Amazon Web Services ブログ
Amazon Athena、AWS Glue、Amazon QuickSight を使って Amazon Connect のレコードを分析する
昨年、当社はあらゆるビジネスがより低コストでより良い顧客サービスを提供できるようにするためのクラウドベースのコンタクトセンターサービス Amazon Connect をリリースしました。このサービスは、Amazon のカスタマーサービスアソシエイトに与えるのと同じ技術に基づいて構築されています。このシステムを使用して、従業員は発送や注文情報を問い合わせる顧客と、何百万件の会話を行います。これは AWS のサービスとして利用できますので、コンタクトセンターのエージェントがわずか数分で電話をかけたり受けたりできるようになります。一切のハードウェアのプロビジョニングが不要です。
ドキュメントに記載されているように、AWS クラウドにコンタクトセンターを構築することにはいくつかの利点があります。さらに、顧客は幅広い AWS のサービスを利用して、Amazon Connect の機能を拡張することもできます。このブログ記事では、Amazon Connect が公開した豊富なデータセットから分析する方法を中心に説明します。Amazon Connect データストリームを利用して、エンドツーエンドのワークフローを作成し、必要に応じてカスタマイズ可能な分析ソリューションを提供します。
ソリューションの概要
次の図は、このソリューションを示しています。
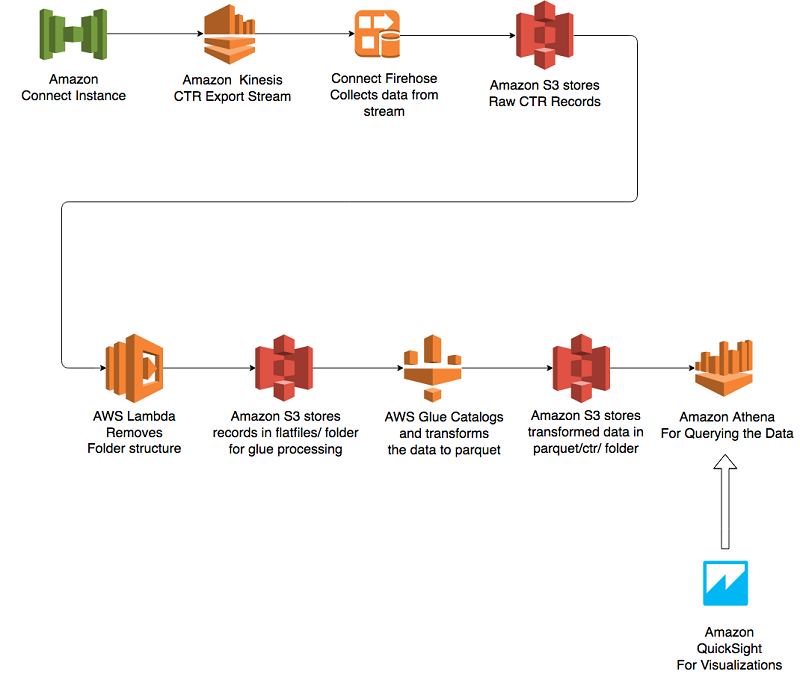
このソリューションでは、Amazon Connect は Amazon Kinesis を使用してコンタクトトレースレコード (CTR) をエクスポートします。CTR は JSON 形式のデータストリームで、それぞれに個々の連絡先に関する情報があります。例えば、この情報には、通話の開始時刻と終了時刻、通話を処理したエージェント、ユーザーが選択したキュー、キュー待機時間、保留数などが含まれます。この機能を有効にするには、ドキュメントを確認してください。
このアーキテクチャでは、Kinesis Firehose を使用して Amazon S3 バケットで Amazon Connect CTR を raw データとして取得します。Apache Parquet 形式として S3 にデータを保存するために、Kinesis Firehose で最近追加された機能は使用しません。AWS Glue 機能を使用して、Amazon Connect データストリームからスキーマをオンザフライで自動的に検出します。
このアプローチの主な理由は、属性を使用して Amazon Connect 管理者が必要に応じて動的にフィールドを追加できるようにすることです。また、データを (数時間ごとに) 一括で Parquet に変換することで、圧縮率を高めることができます。 しかし、Parquet 形式でデータをリアルタイムで取り込む必要がある場合には、最近追加された Kinesis Firehose の機能を使用することをお勧めします。詳細はこのブログ記事をお読みください。
デフォルトでは、Firehose はこれらのレコードを時系列形式で保存します。AWS Glue クローラーが新しいレコードから情報を簡単に取得できるようにするため、AWS Lambda を使用して、すべての新しいレコードを flatfiles と呼ばれる単一の S3 プレフィックスに移動します。当社の Lambda 関数は、S3 イベント通知を使用して設定されます。AWS Glue と Athena のベストプラクティスに準拠するため、Lambda 関数はすべての列名も小文字に変換します。最後に、Lambda 関数を使用して、AWS Glue クローラーも起動します。AWS Glue クローラーはデータスキーマを識別し、ワークフローの後半で AWS Glue の抽出、変換、ロード (ETL) ジョブによって使用される AWS Glue データカタログを更新します。
次の Lambda コードで、当社の手法を紹介します。
イベントに基づいて、AWS Glue クローラーをトリガーします。このアプローチによって、本質的に動的に新しいデータフレームを取得することができるようになります。CTR 属性は、特定のコールフローに基づいて複数のカスタムオプションを提供するように設計されています。属性は本質的にネストされた JSON 形式のキーと値のペアです。イベントベースの AWS Glue クローラーを使用して、より新しい属性を自動的に識別することができます。
24 時間のみレコードを保管する flatfiles フォルダに S3 ライフサイクルポリシーを設定することをお勧めします。これにより、AWS Glue ETL ジョブが最適化され、レコード全体ではなくファイルのサブセットが処理されます。
flatfiles フォルダにデータを保存後、AWS Glue を使用してデータをカタログ化し、parquet/ctr/ というフォルダ内で Parquet 形式に変換します。AWS Glue ジョブは、データを JSON から Parquet 形式に変換する ETL を実行します。AWS Glue クローラーを使用して、本質的に動的にしたい JSON コード内の新しいデータフレームを取得します。つまり、Amazon Connect インスタンスに新しい属性を追加すると、ソリューションは自動的にその属性を認識し、結果のスキーマに組み込みます。
AWS Glue が結果を Parquet 形式で保存後、Amazon Redshift Spectrum、Amazon Athena、またはサードパーティー製のデータウェアハウスプラットフォームを使用して分析を実行できます。このソリューションを簡単にするために、分析には Amazon Athena を使用しました。 Amazon Athena では、サーバーやデータウェアハウスプラットフォームを設定したり管理したりすることなく、データを照会することができます。さらに、実行されるクエリに対してのみ支払いをします。
試してください!
私たちが用意したサンプル AWS CloudFormation テンプレートを使って始めることができます。このテンプレートは Kinesis ストリームから始まるコンポーネントを作成し、S3 バケット、AWS Glue ジョブ、クローラーで完成します。テンプレートをデプロイするには、次の [link] をクリックして、AWS マネジメントコンソールを開きます。
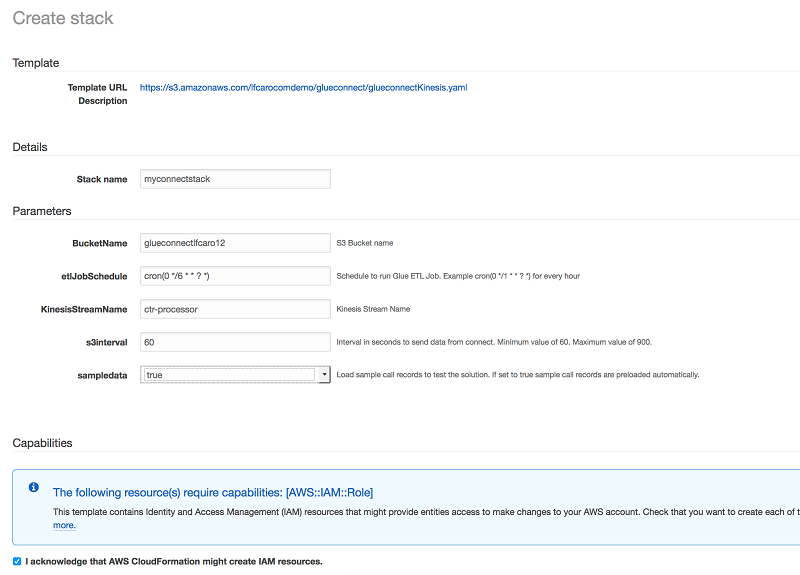
コンソールで、次のパラメータを指定します。
- BucketName: すべてのソリューションファイルを保存するバケットの名前。この名前は一意である必要があります。それ以外は、テンプレートの作成に失敗します。
- etlJobSchedule: AWS Glue ジョブの実行頻度を示す cron 形式のスケジュール。デフォルト値は 1 時間です。
- KinesisStreamName: Amazon Connect からデータを受け取る Kinesis ストリームの名前。この名前は、AWS アカウントで作成された他の Kinesis ストリームとは異なる名前でなければなりません。
- s3interval: S3 の flatfiles フォルダに Kinesis Firehose がデータを保存する間隔 (秒)。値は 60 ~ 900 秒の間でなければなりません。
- sampledata: このパラメータを true に設定すると、サンプル CTR レコードが使用されます。これにより、Amazon Connect インスタンスを設定せずにこのソリューションを試すことができます。このチュートリアルのすべての例で、このサンプルデータを使用します。
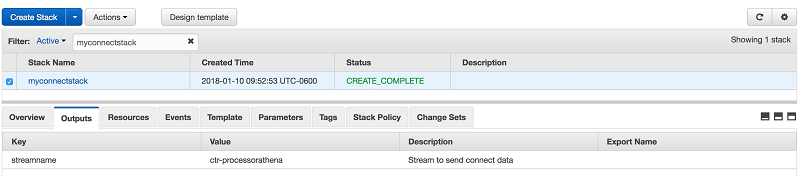
[I acknowledge that AWS CloudFormation might create IAM resources.] チェックボックスを選択し、[Create] を選択します。テンプレートがリソースの作成を完了したら、スタック [ Outputs] タブにストリーム名が表示されます。
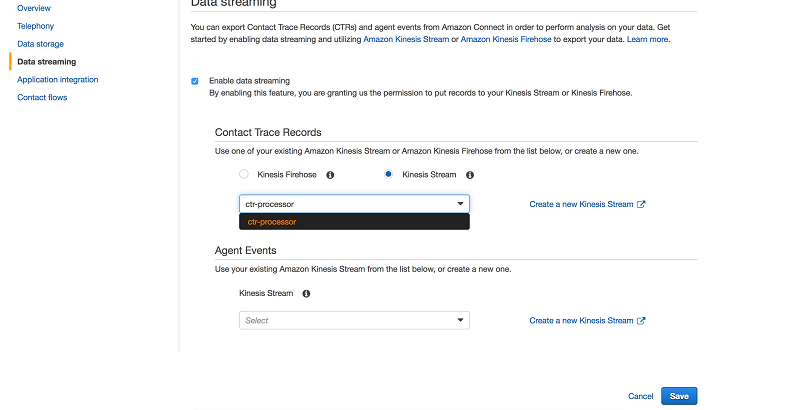
まだ Amazon Connect インスタンスを作成していない場合には、入門ガイドに従って、これを行ってください。作成が完了したら、コンソールで Amazon Connect インスタンスを選択し、インスタンス設定に移動します。CTR レコードのデータストリーミングを有効にするには、[Data streaming] を選択します。ここでは、CloudFormation テンプレートで作成された Kinesis ストリーム (KinesisStreamName パラメータで定義) を選択できます。
これで、Amazon Connect を使用して通話を発信または受信してデータを生成する準備ができました。Amazon Connect クラウドコントロールパネル (CCP) にアクセスして、ソフトウェア電話またはデスクトップ電話を使用して、電話を発信または受信できます。数分後、flatfiles フォルダ内のデータが表示されます。 このソリューションを簡単に試すために、CloudFormation テンプレートの sampledata パラメータを true に設定することで有効にできるサンプルデータを提供しています。
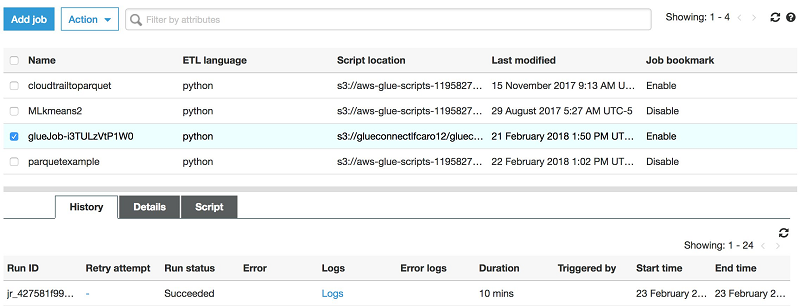
コンソールの左側ナビゲーションペインで [Jobs] を選択して、AWS Glue コンソールに移動します。ここでジョブを選択できます。私の場合には、CloudFormation が作成したジョブの名前は glueJob-i3TULzVtP1W0 ですが、あなたのものも似たようなものになっているはずです。[Run job] の [Action] を選択してジョブを実行します。
その後、AWS Glue ジョブが実行されて正常に終了するまで待ちます。[History] タブをチェックして、ジョブのステータスを追跡できます。
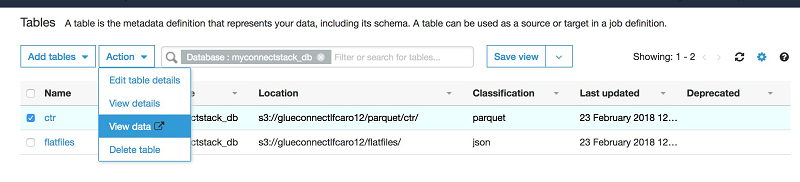
ジョブが実行を終了すると、[Database] セクションを確認できます。Parquet 形式で ctr という名前の新規テーブルを作成してください。
Athena でデータをクエリするには、ctr テーブルを選択し、[Action] で [View data] を選択します。
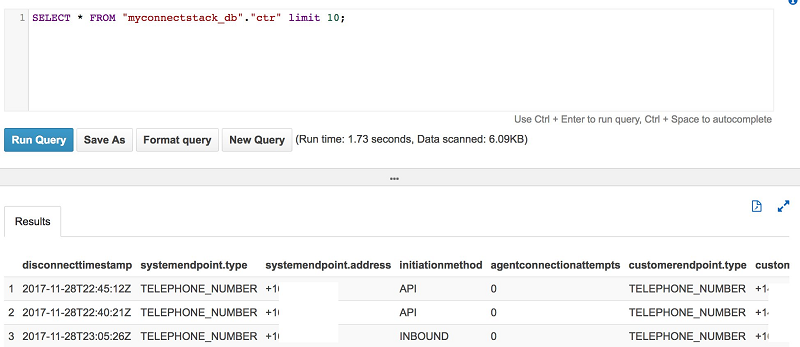
これを実行すると、Athena コンソールに進みます。クエリを実行すると、Athena はデータのプレビューを表示します。
Athena を使用してデータをクエリできるときは、Amazon QuickSight を使用してこれを視覚化できます。Amazon QuickSight を Athena に接続する前に、Amazon QuickSight に Athena と関連する S3 バケットへのアクセスを許可する必要があります。この実行についての詳細情報は、Amazon QuickSight ユーザーガイドの AWS リソースへの Amazon QuickSight アクセス許可の管理を参照してください。 作成した Athena テーブルに基づいて、Amazon QuickSight に新しいデータセットを作成することができます。
アクセス許可を設定後、[New analysis] を選択して、Amazon QuickSight で新しい分析を作成することができます。

次に、新しいデータセットを追加します。
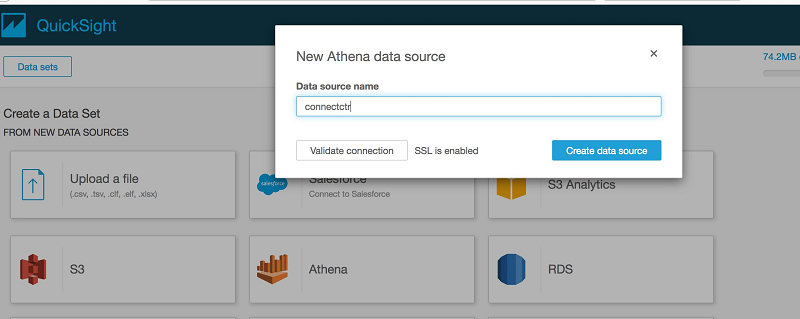
ソースとして Athena を選択し、データソースに名前を付けます (この例では connectctr)。
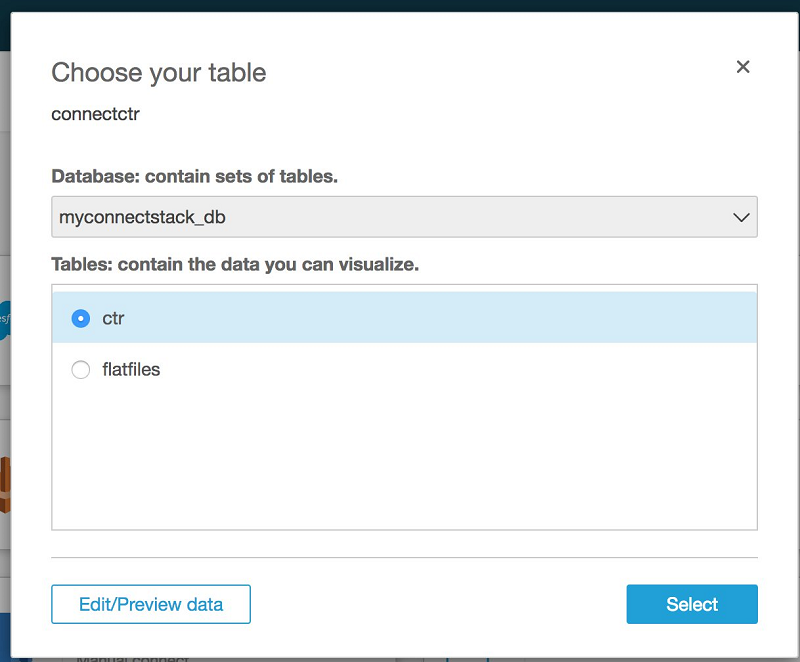
データベースの名前と Parquet の結果を参照するテーブルを選択します。
次に、[Visualize] を選択します。
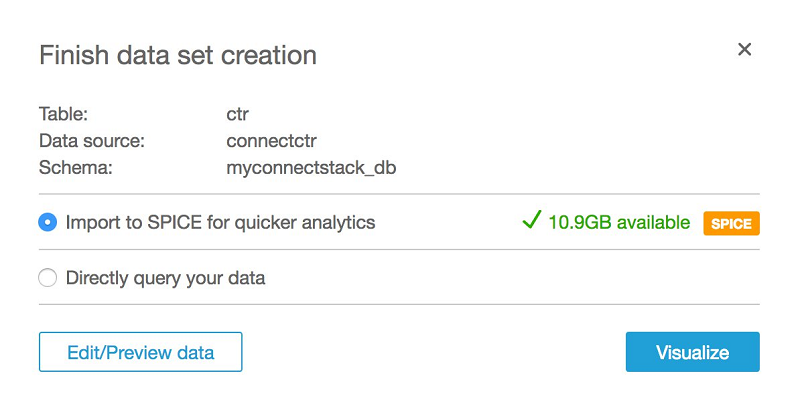
その後、次の画面が表示されます。
これで、いくつかの可視化が作成できます。まず、agent.username 列を探し、これを AutoGraph セクションにドラッグします。
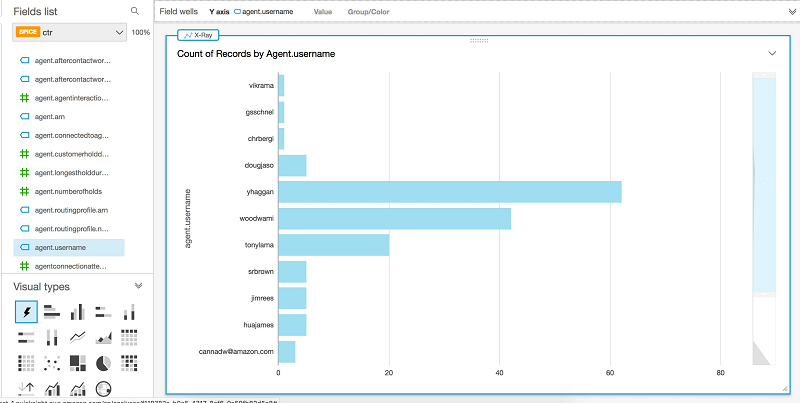
エージェントと、それぞれの通話数を見ることができるので、どのエージェントが最も多くの通話を受けたかを簡単に確認できます。各エージェントの通話がどのキューから来たのかを確認したい場合には、queue.arn 列を可視化に追加できます。
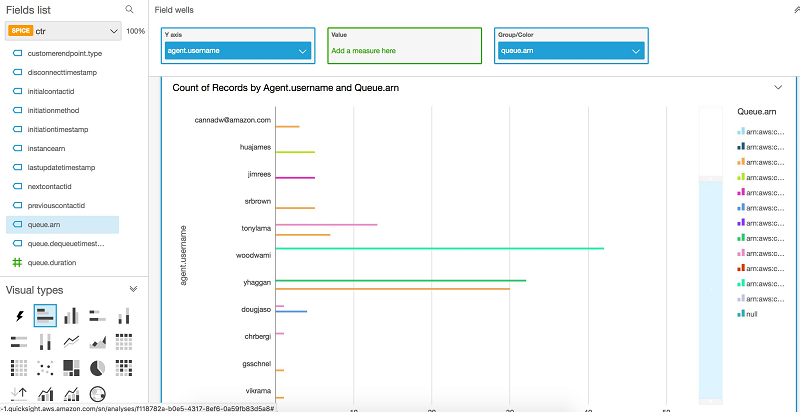
これらすべてのステップの後で、Amazon QuickSight を使用して、通話記録からさまざまな列を追加し、さまざまな種類の視覚化を実行できます。接続インスタンスを継続的に監視するダッシュボードを構築できます。これらのダッシュボードは、このデータを参照する必要のある組織内の他のユーザーと共有できます。
結論
この記事では、AWS Lambda、AWS Glue、Amazon Athena のようなサービスを使用して、Amazon Connect の通話記録を処理する方法について説明します。この記事では、AWS Lambda を使用して Amazon S3 でファイルを事前処理し、AWS Glue クローラーによって認識される形式に変換する方法も示しています。最後に、記事では Amazon QuickSight を使用して可視化を行う方法を示しています。
提供されたテンプレートを使用して、独自のコンタクトセンターインスタンスを分析できます。また、CloudFormation テンプレートを使用して、Amazon Kinesis を使用して取り込むか、Amazon S3 に保存できる他のデータストリームを処理することができます。
その他の参考資料
この記事が役立つと思いましたら、Amazon Kinesis Data Firehose、Amazon Athena、Amazon Redshift を使用して Apache Parquet 最適化データを分析するや AWS Glue と Amazon QuickSight を使用した AWS Cloudtrail ログの可視化の記事も参照ください。
著者について
 Luis Caro は AWS Professional Services のビッグデータコンサルタントです。 彼は、AWS を使用しているソリューションの価値を向上させる支援をするために、AWS の顧客と協力してビッグデータプロジェクトの指導や技術支援を行っています。
Luis Caro は AWS Professional Services のビッグデータコンサルタントです。 彼は、AWS を使用しているソリューションの価値を向上させる支援をするために、AWS の顧客と協力してビッグデータプロジェクトの指導や技術支援を行っています。
 Peter Dalbhanjan は、バージニア州ハーンドンに拠点を置く AWS のソリューションアーキテクトです。Peter は AWS ソリューションの宣伝に興味を持ち、複雑なユースケースの簡素化について複数のブログ記事を書いています。Peter は AWS で、さまざまな顧客ワークロードの設計およびアーキテクチャの設計を支援しています。
Peter Dalbhanjan は、バージニア州ハーンドンに拠点を置く AWS のソリューションアーキテクトです。Peter は AWS ソリューションの宣伝に興味を持ち、複雑なユースケースの簡素化について複数のブログ記事を書いています。Peter は AWS で、さまざまな顧客ワークロードの設計およびアーキテクチャの設計を支援しています。