Amazon Web Services 한국 블로그
Amazon EC2 P5 인스턴스 정식 출시 – NVIDIA H100 Tensor Core GPU 기반 생성형 AI 및 HPC 애플리케이션 가속화
2023년 3월, AWS와 NVIDIA는 갈수록 복잡해지는 대규모 언어 모델(LLM)을 훈련하고 생성형 AI 애플리케이션을 개발하는 데 최적화되고 최고의 확장성을 갖춘 온디맨드 인공 지능(AI) 인프라를 구축하는 것을 목표로, 다자간 협업을 진행한다고 발표했습니다.
AWS는 NVIDIA H100 Tensor Core GPU와 최신 AWS 서비스의 네트워킹 및 확장성을 기반으로 구동되는 Amazon Elastic Compute Cloud(Amazon EC2) P5 인스턴스를 사전 발표했습니다. 이 인스턴스는 최대 규모의 기계 학습(ML) 모델을 구축하고 훈련하는 데 사용할 수 있는 최대 20엑사플롭스의 컴퓨팅 성능을 제공합니다. 이번 발표는 클러스터 GPU(cg1) 인스턴스(2010), G2(2013), P2(2016), P3(2017), G3(2017), P3dn(2018), G4(2019), P4(2020), G5(2021), P4de 인스턴스(2022) 등을 거치며 비주얼 컴퓨팅, AI 및 고성능 컴퓨팅(HPC) 클러스터를 제공해온 지난 10여 년의 AWS와 NVIDIA 간 협업의 산물입니다.
ML 모델 크기가 이제 파라미터 수조 개에 이르게 되었다는 점이 무엇보다 주목할 만합니다. 하지만 이러한 복잡성으로 인해 고객의 훈련 시간이 늘어났으며, 최신 LLM은 수개월에 걸쳐 훈련을 받게 되었습니다. HPC 고객도 비슷한 추세를 보이고 있습니다. HPC 고객 데이터 수집의 충실도가 높아지고 데이터 세트가 엑사바이트 규모에 도달함에 따라, 고객들은 갈수록 복잡해지는 애플리케이션에서 솔루션 제공 시간을 단축할 방법을 찾고 있습니다.
EC2 P5 인스턴스 소개
오늘 AWS는 AI/ML 및 HPC 워크로드의 고성능 및 확장성에 대한 고객의 요구를 해결해줄 차세대 GPU 인스턴스인 Amazon EC2 P5 인스턴스의 정식 출시를 발표합니다. P5 인스턴스는 최신 NVIDIA H100 Tensor Core GPU로 구동되며 이전 세대 GPU 기반 인스턴스에 비해 훈련 시간을 최대 6배(며칠에서 몇 시간으로) 단축해줍니다. 이러한 성능 향상 덕분에 고객은 훈련 비용을 최대 40% 절감할 수 있습니다.
P5 인스턴스는 640GB의 고대역폭 GPU 메모리, 3세대 AMD EPYC 프로세서, 2TB의 시스템 메모리 및 30TB의 로컬 NVMe 스토리지를 탑재한 8개의 NVIDIA H100 Tensor Core GPU를 제공합니다. 아울러 P5 인스턴스는 GPUDirect RDMA를 지원하는 총 3,200Gbps의 네트워크 대역폭을 제공하므로, 노드 간 통신에서 CPU를 우회하여 지연 시간을 줄이고 효율적인 스케일 아웃 성능을 구현할 수 있습니다.
인스턴스 사양은 다음과 같습니다.
| 인스턴스
크기 |
vCPU | 메모리
(GiB) |
GPU
(H100) |
네트워크 대역폭
(Gbps) |
EBS 대역폭
(Gbps) |
로컬 스토리지
(TB) |
| p5.48xlarge | 192 | 2,048 | 8 | 3,200 | 80 | 8×3.84 |
다음은 P5 인스턴스 및 NVIDIA H100 Tensor Core GPU가 이전 인스턴스 및 프로세서와 어떻게 다른지 비교하는 간단한 인포그래픽입니다.
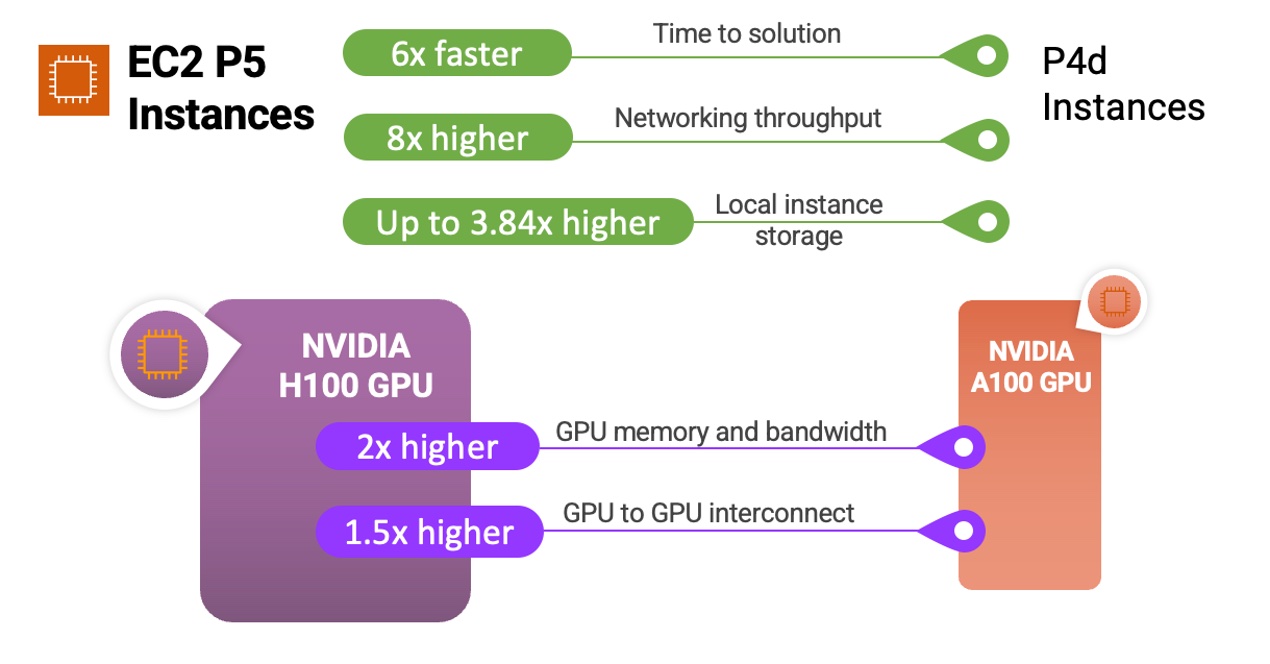
P5 인스턴스는 질문 답변, 코드 생성, 비디오 및 이미지 생성, 음성 인식 등을 비롯하여 가장 까다롭고 컴퓨팅 집약적인 생성형 AI 애플리케이션의 기반으로서 갈수록 복잡해지는 LLM 및 컴퓨터 비전 모델의 추론 훈련 및 실행에 적합한 인스턴스입니다. P5는 이러한 애플리케이션 전반에서 이전 세대 GPU 기반 인스턴스에 비해 최대 6배 더 짧은 훈련 시간을 제공합니다. 트랜스포머 모델 백본을 사용하는 여러 언어 모델에서 흔히 볼 수 있는 정밀도가 낮은 FP8 데이터 유형을 워크로드에 사용하는 고객은 NVIDIA 트랜스포머 엔진에 대한 지원을 통해 최대 6배까지 성능이 향상되는 추가적인 이점을 누릴 수 있습니다.
P5 인스턴스를 사용하는 HPC 고객은 신약 개발, 지진 분석, 일기 예보 및 재무 모델링 사용 사례에서 까다로운 애플리케이션을 대규모로 배포할 수 있습니다. 게놈 시퀀싱이나 가속화된 데이터 분석과 같은 애플리케이션에 동적 프로그래밍(DP) 알고리즘을 사용하는 고객은 새로운 DPX 명령 세트에 대한 지원을 통해 P5의 추가적인 이점을 누릴 수 있습니다.
이를 통해 고객은 이전에는 불가능했던 문제 영역을 탐색하고 더 빠른 속도로 솔루션을 반복하여 제품을 더 빠르게 출시할 수 있습니다.
아래에서 p4d.24xlarge와 새로운 p5.48xlarge의 인스턴스 유형을 서로 비교하고 세부적인 인스턴스 사양을 확인할 수 있습니다.
| 기능 | p4d.24xlarge | p5.48xlarge | 비교 |
| 액셀러레이터 수 및 유형 | 8 x NVIDIA A100 | 8 x NVIDIA H100 | – |
| 서버당 FP8 TFLOPS | – | 1만 6,000 |
6.4x vs. A100 FP16 |
| 서버당 FP16 TFLOPS | 2,496 | 8,000 | |
| GPU 메모리 | 40GB | 80GB | 2x |
| GPU 메모리 대역폭 | 12.8TB/초 | 26.8TB/초 | 2x |
| CPU 패밀리 | 인텔 캐스케이드 레이크 | AMD Milan | – |
| vCPU | 96 | 192 | 2x |
| 총 시스템 메모리 | 1,152GB | 2,048GB | 2x |
| 네트워킹 처리량 | 400Gbps | 3,200Gbps | 8x |
| EBS 처리량 | 19Gbps | 80Gbps | 4x |
| 로컬 인스턴스 스토리지 | 8TB NVMe | 30TB NVMe | 3.75x |
| GPU 간 상호 연결 | 600GB/초 | 900GB/초 | 1.5x |
2세대 Amazon EC2 UltraClusters 및 Elastic Fabric Adaptor
P5 인스턴스는 다중 노드 분산 훈련 및 밀결합된 HPC 워크로드를 위한 업계 최고의 스케일 아웃 기능을 제공합니다. 2세대 Elastic Fabric Adaptor(EFA) 기술을 사용하여 최대 3,200Gbps의 네트워킹을 제공하며, 이는 P4d 인스턴스와 비교해 8배 향상된 성능입니다.
큰 규모와 짧은 지연 시간에 대한 고객의 요구를 충족하기 위해, 2세대 EC2 UltraClusters에 P5 인스턴스가 배포되었습니다. 2세대 EC2 UltraClusters는 최대 2만 개 이상의 NVIDIA H100 Tensor Core GPU를 활용하여 더 짧은 지연 시간을 제공합니다. 클라우드에서 최대 규모의 ML 인프라를 제공하는 EC2 UltraClusters의 P5 인스턴스는 최대 20엑사플롭스의 총 컴퓨팅 용량을 제공합니다.

EC2 UltraClusters는 가장 널리 사용되는 고성능 병렬 파일 시스템을 기반으로 구축된 완전관리형 공유 스토리지인 Amazon FSx for Lustre를 사용합니다. FSx for Lustre를 사용하면 방대한 데이터 세트를 온디맨드 방식으로, 대규모로 신속하게 처리하고 1밀리초 미만의 지연 시간을 제공할 수 있습니다. FSx for Lustre의 짧은 지연 시간과 높은 처리량 특성은 EC2 UltraClusters의 딥 러닝, 생성형 AI 및 HPC 워크로드에 최적화되어 있습니다.
FSx for Lustre는 EC2 UltraClusters의 GPU 및 ML 액셀러레이터에 데이터를 공급하여 가장 까다로운 워크로드를 가속화합니다. 이러한 워크로드에는 LLM 훈련, 생성형 AI 추론, 유전체학 및 재무 위험 모델링과 같은 HPC 워크로드가 포함됩니다.
EC2 P5 인스턴스 시작하기
미국 동부(버지니아 북부) 및 미국 서부(오레곤) 리전의 P5 인스턴스를 사용하여 시작할 수 있습니다.
P5 인스턴스를 시작할 때는 P5 인스턴스를 지원하도록 AWS Deep Learning AMI(DLAMI)를 선택합니다. DLAMI는 사전 구성된 환경에서 확장 가능하고 안전한 분산 ML 애플리케이션을 신속하게 구축할 수 있는 인프라와 도구를 ML 실무자와 연구원에게 제공합니다.
Amazon Elastic Container Service(Amazon ECS) 또는 Amazon Elastic Kubernetes Service(Amazon EKS)용 라이브러리를 사용한 AWS 딥 러닝 컨테이너로 P5 인스턴스에서 컨테이너화된 애플리케이션을 실행할 수 있습니다. 관리형 경험을 구현하려는 경우에는 Amazon SageMaker를 통해 P5 인스턴스를 사용할 수 있습니다. Amazon SageMaker는 개발자 및 데이터 사이언티스트가 수십, 수백 또는 수천 개의 GPU로 손쉽게 확장하여 클러스터 및 데이터 파이프라인을 설정하는 번거로움 없이 어떤 규모로든 신속하게 모델을 훈련할 수 있도록 지원합니다. HPC 고객은 P5와 함께 AWS Batch 및 ParallelCluster를 활용하여 작업과 클러스터를 효율적으로 오케스트레이션할 수 있습니다.
기존 P4 고객이 P5 인스턴스를 사용하려면 AMI를 업데이트해야 합니다. 특히, NVIDIA H100 Tensor Core GPU를 지원하는 최신 NVIDIA 드라이버를 포함하도록 AMI를 업데이트해야 합니다. 또한 최신 CUDA 버전(CUDA 12), CuDNN 버전, 프레임워크 버전(예: PyTorch, Tensorflow) 및 업데이트된 토폴로지 파일이 포함된 EFA 드라이버를 설치해야 합니다. 이 프로세스를 쉽게 수행할 수 있도록, P5 인스턴스를 즉시 사용하는 데 필요한 모든 소프트웨어 및 프레임워크가 사전 패키징된 새로운 DLAMI와 딥 러닝 컨테이너를 제공합니다.
정식 출시
Amazon EC2 P5 인스턴스는 현재 미국 동부(버지니아 북부) 및 미국 서부(오레곤) AWS 리전에서 사용할 수 있습니다. 자세한 내용은 Amazon EC2 요금 페이지를 참조하세요. 더 자세한 정보는 P5 인스턴스 페이지를 방문하여 EC2용 AWS re:Post를 살펴보거나 AWS Support 담당자에게 문의하세요.
생성형 AI가 내장된 다양한 AWS 서비스를 선택할 수 있으며, 이러한 모든 서비스는 생성형 AI에 최적화된 비용 효율성을 제공하는 클라우드 인프라에서 실행됩니다. AWS 기반 생성형 AI에서 자세한 내용을 참조하여 혁신을 가속화하고 애플리케이션의 패러다임을 바꾸세요.
– Channy