Amazon Web Services 한국 블로그
AWS IoT Greengrass, 엣지의 컨테이너 지원 및 데이터 스트림 관리 기능 추가
AWS IoT Greengrass는 클라우드 기능의 적용 범위를 엣지 디바이스로 확장하여 간헐적인 연결을 통해서도 실시간에 가깝게 로컬 이벤트에 응답할 수 있도록 합니다.
오늘 IoT 솔루션을 보다 손쉽게 구축할 수 있는 두 가지 기능을 추가합니다.
- Greengrass Docker 애플리케이션 배포 커넥터를 사용한 애플리케이션 배포를 지원해보십시오.
- Stream Manager for AWS IoT Greengrass로 엣지 디바이스에서 데이터 스트림을 수집하고 처리하고 내보내며, 해당 데이터의 수명 주기를 관리하십시오.
그럼 새로운 기능의 작동 방식과 사용 방법을 알아보겠습니다.
Greengrass 코어 디바이스에 컨테이너 기반 애플리케이션 배포
이제 AWS Lambda 함수와 컨테이너 기반 애플리케이션을 AWS IoT Greengrass 코어 디바이스에서 실행할 수 있습니다. 이렇게 하면 컨테이너 이미지를 사용하여 온프레미스에서 애플리케이션을 마이그레이션하거나, 라이브러리, 기타 이진 파일 및 구성 파일과 같은 종속성을 포함하는 새 애플리케이션을 구축하기가 더 쉬워집니다. 따라서 애플리케이션에 일관된 배포 환경을 제공하여 개발 환경 및 엣지 로케이션 간에 이동성을 확보할 수 있습니다. 코드 또는 실행 파일을 컨테이너 이미지에 패키징하여 레거시 및 타사 애플리케이션을 쉽게 배포할 수 있습니다.
이 기능을 사용하기 위해 Docker Compose 파일을 사용하여 컨테이너 기반 애플리케이션을 설명합니다. 컨테이너 이미지는 Amazon Elastic Container Registry(ECR) 또는 Docker Hub와 같은 공용 또는 개인 저장소에서 참조할 수 있습니다. 시작하기 위해 먼저 Python과 시각화 횟수를 카운팅하는 Flask를 사용하여 간단한 웹 앱을 만듭니다.
from flask import Flask
app = Flask(__name__)
counter = 0
@app.route('/')
def hello():
global counter
counter += 1
return 'Hello World! I have been seen {} times.\n'.format(counter)
requirements.txt 파일에는 flask라는 단일 종속 항목이 포함되어 있습니다.
이 Docker 파일을 사용하여 컨테이너 이미지를 작성하고 ECR로 푸시합니다.
FROM python:3.7-alpine
WORKDIR /code
ENV FLASK_APP app.py
ENV FLASK_RUN_HOST 0.0.0.0
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
COPY . .
CMD ["flask", "run"]
ECR 리포지토리의 컨테이너 이미지를 참조하는 docker-compose.yml 파일은 다음과 같습니다. Docker Compose 파일은 여러 컨테이너를 사용하여 애플리케이션을 설명할 수 있지만 이 예에서는 하나만 사용합니다.
version: '3'
services:
web:
image: "123412341234.dkr.ecr.us-east-1.amazonaws.com/hello-world-counter:latest"
ports:
- "80:5000"
docker-compose.yml 파일을 Amazon Simple Storage Service(S3) 버킷에 업로드합니다.
이제Amazon Elastic Compute Cloud(EC2) 인스턴스를 코어 디바이스로 사용하여 AWS IoT Greengrass 그룹을 생성합니다. 일반적으로 디바이스는 AWS 클라우드 외부에 있지만 EC2 인스턴스를 사용하면 엣지에서 배포를 위한 개발 및 테스트 환경을 설정하고 자동화할 수 있습니다.
그룹이 준비되면 모든 구성 요소가 예상대로 작동하는지 확인하기 위해 “빈” 배포를 실행합니다. 몇 초 후, 첫 번째 배포가 완료되면 커넥터를 추가하기 시작합니다.

AWS IoT Greengrass 그룹의 커넥터 섹션에서 [Add a connector]를 선택하고 “Docker”를 검색합니다. [Docker Application Deployment]를 선택하고 [Next]를 누릅니다.

이제 커넥터의 파리미터를 구성할 수 있습니다. S3에서 docker-compose.yml 파일을 선택합니다. AWS IoT Greengrass 그룹에 사용되는 AWS Identity and Access Management(IAM) 역할에는 S3에서 파일을 가져오고 인증 토큰을 가져오고 ECR에서 이미지를 다운로드할 수 있는 권한이 필요합니다. Docker Hub와 같은 개인 저장소를 사용하는 경우 AWS Secret Manager와의 통합을 통해 커넥터 및 Lamda 함수가 로컬 암호를 사용하여 서비스 및 응용 프로그램과 쉽게 상호 작용하도록 할 수 있습니다.

이전에 한 것과 유사하게 변경 사항을 배포합니다. 이번에는 새 컨테이너 기반 애플리케이션이 AWS IoT Greengrass 코어 디바이스에 설치되고 시작됩니다.

배포한 웹 앱을 테스트하기 위해 현재 코어 디바이스로 사용 중인 EC2 인스턴스의 보안 그룹에서 HTTP 포트에 대한 액세스를 개방합니다. 브라우저로 연결하면 Flask 앱이 방문 횟수를 카운팅하는 것을 확인할 수 있습니다. 컨테이너 기반 애플리케이션이 AWS IoT Greengrass 코어 디바이스에서 실행되고 있습니다.
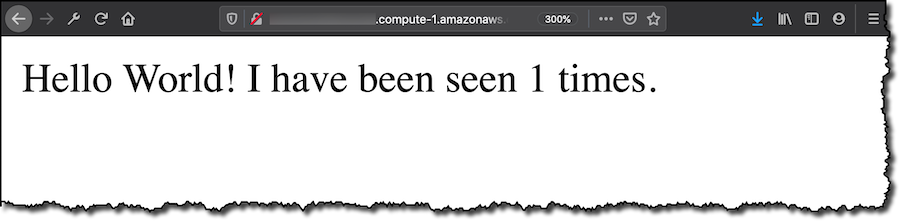
이 예의 애플리케이션보다 훨씬 복잡한 애플리케이션을 배포할 수 있습니다. 다음으로, 오늘 릴리스된 다른 기능을 살펴보겠습니다.
AWS IoT Greengrass에 Stream Manager 사용
동영상 처리, 이미지 인식 또는 엣지의 센서로부터 대량 데이터 수집과 같은 일반적인 사용 사례의 경우, 고유한 데이터 스트림 관리 기능을 구축해야 하는 경우가 많습니다. 새로운 Stream Manager는 IoT 장치의 데이터 스트림을 처리하는 데 사용할 수 있는 표준화된 메커니즘을 Greengrass Core SDK에 추가하고, 캐시 크기 또는 데이터 사용 기간을 기준으로 로컬 데이터 보존 정책을 관리하고, Amazon Kinesis 및 AWS IoT Analytics 같은 AWS 클라우드 서비스에 직접 데이터를 자동으로 전송하여 이 프로세스를 간소화합니다.
또한 Stream Manager는 구성 가능한 우선 순위 지정, 캐싱 정책, 대역폭 사용률 및 제한 시간을 스트림별로 추가하여 연결 끊김 또는 간헐적 연결 시나리오를 처리합니다. 연결을 예측할 수 없거나 대역폭이 제한되는 상황에서 이 새로운 기능을 사용하면 연결이 끊기거나, 재연결 중이거나, 연결된 상태별로 애플리케이션의 데이터 관리 동작을 정의할 수 있으므로 중요한 데이터의 클라우드 경로에 우선 순위를 지정하고 연결이 가능할 때 연결을 효율적으로 사용할 수 있습니다. 이 기능을 사용하면 데이터 보존 및 연결 관리 기능을 구축하는 것이 아니라 특정 애플리케이션 사용 사례에 집중할 수 있습니다.
이제 실제 사용 사례에서 Stream Manager가 어떻게 작동하는지 살펴보겠습니다. 예를 들어 AWS IoT Greengrass 코어 디바이스는 여러 디바이스에서 많은 양의 데이터를 수신합니다. 수집하는 데이터에 대해 다음 두 가지 작업을 수행하려고 합니다.
- 우선 순위가 낮은 모든 행 데이터를 AWS IoT Analytics에 업로드합니다. 여기서는 Amazon QuickSight를 사용하여 데이터를 시각화하고 파악합니다.
- 디바이스의 시간과 위치를 기준으로 로컬로 데이터를 집계하고, 예측 유지 관리를 위해 비즈니스 애플리케이션에서 처리되는 Kinesis Data Stream에 우선 순위가 높은 집계 데이터를 전송합니다.
Greengrass Core SDK의 Stream Manager를 사용하여 다음 2개의 로컬 데이터 스트림을 생성합니다.
- 첫 번째 로컬 데이터 스트림에는 IoT Analytics로의 낮은 우선 순위 내보내기가 구성되어 있으며 최대 256MB의 로컬 디스크(예: 제한된 디바이스)를 사용할 수 있습니다. 복원력보다 속도를 원하는 경우 메모리를 사용하여 로컬 데이터 스트림을 저장할 수 있습니다. 예를 들어 클라우드에 대한 연결이 끊긴 상태에서 로컬로 계속 캐싱하여 로컬 공간이 채워질 경우 새 데이터를 거부하거나 가장 오래된 데이터를 덮어쓰도록 선택할 수 있습니다.
- 두 번째 로컬 데이터 스트림은 우선 순위가 높은 데이터를 Kinesis Data Stream으로 내보내며, 최대 128MB의 로컬 디스크를 사용할 수 있습니다(집계된 데이터이므로 동일한 시간 동안 필요한 공간이 더 적음).

이 아키텍처의 데이터 흐름은 다음과 같습니다.
- 센서 데이터는 첫 번째 로컬 데이터 스트림에 데이터를 쓰는 Producer Lambda 함수에 의해 수집됩니다.
- 두 번째 Aggregator Lambda 함수는 첫 번째 로컬 데이터 스트림에서 읽기를 수행하여 해당 출력을 두 번째 로컬 데이터 스트림에 씁니다.
- Reader 컨테이너 기반 앱(Docker 애플리케이션 배포 커넥터를 사용하여 배포됨)이 디스플레이 패널에 대해 집계된 데이터를 실시간으로 렌더링합니다.
- Stream Manager가 로컬 데이터 스트림의 구성 및 정책에 따라 클라우드의 수집을 관리하므로 개발자는 장치의 로직과 관련한 작업에 집중할 수 있습니다.
이전 아키텍처에서 Lambda 함수 또는 컨테이너 기반 앱을 사용하는 것은 하나의 예일 뿐입니다. 개발 모범 사례에 따라 혼합하여 사용하거나 둘 중 하나로 표준화할 수 있습니다
지금 이용 가능
Docker 애플리케이션 배포 커넥터와 Stream Manager는 Greengrass 버전 1.10에서 사용할 수 있습니다. Stream Manager는 Java 및 Python용 Greengrass Core SDK에서 사용할 수 있습니다. 고객 피드백을 바탕으로 다른 플랫폼에 대한 지원을 추가할 예정입니다.
이러한 새로운 기능은 서로 독립적이지만 이 예에서와 같이 함께 사용할 수 있습니다. 또한 엣지 디바이스에 애플리케이션을 구축하고 배포하는 방식을 간소화하여, 로컬에서 데이터를 보다 쉽게 처리하고 백엔드에서 스트리밍 및 분석 서비스와 통합할 수 있습니다. 앞으로 이 기능을 어떻게 사용할 것인지에 대해 경험을 공유해주세요!
— Danilo