Amazon Web Services ブログ
Amazon Kinesis Data Streams および AWS Lambda を使用して、Amazon RDS for PostgreSQL の変更をストリーミングする
この記事では、Amazon Relational Database Service (Amazon RDS) for PostgreSQL 中央データベースを、Amazon Kinesis Data Streams にその変更をストリーミングすることで、他のシステムと統合する方法について説明します。以前の記事、「Amazon Kinesis を使用したデータベースの変更をストリーミングする」では、変更を Kinesis へストリーミングすることによって、MySQL データベース用の中央 RDS を他のシステムに統合する方法についてお話ししました。この記事では、さらに進んで、AWS Lambda 関数を使用して Amazon RDS for PostgreSQL の変更をキャプチャし、その変更を Kinesis Data Streams にストリーミングする方法を説明します。
次の図は、分散システムにおける一般的なアーキテクチャ設計を表しています。これには、信頼できる唯一の情報源と呼ばれる中央ストレージと、この中央ストレージを使用するいくつかの派生「サテライト」システムが含まれます。
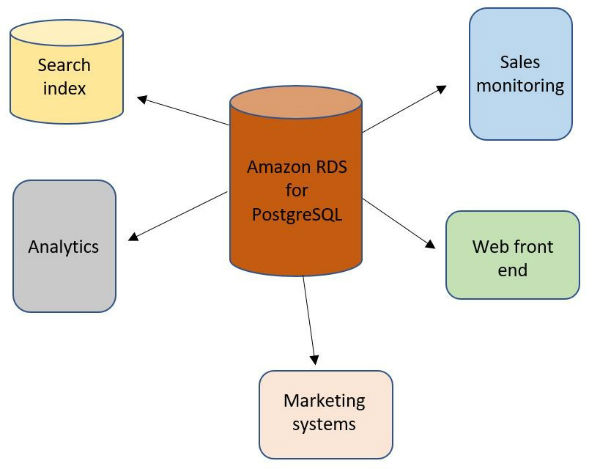
この設計アーキテクチャーを用いて、データの整合性を維持するためにこのシステムのトランザクション機能を活用しながら、リレーショナルデータベースを中央データストアとして使用することができます。このコンテクストにおいての派生システムとは、全文検索システムであり、この信頼できる唯一の情報源の変更を観察し、それらの変更を変換かつフィルタリングし、最終的にその内部インデックスを更新するものです。もう 1 つの例は、OLAP クエリにより適したカラムナストレージです。一般に、中央リレーショナルシステムの個々の行が変更された時にアクションを実行する必要があるシステムはどれも、派生データストアにするのに適しているとい言えます。
この種のアーキテクチャの単純な実装では、変更された行を検索するために定期的にクエリを発行する派生システムがあります。これは基本的に SELECT ベースのクエリ (バッチ処理システムとも呼ばれます) で中央データベースをポーリングします。一方で、このアーキテクチャにより適した実装は、非同期の更新ストリームを使用するアーキテクチャです。
データベースには通常、行のすべての変更が格納されるトランザクションログがあります。ですので、この変更のストリームが外部のオブザーバシステムに公開されている場合、このシステムはこれらのストリームに接続し、行の変更を処理およびフィルタリングできる可能性があります。 この記事では、PostgreSQL を中央データベースとして、また Kinesis Data Stream をメッセージバスとして使用して、この基本的な実装を紹介します。
通常、PostgreSQL Write-Ahead Logging (WAL) ファイルは、マスター上のすべての変更を読み込んだ後、ローカルに適用するリードレプリカに公開されます。リードレプリカからデータを読み取る代わりに、wal2json 出力プラグインを用いた論理デコードを使用して、WAL の内容を直接デコードします。プラグインはこの GitHub リポジトリからダウンロードできます。論理デコードとは、データベースのテーブルに対するすべての持続的な変更を、一貫性がありかつ分かりやすい形式に抽出するプロセスのことです。この形式だと、データベースの内部状態を詳細に把握していなくても解釈することが可能です。
PostgreSQL WAL ログの RDS からの変更を継続的に読み取って、変更を Kinesis Data Streams にプッシュするには、AWS Lambda 関数を使用します。上位レベルでは、エンドツーエンドプロセスは次のようになります。
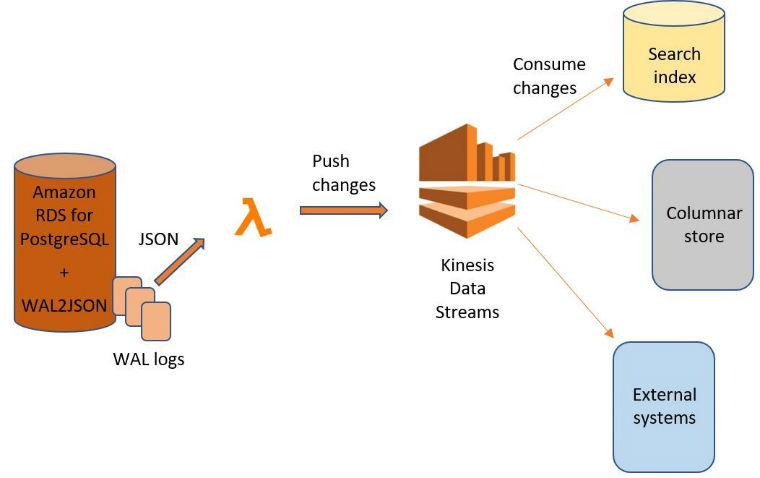
このメソッドの重要な点の 1 つは、コンシューマーが SQL クエリを受け取らないことです。それらは公開される可能性もありますが、一般に、SQL 互換のデータのレプリカを維持しない限り、オブザーバは SQL にあまり関心がありません。代わりに、変更された複数のエンティティ (複数行) をそれぞれ受け取ります。
このアプローチの利点は、コンシューマーは SQL を理解する必要がなく、信頼できる唯一の情報源は誰が変更を使用するかを知る必要はないということです。つまり、異なるチームが、チーム間で連携して必要なデータ形式に対処することなく、作業できることを意味します。さらに良いのは、Kinesis Data Streams クライアントが特定の時点から読み取る機能を備えているため、各コンシューマーは独自のペースでメッセージを処理できることです。ですので、メッセージバスは、システムを統合するのにあまり利用されていない方法なのです。
この記事で使用されている例では、行フェッチャーは中央データベースに接続する通常の Python プロセスであり、リードレプリカをシミュレートします。データベースは、Amazon RDS か、PostgreSQL の任意のインストールのいずれかです。Amazon RDS の場合、RDS インスタンスホストにカスタムソフトウェアをインストールすることができないため、フェッチャープロセスを別のホスト (例えば、Amazon EC2、または Lambda 関数) にインストールする必要があります。外部インストールの場合、フェッチャープロセスをデータベースと同じホストにインストールできます。
マスター PostgreSQL インスタンスを準備する
PostgreSQL マスター (信頼できる唯一の情報源) を、通常のレプリケーションのマスターであるように設定する必要があります。WAL ログを有効にする必要があります。つまり、RDS for PostgreSQL の場合、バックアップを有効にするだけです。また、Amazon RDS の PostgreSQL 論理レプリケーションは、新しいパラメータ、新しいレプリケーション接続タイプ、および新しいセキュリティロールによって有効になります。レプリケーションのクライアントは、PostgreSQL DB インスタンス上のデータベースへのレプリケーション接続を確立できる任意のクライアントです。詳細については、「Amazon RDSのPostgreSQL の論理レプリケーション」を参照してください。
論理レプリケーションスロットは、ストリームのレシーバーについて何も分かっていません。よって、論理レプリケーションスロットを設定してスロットから読み取らないと、データが DB インスタンスのストレージに書き込まれ、ストレージがすぐにいっぱいとなる可能性があります。PostgreSQL の論理レプリケーションの最も一般的なクライアントは、AWS Database Migration Service (AWS DMS) または Amazon EC2 インスタンス上のカスタム管理ホストです。例えば、AWS DMS タスクを構成していて、変更を積極的に使用しない場合、DB サーバー上のストレージがいっぱいとなる可能性があります。
Amazon RDS PostgreSQL DB インスタンスの論理レプリケーションを有効にするには、次の操作を行う必要があります。
- Amazon RDS 上にある PostgreSQL データベースの論理レプリケーションを開始する AWS ユーザーアカウントに、
rds_superuserとrds_replicationがあることを確認します。Rds_replicationロールは、論理スロットを管理し、論理スロットを使用してデータをストリーミングする権限を与えます。 Rds.logical_replicationパラメータを 1 に設定します。これは静的パラメータで、実行には再起動が必要です。このパラメータを適用するには、wal_level、max_wal_senders、max_replication_slots、およびmax_connectionsパラメータを設定します。これらのパラメータ変更は WAL 生成を増加させる可能性があるので、rds.logical_replicationパラメータは論理スロットを使用している時にのみ設定する必要があります。 注 :
注 :
- デフォルトの
wal_levelは REPLICA です。 Rds.logical_replicationを 1 に設定すると、wal_levelが LOGICAL に設定されます。
- デフォルトの
- 論理レプリケーションスロットを作成し、デコードプラグインを選択します。この例では、
wal2jsonを使用して、次の手順に示すように、Python を用いてレプリケーションスロットを作成します。
DB インスタンスを変更する
新しいパラメータグループを使用するようにインスタンスを変更した後、インスタンスには「pending reboot」と表示されます。再起動して、新しいパラメータグループを有効にする必要があります。インスタンスを再起動したら、次のように新しいパラメータを確認できるはずです。
RDS DB インスタンスの変更についての詳細は、「PostgreSQL データベースエンジンを実行している DB インスタンスの変更」を参照してください。
データベースユーザーに権限を追加する
Amazon RDS によって作成されたデフォルトの master ユーザーを使用している場合は、すでに必要な権限を持っている可能性があります。そうでない場合は、次の例のように、REPLICATION 権限を持つユーザーを作成する必要があります。
Kinesis データストリームを作成する
Kinesis データストリームと boto3 クライアントの認証情報が必要です。クライアントの認証情報については、Boto 3 ドキュメントを参照してください。AWS CLI または Amazon Kinesis コンソールのどちらかを使用して、データストリームを作成できます。
次の AWS CLI コマンドを使用して、Kinesis データストリームを作成します。
または、Amazon Kinesis コンソールを開き、ナビゲーションペインで [データストリーム] を選択します。次に、[Kinesis ストリームの作成] を選択します。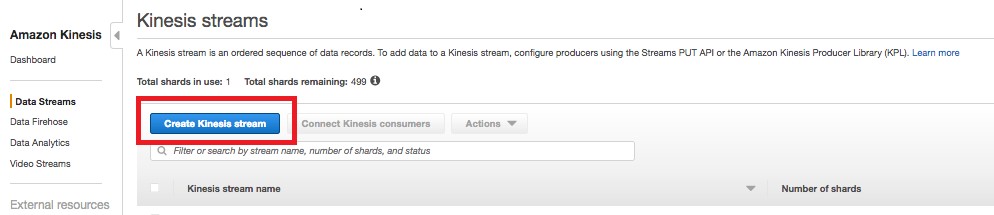
ストリームの名前とシャードの数を入力します。この例では、シャードが 1 つあります。
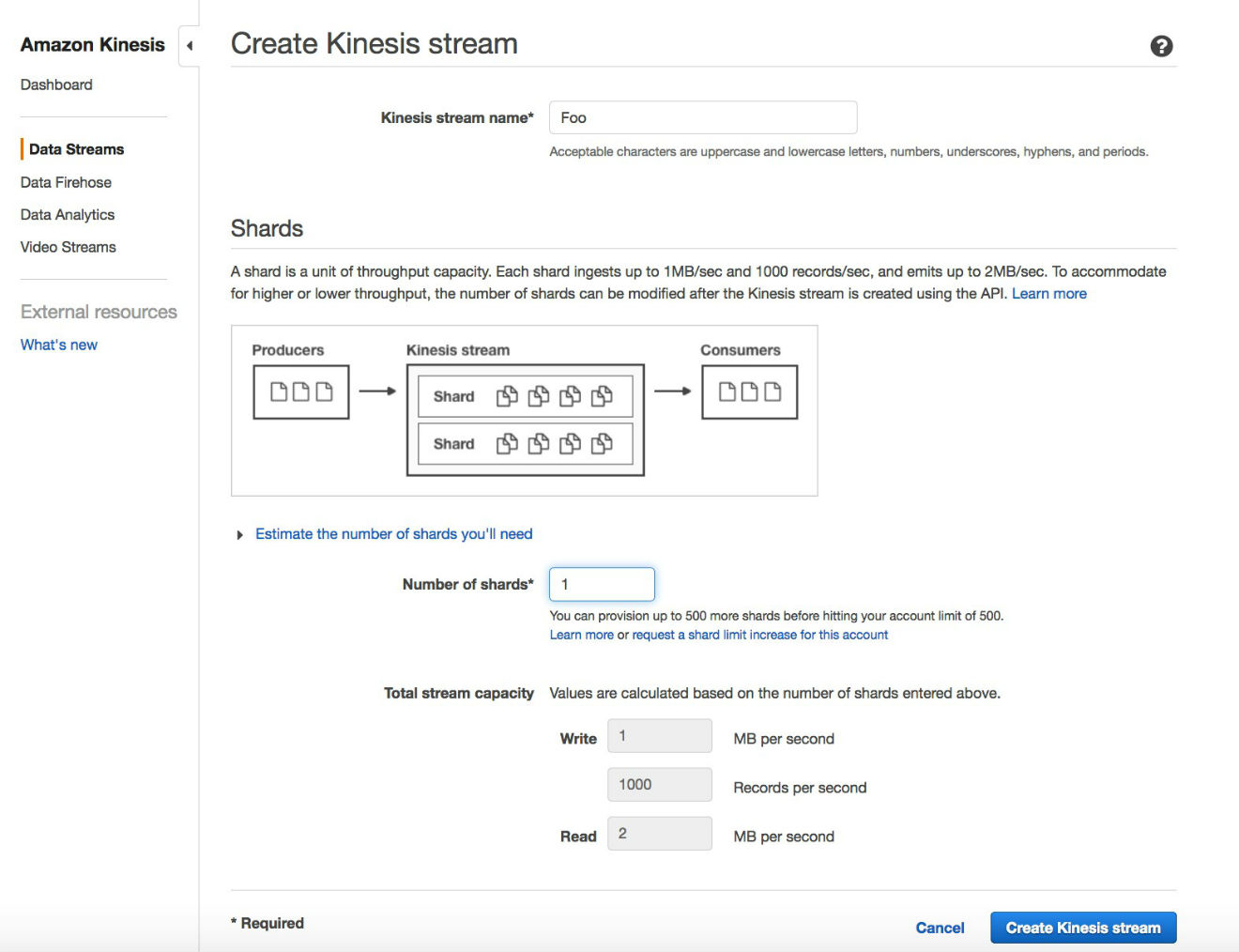
数分後には、ストリームは行の変更を受け入れる準備ができているはずです!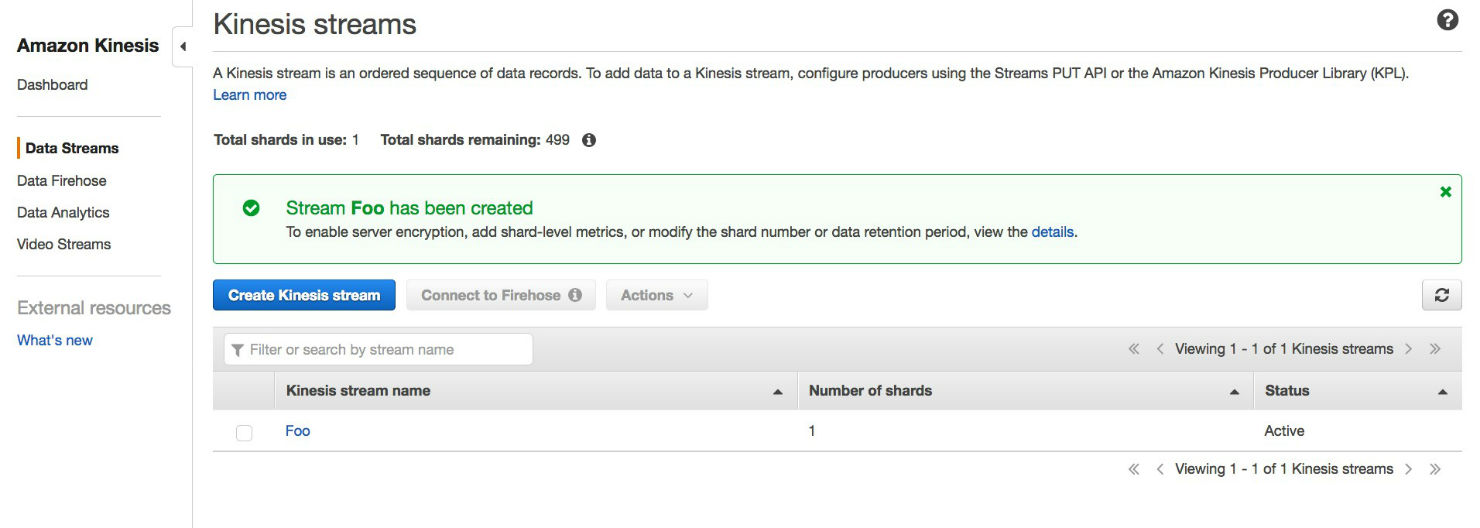
AWS CLI ユーザーに権限を割り当てる
AWS Identity and Access Management (IAM) を使用して、このストリームにアクセスする CLI ユーザーに権限を付与できます。

この例では、権限のあるユーザーは kinesis-rds-user です。新しいユーザーを作成したり、既存のユーザーを使用することはできますが、Kinesis データストリームへの書き込み権限を追加する必要があります。
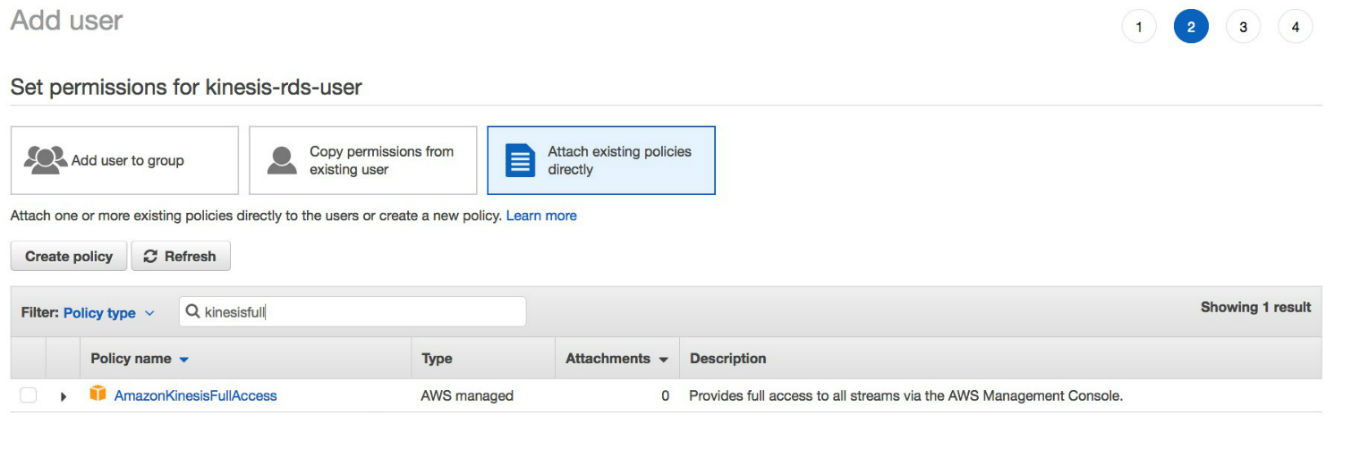
ストリームに固有のポリシーを作成できます。この例では、Kinesis データストリームに完全にアクセスできる標準ポリシーを使用しています。
メッセージを Kinesis データストリームに公開する
WAL ログからの変更を読み込んで、Amazon Kinesis に公開するには、次のいずれかを使用します。
- アクセスキー ID とシークレットアクセスキーを持つ Amazon EC2 マシン
- IAM ロールのある Lambda 関数
ここでは、シンプルな Python プログラムを使って、上記 2 つの方法を紹介します。ただし、この例はテストコードであり、本番に対応していないことに注意してください。
オプション 1: Amazon EC2 マシンを使用する
EC2 マシンを kinesis-rds-user の AWS アクセスキー ID と、以前の投稿で作成した AWS シークレットアクセスキーを用いて使用するには、次のように認証情報を設定します。
この Python コードを使用する :
注 : オプションの print(msg.payload) を使用しましたが、これは次のプリント出力を示しています。例えば、RDS for PostgreSQL では、このサンプル DML を実行します。
Python コードは、次のようになります。
オプション 2AWS Lambda 関数を使用する
AWS Lambda 関数を使用するには、前の Python コードを再利用し、デプロイパッケージでパッケージ化することができます。詳細については、「デプロイパッケージ (Python) の作成」を参照してください。これは「AWS Lambda 開発者ガイド」の中にあります。
この例では、psycopg2 を使用しました。これは、Python プログラミング言語に対応した一般的な PostgreSQL アダプタです。パッケージは次のようになります。
With app.py, it looks like the following:
IAM ロールを作成する
AWS Lambda 関数を作成する前に、Kinesis と Amazon RDS データベースにアクセスする権限を持つ、適切な IAM ロールがあることを確認する必要があります。また、Amazon RDS および Kinesis データストリームにアクセスできるように、適切なセキュリティグループを添付して、適切な仮想プライベートクラウド (VPC) に Lambda 関数を作成する必要があります。
IAM コンソールでは、以下に示すように、Lambda 関数に割り当てる IAM ロールを作成できます。

AWS Lambda 関数を作成する
AWS CLI を使用して、次のように Lambda 関数を作成できます。
テストする
Lambda 関数を作成したら、それを起動してテストすることができます。
ちなみに、別のセッションでは、次のように、シェルスクリプトを使用してレコードが Kinesis データストリームに公開されているかどうかをテストすることもできます。
この例では、自分のレコードが Kinesis データストリームに公開されていることを示しています。
メッセージを使用する
これで、変更されたレコードを使用する準備が整いました。すべてのコンシューマーコードが動作します。この投稿のコードを使用すると、前述のように JSON 形式のメッセージが表示されます。
まとめ
この記事では、Amazon Kinesis Data Streams を使用して、変更ストリームをデータベースのレコードに公開する方法を説明しました。データ指向の企業の多くは、これに類似したアーキテクチャを使用しています。この記事で示す例は、実際の本番環境では使用できませんが、この統合スタイルを試して、エンタープライズアーキテクチャの拡張機能を改善することが可能です。最も複雑な部分はおそらく、Amazon Kinesis Data Streams が水面下で既に解決しているでしょう。
その他のリソース
詳細については、以下のソースを参照してください。
チェンジセット抽出用 JSON 出力プラグイン (GitHub)
「レプリケーション接続とカーソルクラス」 (Psycopg 2.7.5 ドキュメント)
「Adding replication protocol」 (PDF ファイル)
著者について
 Jatin Singh はアマゾン ウェブ サービスのパートナーソリューションアーキテクトです。 彼は、AWS を使用している場合にソリューションの価値を向上させる手助けとなるために、AWS の顧客と協力してデータベースプロジェクト上の指導や技術支援を行っています。
Jatin Singh はアマゾン ウェブ サービスのパートナーソリューションアーキテクトです。 彼は、AWS を使用している場合にソリューションの価値を向上させる手助けとなるために、AWS の顧客と協力してデータベースプロジェクト上の指導や技術支援を行っています。