Amazon Web Services ブログ
Category: Analytics

AWS AI League: 新しい究極の AI 対決で学習し、イノベーションを起こし、競い合う
2018 年以来、AWS DeepRacer は世界中で 560,000 人超のビルダーを魅了し、デベロッパー […]

新しい Amazon EventBridge のログ記録を使用して、イベントドリブンのアプリケーションをモニタリングおよびデバッグする
7 月 15 日より、Amazon EventBridge の拡張ログ記録機能を使用して、包括的なログでイベン […]

Amazon SageMaker Catalog の新機能を使用して、データからインサイトを得るプロセスを効率化
現代の組織は、構造化データベース、非構造化ファイル、個別のビジュアライゼーションツールなど、複数の分断されたシ […]

OpenSearch ベースのマルチテナント集中ログプラットフォームにおけるワークロード管理
この記事では、OpenSearch ベースのマルチテナント集中ログプラットフォームにおけるワークロード管理について説明します。ルールベースのプロキシと OpenSearch ワークロード管理を使用した多層フレームワークにより、多様なテナントワークロードに対する効率的なリソース割り当てとパフォーマンス分離を実現する方法を紹介します。
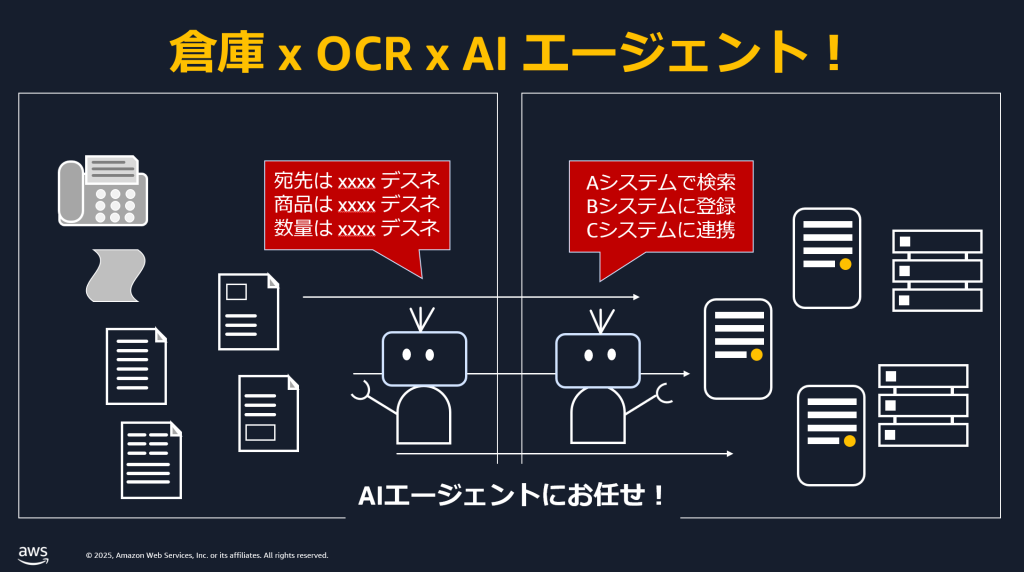
【開催報告】AWS Summit Japan 2025 物流業界向けブース展示 「倉庫 x OCR x 生成 AI エージェント」
6月 24 日と 25 日の 2 日間にわたり、幕張メッセにおいて 14 回目となる AWS Summit J […]

通信事業者が提供するSmart-Xのための協調AIエージェントによる分散推論
本稿は、2025年3月20日に AWS for industriesで公開された “Distributed i […]

寄稿:レンゴーが実践するDX人材育成 – Amazon 流の考え方とパートナー活用 –
レンゴー株式会社について レンゴーは、たゆまぬ意識改革とイノベーションを通じて、あらゆる産業のすべての包装ニー […]

【開催報告 & 資料公開】Apache Iceberg on AWS ミートアップ開催報告
2025 年 5 月 14 日に「Apache Iceberg on AWS ミートアップ ~話題のIcebergをAWSで徹底活用~」と題したイベントを開催しました。ご参加いただきました皆様には、改めて御礼申し上げます。
本セミナーでは、AWS における Iceberg の活用についてさまざまな角度からご紹介しました。Iceberg 活用の全体像に加えて、マネージドな Iceberg のストレージである Amazon S3 Tables Bucket、既存データレイクからの移行における考え方、リアルタイムデータ処理を実現するストリーミングワークロードの実装方法、更には機械学習における活用まで、幅広いトピックをご紹介しました。本ブログでは、その内容を簡単にご紹介しつつ、発表資料を公開致します。
すでに Iceberg を活用されている方も、これからはじめる方も是非ご確認下さい!

[教育業界向け] 手を動かしながら学ぶデータ分析ワークショップ [開催報告]
アマゾン ウェブ サービス ジャパン(以下、AWS)は 2025 年 5 月 30 日に、「 [教育業界向け] 手を動かしながら学ぶデータ分析ワークショップ」を AWS Startup Loft Tokyo にて開催しました。 近年、個別最適な学びと協働的な学びの実現に向けて教育業界におけるデータ分析の重要性が増しています。 本イベントでは、初等中等教育、EdTech のシステム構築に関わるベンダー、パートナー企業の方々をお招きし、教育業界におけるデータ利活用や AWS における実現方法に関して振り返りつつ、Amazon QuickSight を活用した教育データ分析ダッシュボードの構築を中心にハンズオンを体験していただきました。当日お集まりいただいた総勢 40 名以上の皆様には、改めて御礼申し上げます。本ブログではその開催報告をお届けします。

新機能: sort コンパクションと z-order コンパクションで Amazon S3 内での Apache Iceberg クエリパフォーマンスを向上
sort コンパクションと z-order コンパクションを使用して、Amazon S3 Tables と 汎 […]