、単一の EBS ボリュームでは要件を満たすことはできないでしょう。たとえば、マルチ AZ アーキテクチャでの高可用性、単一の EBS ボリューム制限を超えるストレージ容量や、単一ボリュームで達成できるもの以上のスループットと IOPS が必要になる可能性があります。SQL Server Always On 可用性グループを使用して高可用性の問題に対処することはできますが、ボリューム、IOPS、およびスループットの問題は解決されません。また、SQL Server コンテナの Always On 可用性グループ機能は、現在 SQL Server 2019 でプレビューされています。
複数の EBS ボリュームを 1 つのストレージプールに結合し、各 EC2 インスタンスのボリュームをストライピングし、別々のアベイラビリティーゾーンの複数のインスタンスにまたがってストレージプールを拡張することで、これらすべての要件 (高可用性、ボリューム、IOPS、スループット) を満たすことができます。別のストレージクラスターを実装してから、NFS ストレージクラスを介して Kubernetes クラスターで使用できます。しかし、これらすべてにより複雑さとオーバーヘッドが増大してしまいます。
Portworx クラウドネイティブストレージ
Portworx は、Kubernetes クラスターでのアプリケーションとデプロイに役立つストレージクラスタリングソリューションです。さらに、Portworx 自体が Kubernetes 上に配置されています。言い換えれば、Portworx は Kubernetes の力を利用して、ストレージクラスター管理の複雑さをすべて取り除きます。Kubernetes クラスターのステートフルアプリケーションで使用可能な単純なストレージクラスを提供します。
AWS では、Portworx は Kubernetes クラスターのワーカーノードにアタッチされている EBS ボリューム (EC2 インスタンス) を要求することによってこれを行います。次に、それらのボリュームすべてを抽象ストレージプールに入れ、そのプールから論理ボリュームを切り出します。SQL Server のようなアプリケーションが Portworx ストレージクラスで PVC を作成し、ボリュームサイズを指定すると、指定されたサイズの Portworx PV がアプリケーションに割り当てられます。
Portworx は 3DSnaps という名前のライブスナップショットを作成することもできます。この機能により、SQL Server を停止したり読み取り専用モードにしたりすることなく、SQL Server ボリュームから一貫してスナップショットを作成できます。Portworx のもう 1 つの便利な機能は、既存の EBS ボリュームを Portworx 論理クラスターボリュームにインポートできることです。これにより、既存のワークロードの移行が容易になります。また、Portworx では、クラスターを高密度にすることができます。つまり、ホストごとに多数のコンテナを実行できるということです。Kubernetes の推奨は、VM あたり 100 ポッドです。Portworx の顧客の中にはホストごとに 200〜300 のポッドを実行している顧客もいます。
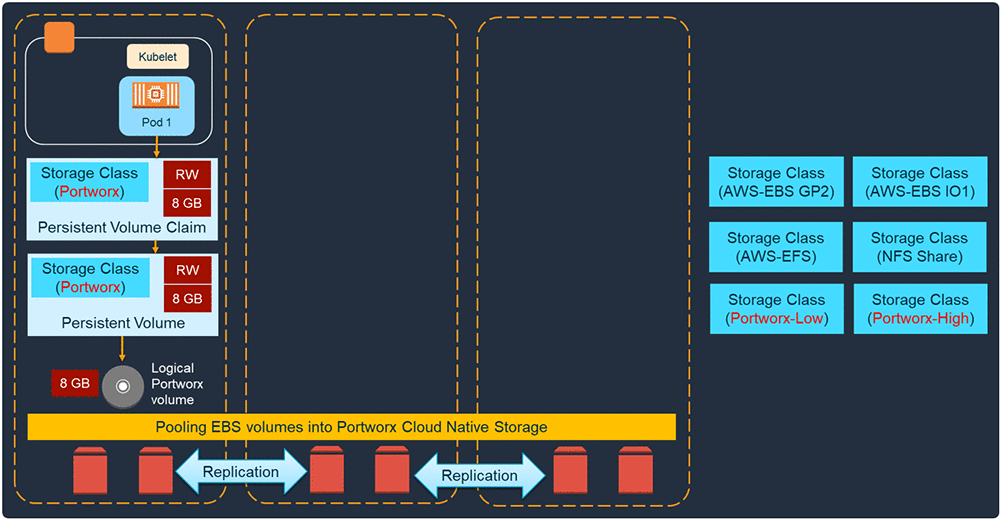
Portworx は、EBS ボリュームの上に独自のきめ細かいスナップショットレイヤーを使用します。
Portworx スナップショットの作成と復元は瞬時に行われます。これは、Portworx スナップショットが書き込み直書きスナップであるためです。本質的に、Portworx はブックマークを介して瞬時にボリュームのポイントインタイムスナップショットを作成することができます。実際のストレージブロックはコピーされないので、取られるスナップの量にかかわらず書き込みペナルティはありません。パフォーマンスを低下させることなく、15 分ごとに頻繁に新しいスナップを取ることができます。これらはすべて、複数の EBS ボリュームにまたがって、クラスター全体で、そしてアプリケーションと一貫性のあるビューで行われます。
Portworx は仮想ボリュームのサイズ変更を可能にします。この機能を EBS エラスティックボリュームと組み合わせて使用すると、ストレージを動的に拡張または縮小し、オーバープロビジョニングに伴う余分なコストを回避できます。本来 Portworx スナップショットは余分なスペースを消費しません。これは、Portworx が同じブロックの複数のバージョンのデータを追跡できる B ツリーベースのファイルシステムを使用した場合の基になるストレージ方式が、リダイレクト書き込みであるためです。したがって、これらのスナップショットのスペース効率は非常に良好です。
Portworx クラウドスナップショットポリシーを使用して、すべてのスナップを自動的に Amazon Simple Storage Service (S3) バケットにアップロードし、ローカルスナップショットをクリーンアップできます。この機能は、EBS ボリュームスペースが残りのスナップショットによって消費されるのを防ぐのに役立ちます。Portworx には、指定された数のスナップショットを保持できるローカルスナップショット保存ポリシーもあります。このポリシーはボリュームごとに設定でき、ボリュームの作成時に動的に設定したり、後で更新したりできます。Amazon S3 は、99.999999999% の耐久性を提供するオブジェクトストレージサービスです。Amazon S3 にアップロードされる Portworx スナップショットには、単なるブックマークではなく実際のストレージブロックが含まれています。したがって、データ損失に対する保護のもう 1 つの層として機能できます。
ローカルスナップショットの場合、復元操作は瞬時に行われます。cloudsnaps では、Portworx は snap-diff を Amazon S3 バケットに格納するだけなので、復元操作はまだ瞬間的である可能性があります。
パフォーマンスと待ち時間の観点から、Portworx 論理ボリュームへは各ポッドがローカルにアクセスします。バックグラウンドでは、Portworx が他のアベイラビリティーゾーンの他のワーカーノードにブロックを複製します。これにより、別のアベイラビリティーゾーンにフェイルオーバーしたポッドがすぐに再びローカルでデータにアクセスしてその操作を再開できるようになります。
Portworx には、AWS で数百テラバイトのデータを使用して、Cassandra や Elasticsearch のような大規模なデータベースを正常に運用している顧客がいます。これらの顧客は、Portworx を EBS 上で実行することによるコスト上の利点を認識しています。Portworx が提供するすべての機能について詳しくは、Portworx のウェブサイトにある機能を参照してください。
これまで、SQL Server ワークロードをホストするための信頼性の高い柔軟なソリューションとして、Amazon EKS と Portworx ストレージを併用する方法について説明してきました。次のセクションでは、SQL Server を Amazon EKS に実際にデプロイするのに役立ついくつかの手順について説明します。これらの手順を使用して、このソリューションをすばやく展開し、自分の環境で検証することができます。
前提条件
このソリューションは PowerShell スクリプトに基づいています。Windows PowerShell と PowerShell Core の両方で実行できます。Windows 10 または Windows Server 2016 でスクリプトを実行する予定の場合は、既存の Windows PowerShell を使用できます。このスクリプトは MacBook や Linux マシンでも実行できます。そのためには、まずターゲットデバイスに PowerShell Core をインストールする必要があります。 あるいは、Mac ユーザーは ReadMe ファイルの指示に従って、すべての前提条件を含むローカルの Docker コンテナをデプロイすることもできます。
スクリプトは AWS Tools for PowerShell で使用できる PowerShell コマンドレットを呼び出します。お使いのマシンに AWS Tools for Windows PowerShell または AWS Tools for PowerShell Core のいずれかの最新バージョンがインストールされていることを確認してください。
このスクリプトは、Amazon EKS API を呼び出すために AWS Command Line Interface (AWS CLI) ツールに依存することがあります。最新の AWS CLI がインストールされていることを確認してください。
最後に、このスクリプトを実行するには、AWS アカウントで必要な権限を持っていることが必要です。これには、AWS CloudFormation テンプレートの実行、Virtual Private Cloud (VPC)、サブネット、セキュリティグループ、および EC2 インスタンスの作成、EKS クラスターのデプロイとアクセスが含まれます。コンピューター上で一対の長命のプログラミングキーを持つ IAM ユーザーを使用することができます。この場合、PowerShell と AWS CLI の両方で、プログラミングキーを使用して AWS プロファイルを有効にする必要があります。
あるいは、スクリプトを実行する EC2 インスタンスに必要なすべての特権が割り当てられた IAM ロールを使用することもできます。このオプションを使用すると、それ以上の設定は不要で、AWS PowerShell ツールと AWS CLI の両方が EC2 インスタンスメタデータから一時的な認証情報を自動的に取得します。
オプションで、パッケージには Dockerfile が含まれています。この Dockerfile により、スクリプトと上記のすべての依存関係 (AWS CLI、AWS コマンドレットなど) が直接 microsoft/powershell Docker イメージに組み込まれます。つまり、Docker がインストールされていれば、macOS、Linux、Windows のいずれの環境でも、docker run を使用して環境をセットアップできます。
Amazon EKS への SQL Server のデプロイ
付属のスクリプトを実行して必要なパラメータを渡すことで、SQL Server をデプロイできます。このスクリプトには多数のパラメータが含まれていますが、それらのほとんどには、初めてのユーザーが簡単に使用できるようにデフォルト値が定義されています。同じパラメータを使用してスクリプトを複数回実行しても安全です。基礎となるリソースがすでに存在するかどうかを確認し、利用可能な場合はそれらを再利用します。
スクリプトが実行するステップのリストを次に示します。
- まず、Amazon EKS の IAM サービスロールが作成されます。このロールは、EKS がお客様に代わって AWS に必要なリソースをプロビジョニングできるようにするために必要です。
- クラスターを実行するための VPC が必要です。スクリプトは AWS CloudFormation VPC スタック名をパラメータとして受け取ります。スタックがすでに存在する場合は、同じスタックを再利用します。それ以外の場合は、AWS が提供するテンプレートから新しいスタックを作成します。スタックには、クラスターの実行に必要な VPC、サブネット、およびセキュリティグループが含まれています。
- kubectl と呼ばれるクライアントツールを介して Kubernetes を設定しやり取りします。このスクリプトは AWS のキュレーションバージョンである kubectl をダウンロードして、それをローカルコンピューターにインストールします。
- kubectl を使用して Amazon EKS をクエリすると、AWS PowerShell ツールで使用しているのと同じ AWS 認証情報が Amazon EKS に渡されます。このタスクは、スクリプトがダウンロードおよびインストールする aws-iam-authenticator という別のツールによって実行されます。
- 新しい EKS クラスターが作成されます。EKS クラスターは、3 つの AWS アベイラビリティーゾーンにある 3 つのマスターノードの管理セットで構成されています。
- 前の手順で作成した EKS クラスターと接続されるように kubectl を設定します。
- 新しい EC2 インスタンスを起動し、EKS クラスターとワーカーノードに連結するように設定します。
- Portworx が通信するための Etcd クラスターを起動します。
- 次に DaemonSet の仕様をダウンロードし、それを EKS クラスターに適用します。これにより、Portworx クラウドネイティブストレージに GP2 および IO1 EBS ボリュームが自動的にインストールされ、ユーザーはどちらか一方または両方を選択できます。
- EKS クラスター内に 3 の複製係数を持つ Portworx ボリュームのストレージクラスを作成します。これは、Kubernetes が SQL Server ポッドを別のアベイラビリティーゾーンに再スケジュールした場合でも、ホストの障害時に高可用性の SQL Server クラスターを維持する方法です。
- EKS クラスター内に gp2 EBS ボリューム用のストレージクラスを作成します。
- EKS クラスター内に新しい Persistent Volume Claim (PVC) を作成します。PVC により、Portworx は、基礎となる Amazon EBS ボリュームを基にして Persistent Volume (PV) をプロビジョニングできます。
- SQL Server SA ユーザーのパスワードを入力するように求められます。既定の SQL Server SA パスワードポリシーに準拠した強力なパスワードを入力します。スクリプトは EKS クラスター内でこのパスワードを秘密として保存します。
- その後、SQL Server のデプロイを作成します。デプロイにはレプリカセットが含まれており、レプリカセットによって Kubernetes ポッドが作成されます。ポッドは、SQL Server を実行する単一のコンテナで構成されています。PVC コンテナはこのコンテナにマウントされ、SA パスワードを使用してスピンアップします。
- 最後に、接続文字列で SQL Server インスタンスに接続するために使用できるエンドポイント名が出力されます。
スクリプトを 1 回実行すると、EKS クラスターとその上に単一の SQL Server インスタンスがデプロイされます。同じスクリプトを再度実行して appName パラメータに異なる名前を渡すことで、同じ EKS クラスターに SQL Server の追加インスタンスをデプロイできます。
高可用性
このスクリプトは、マルチ AZ Kubernetes クラスターと、Portworx ボリュームで強化されたストレージクラス (SC) を使用して SQL Server をデプロイします。Portworx による保護と SQL Server コンテナ内でのデータの複製のおかげで、デプロイは以下に対して回復力があります。
- コンテナ障害
- ポッドの失敗
- EC2 インスタンスの失敗
- EC2 ホスト障害
- EBS ディスク障害
- EC2 ネットワークパーティション
- AWS アベイラビリティーゾーンの失敗
コンテナまたはポッドが失敗した場合、Kubernetes はすぐに別のコンテナまたはポッドをスケジュールします。Kubernetes ポッドが別のアベイラビリティーゾーンに再スケジュールされても、Portworx はアベイラビリティーゾーンにまたがってデータを自動的に複製するため、データの損失を被ることはありません。
前のセクションで、Portworx の複製係数が 3 に設定されていることに触れました。つまり、Portworx では、プライマリ PV に加えて、いつもクラスター内の他の場所に PV のコピーを 2 つ維持しています。Amazon EBS ボリュームは単一のアベイラビリティーゾーン内でのみ高可用性を実現するため、デフォルトでは、Portworx はこれらのレプリカを複数のアベイラビリティーゾーンに分散させます。大きな改善点は、オンプレミスにデプロイすると、通常、SQL Server フェイルオーバークラスタリングインスタンス (FCI) が単一のデータセンターにデプロイされる点です。ただし、ここでは Kubernetes と Portworx のクラスターが複数のアベイラビリティーゾーンにまたがっています。したがって、可用性と回復力のレベルははるかに高くなります。
Portworx のようなクラスター化されたストレージの上で Kubernetes で SQL Server コンテナを実行することは、複数のアベイラビリティーゾーンにまたがっている Storage Spaces Direct クラスタの上で SQL Server Always On FCI を実行することと似ています。結果として、ゼロの目標復旧ポイント (RPO) と 10 分以内の目標復旧時間 (RTO) が得られ、主要なアベイラビリティーゾーンの障害に対する回復力が備わります。違いは、EKS でコンテナを実行する方が、Windows Server Failover Cluster 上で SQL Server を設定して維持するよりもさらに簡単だということです。
SQL Server Standard エディションを実行している場合は、従来のWindows のデプロイとは異なり、コンテナと Amazon EKS を使用してより高いレベルの可用性を実現することも可能です。これは、SQL Server Standard エディションの FCI は最大 2 ノード (つまり 1 つのセカンダリノード) に制限されているためです。ただし、コンテナは任意の数のノードで構成されるクラスターにデプロイできます。Enterprise エディションの SQL Server Always On FCI は、2 ノードを超えることがあります。ただし、ライセンス契約によっては、追加インスタンスごとにライセンスを取得する必要があります。これはコンテナには当てはまりません。クラスター内のスタンバイインスタンスの数に関係なく、1 つのコンテナに対してのみ支払います。
Always On 可用性グループで SQL Server コンテナをデプロイすることもできます (現在 SQL Server 2019 でプレビュー中)。このような設定は、参加している各ノード自体が Always On FCI クラスターである Always On 可用性グループをデプロイするのと似ています。ただし、Always On 可用性グループと FCI の面倒な制限のいくつかは、コンテナに課されなくなりました。たとえば、可用性グループの 1 つのノードからセカンダリへの自動フェイルオーバーや、各ノードに個別の FCI を設定することの複雑さなどの制限があります。
SQL Server コンテナのライセンス
SQL Server 2017 Licensing Datasheet によると、「SQL Server 2017 は仮想マシンとコンテナの使用権を提供し、顧客のデプロイに柔軟性を提供します。SQL Server 2017 の仮想マシンとコンテナには、2 つの主要なライセンスオプションがあります — 個々の仮想マシンおよびコンテナのライセンスを取得する機能と、高度に仮想化または高密度のコンテナ環境で最大密度のライセンスを取得する機能です」。
SQL Server ワークロードのコンテナ化によりライセンスコストを削減する機会があります。特定のシナリオでは、必要なライセンス数を減らすために、コンテナごとのライセンスモデルと物理ホストごとのライセンスモデル (高密度) の両方を適用できます。
EC2 インスタンス上で複数のアプリケーションを実行していて、それらのアプリケーションと同じホスト上で SQL Server を並行して実行する場合は、コンテナ単位のライセンスを使用できます。コンテナがないと、EC2 インスタンスを含む仮想マシンで SQL Server を直接実行する場合、その VM で利用できるすべての vCPU のライセンスを取得する必要があります。これは、実際に SQL Server で使用されている vCPU の数には関係しません。ただし、同じ VM 上のコンテナで SQL Server を実行している場合は、コンテナからアクセスできる vCPU の数を制限できます。アクセス可能なコアの数だけライセンスを取得できます。これは、最小 4 コアの 2 コアの増分、つまり 4、6、8・・・コアになります。
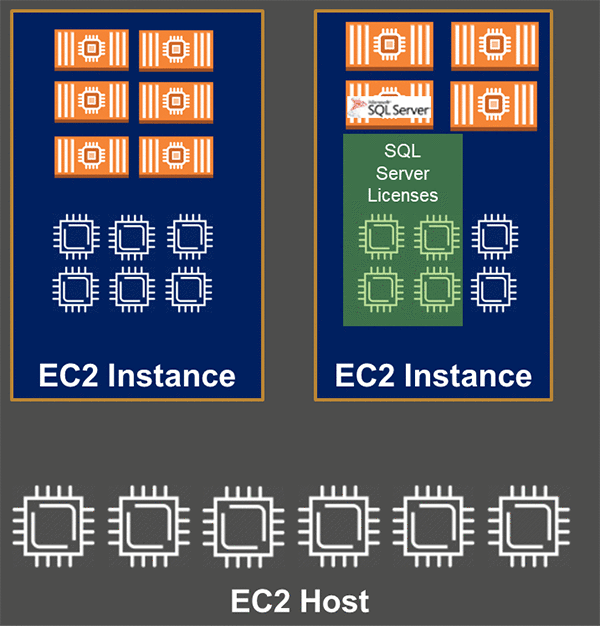
使用率の高いパターンを持つ一連の SQL Server インスタンスがある場合は、コンテナを使用してこれらを高密度で実行できます。この場合は、物理ホストごとのライセンスモデルを選択する必要があります。すべての物理コアが適切にライセンスされている限り、物理コア上で無制限の数のコンテナと任意の数の vCPU を実行できます。

前の図には、12 の vCPU コアと 20 のコンテナがあります。しかし、これらはすべて 6 つの物理コア上で実行されているため、必要なコアライセンスは 6 つだけです。これは、オンプレミスの SQL Server 仮想マシンをオーバープロビジョニングしている企業にとって特に便利です。EC2 インスタンスは、1 物理コアあたり 2 vCPU という固定ハイパースレッディング率を持っています。そのため、3:1、4:1、5:1 またはそれ以上の比率でオーバープロビジョニングされたワークロードを EC2 インスタンスに直接移動すると、問題を回避するための総コストが高くなります。コンテナ化はその問題を解決するだけでなく、結果を改善する可能性もあります。
Portworx ライセンス
Portworx は補完的なライセンスモデルで高密度コンテナ環境をサポートします。Kubernetes 自体は、ノードあたり最大 100 個のポッドを推奨しています。理論的には、EC2 インスタンスあたり最大 100 個の SQL Server ポッドを実行でき、SQL Server ライセンス数を大幅に節約できます。Portworx は、実行されているコンテナの数や消費するストレージの量に関係なく、EC2 インスタンスあたり 1 つのライセンスしか必要としません。つまり、密集したクラスターでは、あるライセンスを別のライセンスと交換するだけではありません。実際、ホストごとに実行する SQL Server が多いほど、平均ライセンス費用を節約できます。Portworx は、クラスターあたり数千のノードと、ノードあたり数百のステートフルコンテナをサポートします。
SQL Server コンテナを使用しない場合
現在リリースされている機能では、すべての SQL Server ワークロードをコンテナ化できるわけではありません。まず第一に、SQL Server コンテナは現在 SQL Server 2017 でのみ利用できます。SQL Server の古いバージョンはコンテナ化できません。ただし、SQL Server 2017 は、SQL Server 2008 以降のすべてのバージョンと下位互換性があります。つまり、SQL Server 2008 以降で作成されたデータベース (コンテナ内で実行されるものも含む) を SQL Server 2017 のインスタンス内で復元し、互換モードで実行することができます。
さらに、Linux の SQL Server は Microsoft Active Directory との統合をサポートしていますが、SQL Server コンテナは現在 Active Directory との統合をサポートしていません。
SQL Server で一般的に使用されている機能は、Always On 可用性グループを通じて利用できる、水平方向の読み取りスケーリング機能です。この機能は現在プレビューとしてコンテナで利用でき、本番環境では使用できません。
クラウドによってもたらされる最も高く評価される可能性があるサービスの 1 つは License Included サービスです。多くの企業にとって、実際のソフトウェア消費量に対して調達したライセンスを管理するのは面倒なオーバーヘッドです。決して使用しないものに対して支払うか、またはベンダーの使用条件の不遵守という形で、矛盾につながることもあります。SQL Server コンテナは、ライセンス持ち込み (BYOL) モデルでのみ使用できます。したがって、決定を下す前にライセンス管理の負担を考慮する必要があります。
Distributed Transaction Coordinator (DTC) やカスタム CLR ユーザータイプなど、現在使用できない機能も他にいくつかあります。SQL Server のワークロードの性的リソースの使用パターンがかなり一貫している場合は、従来のデプロイモデルの方が信頼性が高いと感じるかもしれません。
結論
この記事では、Portworx と一緒に SQL Server をコンテナ内で実行することを検討すべき理由と、このアプローチの長所と短所について説明しました。
この方法には次のような利点があります。
- 簡単で、管理上の負担を軽減するのに役立つ
- それを必要とする作業負荷にアイドル状態のリソース容量を解放することによって、アプリケーションのパフォーマンスを向上させることができる
- デプロイのデータ保護とフェイルオーバー機能を向上させることができる
- インフラストラクチャのコストを削減できる
- SQL Server のライセンスコストを削減できる
この記事では、Portworx を使用して SQL Server を Amazon EKS にデプロイするのがいかに簡単かを説明しました。AWS API を呼び出す単純なスクリプトを使用して、インフラストラクチャと EKS クラスターをプロビジョニングし、SQL Server コンテナを実行できます。特定の要件に基づいて、主に次の 2 つのストレージオプションから選択できます。
- 個々の EBS ボリュームを PVC として使用して、単一のアベイラビリティーゾーンで高可用性を提供し、最小限のストレージコストで済ませるオプション
- 複数のアベイラビリティーゾーンにまたがって Portworx などのクラスター化されたストレージソリューションを使用して、アベイラビリティーゾーンの障害に対して回復力のあるレベルの高可用性を提供するオプション
著者について
 Sepehr は 現在 AWS のシニアソリューションアーキテクトです。彼のキャリアは .Net 開発者として 10 年以上働いたところからスタートしました。彼は初期の頃からすぐにクラウドコンピューティングのファンになり、お客様が AWS で Microsoft の技術を活かすのを手助けすることが大好きです。彼にとって妻と娘で人生で最も大切な部分で、さらにもうすぐ 2 人目の赤ちゃんが生まれる予定です。
Sepehr は 現在 AWS のシニアソリューションアーキテクトです。彼のキャリアは .Net 開発者として 10 年以上働いたところからスタートしました。彼は初期の頃からすぐにクラウドコンピューティングのファンになり、お客様が AWS で Microsoft の技術を活かすのを手助けすることが大好きです。彼にとって妻と娘で人生で最も大切な部分で、さらにもうすぐ 2 人目の赤ちゃんが生まれる予定です。
 Ryan Wallner は Portworx の テクニカルアドヴォケイトで、Kubernetes コンテナストレージエコシステムに注力しています。以前は、Athenahealth で DC/OS にマイクロサービスプラットフォームを構築するテクニカルメンバーで、さらにその前は、ClusterHQ および EMC の CTO オフィスで働いていました。彼は Flocker、Amazon ECS Agent、BigSwitch Floodlight、Kubernetes や Docker-py を含む様々なオープンソースプロジェクトに貢献してきました。
Ryan Wallner は Portworx の テクニカルアドヴォケイトで、Kubernetes コンテナストレージエコシステムに注力しています。以前は、Athenahealth で DC/OS にマイクロサービスプラットフォームを構築するテクニカルメンバーで、さらにその前は、ClusterHQ および EMC の CTO オフィスで働いていました。彼は Flocker、Amazon ECS Agent、BigSwitch Floodlight、Kubernetes や Docker-py を含む様々なオープンソースプロジェクトに貢献してきました。