- AWS Solutions Library
- Guidance for Connecting Data Sources for Advertising and Marketing Analytical Workloads on AWS
Guidance for Connecting Data Sources for Advertising and Marketing Analytical Workloads on AWS
Overview
How it works
Overview
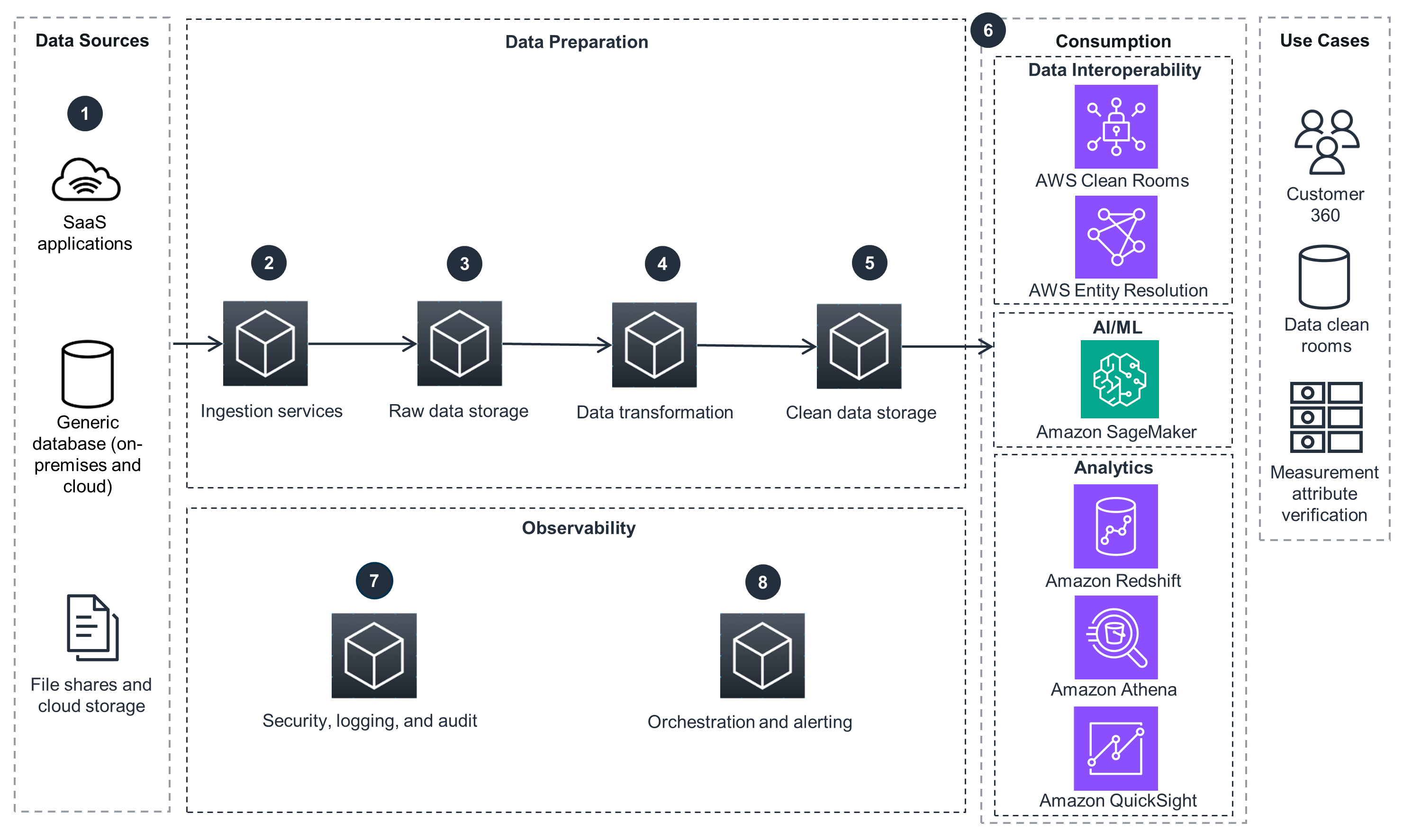
This architecture diagram shows an overview of how to connect data sources stored in a variety of data sources to AWS.
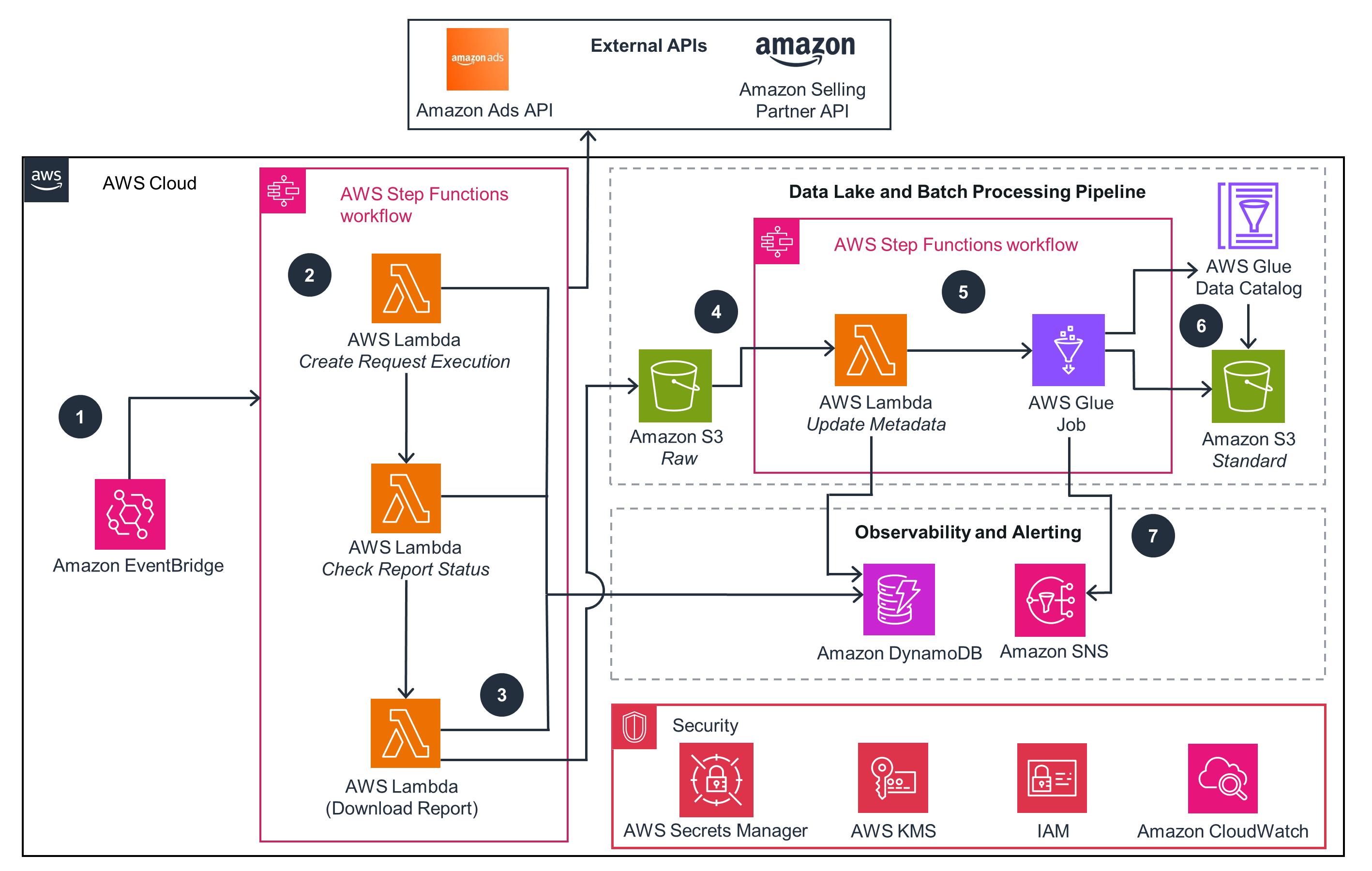
Connecting Amazon Ads and Amazon Selling Partner Data to AWS – API Pull Pattern with AWS Lambda
This architecture diagram shows data ingestion and integration patterns for the Amazon Ads and Amazon Selling Partner APIs.
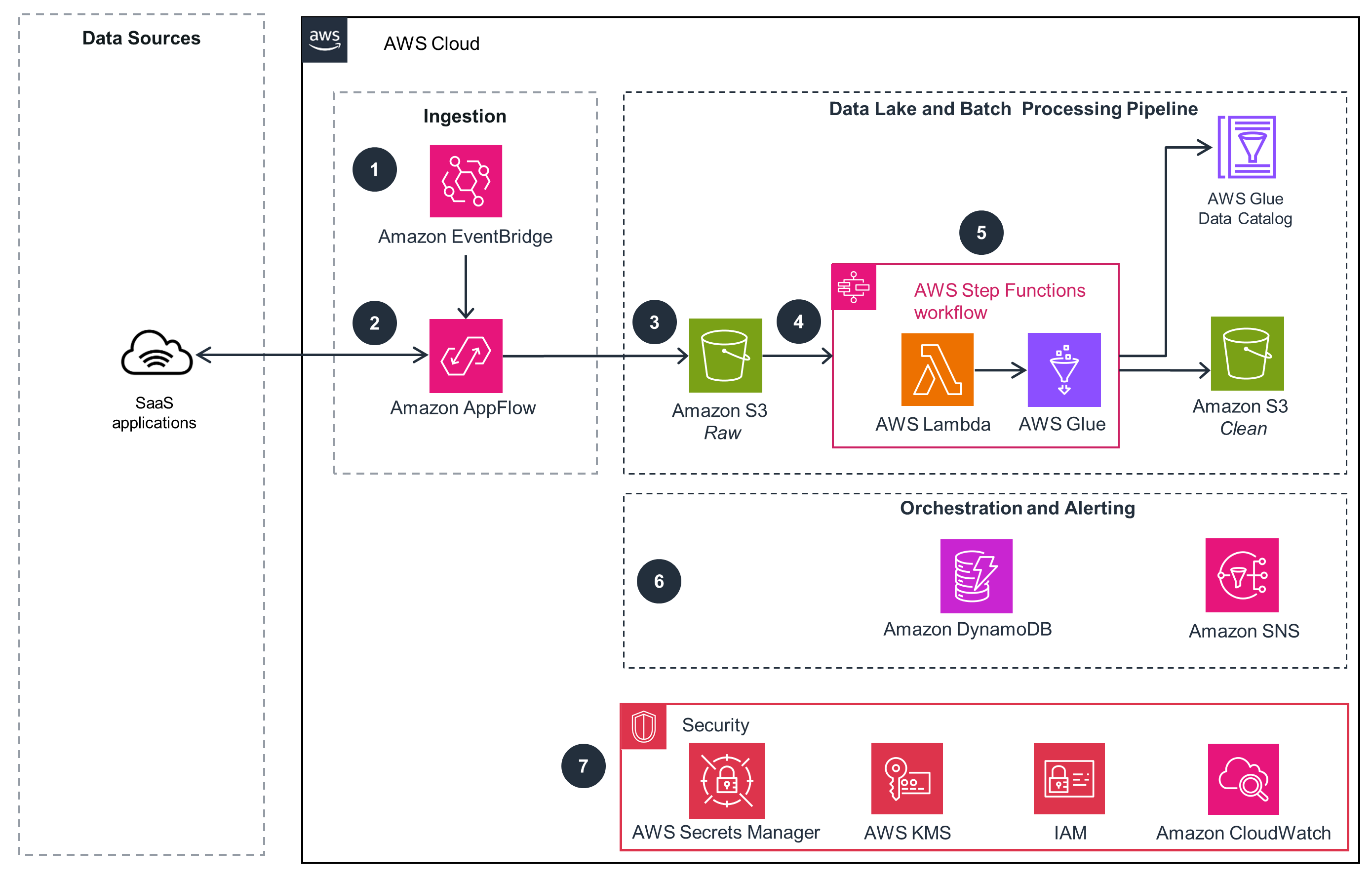
Connecting SaaS Application Data to AWS – API Pull Pattern with Amazon AppFlow
This architecture diagram shows introduces data ingestion and a pull pattern for data available in SaaS applications.
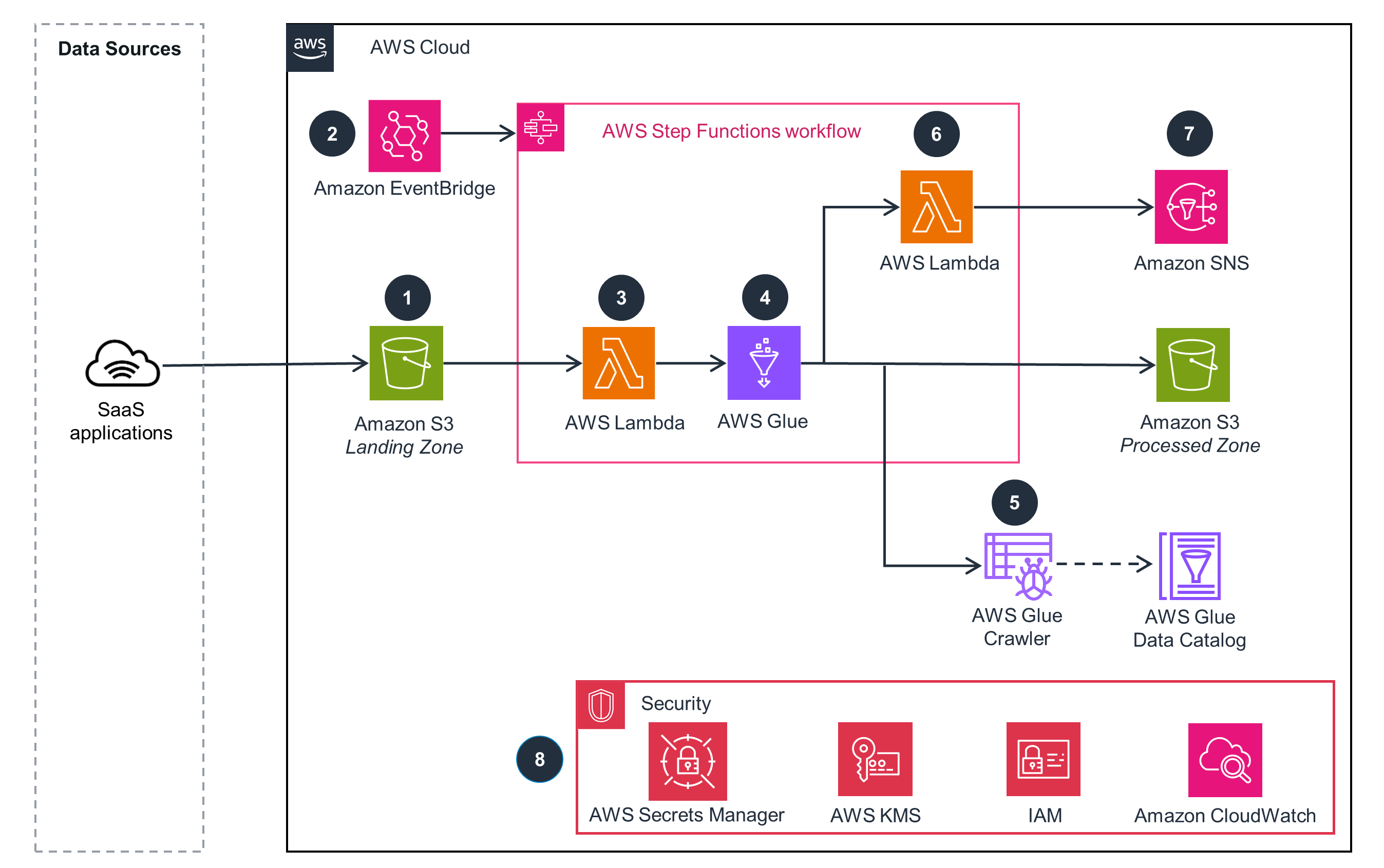
Connecting SaaS Applications to AWS – Push Pattern with Amazon S3
This architecture diagram shows data ingestion and a push pattern for data available in SaaS applications.
Connecting RDBMS Sources to AWS – Batch Pull and Change Data Capture Pattern
This architecture diagram shows how to build a connector for relational database management systems (RDBMS) to AWS.
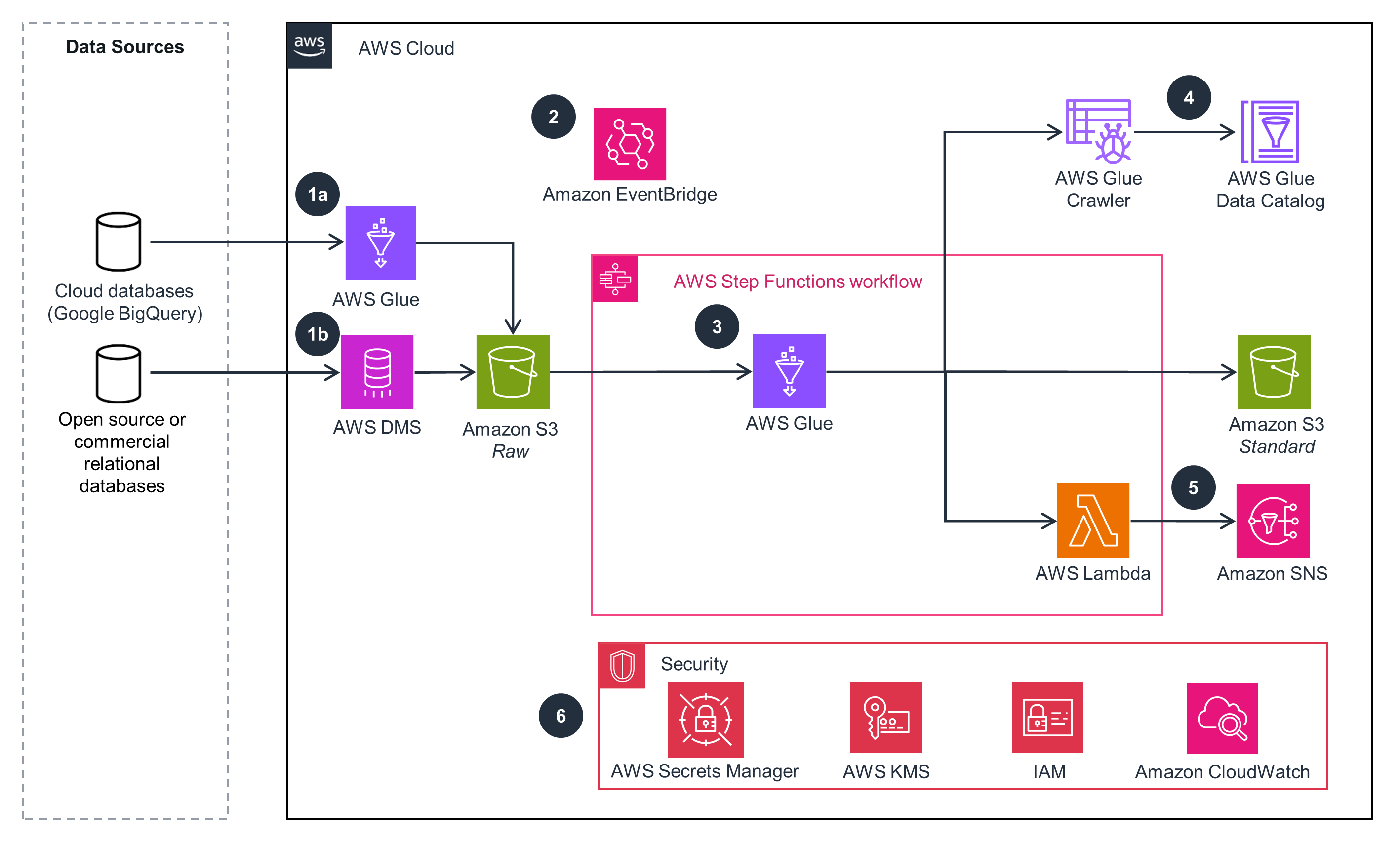
How it works (continued)
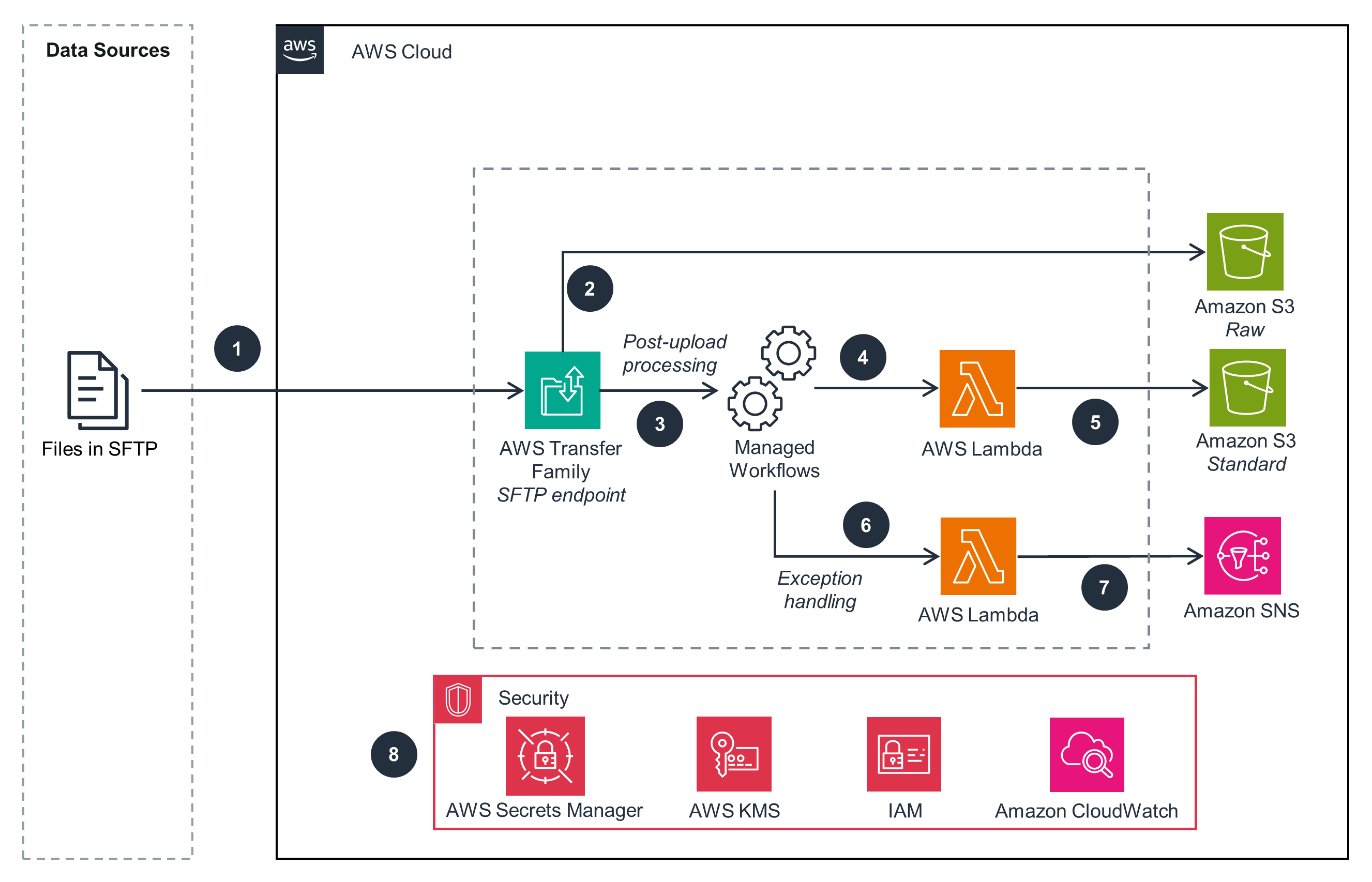
Connecting SFTP Data Sources to AWS – Managed File Transfer Pattern
This architecture diagram shows how to build a connector for file systems to AWS.
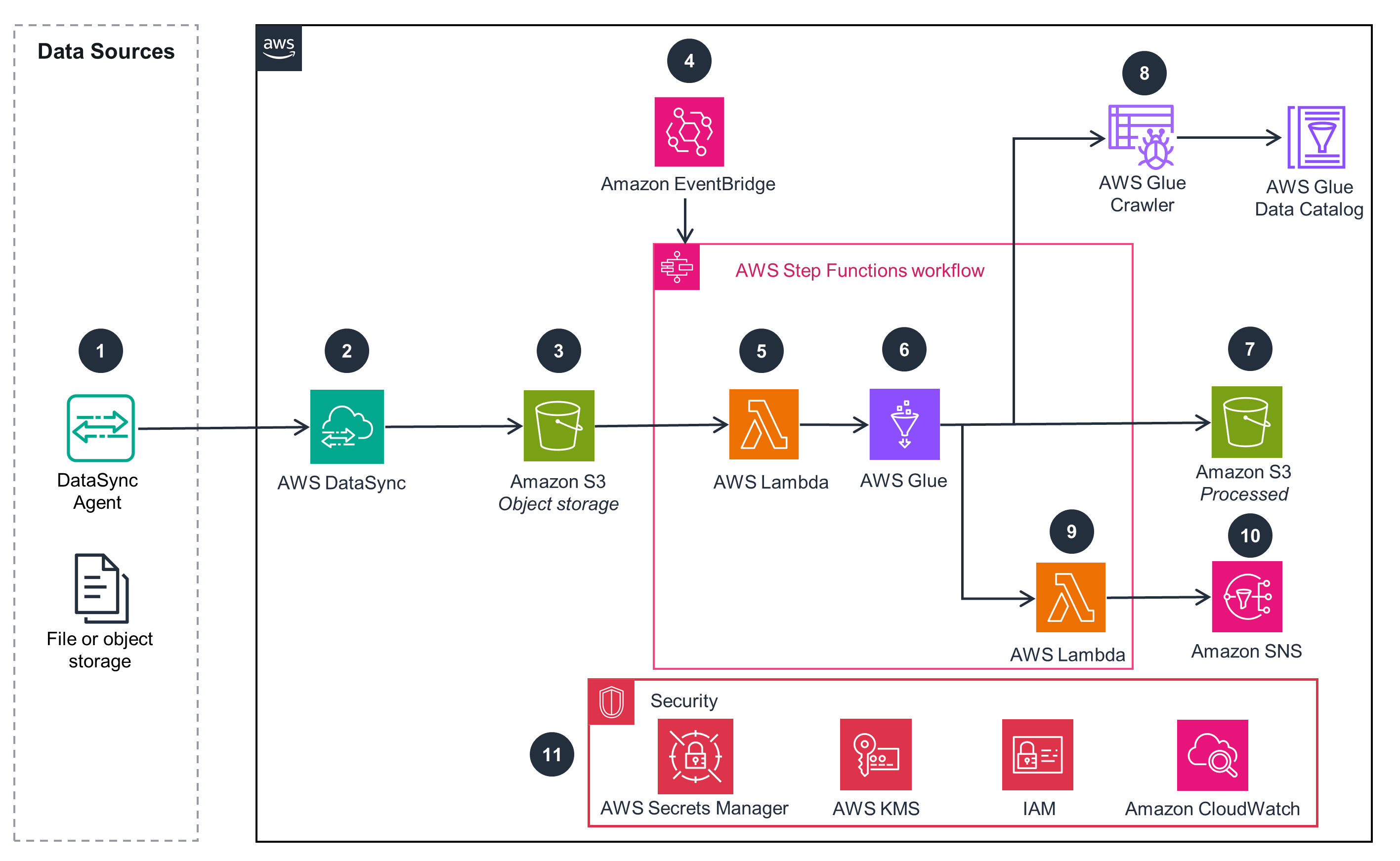
Connecting File and Cloud Object Storage to AWS – File Replication Pattern
This architecture diagram shows how to build a connector for cloud-based object storage services to AWS.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
The services in this Guidance are serverless, which eliminates the need for users to manage (virtual or bare metal) servers. For example, Step Functions is a serverless managed service for building workflows and reduces undifferentiated heavy lifting associated with building and managing a workflow solution. AWS Glue is a serverless managed service for data processing tasks.
Similarly, the following services eliminate the need for capacity management: Amazon SNS for notifications, AWS KMS for key management, Secrets Manager for secrets, EventBridge for event driven architectures, DynamoDB for low-latency NoSQL databases, AppFlow for integrating with third-party applications, Transfer Family for file transfer protocols, DataSync for discovery and sync of remote data sources (on-premises or other clouds), and AWS DMS for a managed data migration service that simplifies migration between supported databases.
IAM manages least privilege access to specific resources and operations. AWS KMS provides encryption for data at rest and data in transit using Pretty Good Privacy (PGP) encryption of data files. Secrets Manager provides secrets for remote system access and hashing keys for personally identifiable information (PII) data. CloudWatch monitors logs and metrics across all services used in this Guidance. As managed services, these services not only support a security strong posture, but help free up time for you to focus efforts on data and application logic for fortified security.
Use of Lambda in the pipeline is limited to file-level processing, such as decryption. This avoids the pipeline from hitting the 15-minute run time limit. For all row-level processing, AWS Glue Spark engine scales to handle large volume of data processing. Additionally, you can use Step Functions to set up retries, back-off rates, max attempts, intervals, and timeouts for any failed AWS Glue job.
The serverless services in this Guidance (including Step Functions, AWS Glue, Lambda, EventBridge, and Amazon S3) reduce the amount of underlying infrastructure you need to manage, allowing you to focus on solving your business needs. You can use automated deployments to quickly deploy the architectural components into any AWS Region while also addressing data residency and low latency requirements.
When AWS Glue performs data transformations, you only pay for infrastructure during the time the processing is occurring. For Data Catalog, you pay a simple monthly fee for storing and accessing the metadata. With EventBridge Free Tier, you can schedule rules to initiate a data processing workflow. With a Step Functions workflow, you are charged based on the number of state transitions. In addition, through a tenant isolation model and resource tagging, you can automate cost usage alerts to help you measure costs specific to each tenant, application module, and service.
Serverless services used in this Guidance (such as AWS Glue, Lambda, and Amazon S3) automatically optimize resource utilization in response to demand. You can extend this Guidance by using Amazon S3 lifecycle configuration to define policies that move objects to different storage classes based on access patterns.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages