Amazon Web Services ブログ
AWS ライフサイエンスエグゼクティブシンポジウム 2023 のハイライト: データへのアクセスとインサイトの活用
この記事は “Highlights from the AWS Life Sciences Executive Symposium 2023: Unlocking access to and insights from data” を翻訳したものです。
5 月 15 日にボストンで AWS ライフサイエンスエグゼクティブシンポジウムを開催しました。そこで、「データへのアクセスとインサイトの活用」をテーマにしたトラックを私がリードしました。100の組織から集まった300人以上のライフサイエンス担当幹部がこの半日のオンサイトイベントに参加し、クラウド上の強固なデータ基盤と機械学習(ML)を通じたイノベーションを推進する方法を探りました。
いくつかの新しいトレンドの高まりにより、データに焦点を当てたこのトラックは非常にタイムリーなものになりました。第一に、ライフサイエンス企業は、より限られたリソースでより多くの成果をあげなければならないという大きなプレッシャーにさらされています。「インフレ抑制法」、期限切れをむかえる特許、研究開発のスピードアップの必要性などに対応するため、企業はデータをより有効に活用して市場投入までの時間を短縮し、オペレーションの俊敏性を向上させる方法を模索しています。第二に、今日生成される医療データのほぼ 97% は、保存と管理が不十分なため、未使用のままになっています。チームは、最大 80% の時間をデータの検索、購入、クリーニングに費やしており、インサイトやエビデンスの生成、科学的またはビジネス上の課題への回答に費やしている時間は 20% に過ぎないと報告しています。第三に、企業は、データ主権とGxPコンプライアンスを維持しながら、データのカタログ化、管理、共有、コラボレーションをより効率的に行うためのソリューションと、自社にとって重要な機密情報を開示することなく複数の関係者によるコラボレーションを可能にする機能を求めています。効果的なコラボレーションソリューションの必要性は急務であり、現在市場に参入している対応策の 50% 以上は、製薬会社、スタートアップ、大学、コンソーシアム間のパートナーシップによるものです。最後に、企業はバリューチェーン全体でイノベーションを促進するために、生成系AIと大規模言語モデル(LLM)の可能性を模索する競争を繰り広げています。そのため、差し迫ったデータに関する課題への緊急性がさらに高まっています。
シンポジウムのオープニング基調講演では、マルチモーダルデータの効率的な保管、分析、カタログ作成、共有のための専用サービスとソリューションによって、AWS がお客様の課題解決をどのように支援しているかを紹介しました。
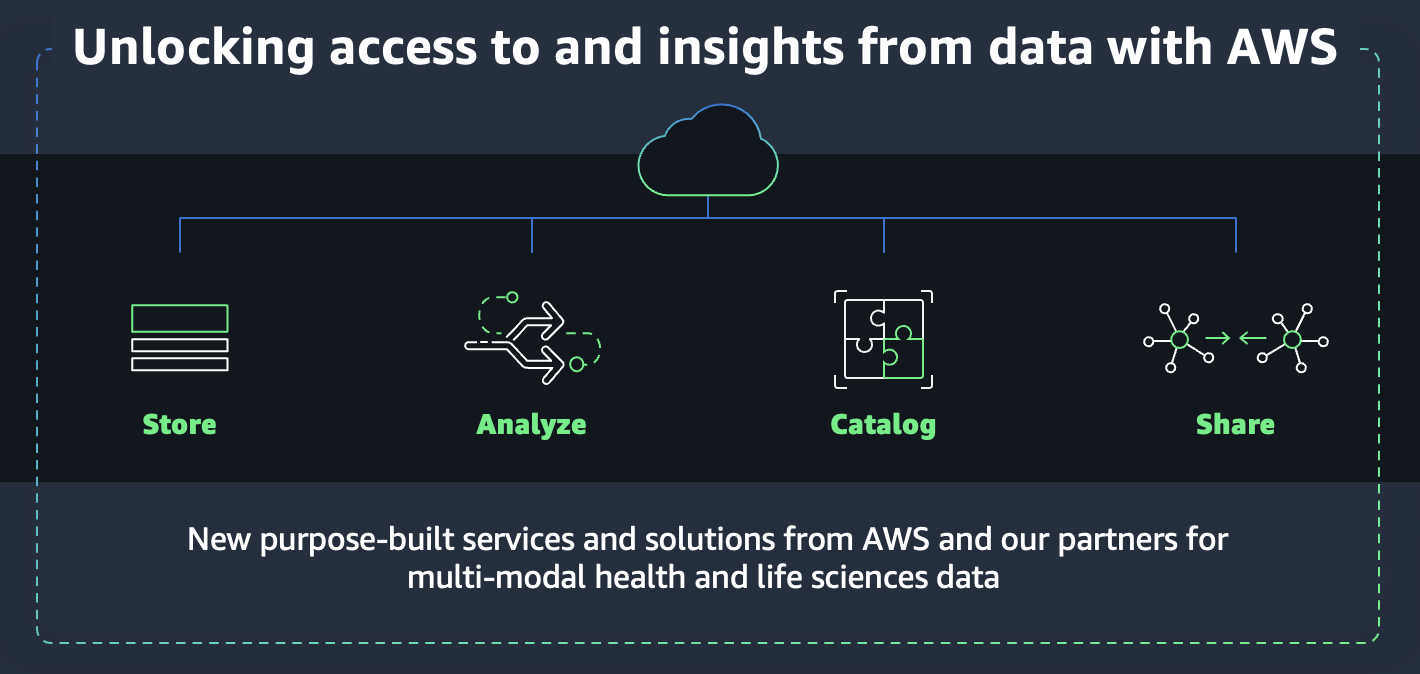
参加者は、業界固有のストレージと分析のニーズに合わせて特別に設計された 3 つの製品、Amazon HealthLake (訳注: 現在のAWS HealthLake) 、Amazon HealthLake Imaging (訳注: 現在のAWS HealthImaging)、Amazon Omics (訳注: 現在のAWS HealthOmics) についてのインサイトを得ました。Amazon HealthLake は HIPAA 適格サービスで、ユーザーは個人または患者の健康データを時系列で表示して大規模なクエリや分析を行うと同時に、医師のメモなどの非構造化臨床データを構造化データに自動的に変換します。Amazon HealthLake Imaging を使用すると、プロバイダーは医用画像ストレージのコストを最大 40% 削減でき、複数のユーザーがその画像の同じコピーにアクセスして 1 秒もかからずに画像を取得できるようになります。また、Amazon Omics は、ゲノミクス、トランスクリプトミクス、およびその他のオミクスデータを保存、クエリ、分析して、科学的発見を進めるためのより深いインサイトを生み出すのに役立ちます。これらのサービスにより、データを分析や機械学習に数分以内に利用できるようになり、Amazon Athena、Amazon Redshift、Amazon SageMaker などの使い慣れたツールや、Tableau やデロイトの ConvergeHealth MINER などのサードパーティツールで使用できるようになります。


データカタログ作成では、Amazon DataZone がビルトインのガバナンスによって企業独自のデータを活用するうえでどのように役立つかをデモしました。Amazon DataZone を使用すると、企業はエンタープライズデータエコシステム (データメッシュプラットフォームのような) を構築し、研究開発やコマーシャルなどの分野にまたがる複数のチームが効果的にコラボレーションできるようになります。統合データ分析ポータルへのプロジェクトレベルのアクセスにより、ユーザーはすべてのデータをパーソナライズされた360度ビューで確認できると同時に、厳格なガバナンスとコンプライアンスポリシーを適用できます。また、カスタムメタデータを含むデータ製品の一覧と、品質指標やプロファイリングに関する情報を追加できるため、ユーザーは数週間ではなく数日で作業を開始できます。
医療機関やライフサイエンス企業は、バイオマーカーやパスウェイの研究、臨床試験の設計、有効性に関するリアルワールドデータの分析など、外部ソースからのデータにアクセスする必要があることも理解しています。しかし、企業は多くの場合、購入するデータの単一コホートの定義に数週間を費やし、サードパーティデータのライセンスに毎年数百万ドルを費やし、社内に持ち込んだデータを変換して使用できるように数百時間を費やす必要があります。Amazon Data Exchange はユーザーが、1 つのユーザーインターフェイスから 3500 以上のデータセットにアクセスできることができ、簡単に検索、購入、使用できるように構築されており、このサービスを紹介したときには多くの参加者が興奮していました。一方で、データを交換できない(またはしたくない)企業のために、Amazon Clean Rooms を紹介しました。これは、企業とそのパートナーが、互いの基礎データを共有したりコピーしたりすることなく、より簡単かつ安全に共同作業して集合データセットを分析できるようにするためです。
また、生成AIにおけるデータの役割についても議論しました。AWS は長い間、人工知能 (AI) と ML が患者の治療成績を改善するものであるというお客様の期待を信じ、それを共有してきました。私たちは 20 年以上にわたり ML によるイノベーションに取り組んできましたが、その勢いは衰えていません。これは Amazon の伝統、精神、そして未来の一部であり、世界の製薬企業の上位 10 社のうち 9 社が AWS を分析と機械学習に使用しているのはそのためです。
振り返ってみると、私たちは機械学習の民主化において重要な役割を果たしてきました。ライフサイエンスのユースケースに特化した、最も幅広く深い一連のAIおよび機械学習サービスにアクセスして、お客様がより迅速にイノベーションを起こすのを支援してきました。また、生成AIにも同じアプローチを採用しています。つまり、ライフサイエンス企業がビジネスで生成AIを簡単に、費用対効果が高く、実用に値する斬新なイノベーションを提供しています。
適切なモデルを見つけることから、モデルを安全にカスタマイズすること、既存のアプリケーションにモデルを統合することまで、AWS が基盤モデル (FM) を使用して構築するのが最も簡単な場所であることを確認することに重点を置いています。そこで Amazon Bedrock を導入しました。これは、お客様が FM を使用して生成AIベースのアプリケーションを簡単に構築およびスケーリングできるようにし、すべてのビルダーが誰でもアクセスできるようにするためです。Amazon Bedrock では、データを非公開かつ安全に保つための安全なカスタマイズをサポートしています。お客様は Amazon S3 のラベル付けされたいくつかのサンプルを Amazon Bedrock に適用するだけで、大量のデータにラベルを付けることなく、特定のタスクに合わせてモデルを調整できます。また、エンドツーエンドのデータ戦略を策定するという当社の包括的なテーマに沿って、使い慣れたコントロールと Amazon SageMaker や Amazon S3 などの AWS の深くて幅広い機能との統合により、お客様が AWS 上で実行されているアプリケーションやワークロードに FM を簡単に統合してデプロイできるようにしています。

Amazon Bedrockがいかに簡単に使い始められるかを楽しみにしている一方で、多くのお客様がすでに生成AI のユースケースで既存の AWS サービスを活用していることも認識しています。たとえば、お客様は Amazon SageMaker Jumpstart と Amazon SageMaker Studio を使用して FM のトレーニング、ファインチューニング、デプロイ、および運用を大規模に行っています。また、AWS を活用したタンパク質フォールディングのガイダンスを使用すると、オープンソースの分子モデルを使用してワークフローを俊敏かつ大規模に実行できます。研究開発セッションにおける生成AIについて詳しく知るには、「ML による創薬研究の加速」のまとめをご覧ください。
データのトラックには、思慮深く準備されたライトニングトークから魅力的な座談会まで、他にも8つのセッションが用意されていました。先見の明のあるリーダーたちがステージに上がり、AWS を使用して重要な課題にどのように取り組んでいるかについて、刺激的な実例と共に紹介しました。また、AWS 主導のセッションも行われ、お客様の現在および将来のニーズを満たす新しい機能を紹介しました。
最初に、世界最大級のバイオバンクを構築するにあたり、AWS を使用してデータストアを最適化することで精密医療を加速させる方法を Ovation が紹介しました。参加者は、Amazon Omicsをどのように活用して、リンクされたオミクスやフェノタイプデータを安全かつ効率的に保存、クエリし、大規模に顧客に配信しているのかを知ることができました。Ovation は、AWS Data Exchange を介して、匿名化されリンクされたオミクスおよびフェノタイプデータへのアクセスと分析が、信頼性が高くコスト効率が高いことを説明します。研究者は、Ovation のオミックスやフェノタイプデータを自分の環境に直接取り込み、そのデータを AWS Step Functions と AWS Lake Formation を使用してデータレイクと Amazon Omics のバリアントストアにインポートできます。このデータは Amazon SageMaker ですぐに利用でき、複数の AI または ML モデルを構築してデプロイし、患者のオミクスプロファイルと疾患リスク、疾患の進行、治療結果との関係などのインサイトを得ることができます。

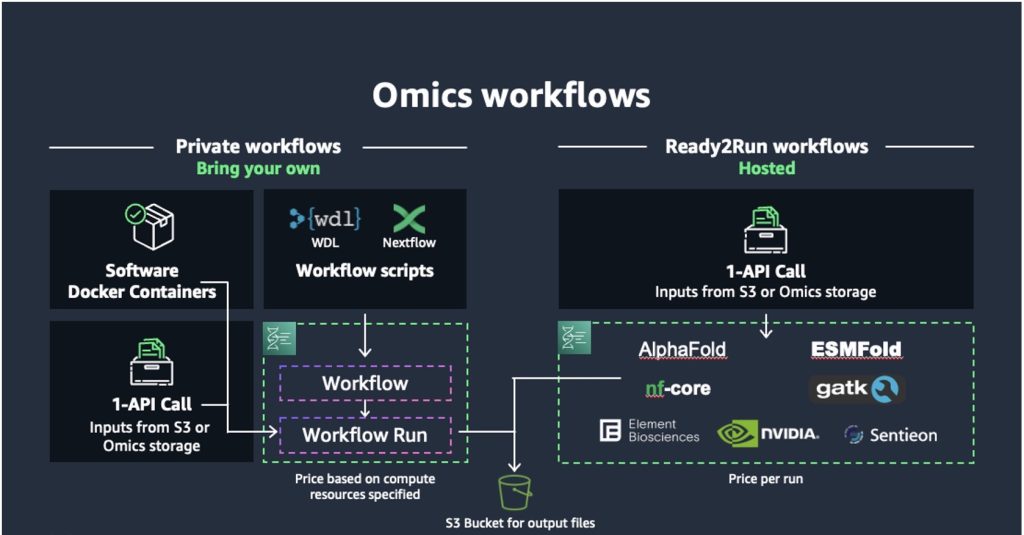
Ovation のセッションの後、Amazon Omicsの5つの新機能が発表されました。これにより、企業は定価によるワークフロー実行による予測可能な価格設定でワークロードをより簡単に構築、実行、スケーリングできるようになります。これには以下が含まれます。1/ Ready2Run のワークフロー、顧客が数回のクリックまたは 1 回の API 呼び出しで分析用の事前構築済みパイプラインを実行できる、2/ NVIDIA Parabricks とオープンソースのプロテインフォールディングパイプラインによる AI ベースのゲノミクス解析を高速化するための Omics プライベートワークフローにおける NVIDIA T4 および a10 グラフィカルプロセッシングユニット (GPU) のサポート、3/ FASTQ、BAM、CRAMファイルをコストパフォーマンスの高い価格で大規模に保存するための新しい取り込みAPIを使用したOmicsストレージへの直接データ取り込み、4/ 簡単にバリアントコールファイル (VCF) とアノテーションデータを変換してマルチオミック分析やマルチモーダル分析に使用できるようにすることで、自動バリアントデータ解析によるクエリと分析、5/ イベント駆動型アプリケーションと Amazon EventBridge の統合により、Amazon Omics が公開したイベントは、ラボ情報管理システム (LIMS) や診断レポートシステムなどの他の AWS サービスやソフトウェアアプリケーションと簡単に統合できます。これらの新機能は、Kite Pharma、コロンビア大学医療センター、FYR Diagnosticsなどのお客様ですでに使用されており、変更を加えることなく業界標準の分析ワークフローを実行できるようになっています。
ガバナンスの重要な側面を取り上げなければ、データに関する議論は包括的とは言えません。Collibraは、データドリブンな組織文化を構築し、スチュワードシップ管理、包括的なビジネス用語集、一元的なポリシー管理、そして最も重要なこととして、安全で管理されたデータアクセスの簡素化などのセルフサービス方式を通じてデータを容易に入手できるようにするためのベストプラクティスについてのインサイトを共有しました。
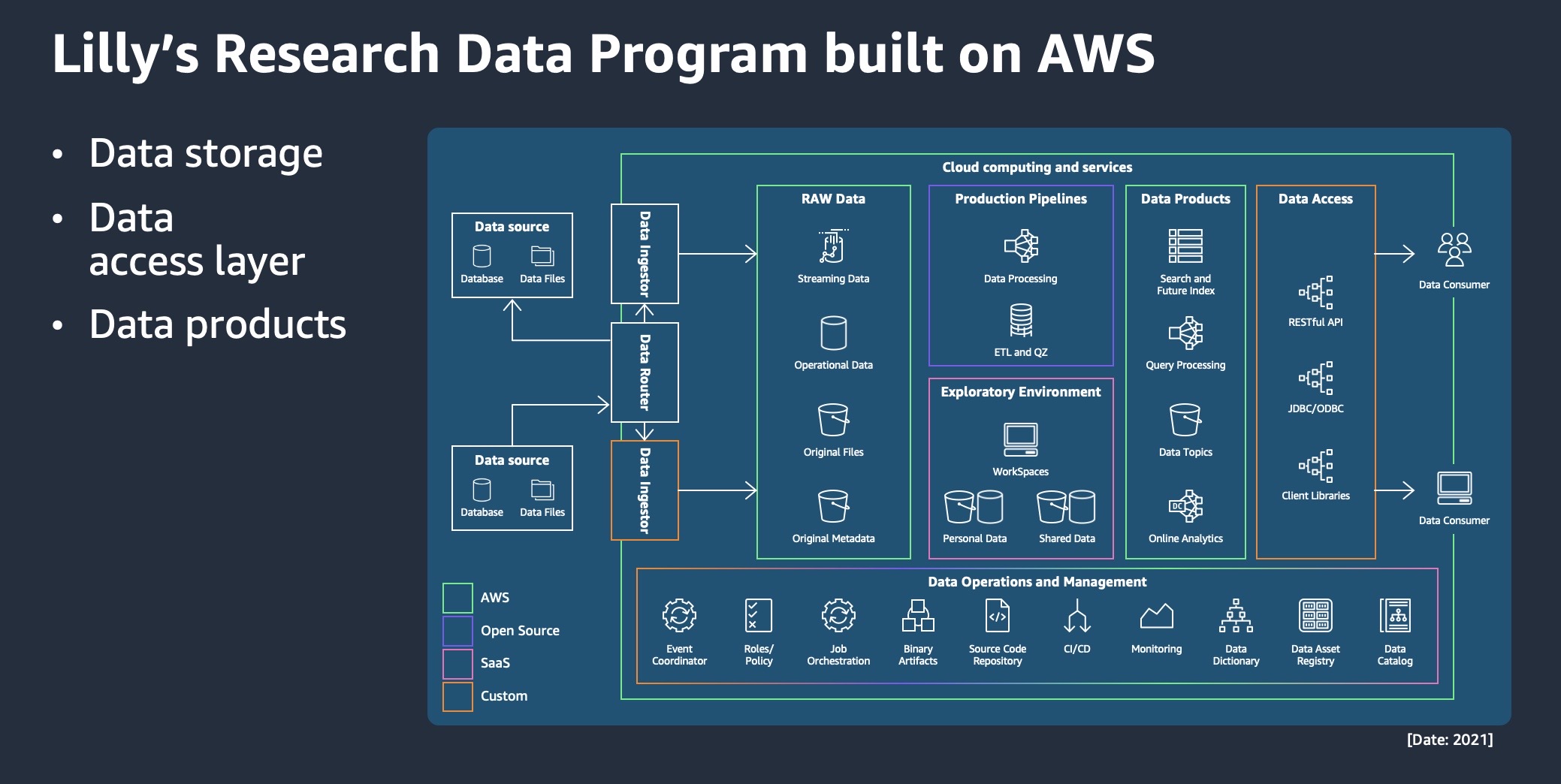
それに続き、2 つのバイオ医薬品企業である Eli Lilly と Foundation Medicine が、自社データの価値を引き出すためのライトニングトークを発表しました。140 年以上前に設立された Lilly は、AWS上で社内データをあたかも製品として扱うような重厚なデータエコシステムを形成し、(FAIR の原則に沿った) 広範なマルチモーダルデータランドスケープを活用することで、いかに研究開発を加速させているかについて紹介しました。ハイライトは、研究データプラットフォームがどのようにさまざまな AWS サービスを使用してデータストレージ、データアクセス、データ製品レイヤーを構築し、研究者がポートフォリオの意思決定に関するインサイトをより迅速かつ効率的に得ることができるかを詳しく説明したことです。Lilly はまた、LLMや会話型AIを創薬に活用する今後の取り組みについても話しました。一方、Foundation Medicineは、自社のエンタープライズデータプラットフォームがどのようにFDAの承認を早め、医学研究機関とのより緊密なコラボレーションを促進しているかを共有しました。
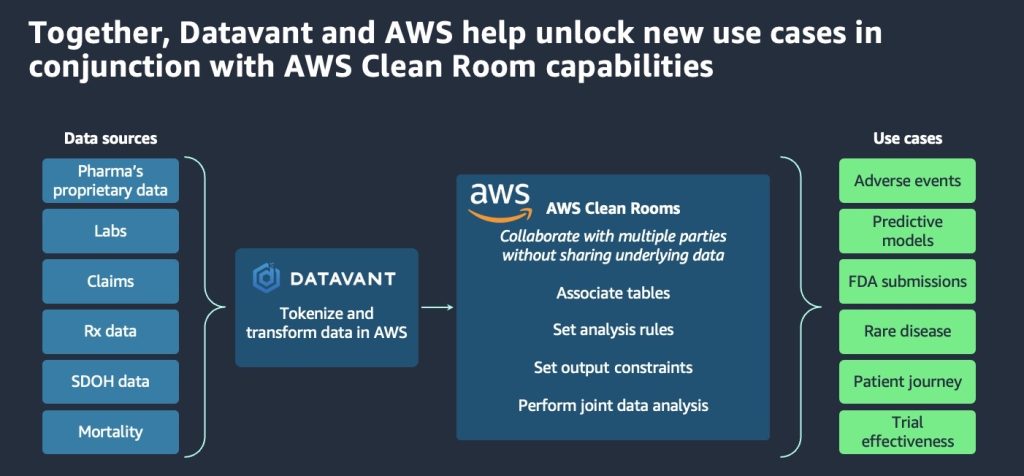
コラボレーションの流れに続き、次のセッションでは、AWS とパートナーの Datavant が、AWS Clean Rooms が HIPAA 適格になったことを発表しました。医療機関やライフサイエンス企業は、パートナーと数分でAWS Clean Roomsのコラボレーションを構築し、基礎となるデータを共有したり、AWSの外に移動したりすることなく、集合的なデータセットを分析できます。Datavantは、データの匿名化とトークン化機能のデモを実施しました。これにより、顧客は識別可能な患者情報を、リバースエンジニアリングして元の情報を明らかにできない暗号化された「トークン」に置き換えることができるため、集団分析が容易になり、新しいインサイトを得ることができます。
また、学術機関、非営利団体、連邦政府機関の研究者に対し、今年1月からNIHが資金提供したすべての研究データを一般に公開することを義務付ける米国政府の新しい規制変更についても取り上げました。この画期的な執行規制は、臨床研究とライフサイエンスに幅広い影響を及ぼします。技術開発拠点の1つに指定されているMITREは、これらの変化がCancer Moonshot Initiativeなどの主要プログラムにどのように影響するかを発表しました。彼らは、25年以内にがんによる死亡率を50%削減するという国の取り組みにおいて、クラウドインフラストラクチャとソフトウェアソリューションを使用することで、データ収集と共有のメカニズムがどのように強化されるかを説明しました。参加者は、ポータブルで共有可能で標準化されたがん医療記録を作成するプログラムであるCC-Direct、あらゆるタイプのがんのEHRデータの質を向上させるデータ標準であるmCode、mCodeに関する相互運用可能なデータモデリングと実装を加速し、がん治療の段階的な改善につながるプラットフォームであるCoDexについて意見を聞きました。

最後に、AWSのパートナーであるTrinetXが、投資に見合った価値を備えたリアルワールドデータ製品を作るという彼らの革新的なアプローチについて発表しました。参加者は、AWS 上に構築された、200 を超える医療機関の 1 億5,000万人以上の患者からのリンクされたデータで構成される、大規模なリアルワールドデータエコシステムを垣間見ることができました。製薬会社はTrinetXと協力して、臨床試験からエビデンス生成まで、さまざまなユースケースに対応するHCOのグローバルネットワークから患者コホートにアクセスできます。Amazon S3 と Amazon Redshift 経由の Amazon Data Exchange を使用すると、組織はインフラストラクチャを維持する必要なく、このデータに簡単にアクセスして数分でインサイトを引き出すことができます。

セッション中に提示されたすべての内容が、お客様にとって実行可能なものであることを確認することが私たちにとって極めて重要でした。その一環として、セッション終了後に Ask-the-Expert デモとネットワーキングエキスポを開催しました。参加者は AWS の専門家と面談して、当社サービスの詳細なデモを見たり、不明な点があれば質問したりしました。
最後に考えたのは、17 年前に AWS を立ち上げたときから、臨床およびライフサイエンスの研究者がクラウド利用の最前線にいたということです。そして、シンポジウムで業界のリーダーたちが団結し、個別化医療に向けて大きな一歩を踏み出すのを目の当たりにしたことは、私たちが「the art of the possible」と呼ぶものの真の姿でした。
当社の包括的なデータサービスの詳細については、AWS Health for Data ウェブサイトをご覧ください。特定のビジネスニーズについて AWS スペシャリストと 1 対 1 で話し合いたい場合は、こちらからお問い合わせください。
Valerie Delva
Valerie Delvaは、AWS の Data/AI/ML 戦略およびソリューション担当のワールドワイドヘッドです。彼女はヘルスケアとライフサイエンスのエグゼクティブであり、データ製品の開発と提供、市場開拓と事業開発の先頭に立ち、規制対象の業界が交差する場所で新しいベンチャーを立ち上げ、学際的なチームを率いた経験があります。AWS に入社する前は、Foundation Medicine、Gilead Sciences、米国保健社会福祉省など、民間部門と公共部門の両方で上級職を歴任しました。彼女は、データの力を最大限に活用して、医療をより予防的、パーソナライズされた、利用しやすいものにすることに全力を注いでいます。
翻訳はソリューションアーキテクトの松永と事業開発の亀田が担当しました。