Containers
Manage scale-to-zero scenarios with Karpenter and Serverless
March 2024: This blog has been updated for Karpenter version v0.33.1 and v1beta1 specification.
Introduction
Cluster autoscaler, has been the de facto industry standard autoscaling mechanism on kubernetes since the very early version of the platform. However, with the evolving complexity and number of containerized workloads, our customers running on Amazon Elastic Kubernetes Service (Amazon EKS) started to ask for a more flexible way to allocate compute resources to pods and flexibility in instance size and heterogeneity. We addressed those needs with karpenter, a product that automatically launches just the right compute resources to handle your cluster’s applications. Karpenter is designed to take full advantage of Amazon Elastic Compute Cloud (Amazon EC2). Although serving the same purpose, cluster autoscaler and karpenter take a very different approach to autoscaling. In this post, we won’t focus on the differences of the two solutions, but instead we’ll analyze how those can be used to fulfil a specific requirement — scaling an Amazon EKS cluster to zero nodes. Scaling an Amazon EKS cluster to zero nodes can be useful for a variety of reasons. For example, you might want to scale your cluster down to zero nodes when there is no traffic, or you might want to scale your cluster down to zero nodes when you are performing maintenance. This not only reduces costs, but increases the sustainability of resource utilization.
Solution overview
Cost considerations of scaling down clusters
The cost optimization pillar of the AWS Well-Architected Framework includes a specific section that focuses on the financial advantages of implementing a just-in-time supply strategy. Autoscaling is often the preferred approach for matching supply with demand.

Figure 1: Adjusting capacity as needed.
Autoscaling in Amazon EKS
When it comes to Amazon EKS, we need to think of control plane autoscaling and data plane autoscaling as two separate concerns.
When Amazon EKS launched in 2018, the goal was to reduce users’ operational overhead by providing a managed control plane for kubernetes. Initially, this included automated upgrades, patches, and backups, but with fixed capacity. Today, the control plane is scaled automatically when certain metrics are exceeded.
The data plane, on the other hand, is not fully managed by AWS (with the exception of AWS Fargate). Managed node groups do reduce the operational burden by automating the provisioning and lifecycle management of nodes. However, upgrades, patches, backups, and autoscaling are the responsibility of the user.
In this post, we’ll cover data plane autoscaling, and more specifically, since there are different ways to run Amazon EKS nodes — using Amazon EC2 instances, AWS Fargate, or AWS Outposts — we’ll focus on Amazon EKS nodes running on Amazon EC2.
Before we go any further, let’s take a closer look at how kubernetes traditionally handles autoscaling for pods and nodes.
Autoscaling pods
In kubernetes, pods autoscaling is tackled via the Horizontal Pod Autoscaler (HPA), which automatically updates a workload resource (such as a Deployment or StatefulSet), with the aim of automatically scaling the workload to match demand.
Horizontal scaling means that the response to increased load is to deploy more pods. This is different from vertical scaling, which for kubernetes, means assigning more resources (e.g., memory or central process units [CPUs]) to the pods that are already running for the workload.
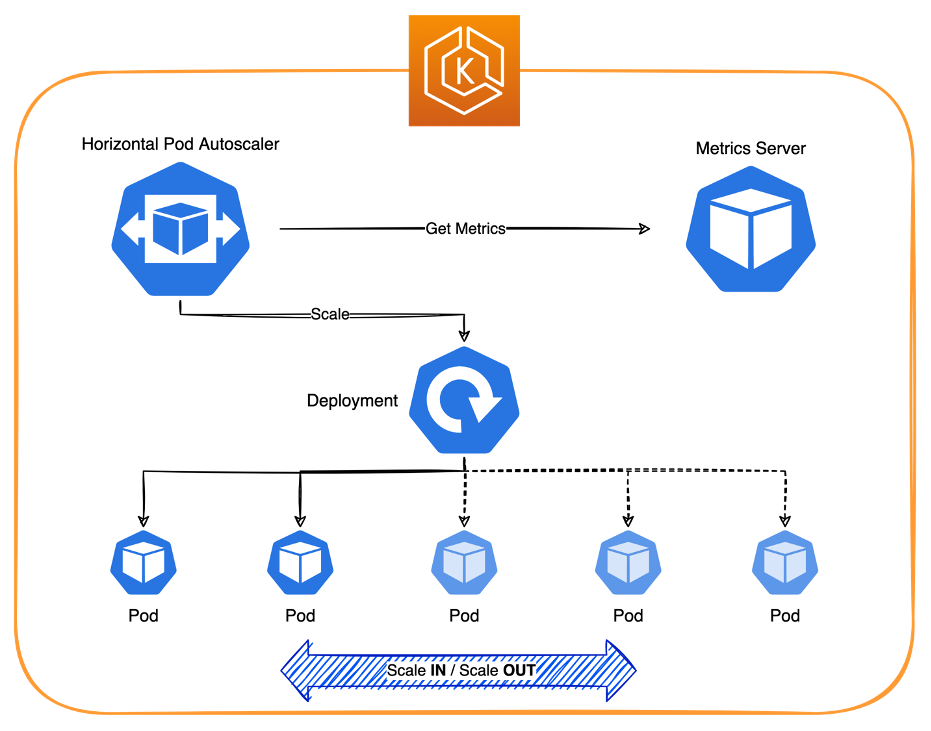
Figure 2: Autoscaling pods with the Horizontal Pod Autoscaler.
When the load decreases and the number of pods is above the configured minimum, the Horizontal Pod Autoscaler instructs the workload resource (i.e., the deployment, StatefulSet, or other similar resource) to scale back in.
However, Horizontal Pod Autoscaler does not natively support scaling down to 0.
There are a few operators that allow you to overcome this limitation by intercepting the requests coming to your pods, or by checking some specific metrics, such as Knative or Keda. However, these are sophisticated mechanisms for achieving serverless behaviour and are beyond the scope of this post on schedule-based scaling to 0.
Autoscaling nodes
In kubernetes, nodes autoscaling can be addressed using the cluster autoscaler, which is a tool that automatically adjusts the size of the kubernetes cluster when one of the following conditions is true:
- there are pods that failed to run in the cluster due to insufficient resources.
- there are nodes in the cluster that have been underutilized for an extended period of time and their pods can be placed on other existing nodes.

Figure 3: Autoscaling nodes with the Cluster Autoscaler.
Cluster autoscaler decreases the size of the cluster when some nodes are consistently unneeded for a set amount of time. A node is unnecessary when it has low utilization and all of its important pods can be moved elsewhere.
When it comes to Amazon EC2-based nodegroups (assuming their minimum size is set to 0) the cluster autoscaler scales the nodegroup to 0 if there are no pods preventing the scale in operation.
Pricing model and cost considerations
For each Amazon EKS cluster, you pay a basic hourly rate to cover for the managed control plane as well as the cost of running the Amazon EC2-backed data plane and any associated volumes. Hourly Amazon EC2 costs vary depending on the size of the data plane and the underlying instance types.
While we would continue to pay the hourly rate for the control plane for the non-production clusters that are used for testing or quality assurance purposes, we may not need the data plane to be available 24 hours a day including weekends. By establishing a schedule-based approach to scale the nodegroups to 0 when unneeded, we can significantly optimize the overall Amazon EC2 compute costs.
Cost savings can go beyond bare Amazon EC2 costs. For example, if you use Amazon CloudWatch container insights for monitoring, then you would not be charged when nodes are down given that the costs associated with metrics ingestion are prorated by the hour.
In this post, we’ll show you how you can achieve schedule-based scale to 0 for your data plane with Horizontal Pod Autoscaler (HPA) and cluster autoscaler as well as with karpenter.
Current mechanisms to scale to zero using HPA and cluster autoscaler
We have seen how kubernetes traditionally handles autoscaling for both pods and nodes. We’ve also seen how the current implementations of Horizontal Pod Autoscaler can’t handle schedule-based scale to 0 scenarios. However, the native capabilities can be supplemented with dedicated Kubernetes CronJobs or community-driven open source solutions like cron-hpa or kube downscaler, which can scale pods to 0 on specific schedules.
Additionally, we need to make sure that not only we can scale in to 0 but that we can also scale out from 0. Since kubernetes version 1.24, a new feature has been integrated in cluster autoscaler, which makes this easier.
Quoting the official announcement:
For Kubernetes 1.24, we have contributed a feature to the upstream Cluster Autoscaler project that simplifies scaling the Amazon EKS managed node group (MNG) to and from zero nodes. Before, you had to tag the underlying EC2 Autoscaling Group (ASG) for the Cluster Autoscaler to recognize the resources, labels, and taints of an MNG that was scaled to zero nodes.
Starting with kubernetes version 1.24, when there are no running nodes in the MNG and the cluster autoscaler calls the Amazon EKS DescribeNodegroup API to get the information it needs about MNG resources, labels, and taints. When the value of a cluster autoscaler tag on the ASG powering an Amazon EKS MNG conflicts with the value of the MNG itself, the cluster autoscaler prefers the ASG tag so that customers can override values as necessary.
Thanks to this new feature, the cluster autoscaler determines which nodegroup needs to be scaled out from 0 based on the definition of the unschedulable pods, but in order for it to be able to do so, it must be up and running. In other words: we cannot scale all of our nodegroups to 0 as we do need to guarantee a minimal stack of core components to be constantly up and running. Such a stack would include, at the very least: the cluster autoscaler, the Core DNS, and the open-source tool of our choice to cover schedule-based scaling of pods. Ideally, we might also need to accommodate Cluster Proportional Autoscaler (CPA) to address Core DNS scalability.
To be cost efficient, we might decide to create a dedicated nodegroup for the core components, which would be backed by cheap instance types, and separate nodegroups for applicative workloads.
Putting it all together:
- Kube downscaler or cron-hpa apply a schedule-based scaling to or from 0 for applicative workloads.
- Cluster autoscaler notices if nodes can be scaled in (including to 0) as underutilized or that some pods cannot be scheduled due to insufficient resources and nodes need to scale out (including from 0).
- Cluster autoscaler interacts with the AWS ASG API (Application Programming Interface) to terminate or provision new nodes.
- The nodegroup is scaled to or from 0 as expected.

Figure 4: Schedule-based scale to 0 using an EC2 backed technical nodegroup for core components.
Eventually, this pattern can be further optimized by moving the minimal stack of core components to AWS Fargate. This means that not a single Amazon EC2 instance is running when the data plane is unneeded.
The cost implications of hosting the core components in AWS Fargate must be carefully assessed. Keeping the lower-cost Amazon EC2 instance types may result in a less elegant but more cost-effective solution.

Figure 5: Schedule-based scale to 0 using a Fargate profile for core components.
How it is done with karpenter
With karpenter, we have the concept of provisioner. Provisioners set constraints on the nodes that can be created by parpenter and the pods that can run on those nodes. With the current version of karpenter (0.28.x), there are three ways to scale down the number of nodes to zero using provisioners:
- Delete all provisioners. Deleting provisioners causes all nodes to be deleted. This option is the simplest to implement, but it may not be feasible in all situations. For example, if you have multiple tenants sharing the same cluster, you may not want to delete all provisioners, as this would prevent any tenants from running workloads.
- Scale all workloads to zero. Karpenter then deletes the unused nodes. This option is more flexible than deleting all provisioners, but it may not be ideal if your workloads are managed by different team and might be difficoult to implement in a GitOps setup.
- Add a zero CPU limit to provisioners and then delete all nodes. This option is the most flexible, as it allows you to keep your workloads running while still scaling down the number of nodes to zero. To do this, you need to update the spec.limits.cpu field of your provisioners.
The first two options previously described may be difficult to implement in multi-tenant configurations or using GitOps frameworks. Therefore, this post focuses on the third option.
Walkthrough
Technical considerations
Programmatically scaling provisioner limits to zero can be done in a number of ways. One common pattern is to use kubernetes CronJobs. For example, the following Cronjob scales the provisioner limits to zero every work day at 10.30 PM:
This job runs every night at 10.30 PM and scales the provisioner’s limits to zero, which effectively disables the creation of new nodes until it is manually scaled back up.
CronJobs can be used with AWS Lambda to terminate running nodes, or to implement more complex logic such as scaling other infrastructure components, handling errors and notifications, or any event-driven pattern that can be connected to an application or workload.
AWS Step Functions can add an additional layer of orchestration to this, allowing you to interact with your cluster using the kubernetes API and run jobs as part of your application’s workflow. More information on how to use the kubernetes API integrations with AWS Step Functions can be found here.
This is a simplified example of an AWS Lambda function that can be used to terminate the remaining karpenter nodes:
Note: these steps can be difficult to orchestrate in a GitOps setup. The general advise is to create specific conditions for provisioner limits. This is (purely) as example, how this can be done with ArgoCD:
How to move core components to AWS Fargate for further optimization
Karpenter and cluster autoscaler run a controller inside a pod running on the cluster. This controller needs to be up and running to orchestrate scale operations up or down. This means that at least one node should be running on the cluster to host those controllers. However, if you are interested in scale-to-zero scenarios, there is an option that should be taken into consideration: AWS Fargate.
AWS Fargate is a serverless compute engine that allows you to run containers without having to manage any underlying infrastructure. This means that you can scale your application up and down as needed, without having to worry about running out of resources.
AWS Fargate profiles that run karpenter can be configured via AWS Command Line Interface (AWS CLI), AWS Management Console, CDK (Cloud Development Kit), Terraform, AWS CloudFormation, and eksctl. The following example shows how to configure those profiles with ekstcl:
Note: By default, CoreDNS is configured to run on Amazon EC2 infrastructure on Amazon EKS clusters. If you want to only run your pods on AWS Fargate in your cluster, then refer to the Getting started with AWS Fargate using Amazon EKS guide.
Conclusions
In this post, we showed you how to scale your Amazon EKS clusters to save money and reduce your environmental impact. By using cluster autoscaler and karpenter, you can easily and effectively scale your clusters up and down, as needed. These tools can help you to scale your Amazon EKS clusters to zero nodes and save on your resource utilization and carbon footprint.
If you want to get started with karpenter, then you can find the official documentation here. The documentation includes instructions on Kubernetes installation and the configuration of NodePools and all the other components required to orchestrate autoscaling. This guide focuses on Amazon EKS, but the same concepts can apply on self-hosted kubernetes solutions.