Amazon Web Services 한국 블로그
Amazon Kinesis Data Analytics Studio 소개 – SQL, Python, Scala를 통한 스트리밍 데이터 처리 기능 (서울 리전 포함)
시기적절한 인사이트를 확보하고 비즈니스와 애플리케이션에서 들어오는 새로운 정보에 신속하게 대응하는 가장 좋은 방법은 스트리밍 데이터를 분석하는 것입니다. 스트리밍 데이터는 일반적으로 레코드 단위로 또는 슬라이딩 시간대에 걸쳐 순차적으로 증분 처리되어야 하며 상관 관계, 집계, 필터링 및 샘플링과 같은 다양한 분석에 사용될 수 있습니다.
오늘은 스트리밍 데이터를 더 쉽게 분석할 수 있는 Amazon Kinesis Data Analytics Studio를 소개합니다.
이제 Amazon Kinesis 콘솔에서 Kinesis 데이터 스트림을 선택하고 클릭 한 번으로 Apache Zeppelin 및 Apache Flink로 구동되는 Kinesis Data Analytics Studio 노트북을 시작하여 스트림 데이터를 대화형으로 분석할 수 있습니다. 마찬가지로, Amazon Managed Streaming for Apache Kafka 콘솔에서 클러스터를 시작하여 노트북을 시작하고 Apache Kafka 스트림 데이터를 분석할 수 있습니다. Kinesis Data Analytics Studio 콘솔에서 노트북을 시작하고 사용자 지정 소스에 연결할 수도 있습니다.

노트북에서 스트리밍 데이터와 상호 작용하고 SQL 쿼리와 Python 또는 Scala 프로그램을 사용하여 몇 초 만에 결과를 얻을 수 있습니다. 결과에 만족하면 클릭 몇 번으로 추가 개발 작업 없이 대규모로 안정적으로 실행되는 프로덕션 스트림 처리 애플리케이션으로 코드를 승격할 수 있습니다.
새 프로젝트의 경우 Kinesis Data Analytics for SQL Applications 대신 새로운 Kinesis Data Analytics Studio를 사용하는 것이 좋습니다. Kinesis Data Analytics Studio는 고급 분석 기능을 손쉽게 사용하여 정교한 스트림 처리 애플리케이션을 몇 분 안에 구축할 수 있는 환경을 제공합니다. 이제 실제 작동 방식을 살펴봅시다.
Kinesis Data Analytics Studio를 사용하여 스트리밍 데이터 분석
일부 센서에서 Kinesis 데이터 스트림으로 전송된 데이터를 제대로 이해하기 위한 작업을 수행할 것입니다.
워크로드를 시뮬레이션하기 위해 random_data_generator.py Python 스크립트를 사용합니다. Python을 알지 못해도 Kinesis Data Analytics Studio를 사용할 수 있습니다. 실제로 다음 단계에서 SQL을 사용할 것입니다. 또한 코딩 작업 없이 Amazon Kinesis Data Generator 사용자 인터페이스(UI)를 사용하여 테스트 데이터를 Kinesis Data Streams 또는 Kinesis Data Firehose로 전송할 수 있습니다. 전송되는 데이터를 세부적으로 제어하기 위해 Python 스크립트를 사용합니다.
import datetime
import json
import random
import boto3
STREAM_NAME = "my-input-stream"
def get_random_data():
current_temperature = round(10 + random.random() * 170, 2)
if current_temperature > 160:
status = "ERROR"
elif current_temperature > 140 or random.randrange(1, 100) > 80:
status = random.choice(["WARNING","ERROR"])
else:
status = "OK"
return {
'sensor_id': random.randrange(1, 100),
'current_temperature': current_temperature,
'status': status,
'event_time': datetime.datetime.now().isoformat()
}
def send_data(stream_name, kinesis_client):
while True:
data = get_random_data()
partition_key = str(data["sensor_id"])
print(data)
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data),
PartitionKey=partition_key)
if __name__ == '__main__':
kinesis_client = boto3.client('kinesis')
send_data(STREAM_NAME, kinesis_client)이 스크립트는 JSON 구문을 사용하여 임의의 레코드를 내 Kinesis 데이터 스트림으로 보냅니다. 예를 들면 다음과 같습니다.
Kinesis 콘솔에서 Kinesis 데이터 스트림(my-input-stream)을 선택하고 [프로세스(Process)] 드롭다운에서 [실시간으로 데이터 처리(Process data in real time)]를 선택합니다. 이렇게 하면 스트림이 노트북의 소스로 구성됩니다.

다음 대화 상자에서 Apache Flink – Studio 노트북을 생성합니다.
노트북의 이름(my-notebook)과 설명을 입력합니다. 이전에 선택한 Kinesis 데이터 스트림(my-input-stream)을 읽을 수 있는 AWS Identity and Access Management(IAM) 권한이 노트북이 수임한 IAM 역할에 자동으로 연결됩니다.

[생성(Create)]을 선택하여 AWS Glue 콘솔을 열고 빈 데이터베이스를 생성합니다. Kinesis Data Analytics Studio 콘솔로 돌아가서 목록을 새로 고치고 새 데이터베이스를 선택합니다. 소스 및 대상에 대한 메타데이터를 정의합니다. 여기에서 기본 Studio 노트북 설정도 검토할 수 있습니다. 그런 다음 [Studio 노트북 생성(Create Studio notebook)]을 선택합니다.

이제 노트북이 생성되었으므로 [실행(Run)]을 선택합니다.
노트북이 실행 중일 때 [Apache Zeppelin에서 열기(Open in Apache Zeppelin)]를 선택하여 노트북에 액세스하고 스트리밍 데이터와 상호 작용하고 실시간으로 인사이트를 얻기 위한 코드를 SQL, Python 또는 Scala로 작성합니다.
노트북에서 새 노트를 생성하고 Sensors라는 이름을 지정합니다. 그런 다음 스트림의 데이터 형식을 설명하는 sensor_data 테이블을 생성합니다.
%flink.ssql
CREATE TABLE sensor_data (
sensor_id INTEGER,
current_temperature DOUBLE,
status VARCHAR(6),
event_time TIMESTAMP(3),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
)
PARTITIONED BY (sensor_id)
WITH (
'connector' = 'kinesis',
'stream' = 'my-input-stream',
'aws.region' = 'us-east-1',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
)
앞의 명령에서 첫 줄은 Apache Zeppelin에 Apache Flink 인터프리터에 대한 스트림 SQL 환경(%flink.ssql)을 제공할 것을 지시합니다. 배치 SQL 환경(%flink.bsql)이나 Python (%flink.pyflink) 또는 Scala (%flink) 코드를 사용하여 스트리밍 데이터와 상호 작용할 수도 있습니다.
CREATE TABLE 문의 첫 번째 부분은 데이터베이스에서 SQL을 사용하는 모든 사용자에게 익숙한 부분입니다. 스트림의 센서 데이터를 저장하기 위한 테이블이 생성됩니다. WATERMARK 옵션은 Apache Flink 설명서의 이벤트 시간 및 워터마크 섹션에 설명된 것처럼 이벤트 시간의 진행률을 측정하는 데 사용됩니다.
CREATE TABLE 문의 두 번째 부분은 테이블의 데이터를 수신하는 데 사용되는 커넥터(예: kinesis 또는 kafka), 스트림의 이름, AWS 리전, 스트림의 전체 데이터 형식(예: json 또는 csv) 및 타임스탬프에 사용된 구문(이 예에서는 ISO 8601)을 설명합니다. 스트림을 처리할 시작 위치를 선택할 수도 있습니다. 여기에서는 LATEST를 사용하여 최신 데이터를 먼저 읽습니다.
테이블이 준비되면 노트북을 생성할 때 선택한 AWS Glue 데이터 카탈로그 데이터베이스에서 테이블을 찾습니다.

이제 sensor_data 테이블에서 SQL 쿼리를 실행하고 슬라이딩 또는 연속 시간대를 사용하여 센서의 상태를 자세히 파악할 수 있습니다.
스트림의 데이터에 대한 개요를 보려면 단순한 SELECT로 시작하여 sensor_data 테이블의 모든 콘텐츠를 가져옵니다.
%flink.ssql(type=update)
SELECT * FROM sensor_data;이번에는 명령의 첫 번째 줄에 파라미터(type=update)가 있으므로 새 데이터가 도착할 때 SELECT의 출력(행이 2개 이상)이 지속적으로 업데이트됩니다.
랩톱의 터미널에서 random_data_generator.py 스크립트를 시작합니다.
처음에는 수신 데이터가 포함된 테이블이 표시됩니다. 쉽게 이해할 수 있도록 막대 그래프 보기를 선택합니다. 그런 다음 여기에 표시된 것과 같이 결과를 상태로 그룹화하여 평균 current_temperature를 표시합니다.
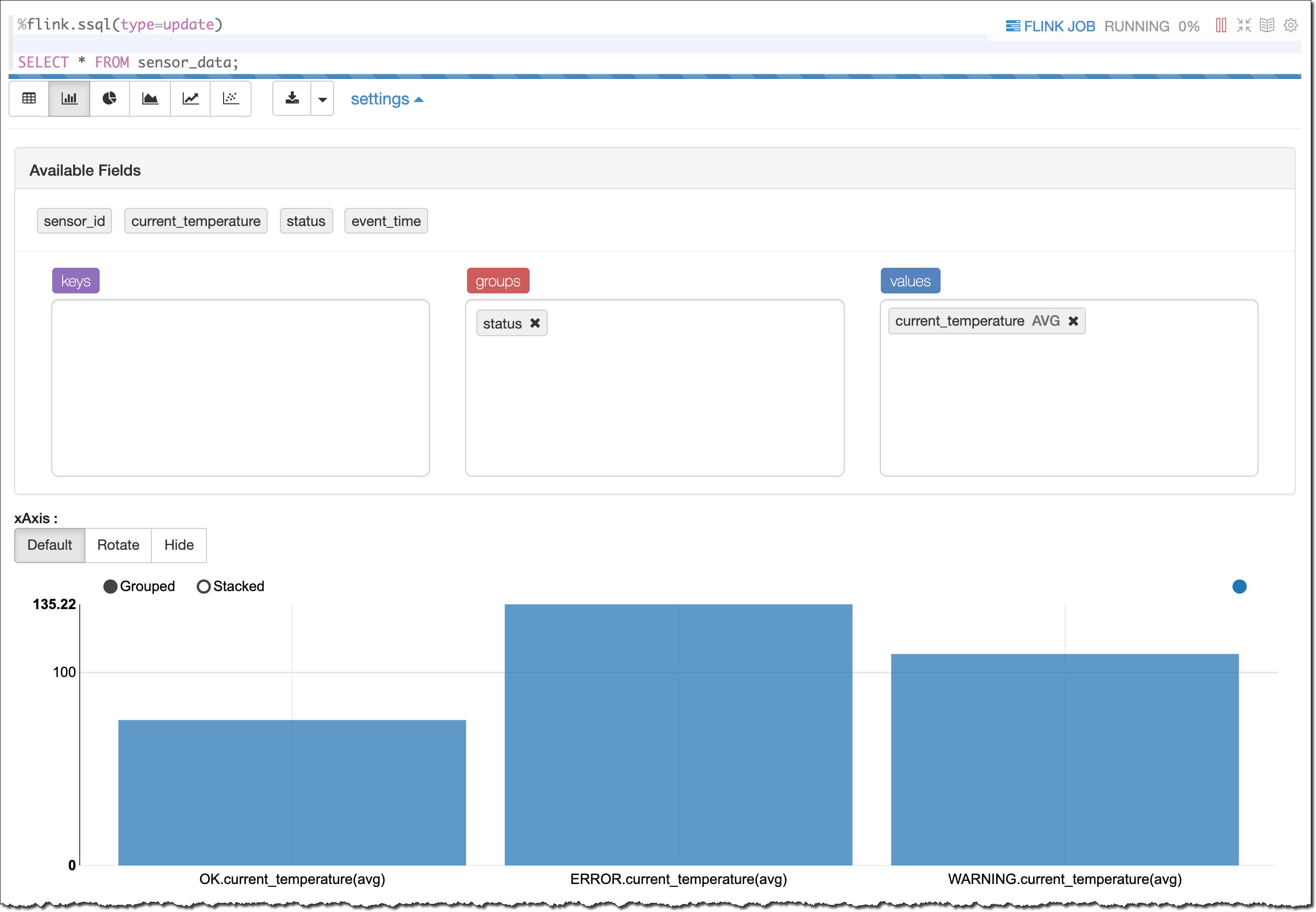
이러한 결과를 생성할 때 사용한 방법에서 예상되는 대로 상태(OK, WARNING 또는 ERROR)에 따라 다른 평균 온도가 표시됩니다. 온도가 높을수록 센서에서 무언가가 올바르게 작동하지 않을 확률이 커집니다.
SQL 구문을 사용하여 집계된 쿼리를 명시적으로 실행할 수 있습니다. 이번에는 10초마다 결과를 업데이트하여 1분의 슬라이딩 시간대에서 결과를 계산하려고 합니다. 이렇게 하려면 SELECT 문의 GROUP BY 섹션에서 HOP 함수를 사용합니다. Select의 출력에 시간을 추가하려면 HOP_ROWTIME 함수를 사용합니다. 자세한 내용은 Apache Flink 설명서에서 그룹 기간 집계의 작동 방식을 참조하세요.
%flink.ssql(type=update)
SELECT sensor_data.status,
COUNT(*) AS num,
AVG(sensor_data.current_temperature) AS avg_current_temperature,
HOP_ROWTIME(event_time, INTERVAL '10' second, INTERVAL '1' minute) as hop_time
FROM sensor_data
GROUP BY HOP(event_time, INTERVAL '10' second, INTERVAL '1' minute), sensor_data.status;이번에는 결과를 테이블 형식으로 봅니다.

쿼리 결과를 대상 스트림으로 보내려면 테이블을 생성하고 테이블을 스트림에 연결합니다. 먼저, 스트림에 쓸 수 있는 권한을 노트북에 부여해야 합니다.
Kinesis Data Analytics Studio 콘솔에서 my-notebook을 선택합니다. 그런 다음 [Studio 노트북 세부 정보(Studio notebooks details)] 섹션에서 [IAM 권한 편집(Edit IAM permissions)]을 선택합니다. 여기에서 노트북에 사용되는 소스와 대상을 구성할 수 있으며 IAM 역할 권한이 자동으로 업데이트됩니다.

[IAM 정책에 포함된 대상(Included destinations in IAM policy)] 섹션에서 대상을 선택하고 my-output-stream을 선택합니다. 변경 사항을 저장하고 노트북이 업데이트될 때까지 기다립니다. 이제 대상 스트림을 사용할 준비가 되었습니다.
노트북에서 my-output-stream에 연결된 sensor_state 테이블을 생성합니다.
%flink.ssql
CREATE TABLE sensor_state (
status VARCHAR(6),
num INTEGER,
avg_current_temperature DOUBLE,
hop_time TIMESTAMP(3)
)
WITH (
'connector' = 'kinesis',
'stream' = 'my-output-stream',
'aws.region' = 'us-east-1',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601');이제 이 INSERT INTO 문을 사용하여 Select의 결과를 sensor_state 테이블에 지속적으로 삽입합니다.
%flink.ssql(type=update)
INSERT INTO sensor_state
SELECT sensor_data.status,
COUNT(*) AS num,
AVG(sensor_data.current_temperature) AS avg_current_temperature,
HOP_ROWTIME(event_time, INTERVAL '10' second, INTERVAL '1' minute) as hop_time
FROM sensor_data
GROUP BY HOP(event_time, INTERVAL '10' second, INTERVAL '1' minute), sensor_data.status;
대상 Kinesis 데이터 스트림(my-output-stream)으로도 데이터가 전송되므로 다른 애플리케이션에서 데이터를 사용할 수 있습니다. 예를 들어 대상 스트림의 데이터를 사용하여 실시간 대시보드를 업데이트하거나 소프트웨어 업데이트 후 센서의 동작을 모니터링할 수 있습니다.
만족스러운 결과가 나왔으므로 이 쿼리와 해당 출력을 Kinesis Analytics 애플리케이션으로 배포하겠습니다.
먼저 노트북에서 SensorsApp 노트를 생성하고 애플리케이션의 일부로 실행할 문을 복사합니다. 테이블이 이미 생성되었으므로 위의 INSERT INTO 문을 복사하면 됩니다.
그런 다음 노트북의 오른쪽 상단에 있는 메뉴에서 [SensorsApp을 구축하고 Amazon S3로 내보내기(Build SensorsApp and export to Amazon S3)]를 선택하고 애플리케이션 이름을 확인합니다.

내보내기가 준비되면 동일한 메뉴에서 [SensorsApp을 Kinesis Analytics 애플리케이션으로 배포(Deploy SensorsApp as Kinesis Analytics application)]를 선택합니다. 그런 다음 애플리케이션 구성을 세부적으로 조정합니다. 입력 Kinesis 데이터 스트림에 샤드가 하나만 있고 트래픽이 많지 않으므로 parallelism을 1로 설정했습니다. 그런 다음 코드 작성 없이 애플리케이션을 실행합니다.
Kinesis Data Analytics 애플리케이션 콘솔에서 [Apache Flink 대시보드 열기(Open Apache Flink dashboard)]를 선택하여 애플리케이션 실행에 대한 추가 정보를 가져옵니다.

가용성 및 요금
오늘부터 Kinesis Data Analytics가 정식 출시된 모든 AWS 리전에서 Amazon Kinesis Data Analytics Studio를 사용할 수 있습니다. 자세한 내용은 AWS 리전 서비스 목록을 참조하세요.
Kinesis Data Analytics Studio에서는 오픈 소스 버전의 Apache Zeppelin과 Apache Flink를 실행하고 업스트림 변경에 기여합니다. 예를 들어 Apache Zeppelin에 대한 버그 수정을 기여하고 Kinesis Data Streams 및 Kinesis Data Firehose와 같은 Apache Flink용 AWS 커넥터에 기여했습니다. 또한 Apache Flink 커뮤니티와 협력하여 가용성 개선에도 기여하고 있습니다. 예를 들어 런타임 시 오류를 자동 분류하여 오류가 사용자 코드에 있는지 애플리케이션 인프라에 있는지 여부를 파악합니다.
Kinesis Data Analytics Studio 사용 요금은 실행 중인 노트북에 사용되는 것을 포함하여 시간당 Kinesis 처리 장치(KPU)의 평균 수를 기준으로 부과됩니다. KPU 1개는 vCPU 컴퓨팅 1개, 메모리 4GB 및 연결된 네트워킹으로 구성됩니다. 또한 실행 중인 애플리케이션 스토리지와 내구성 있는 애플리케이션 스토리지에 대해서도 요금이 부과됩니다. 자세한 내용은 Kinesis Data Analytics 요금 페이지를 참조하세요.
지금 바로 Kinesis Data Analytics Studio를 사용하여 스트리밍 데이터에서 더 나은 인사이트를 확보하시기 바랍니다.
— Danilo