Amazon Web Services ブログ
Category: Artificial Intelligence
Amazon Q Business と Amazon Bedrock によるSAP データ価値の最大化 – パート 2
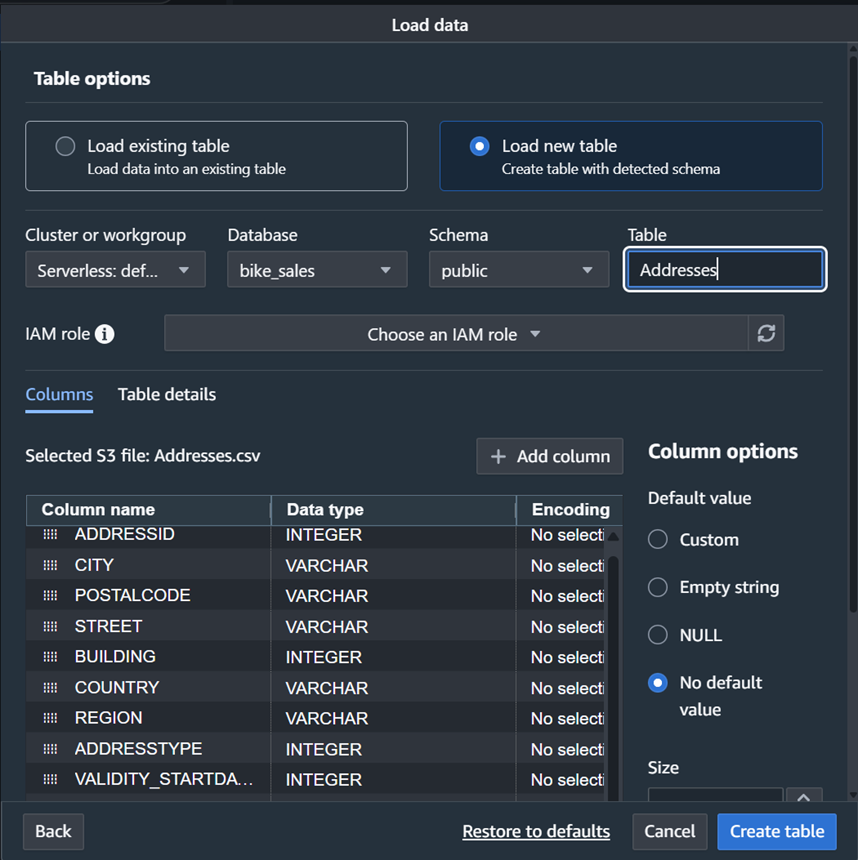
このシリーズのパート1では、Amazon Q BusinessとAmazon Bedrockの力を組み合わせて、SAP Early Watch Reportsから実用的なインサイトを得る方法、およびBusiness Data Automationを使用したIntelligent Document ProcessingをSAPシステムの請求書データ処理に使用する方法を検討しました。この投稿では、Amazon Bedrock Knowledge Bases for Structured Dataを使用して、SAPデータに関する質問に自然言語形式で回答する方法を実演します。

プロパティベーステストが見つけた、私が決して発見できなかったセキュリティバグ
本記事では、Kiro の仕様駆動開発ワークフローを使用したチャットアプリケーション開発において、プロパティベーステスト(PBT)が従来のテスト手法では発見困難なセキュリティバグをどのように発見したかをお伝えします。75 回目のテスト反復で __proto__ というプロバイダー名が JavaScript プロトタイプの誤った処理を露呈し、ランダム生成による体系的な入力空間の探索が、手動コードレビューや単体テストでは見逃されるエッジケースを効果的に発見できることを実例とともに紹介します。

Kiro のマルチルートワークスペース:1 つのプロジェクト内だけでなく、複数のプロジェクトにまたがって作業する
本記事では、Kiro の新しいマルチルートワークスペース機能により、複数のプロジェクトを単一の IDE ウィンドウで効率的に管理する方法をお伝えします。共有ライブラリとメインアプリケーション、複数のマイクロサービス、モノレポのパッケージなど、関連するプロジェクトを同時に編集する際の課題を解決し、各ルートが独立性を保ちながら統合された開発環境を提供する仕組みと、その設定方法や実際の活用例を詳しく説明します。
Amazon Bedrock は ISMAP の言明対象であることについての考え方
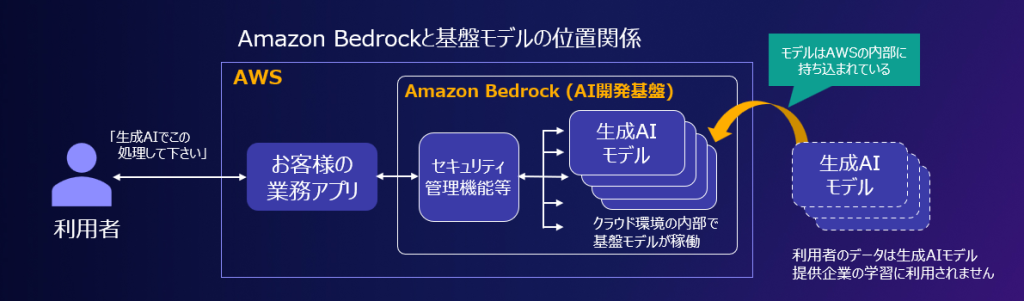
はじめに ISMAP ポータルサイトに、「生成AIサービスに関する留意点について」が追加されていますが、その内 […]

Amazon Connect アップデートまとめ – 2025年11・12月合併号
新年あけましておめでとうございます。Amazon Connect ソリューションアーキテクトの坂田です。 20 […]

明けましておめでとうございます! AWS Weekly Roundup: 10,000 AIdeas Competition、Amazon EC2、Amazon ECS マネージドインスタンスなど (2026 年 1 月 5 日)
明けましておめでとうございます! クリスマスや年末年始を通じて、皆さんが心身ともにリフレッシュし、愛する人と一 […]

AWS IoT Greengrass と Strands Agents を使用した Small Language Model の大規模デプロイ
AWS IoT Greengrass と Strands Agents を活用して、Small Language Models (SLM) をエッジデバイスに大規模デプロイする方法を解説します。製造業における OPC-UA データの処理を例に、クラウド接続なしでもリアルタイムの機器ステータス照会やテレメトリ解釈を可能にするハイブリッド AI ソリューションの実装手順を紹介。エッジでの即時応答とクラウドでの複雑な分析を組み合わせた産業 IoT アーキテクチャを構築できます。

株式会社アド・ダイセンが生成 AI で実現した現場主導の業務効率化:非技術者による生成 AI 活用の実践
本ブログは株式会社アド・ダイセン様とアマゾン ウェブ サービス ジャパン合同会社が共同で執筆いたしました。 み […]

smart EuropeがAmazon Bedrockでカスタマーサポート業務を変革した方法
自動車メーカーにとって、新型車のリリース、無線通信(OTA)によるソフトウェアアップデート、コネクテッドサービスの開始は、新鮮な顧客体験を生み出します。これらのイノベーションは運転体験の向上に役立つ一方で、自動車所有者から車両の機能、充電機能、メンテナンス手順、デジタルサービスに関する多数の問い合わせを生み出します。
AWSはsmart Europeと協力し、smart.AI Case Handlerを開発しました。このツールは、問い合わせに関するインサイトとカスタマイズされた対応を提案することで、サポート担当者の効率を大幅に向上させます。
【開催報告】通信ネットワーク運用向け AI エージェントワークショップ開催しました! ( 2025 年 11 月 27 日 )
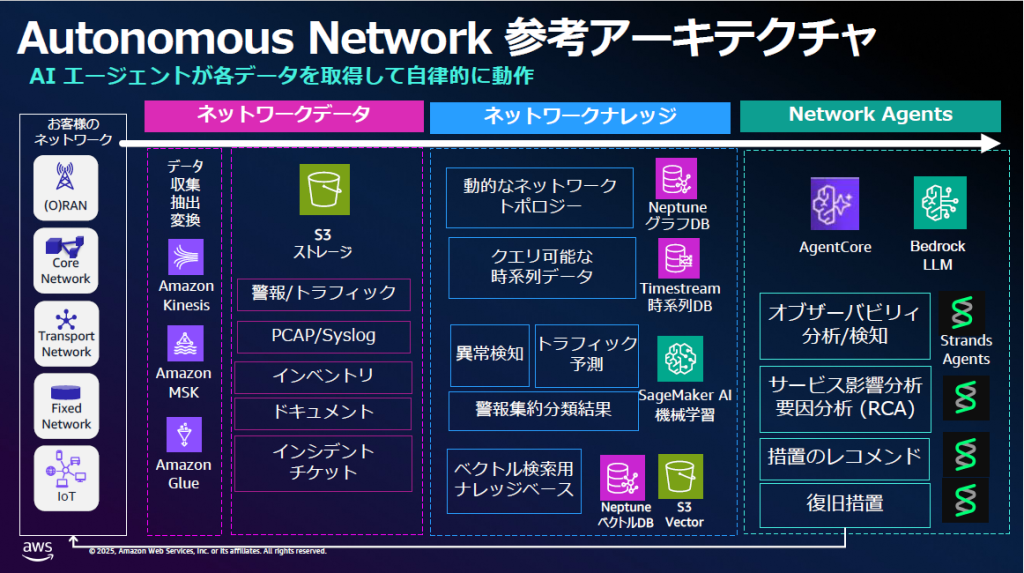
通信業界のネットワーク運用ではより安定した通信ネットワークを提供するために、障害の検知、要因特定、復旧を早期に […]