Guidance for Industrial Data Fabric with HighByte Intelligence Hub on AWS
Overview
This Guidance combines AWS IoT SiteWise with HighByte Intelligence Hub to facilitate the transformation of manufacturing and industrial operations through a proven, governed, data-driven approach. HighByte Intelligence Hub serves as an edge-native DataOps solution, bridging the gap between operational technology (OT) and IT by integrating industrial information across diverse systems. With this Guidance, you can achieve a Unified Namespace (UNS) that helps ensure seamless data access and integration throughout the manufacturing enterprise's lifecycle.
This Guidance facilitates the establishment and upkeep of an enterprise-governed asset model across remote sites with central and remote HighByte Intelligence Hubs. The central Intelligence Hub enables the creation and maintenance of an enterprise-governed asset hierarchy and model across remote sites, while remote Intelligence Hubs at the site level aid in ingesting data from different industrial edge data sources. This provides an effortless publishing process to AWS IoT SiteWise, a purpose-built AWS industrial Internet of Things (IoT) service.
Note: See Disclaimer below
How it works
Delivering Industrial DataOps (IDO) on Industrial Data Fabric (IDF)
This high-level architecture diagram is a reference that helps you create an enterprise governed model, ingest near real-time and historical data at scale from edge data sources into an IDF on AWS, and interface with applications using REST APIs.
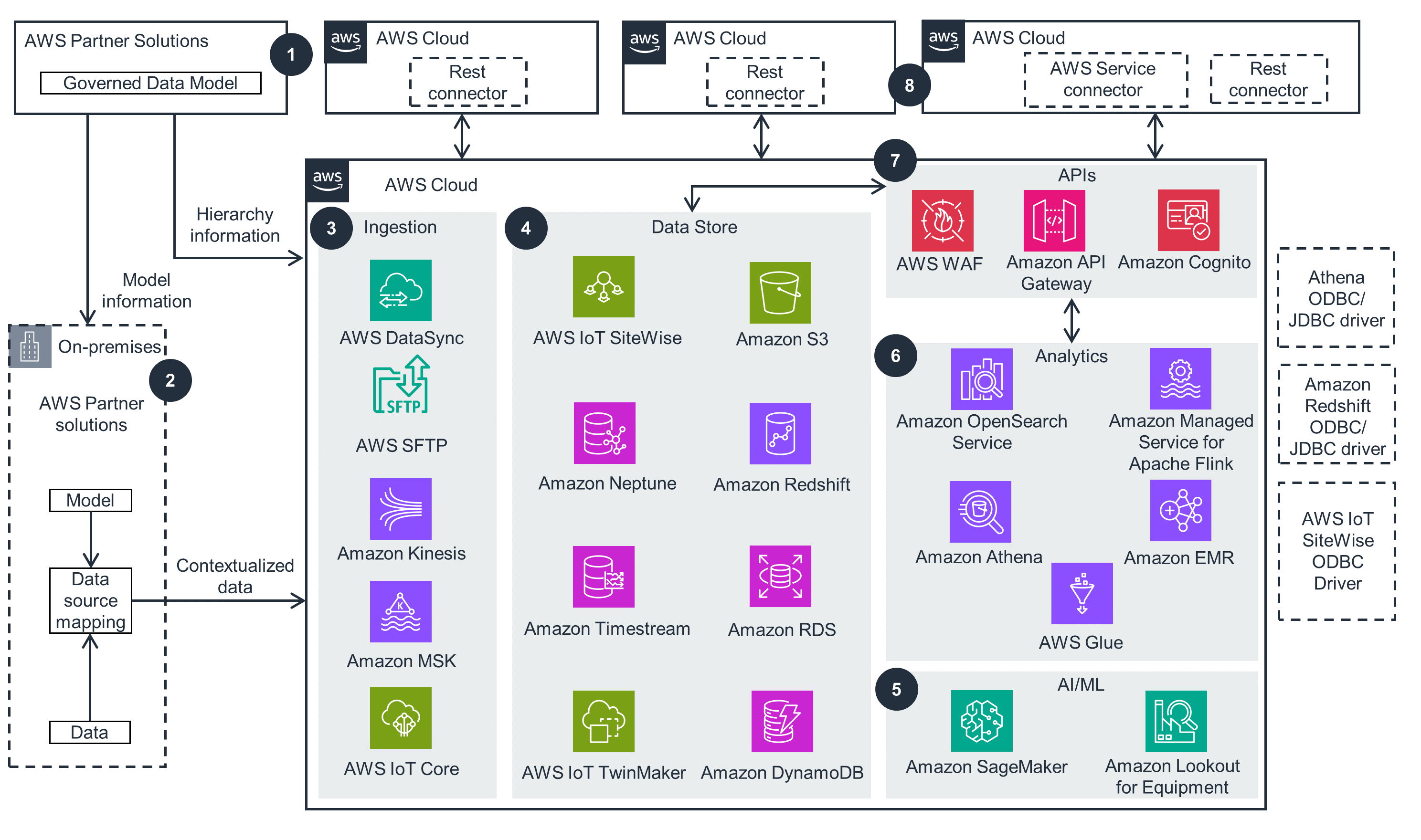
IDF Governed Data Model with HighByte Intelligence Hub
This architecture diagram helps you create an enterprise governed data model, ingest real-time and historical data at scale from edge data sources, and visualize this data using Amazon Managed Grafana. AWS IoT SiteWise provides a contextualized timeseries data store and AWS IoT TwinMaker allows for digital twin scenes.
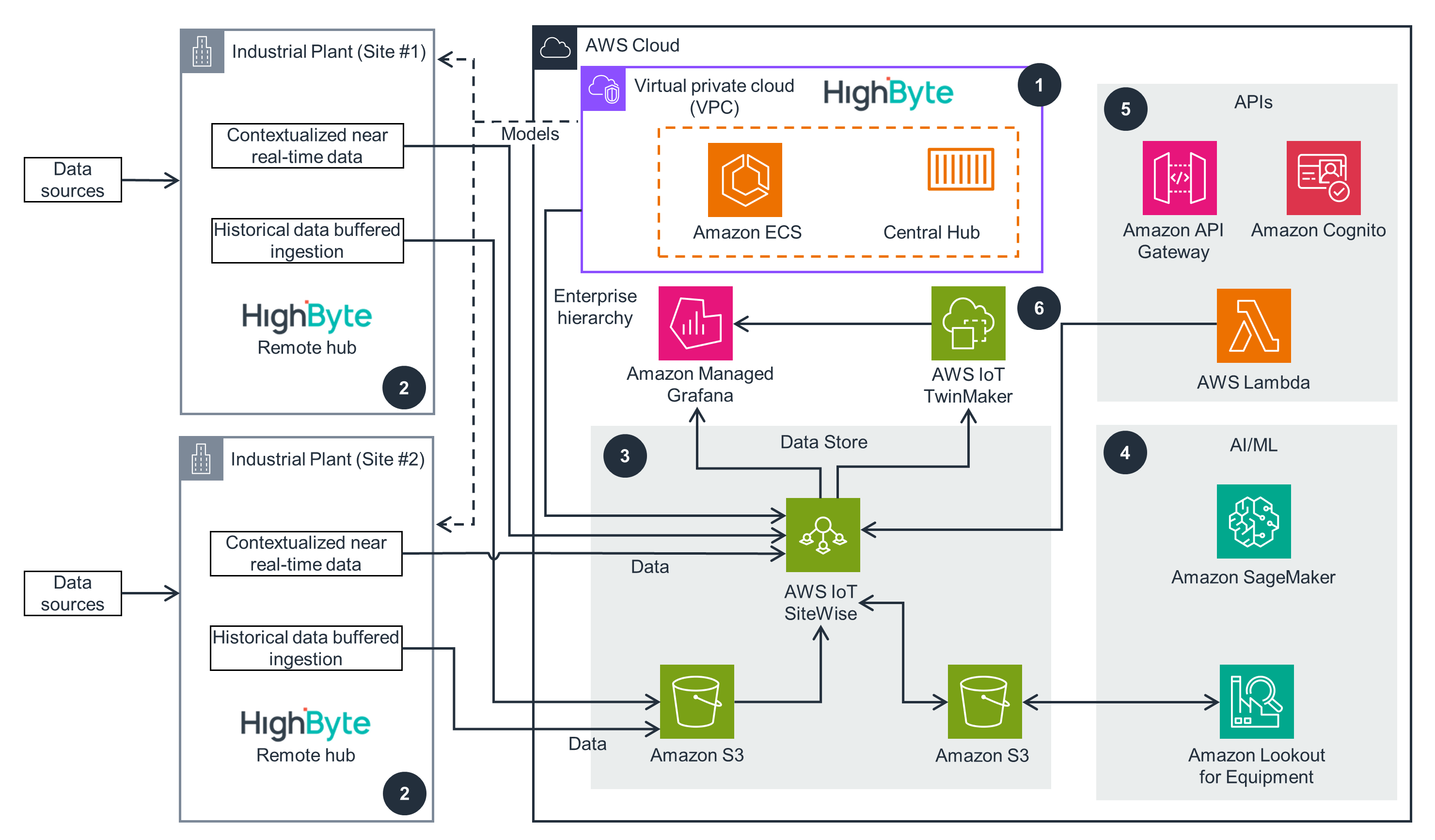
HighByte Intelligence Hub Industrial DataOps on AWS
This architecture diagram demonstrates how HighByte Intelligence Hub integrates OT with IT to combine industrial information across multiple systems, enabling OT teams to model, transform, and share plant floor data with IT systems.
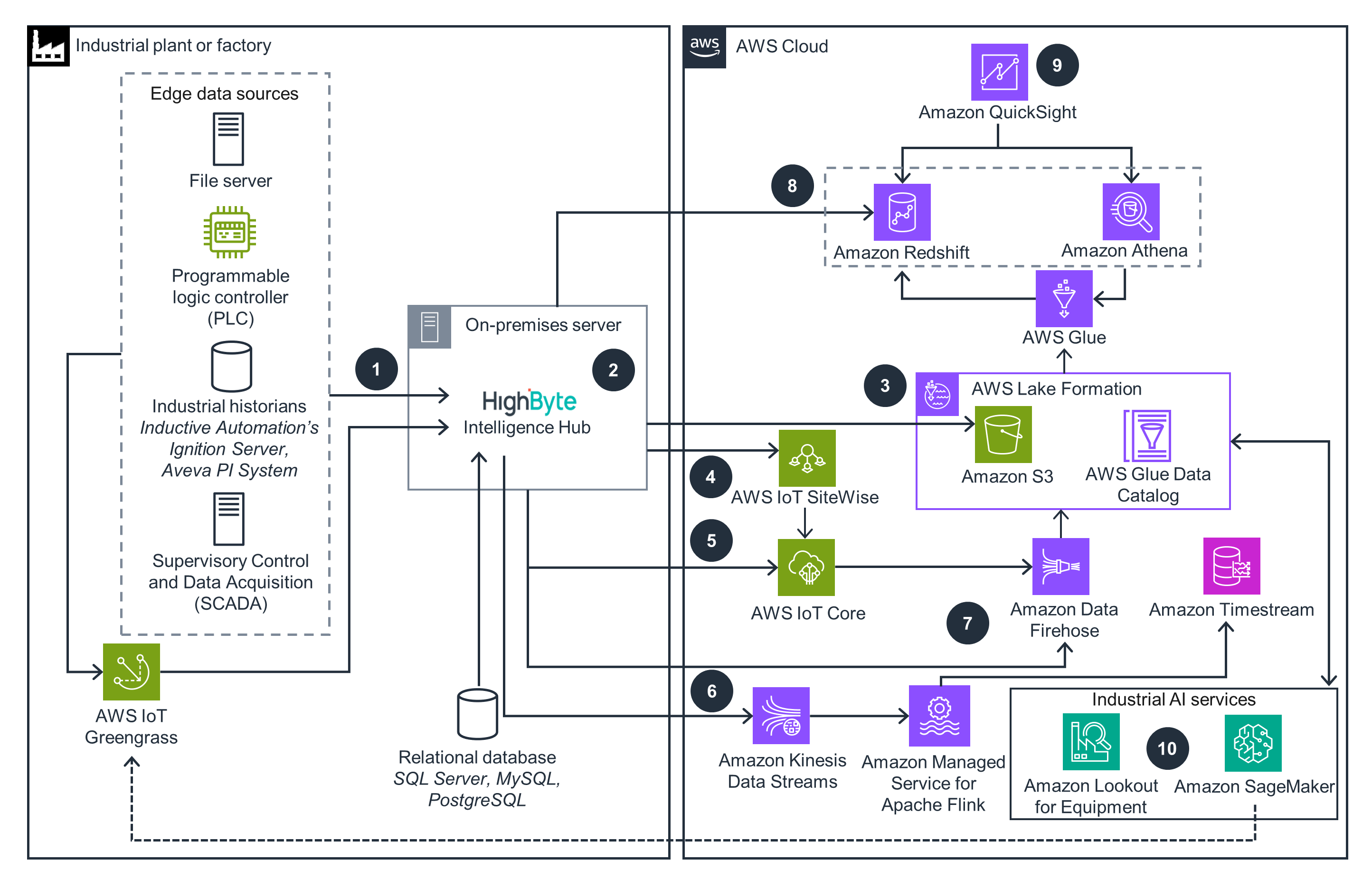
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
The majority of AWS services used by this Guidance, such as Amazon S3 and API Gateway, are serverless, lowering the operational overhead of maintaining the Guidance. This also allows you to evolve the design pattern in a continuous cycle of improvement over time.
This Guidance leverages AWS Security Token Service (AWS STS) and Amazon Cognito. These services allow you to take advantage of cloud technologies to protect data, systems, and assets in a way that can improve your security posture.
Security Best Practices for Manufacturing OT describes how to design, deploy, and secure distributed manufacturing workloads and resources at the industrial edge.
This Guidance uses many of the AWS managed services to allow for a highly available network topology. Availability and reliability are managed on your behalf by AWS service teams (for example, Amazon S3, AWS IoT SiteWise, and Amazon Cognito).
This Guidance uses purpose-built storage services, such as Amazon S3, that can reduce latency and increase throughput. You can use cross-region replication (CRR) to provide lower-latency data access to different geographic Regions. This Guidance provides multiple data-driven approaches to meet your workload requirements of scaling, traffic, and data access patterns.
This Guidance uses purpose-built storage services, such as Amazon S3, that can reduce latency and increase throughput.
This Guidance utilizes scalable services, such as Amazon S3, to align the services to your needs. Its functionalities are implemented by using a serverless architecture (including Amazon Cognito and API Gateway). Your resources are available only when needed and do not run constantly.
Related Content
Partner Solution
Start by building your own platform the focuses on liberating plant data from EDGE to cloud with context
Disclaimer
The sample code; software libraries; command line tools; proofs of concept; templates; or other related technology (including any of the foregoing that are provided by our personnel) is provided to you as AWS Content under the AWS Customer Agreement, or the relevant written agreement between you and AWS (whichever applies). You should not use this AWS Content in your production accounts, or on production or other critical data. You are responsible for testing, securing, and optimizing the AWS Content, such as sample code, as appropriate for production grade use based on your specific quality control practices and standards. Deploying AWS Content may incur AWS charges for creating or using AWS chargeable resources, such as running Amazon EC2 instances or using Amazon S3 storage.
References to third-party services or organizations in this Guidance do not imply an endorsement, sponsorship, or affiliation between Amazon or AWS and the third party. Guidance from AWS is a technical starting point, and you can customize your integration with third-party services when you deploy the architecture.
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages