AWS for SAP
Voice of Customer Analytics using SAP Data Intelligence on AWS
Introduction
Most companies have processes to better understand their customers and data is fast becoming the key to strengthening customer relationships. However, merely collecting data isn’t enough. While most organizations have access to plenty of data, determining the meaning behind the data can be difficult. In this blog post, we show how you can use a combination of SAP Data Intelligence 3 (DI3), SAP HANA and Amazon S3 to build a data-driven architecture to better understand customer feedback and derive meaningful insight.
Overview
We start with the deployment of SAP Data Intelligence 3 and show how easy it is to export data from an Amazon S3 data lake into SAP HANA using SAP Data Intelligence 3. Then we show how to use SAP HANA to derive meaningful insight from textual data. Once we have finished with the analysis, these data are then imported back in to Amazon S3 for long-term low-cost storage.
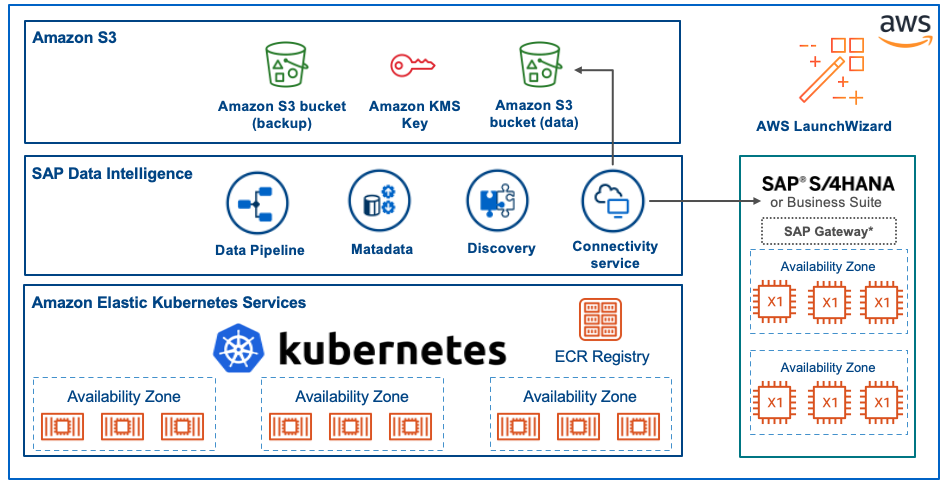
SAP Data Intelligence and SAP HANA deployment on AWS
Let’s start with a quick introduction of SAP Data Intelligence (DI3). Most readers probably recognize the product’s predecessor, SAP Data Hub. From a technical perspective, this is completely different from the traditional SAP NetWeaver architecture and runs entirely on Kubernetes. As this runs in Kubernetes, you can deploy this very quickly using the AWS Cloud Development Kit (CDK) and Amazon Elastic Kubernetes Service (Amazon EKS). There are three key steps in the deployment process.
- AWS CDK deployment of Amazon EKS
- DI3 installation using Software Life-cycle Container (SLC) bridge on Kubernetes in unattended mode.
- Deployment of SAP HANA. The easiest way to deploy this is using AWS LaunchWizard for SAP.
Follow the installation guide in AWS Sample GitHub for step 1 and step 2 and AWS LaunchWizard for SAP deployment guide for step 3.
SAP Data Intelligence Connection Management
Let’s take a quick look at the connection management and see how easy it is to set up a connection to Amazon S3 . Amazon S3 is fully integrated into SAP DI3. Simply enter your AWS access key and secret access key together with the bucket name and AWS region. That’s it!

Setting up the HANA database connection is very easy if both the SAP Data Intelligence and SAP HANA run in the same Virtual Private Cloud (VPC) on AWS. All you need is the SAP HANA database host name, port and the username and password with the required security group opened.
SAP Data Intelligence Pipeline Modeller
Now that we have set up the connection, we show you how to create an example pipeline to extract data from Amazon S3 in to SAP HANA. The SAP DI3 modeler application is based on the pipeline engine that uses a flow-based programming paradigm to create data processing pipelines. The modeler also provides predefined operators that integrates into Amazon SNS, Amazon Redshift and Amazon S3.
Import the sample graph from the AWS sample GitHub. Once the graph has been imported, change the SAP HANA Client and READ FILE operator in the graph. The source data we are going to use is from Amazon Customer Reviews Dataset. This is publicly available and you can use the command below to download a sample set of data directly.
aws s3 cp s3://amazon-reviews-ml/json/dev/dataset_en_dev.json <Amazon S3 Location>The imported graph will look like this.

You can start the job by clicking on the Run button. This takes a few minutes to complete and the example dataset is shown below.
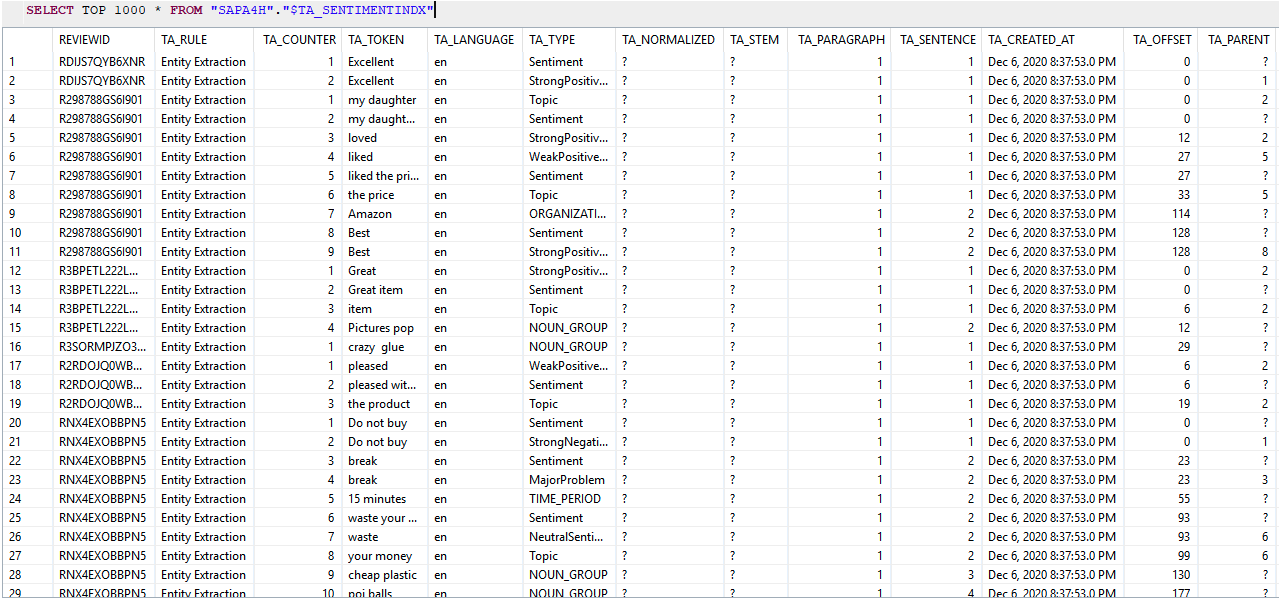
Now the data is in SAP HANA database, let’s use the text analysis feature in SAP HANA to understand the data set better. First, we will create an primary key for the table named REVIEWID
ALTER TABLE <schema>.customer_reviews ADD PRIMARY KEY (REVIEWID)Then we create an full text index called SENTIMENTINDX using the SAP HANA text analysis configuration mode – EXTRACTION_CORE_VOICEOFCUSTOMER for the reviewbody column. We are using this configuration because this includes a set of entity types and rules that address requirements for extracting customer sentiments and requests. There are a number of configuration modes such as EXTRACTION_CORE_ENTERPRISE and EXTRACTION_CORE. You can find the full list of configuration mode in the SAP HANA developer guide.
CREATE fulltext INDEX sentimentindx ON <schema>.customer_reviews ("REVIEWBODY") CONFIGURATION 'EXTRACTION_CORE_VOICEOFCUSTOMER' TEXT ANALYSIS ON;
We can view the full text index using the command below.
SELECT TOP 1000 * FROM <schema>."$TA_SENTIMENTINDX"
The text analysis recognized that the TA_TOKEN “Excellent”, “Great” and “Best” are strong positive sentiment, “Do not buy” is a strong negative sentiment and “my daughter”, “the price” and ‘item“ are topic. The TA_LANGUAGE column indicates the language of the document and this can be very useful as customer reviews can come in many different languages.
Once the analysis has been completed, you can move the full-text index into Amazon S3 for lower cost long term storage. This pipeline uses a HANA table consumer operator and converts it into a CSV, then use the write file operator to write to Amazon S3.

Conclusion
In this blog post, we show how easy it is to move data between Amazon S3 and SAP HANA using SAP Data Intelligence 3. This is just a glimpse of what is possible with SAP on AWS. SAP’s Intelligent Enterprise portfolio and AWS Cloud services are enabling enterprises to create new business models faster. If you have questions or would like to know about SAP on AWS innovations, please contact the SAP on AWS team using this link or visit aws.com/sap to learn more. Start building on AWS today and have fun!