Amazon Web Services ブログ
Category: Management Tools

AIOpsを強化 – Amazon CloudWatchとApplication Signals MCPサーバーのご紹介
この記事では、Amazon CloudWatch とApplication Signals 用の2つの新しい MCP サーバーと Amazon Q Developer CLI を活用して運用ワークフローを変革する方法をご紹介します。従来の手動作業に代わる直感的な会話形式のやり取りを通じて、パフォーマンスのボトルネックの特定、権限の問題の解決、アラーム設定の最適化、インシデント修復の加速化を行う方法を学びます。
Amazon CloudWatch の強化された自動ダッシュボードでログ使用状況を分析する
Amazon CloudWatch の強化された自動ダッシュボードを活用することで、Amazon CloudWatch Logs の使用パターン、コスト、潜在的な問題をより詳しく把握し、効率的な運用管理を実現できます。この記事では、使用状況を理解することの重要性、ダッシュボードの確認方法、そこから得られる知見について説明します。さらに、CloudWatch の使用状況とコストを把握するための他の便利なツールもご紹介します。
アプリケーション監視における Amazon CloudWatch Application Signals の新しい機能強化
2025年10月7日、大規模分散アプリケーションの監視方法を簡素化する Amazon CloudWatch Application Signals の新しい強化機能を発表できることを嬉しく思います。CloudWatch Application Signals のアプリケーションマップの改善により、サービスの関係性に基づいて自動的に検出し、サービスをグループに整理できるようになり、ビジネスの観点に合わせたカスタムグループ化もサポートされます。サービスの最新のデプロイ時刻を表示し、サービスレベル指標(SLI)違反などの問題に関する自動監査結果を確認できるようになりました。
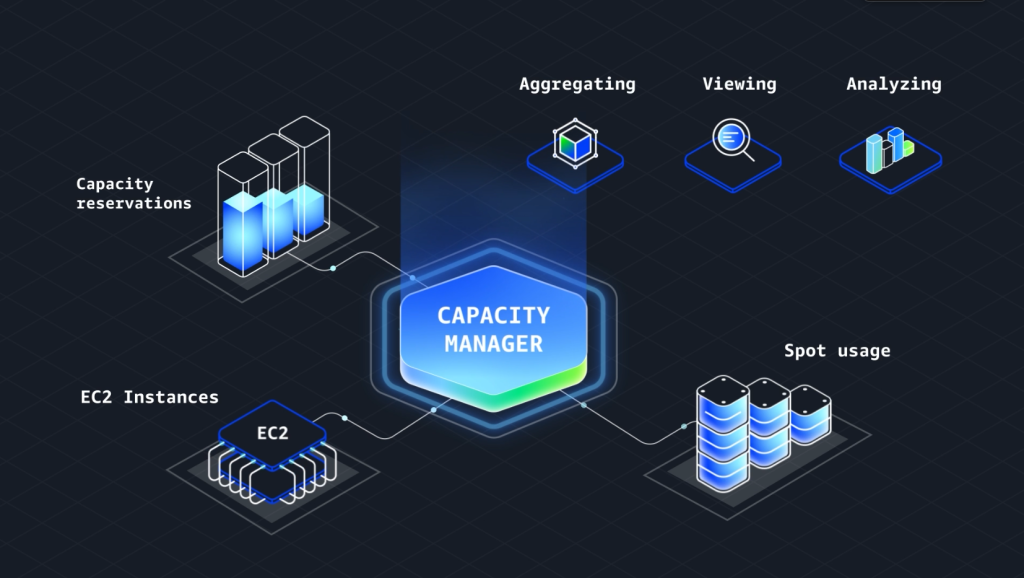
Amazon EC2 Capacity Manager を使用して単一のインターフェイスからキャパシティ使用量を監視、分析、管理
10 月 16 日、Amazon EC2 Capacity Manager を発表いたしました。Amazon […]

Amazon GameLift Servers でローンチを成功させるためのステップ:開発フェーズ
私たちはグローバルなゲームサーバーホスティングのためのフルマネージド型サービスである Amazon GameLift Servers をお勧めしています。このサービスは、オーケストレーション、グローバルなセッション配置、ゲームセッションライフサイクル管理を担うため、マルチプレイヤーゲームのローンチにおける運用作業とストレスを軽減するのに役立ちます。
このブログシリーズでは、ゲームローンチを成功させるための準備の重要な考慮事項について説明します。この最初のブログはプリプロダクションで実行すべきアクションに焦点を当て、第 2 部はプリローンチ準備 ( ローンチの 2〜3 ヶ月前 ) に焦点を当てます。これらの推奨事項は、開発初期のインテグレーションからゲームローンチまで数百のゲームスタジオをサポートした経験に基づいています。

アンマネージド Amazon EC2 ノードへの AWS Systems Manager エージェント自動インストール
AWS Systems Manager は複数の AWS リソースの一元的なマネジメントを可能にする強力なツールです。しかし、Systems Manager を活用するには、EC2 インスタンスに SSM エージェントをインストールし、適切な権限設定を行う必要があります。このブログでは、CloudFormation と SystemsManagerの Automation を用いて、マルチアカウントの EC2 インスタンスに SSM エージェントを自動でインストールする方法が説明されています。

2025 年 9 月の AWS Black Belt オンラインセミナー資料及び動画公開のご案内
2025 年 9 月に公開された AWS Black Belt オンラインセミナーの資料及び動画についてご案内させて頂きます。
動画はオンデマンドでご視聴いただけます。

AWS Weekly Roundup: Amazon Bedrock、AWS Outposts、Amazon ECS マネージドインスタンス、AWS ビルダー ID など (2025 年 10 月 6 日)
9 月 29 日週、SWE-Bench によって世界最高のコーディングモデルと評価されている Anthropi […]

AWS re:Invent 2025 におけるクラウドガバナンスの必須ガイド
組織がガバナンスをコンプライアンスの負荷としてではなく戦略的な実現手段 (enabler) として認識するよう […]
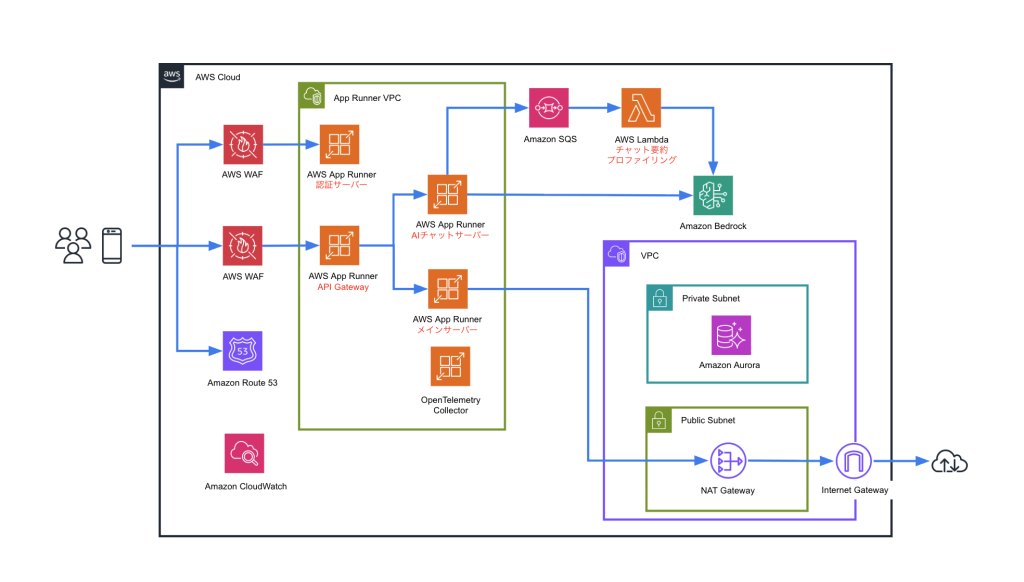
AWS Summit Japan 2025 AI健康アプリ「HugWay」を支えるAWSアーキテクチャ:テオリア・テクノロジーズの認知症プラットフォーム戦略
このブログは、テオリア・テクノロジーズ株式会社と、アマゾン ウェブ サービス ジャパン合同会社 ソリューション […]