Amazon Web Services ブログ
SAP Data Intelligenceによる顧客フィードバック分析
イントロダクション
多くの企業は顧客をよりよく理解するためのプロセスがあり、データは顧客との関係を強化するための鍵となりつつあります。しかし、単にデータを収集するだけでは十分ではありません。ほとんどの組織は多くのデータにアクセスできますが、データの背後にある意味を判断するのは難しい場合があります。このブログ記事では、SAP Data Intelligence 3(DI3)、SAP HANA、Amazon S3を組み合わせてデータドリブンアーキテクチャを構築し、顧客からのフィードバックをよりよく理解し、意味のある洞察を導き出す方法を紹介します。
概要
SAP Data Intelligence 3の導入から始め、SAP Data Intelligence 3を使用してAmazon S3のデータレイクからSAP HANAにデータを簡単にエクスポートする方法を紹介します。次に、テキストデータから意味のある洞察を導き出すためにSAP HANAを使用する方法を紹介します。分析が終了したら、これらのデータをAmazon S3にインポートして、長期的に低コストで保管することができます。
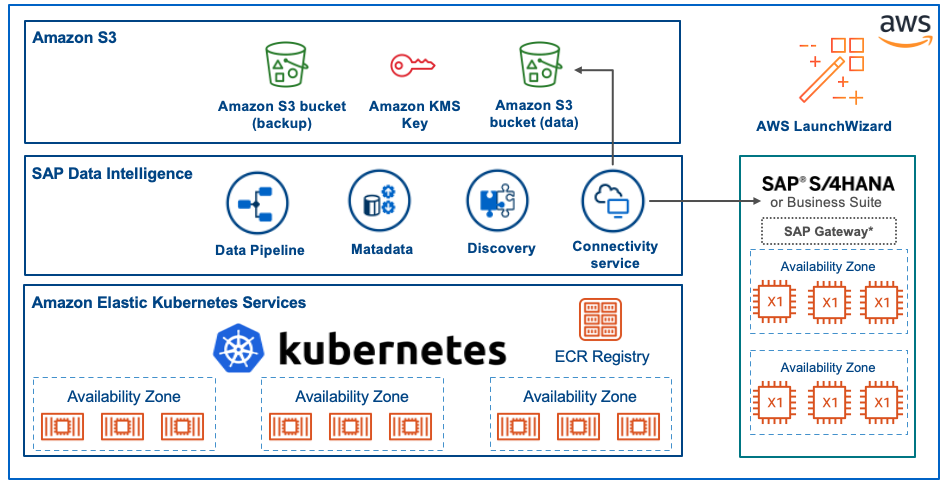
SAP Data IntelligenceとSAP HANAの導入
まずはSAP Data Intelligence(DI3)について簡単に紹介ましょう。ほとんどの読者は、この製品の前身であるSAP Data Hubを認識しているでしょう。技術的な観点から見ると、これは従来のSAP NetWeaverのアーキテクチャとは全く異なり、完全にKubernetes上で動作します。Kubernetes上で動作するため、AWS Cloud Development Kit(CDK)とAmazon Elastic Kubernetes Service(Amazon EKS)を使用して非常に迅速にデプロイすることができます。デプロイのプロセスには3つの重要なステップがあります。
- AWS CDKによるAmazon EKSのデプロイ
- 無人モードでKubernetes上のSLC(Software Lif-cycle Container)ブリッジを使用したDI3のインストール
- SAP HANAのデプロイ。最も簡単なデプロイ方法は、AWS LaunchWizard for SAPを利用することです。
ステップ1とステップ2はAWS Sample GitHubのインストールガイド、ステップ3はAWS LaunchWizard for SAPのデプロイガイドに従ってください。
SAPデータインテリジェンスの接続管理
Amazon S3への接続設定がどれだけ簡単なのかを見てみましょう。Amazon S3 は SAP DI3 に完全に統合されています。バケット名とAWSリージョンと一緒に、AWSのアクセスキーとシークレットアクセスキーを入力するだけです。これで完了です。

SAP Data IntelligenceとSAP HANAの両方がAWS上の同じVirtual Private Cloud(VPC)で実行されている場合、HANAデータベース接続の設定は非常に簡単です。必要なのは、SAP HANAデータベースのホスト名、ポート、必要なセキュリティグループを開いたユーザー名とパスワードだけです。
SAP Data Intelligence Pipeline Modeller
接続の設定が完了したので、Amazon S3からSAP HANAにデータを抽出するためのパイプラインの作成例を紹介します。SAP DI3モデラーアプリケーションは、フローベースのプログラミングパラダイムを用いてデータ処理パイプラインを作成するパイプラインエンジンをベースにしています。モデラーには、Amazon SNS、Amazon Redshift、Amazon S3と統合する定義済みの演算子も用意されています。
AWSのサンプルGitHubからサンプルグラフをインポートします。グラフをインポートしたら、グラフのSAP HANA ClientとREAD FILE演算子を変更します。今回使用するソースデータはAmazon Customer Reviews Datasetです。これは公開されており、以下のコマンドでサンプルセットのデータを直接ダウンロードすることができます。
aws s3 cp s3://amazon-reviews-ml/json/dev/dataset_en_dev.json <Amazon S3 Location>インポートされたグラフは次のようになります。

Runボタンをクリックしてジョブを開始することができます。これは完了するまでに数分かかり、例のデータセットは以下のように表示されます。
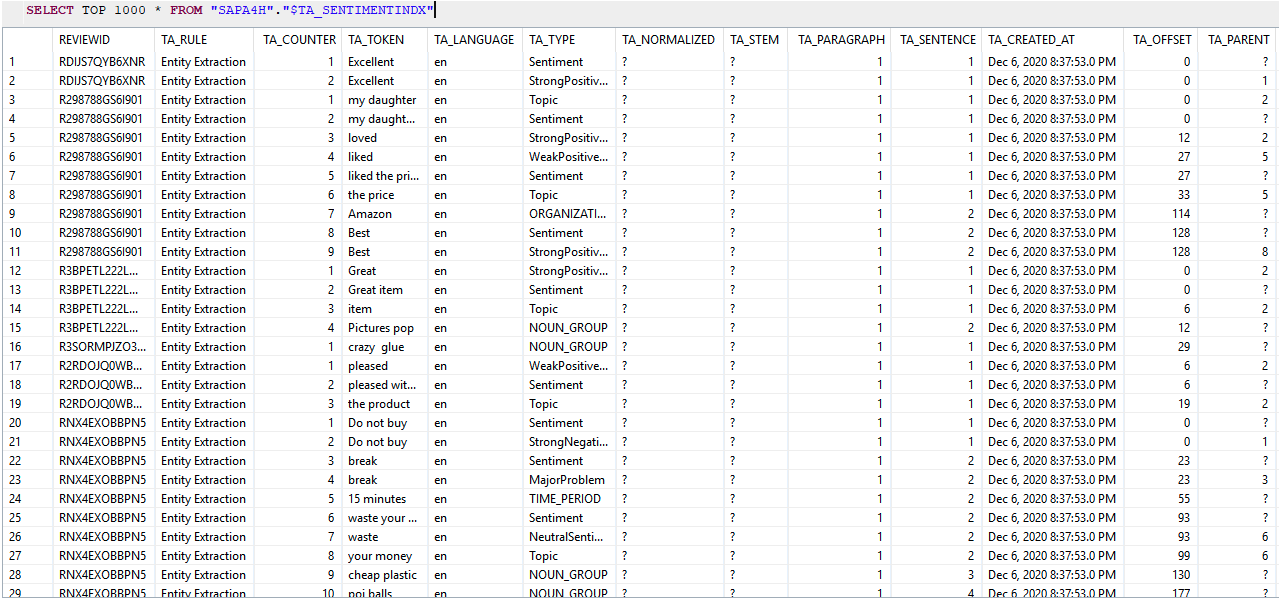
これでデータはSAP HANAのデータベースにあることがわかります。より良いデータセットを理解するためにSAP HANAのテキスト分析機能を使用してみましょう。まず、我々はREVIEWIDという名前のテーブルの主キーを作成します。
ALTER TABLE <schema>.customer_reviews ADD PRIMARY KEY (REVIEWID)次に、SAP HANA のテキスト分析設定モードである EXTRACTION_CORE_VOICEOFCUSTOMER を使用して、SENTIMENTINDX というフルテキストインデックスを reviewbody 列に作成します。この構成を使用しているのは、顧客の心情や要望を抽出するための要件に対応するエンティティタイプとルールのセットが含まれているからです。EXTRACTION_CORE_ENTERPRISE や EXTRACTION_CORE など、多くの構成モードがあります。構成モードの全リストは、SAP HANA 開発者ガイドに掲載されています。
CREATE fulltext INDEX sentimentindx ON <schema>.customer_reviews ("REVIEWBODY") CONFIGURATION 'EXTRACTION_CORE_VOICEOFCUSTOMER' TEXT ANALYSIS ON;
以下のコマンドでフルテキストインデックスを確認することができます。
SELECT TOP 1000 * FROM <schema>."$TA_SENTIMENTINDX"
テキスト分析では、TA_TOKENの「Excellent」「Great」「Best」は強い肯定的な感情、「Do not buy」は強い否定的な感情、「my daughter」「the price」「the item」はトピックであることが認識されました。TA_LANGUAGE列は文書の言語を示しており、カスタマーレビューは様々な言語で書かれていることがあるので、これは非常に便利です。
分析が完了したら、フルテキストインデックスをAmazon S3に移動して、より低コストで長期保存することができます。このパイプラインでは、HANAのテーブルコンシューマー演算子を使用してCSVに変換した後、ライトファイル演算子を使用してAmazon S3への書き込みを行います。

結論
今回のブログ記事では、SAP Data Intelligence 3を使ってAmazon S3とSAP HANAの間でデータを簡単に移動する方法を紹介しています。これは、AWS上のSAPで可能なことのほんの一端を垣間見ただけです。SAPのIntelligent EnterpriseポートフォリオとAWSクラウドサービスにより、企業はより迅速に新しいビジネスモデルを構築できるようになっています。SAP on AWSのイノベーションについてご質問がある場合や知りたい場合は、こちらのリンクからSAP on AWSチームにお問い合わせいただくか、aws.com/sap_japanにアクセスして詳細をご覧ください。今すぐにAWS上での構築を始めて、楽しみましょう。
翻訳はPartner SA 松本が担当しました。原文はこちらです。