Amazon Web Services 한국 블로그
Amazon FSx for Lustre와 Amazon S3 통합 기능 출시
Amazon FSx for Lustre의 두 가지 추가 기능을 발표합니다. 첫째, 삭제된 파일 및 객체를 포함하여 파일 시스템을 Amazon Simple Storage Service(Amazon S3)와 완전히 양방향으로 동기화할 수 있습니다. 둘째, 파일 시스템을 여러 S3 버킷 또는 접두사와 동기화하는 기능입니다.
Lustre는 대부분의 대형 슈퍼컴퓨터의 워크로드를 지원하는 대규모 분산 병렬 파일 시스템입니다. 따라서 기상학, 생명 과학 및 엔지니어링 시뮬레이션과 같은 고성능 컴퓨팅 워크로드를 처리해야 하는 AWS 고객에게 인기가 있습니다. 금융 서비스 산업뿐만 아니라 미디어 및 엔터테인먼트 분야에서도 사용됩니다.
Sun Microsystems에서 일할 때 저는 Lustre 파일 시스템을 처음으로 직접 사용해 봤습니다. 저는 사전 영업 엔지니어였으며 금융 서비스 회사에 수백만 달러의 컴퓨팅 및 스토리지 인프라를 판매하기 위해 몇 가지 거래를 진행했습니다. 그 당시에는 Lustre 파일 시스템에 액세스하는 것이 사치스러운 일이었습니다. 고가의 컴퓨팅, 스토리지 및 네트워크 하드웨어가 필요했습니다. 배송을 받기 위해서는 몇 주를 기다려야 했습니다. 또한 클러스터를 설치하고 구성하는 데에도 며칠이 걸렸습니다.
다시 2021년으로 돌아오면, 이제 페타바이트 규모의 Lustre 클러스터를 만들고 온디맨드로 AWS 클라우드에서 실행되는 컴퓨팅 리소스에 파일 시스템을 연결하고 사용한 만큼만 비용을 지불할 수 있게 되었습니다. 저장소 영역 네트워크(SAN), 파이버 채널(FC) 패브릭 및 기타 기본 기술에 대해 알 필요도 없습니다.
최신 애플리케이션은 워크로드에 따라 다른 스토리지 옵션을 사용합니다. 데이터 변환, 준비 또는 Import/Export 작업에 S3 객체 스토리지를 사용하는 것이 일반적입니다.
다른 워크로드의 경우 데이터에 액세스하기 위해 POSIX 파일 시스템이 필요할 수 있습니다. FSx for Lustre를 사용하면 S3에 저장된 객체를 Lustre 파일 시스템과 동기화하여 이러한 요구 사항을 충족할 수 있습니다.
S3 버킷을 파일 시스템에 연결하면 FSx for Lustre가 S3 객체를 파일로 투명하게 표시하므로 결과를 S3에 다시 쓸 수 있습니다.
여러 S3 버킷으로 완전한 양방향 동기화 구현
S3 버킷에 대한 빠른 POSIX 준수 파일 시스템 액세스가 워크로드에 필요한 경우 FSx for Lustre를 사용하여 S3 버킷을 파일 시스템에 연결하고 파일 시스템과 S3 간에 양방향으로 데이터를 동기화할 수 있습니다. 하지만 지금까지도 몇 가지 제약이 있었습니다. 먼저 FSx for Lustre에서 S3로 데이터를 다시 내보내도록 작업을 수동으로 구성해야 했습니다.
둘째, S3에서 삭제된 파일이 파일 시스템에서 자동으로 삭제되지 않았습니다. 셋째, FSx for Lustre 파일 시스템이 하나의 S3 버킷과만 동기화되었습니다. 이번 출시를 통해 이러한 세 가지 과제가 해결되었습니다.
오늘부터 데이터 리포지토리 연결에 대한 자동 내보내기 정책을 구성하면 FSx for Lustre 파일 시스템의 파일에 대해 S3의 데이터 리포지토리로 내보내기가 자동으로 수행됩니다. 또한 S3에서 삭제된 객체가 FSx for Lustre 파일 시스템에서 삭제됩니다. 그 반대도 가능합니다. FSx for Lustre에서 파일을 삭제하면 S3에서도 해당 객체가 삭제됩니다. 마지막으로, 이제 FSx for Lustre 파일 시스템을 여러 S3 버킷과 동기화할 수 있습니다. 각 버킷은 Lustre 파일 시스템의 루트에 서로 다른 경로를 가집니다. 예를 들어, S3 버킷 로그는 /fsx/logs로 매핑되고 다른 financial_data 버킷은 /fsx/finance에 매핑될 수 있습니다.
이러한 새로운 기능은 파일 기반 및 객체 기반 워크플로를 모두 사용하여 S3 버킷의 데이터를 동시에 처리하고 이러한 워크플로 간에 거의 실시간으로 결과를 공유해야 하는 경우에 유용합니다. 예를 들어 파일 데이터에 액세스하는 애플리케이션은 S3 버킷에 연결된 FSx for Lustre 파일 시스템을 사용하여 액세스할 수 있으며 Amazon EMR에서 실행되는 다른 애플리케이션이 S3의 동일한 파일을 처리할 수 있습니다.
또한 여러 S3 버킷 또는 접두사를 단일 FSx for Lustre 파일 시스템에 연결할 수 있으므로 여러 데이터 집합에 걸쳐 통합된 보기를 사용할 수 있습니다. 이제 단일 FSx for Lustre 파일 시스템을 생성하고 여러 S3 데이터 리포지토리(S3 버킷 또는 접두사)를 쉽게 연결할 수 있습니다. 이 기능은 여러 S3 버킷 또는 접두사를 사용하여 데이터 레이크에 대한 액세스를 구성 및 관리하고, 퍼블릭 S3 버킷의 파일(예: 수백 개의 퍼블릭 데이터 집합)에 액세스하고, 다른 S3 버킷에 작업 출력을 쓰는 경우나, 여러 S3 데이터 세트에 연결된 더 큰 FSx for Lustre를 사용하여 스케일 아웃 성능을 높이려는 경우에 편리합니다.
작동 방법
FSx for Lustre 파일 시스템을 생성하고 이를 Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스에 연결해 보겠습니다. 데이터 전송 비용을 최소화하기 위해 파일 시스템과 인스턴스가 동일한 VPC 서브넷에 있는지 확인합니다. 파일 시스템 보안 그룹에서 인스턴스로부터의 액세스를 승인해야 합니다.
AWS 관리 콘솔을 열고 FSx로 이동한 다음, [파일 시스템 생성(Create file system)]을 선택합니다. 그런 다음, Amazon FSx for Lustre를 선택합니다. 여기서는 파일 시스템을 만드는 모든 옵션을 검토하지는 않습니다. 관련 문서를 참조하여 파일 시스템을 만드는 방법을 알아볼 수 있습니다. [S3에서 데이터 가져오기 및 S3로 데이터 내보내기(Import data from and export data to S3)]가 선택되어 있는지 확인합니다.
 파일 시스템을 생성하는 데 몇 분 정도 걸립니다. 상태가 ✅ [사용 가능]이면 [데이터 리포지토리] 탭으로 이동한 다음, [데이터 리포지토리 연결 만들기]를 선택합니다.
파일 시스템을 생성하는 데 몇 분 정도 걸립니다. 상태가 ✅ [사용 가능]이면 [데이터 리포지토리] 탭으로 이동한 다음, [데이터 리포지토리 연결 만들기]를 선택합니다.
[데이터 리포지토리 경로(Data Repository path)](여기서는 소스 S3 버킷)와 [파일 시스템 경로(file system path)](버킷을 가져올 파일 시스템의 위치)를 선택합니다.
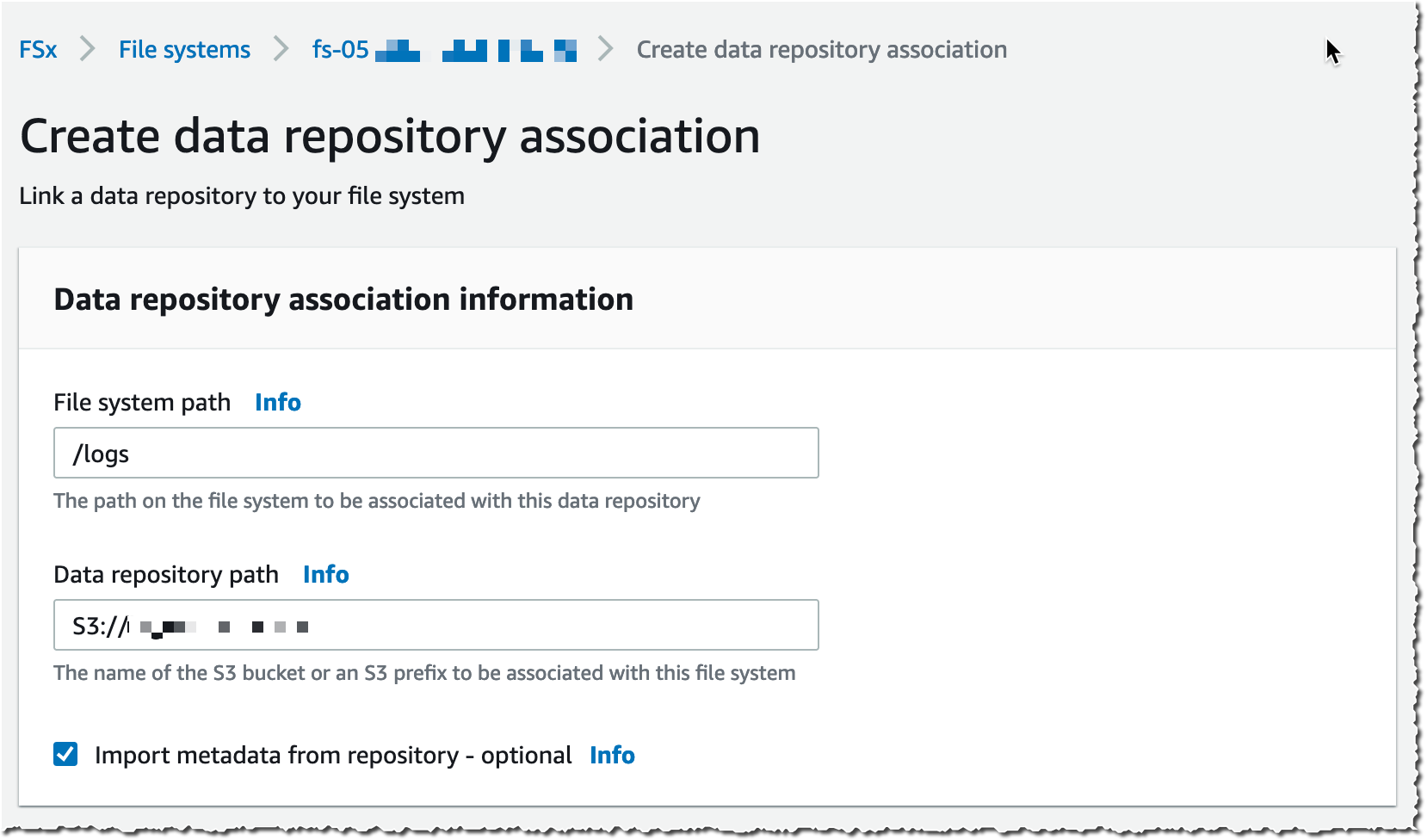
그런 다음, [가져오기 정책(Import policy)]과 [내보내기 정책(Export policy)]을 선택합니다. 파일/객체 생성, 파일/객체의 업데이트 및 파일/객체 삭제 시점을 동기화할 수 있습니다. 그런 다음, [만들기(Create)]를 선택합니다.

자동 가져오기를 사용하는 경우 FSx for Lustre 클러스터와 동일한 AWS 리전에 S3 버킷을 제공해야 합니다. FSx for Lustre는 자동 내보내기 및 기타 모든 기능을 위해 다른 AWS 리전의 S3 버킷에 대한 연결을 지원합니다.
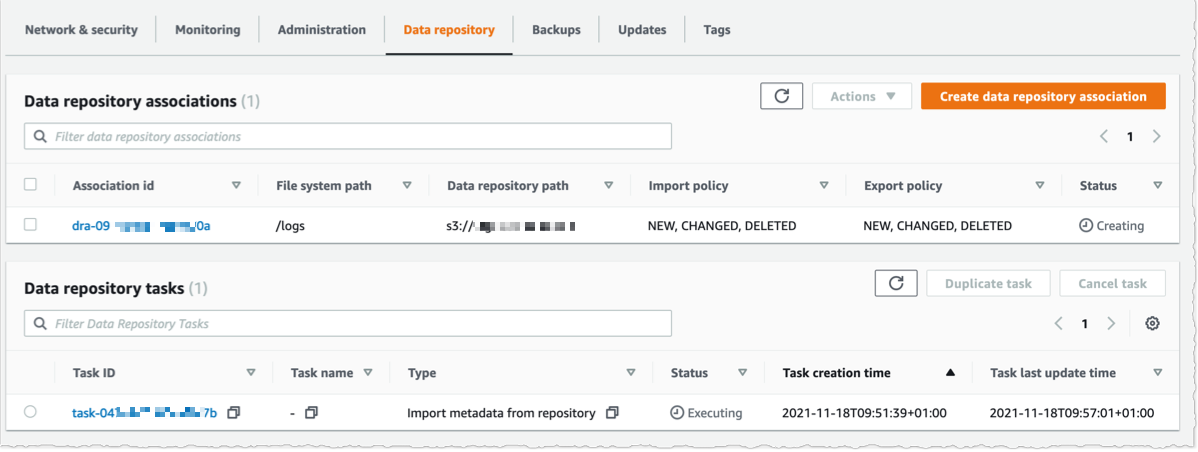
콘솔을 사용하여 [데이터 리포지토리 연결(Data repository associations)] 목록을 볼 수 있습니다. 가져오기 작업 상태가 ✅ [성공(Succeeded)]이 될 때까지 기다립니다. 파일 시스템을 객체 수가 많은 S3 버킷에 연결하는 경우 데이터 리포지토리 연결을 생성하는 동안 [리포지토리에서 메타데이터 가져오기(Importing metadata from repository)]를 건너뛰고, [가져오기 작업(Import task)]을 사용하여 워크로드에 필요한 S3 버킷의 선택된 접두사에서 메타데이터를 로드하도록 선택할 수 있습니다.
동일한 VPC 서브넷에 EC2 인스턴스를 생성합니다. 또한 FSx for Lustre 클러스터 보안 그룹이 EC2 인스턴스의 수신 트래픽을 승인하는지 확인합니다. SSH를 사용하여 인스턴스에 연결한 후 다음 명령을 입력합니다(명령 앞에 셸 프롬프트의 일부인 $ 기호가 붙음).
# check kernel version, minimum version 4.14.104-95.84 is required
$ uname -r
4.14.252-195.483.amzn2.aarch64
# install lustre client
$ sudo amazon-linux-extras install -y lustre2.10
Installing lustre-client
...
Installed:
lustre-client.aarch64 0:2.10.8-5.amzn2
Complete!
# create a mount point
$ sudo mkdir /fsx
# mount the file system
$ sudo mount -t lustre -o noatime,flock fs-00...9d.fsx.us-east-1.amazonaws.com@tcp:/ny345bmv /fsx
# verify mount succeeded
$ mount
...
172.0.0.0@tcp:/ny345bmv on /fsx type lustre (rw,noatime,flock,lazystatfs)
그런 다음, 파일 시스템에 S3 객체가 포함되어 있는지 확인하고 touch 명령을 사용하여 새 파일을 만듭니다.

S3에서 AWS 콘솔로 전환한 다음, 버킷 이름으로 전환하고 파일이 동기화되었는지 확인합니다.

콘솔을 사용하여 S3에서 파일을 삭제합니다. 그러면 몇 초 후에 파일이 FSx 파일 시스템에서도 삭제됩니다.

요금 및 가용성
이러한 새로운 기능은 Amazon FSx for Lustre 파일 시스템에 대한 추가 비용 없이 사용할 수 있습니다. 자동 내보내기 및 여러 리포지토리는 미국 동부(버지니아 북부), 미국 동부(오하이오), 미국 서부(오레곤), 캐나다(중부), 아시아 태평양(도쿄), 유럽(프랑크푸르트) 및 유럽(아일랜드)의 Persistent 2 파일 시스템에서만 사용할 수 있습니다. S3에서 삭제되거나 이동된 객체를 지원하는 자동 가져오기는 FSx for Lustre를 사용할 수 있는 모든 리전에서 2020년 7월 23일 이후에 생성된 파일 시스템에 대해 사용할 수 있습니다.
AWS 관리 콘솔, AWS 명령줄 인터페이스(CLI) 및 AWS SDK를 사용하여 S3 업데이트를 자동으로 가져오도록 파일 시스템을 구성할 수 있습니다.
Amazon FSx for Lustre 파일 시스템과 함께 S3 데이터 리포지토리를 사용하는 방법에 대해 자세히 알아보세요.
추가로 알릴 내용
이 블로그를 읽는 동안 한 가지 더 알릴 내용이 생겼습니다. 오늘 당사는 차세대 FSx for Lustre 파일 시스템도 출시했습니다.
차세대 FSx for Lustre 파일 시스템은 AWS Graviton 프로세서를 기반으로 구축되었습니다. 이전 세대의 파일 시스템에 비해 테라바이트당 최대 5배 높은 처리량(테라바이트당 최대 1Gb/s)을 제공하고 처리량 비용을 최대 60% 절감하도록 설계되었습니다. 지금 사용해보세요!
추신: 제 동료인 Michael이 FSx for Lustre를 위한 향상된 S3 통합을 보여 주는 데모 비디오를 녹화했습니다. 지금 바로 확인해 보세요.