Amazon Web Services ブログ
Category: Management Tools
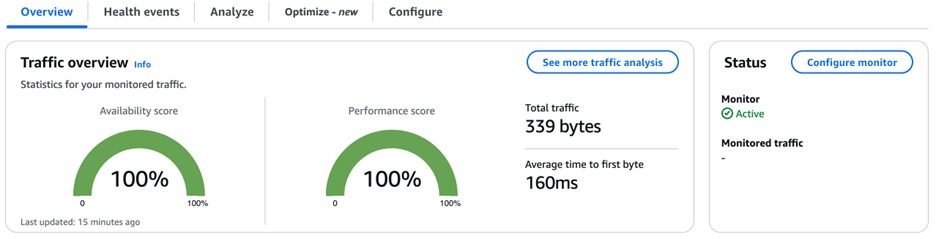
SAP on AWSのエンドツーエンド・オブザーバビリティ: Part-3 Amazon CloudWatch Internet Monitor for SAP
Amazon CloudWatch Internet Monitor for SAP Applications は、インターネット接続に関するリアルタイムのインサイトを提供し、企業が問題をトラブルシューティングし、ネットワークパフォーマンスを最適化するのを支援します。

AWS Compute Optimizer での未使用の NAT ゲートウェイの推奨事項を発表
本日より、AWS Compute Optimizer はアイドル状態のリソース検出機能を NAT ゲートウェイ […]

AWS CloudTrail データイベントの集約とインサイト機能の発表
AWS CloudTrail は、AWS アカウントの API 呼び出しとイベントを記録し、ガバナンス、コンプライアンス、運用上のトラブルシューティングのための監査証跡を提供します。お客様は CloudTrail でデータイベントを有効にすることで、リソースレベルの操作に対するより深い可視性を得ることもできます。本日、データイベントの監視と対応方法を変革する AWS CloudTrail の強力な新機能を 2 つご紹介できることを嬉しく思います:CloudTrail データイベント用のイベント集約と Insights です。

AWS Weekly Roundup: AWS re:Invent 2025 の参加方法、Kiro GA、多くのリリース (2025 年 11 月 24 日)
2025 年 12 月 1 週は、AWS の最新ニュース、専門家によるインサイト、グローバルなクラウドコミュニ […]

AWS Control Tower で Controls Dedicated エクスペリエンスを導入
2025 年 11 月 19 日、AWS Control Tower の Controls Dedicated […]

Container Network Observability を使用して、EKS クラスター全体のネットワークパフォーマンスとトラフィックをモニタリング
組織は、マイクロサービスを導入して段階的に革新し、ビジネス価値をより早く提供することで、Kubernetes […]

re:Invent 2025 クラウド財務管理セッション完全ガイド:参加前に押さえておきたいポイント
本投稿は、2025年 10 月 6 日に公開、11 月 3 日に更新された Your Ultimate Guide to Cloud Financial Management sessions at re:Invent 2025: Know Before You Go を翻訳したものです。
Cloud Financial Management (CFM) の学習とネットワーキングの時間を re:Invent 2025 で最大限に活用する準備はできていますか?例年通り、今年の CFM セッションを最大限に活用し、スケジュールを計画するための包括的なガイドを作成しました。今年のカタログには、ブレイクアウト、チョークトーク、ワークショップ、ビルダーズセッション、コードトークなど、さまざまな形式のコンテンツがエキサイティングに組み合わされています。
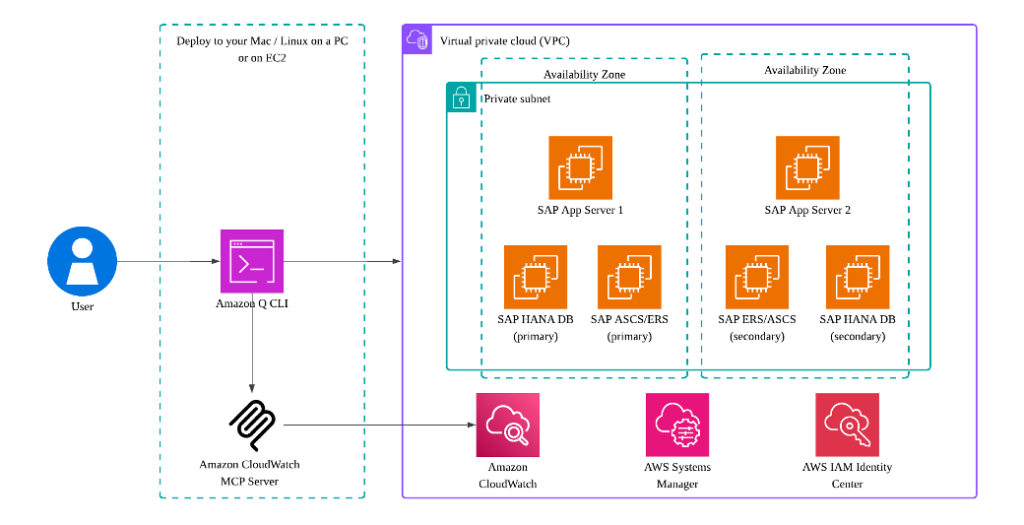
Amazon CloudWatch MCP Server と Amazon Q CLI で SAP 運用を効率化 – Part 4
AWS 上の SAP 運用を最適化するには、効率的な監視、トラブルシューティング、およびメンテナンス機能が必要です。part 1 での Amazon CloudWatch Application Insight に関する以前の議論、part 2 での CloudWatch Application Insight を使用して SAP 高可用性を監視する方法、および part 3 での Amazon CloudWatch Model Context Protocol (MCP) Server と Amazon Q for command line (Q CLI) に基づき、この第4回では、これらのツールの高度な実世界のアプリケーションを実演します。実用的なユースケースを通じて、この統合が SAP メンテナンス計画をどのように効率化し、根本原因分析を加速するかを探ります。
Amazon CloudWatch MCP Server と Amazon Q CLI で SAP 運用を効率化 – Part 3
今日の複雑な SAP 環境において、効率的な運用と迅速なトラブルシューティングは、ビジネス継続性にとって極めて重要です。SAP オブザーバビリティ(part-1 英語)と Amazon CloudWatch Application Insights の機能(part-2 英語)に関する以前の議論に基づき、この第3回では、チームが SAP ランドスケープを管理する方法を革新する強力なツールの組み合わせを紹介します:Amazon CloudWatch Model Context Protocol (MCP) Server と Amazon Q for command line (Q CLI) です。
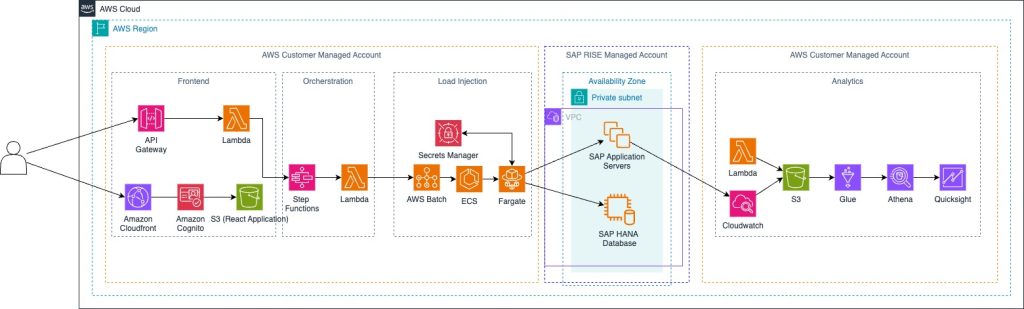
SAPの負荷テスト:AWSによるサーバーレスアプローチ
SAPシステムの適切な負荷テストを実施することは、ピーク使用時にシステムがビジネスのパフォーマンスと信頼性の期待に応えられることを保証する主要な要因です。負荷テストが必要となる典型的なシナリオには、新しい会社/国の展開、ECCからS/4HANAへのソフトウェアリリースアップグレード、アプリケーションパッチ(例:サポートパッケージ)、S/4HANA変革プロジェクト、またはSAP RISEへの移行があります。このような大規模な変更後の安定した運用を確保するため、潜在的なパフォーマンス関連の問題を回避するために、本番カットオーバー前に負荷テストを実行することが推奨されます。このブログでは、オンプレミスまたはRISEにデプロイされたSAP ERPシステムに異なるタイプの負荷を注入するために、AWS上で負荷テストプラットフォームを実装し使用する方法を学びます。