AWS for Industries
Highlights from the AWS Life Sciences Executive Symposium 2023: Unlocking access to and insights from data
On May 15, we hosted the AWS Life Sciences Executive Symposium in Boston, where I led the track on ‘unlocking access to and insights from data’. Over 300 life sciences executives from across 100 organizations attended this half-day, in-person event to explore how they can drive innovation through robust data foundations and machine learning (ML) on the cloud.
Several emerging trends made this data-focused track quite timely. First, life sciences organizations are under tremendous pressure to do more with less. In the light of the Inflation Reduction Act, expiring patents, and the need to speed up R&D, companies are exploring ways to better leverage their data to accelerate time-to-market and improve operational agility. Second, nearly 97% of health data generated today goes unused due to inadequate storage and management. Teams report spending up to 80% of their time finding, buying, and cleaning data, leaving only 20% of their time for generating insights and evidence, and answering scientific or business questions. Third, businesses are seeking solutions to more efficiently catalog, control, share, and collaborate on data while maintaining data sovereignty and GxP compliance, and capabilities to enable multi-party collaborations without revealing the underlying data. The need for effective collaboration solutions is acute, over 50% of therapies entering the market today are a result of partnerships between pharmaceutical companies, startups, universities, and consortia. Lastly, companies are in a race to explore the potential of generative AI and Large Language Models (LLMs) in expediting innovation throughout their value chain — further intensifying the urgency to address immediate data challenges.
In my opening keynote at the symposium, I shared how AWS is helping our customers address these challenges with purpose-built services and solutions for efficient storage, analysis, cataloging, and sharing of multi-modal data.
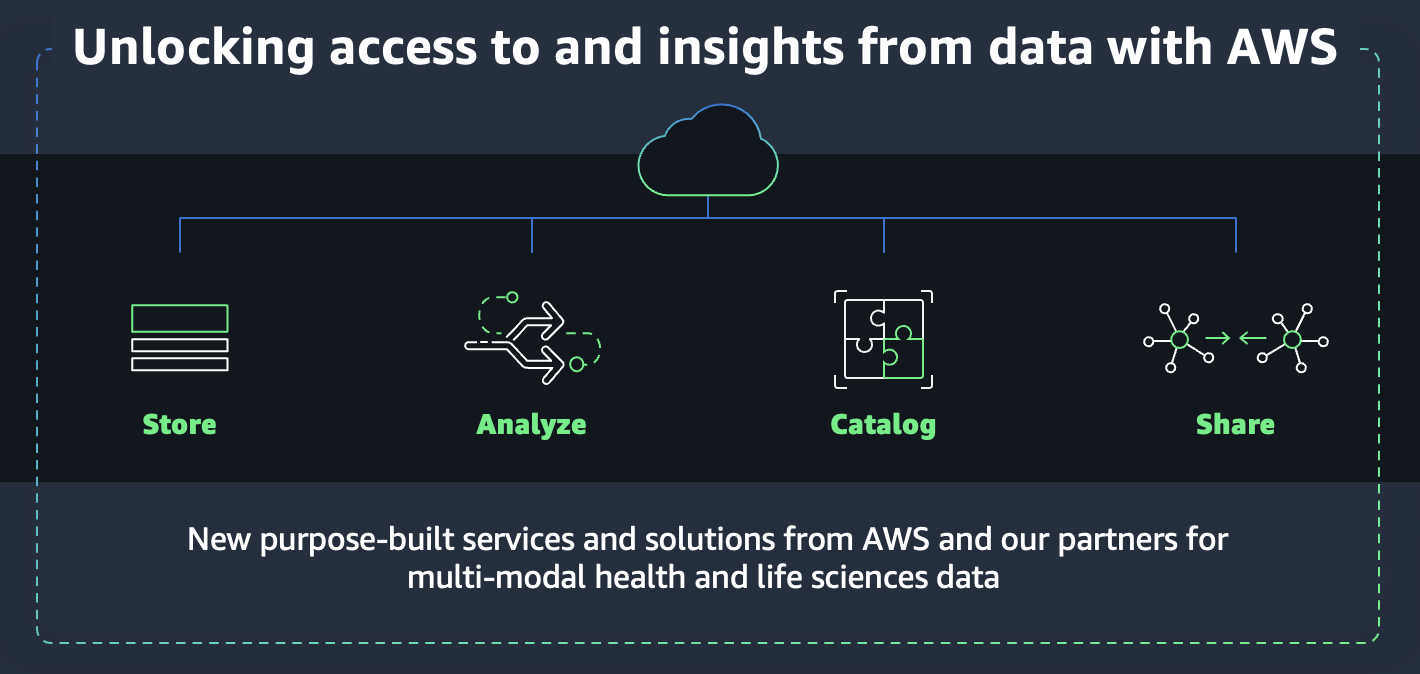
Attendees gained insights into three offerings specifically designed around our industry’s unique storage and analytics needs- Amazon HealthLake, Amazon HealthLake Imaging, and Amazon Omics. Amazon HealthLake is our HIPAA-eligible service offering users a chronological view of individual or patient population health data for query and analytics at scale, while automatically converting unstructured clinical data like physician notes into structured data. Amazon HealthLake Imaging helps providers reduce the cost of medicl imaging storage by up to 40%, and allows multiple users to access the same copy of that image and with sub-second image retrieval. And, Amazon Omics helps organizations store, query, and analyze genomic, transcriptomic, and other omics data to generate deeper insights for advancing scientific discoveries. These services make data available for analytics and machine learning within minutes, for use by familiar tools such as Amazon Athena, Amazon Redshift, and Amazon SageMaker, or third-party tools like Tableau or Deloitte’s ConvergeHealth MINER.


For data cataloguing, I demoed how Amazon DataZone can help organizations unlock their own data with built-in governance. Using Amazon DataZone, companies can build an enterprise data ecosystem (like a data mesh platform), for multiple teams across domains like R&D and commercial to collaborate effectively. Project-level access to a unified data analytics portal gives users a personalized, 360-degree view of all the data, while enforcing stringent governance and compliance policies. And, the listing of data products with custom metadata, along with the ability to add information around quality metrics and profiling gives users the ability to start working with it in days vs. weeks.
We understand healthcare and life sciences organizations also need to access data from external sources whether to study biomarkers and disease pathways, design a clinical trial, or to generate real-world evidence of efficacy. But, companies often need to invest weeks in defining single cohorts of data for purchase, spend millions of dollars each year licensing third-party data, and dedicate hundreds of hours converting the data for usage once brought in-house. This is why the attendees were excited when we gave them a view into Amazon Data Exchange, built to make it easy for users to find, subscribe to, and use third-party data in the cloud, with access to 3500+ datasets from a single user interface. But, for those organizations who are unable (or, unwilling) to put their data onto an exchange, we showcased Amazon Clean Rooms, to help them and their partners more easily and securely collaborate and analyze their collective datasets—without sharing or copying each other’s underlying data.
We also discussed the role of data in Generative AI. AWS has long believed in and shared our customers’ excitement around the power of artificial intelligence (AI) and ML to transform patient outcomes. We have been innovating with ML for more than two decades, and we’re not slowing down. It’s part of Amazon’s heritage, ethos, and future, and it’s why nine out of the top 10 global pharma companies use AWS for analytics and machine learning.
Looking back, we have played a key role in democratizing ML, helping our customers innovate faster with access to the broadest and deepest set of AI and ML services, purpose-built for life sciences use cases. And, we are taking the same approach to generative AI: delivering new innovations to make it easy, cost effective, and practical for life sciences organizations to leverage generative AI in their business.
We are focused on making sure AWS is the easiest place to build with foundation models (FMs)—from finding the right models, to securely customizing models, to integrating models into your existing applications. That’s why we introduced Amazon Bedrock—so that our customers will be able to easily to build and scale generative AI-based applications using FMs, democratizing access for all builders. With Amazon Bedrock, we support secure customization so that your data stays private and secure. Customers simply point Amazon Bedrock at a few labeled examples in Amazon S3, and the service can fine-tune the model for a particular task without having to annotate large volumes of data. And in-line with our overarching theme of creating an end-to-end data strategy, we are making sure customers can readily integrate and deploy FMs into their applications and workloads running on AWS using familiar controls and integrations with AWS’s depth and breadth of capabilities like Amazon SageMaker and Amazon S3.

While we’re excited to see how Amazon Bedrock makes it easier to get started, we also realize that many of our customers have already been leveraging existing AWS services for generative AI use cases. For example, our customers are using Amazon SageMaker Jumpstart and Studio to train, fine-tune, deploy, and operationalize FMs at scale. And, with the Guidance for Protein Folding on AWS, you can run workflows with open-source molecular models with agility and scale. To take a deeper dive into our generative AI in R&D sessions, check out the recap of the ‘accelerating pharma drug discovery with ML‘ track.
The data track also featured eight other sessions, from thoughtfully curated lightning talks to engaging fireside chats. Leaders from forward-thinking organizations took the stage to share inspiring real-world examples of how they are tackling critical challenges using AWS. Alongside, there were AWS-led sessions where we unveiled new capabilities to meet our customers’ current and future needs.
To kick us off, we had Ovation share how they are helping accelerate precision medicine by optimizing their data stores using AWS, as they build one of the largest bio-banks worldwide. Attendees got a view into how they utilize Amazon Omics to securely and efficiently store, query, and deliver linked omics and phenotypic data to customers at scale. Ovation ensures accessing and analyzing our de-identified, linked omics and phenotypic data is both reliable and cost-efficient via AWS Data Exchange. Researchers can directly ingest Ovation omics and phenotypic data into their own environment, importing the data into a data lake and Amazon Omics’ variant store using AWS Step Functions and AWS Lake Formation. This data is immediately available for use by Amazon SageMaker to build and deploy multiple AI or ML models and drive insights, such as the relationship between patient omics profile and disease risk, disease progress, or therapy response.

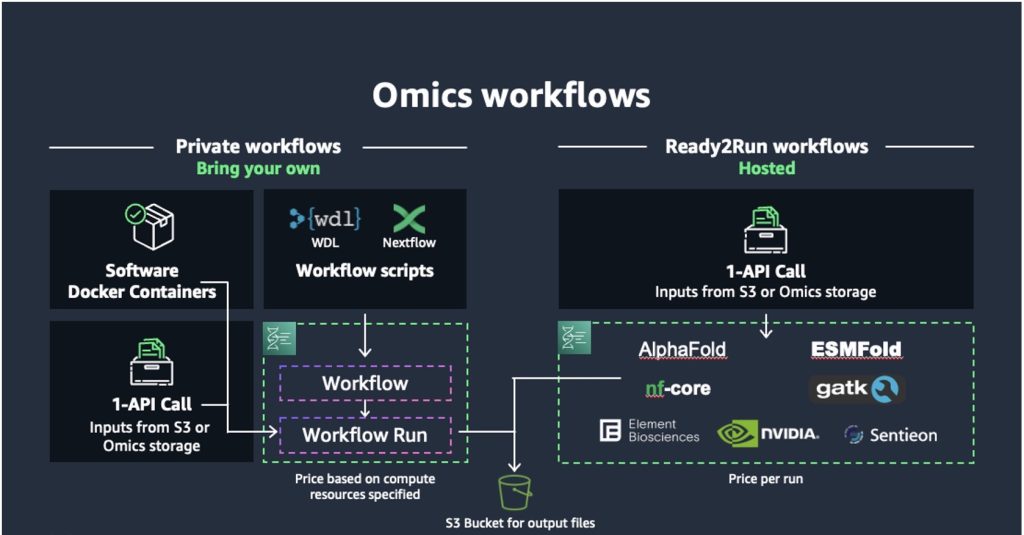
Ovation’s session set the scene for our announcement of five new capabilities for Amazon Omics, to make it even easier for organizations to build, run, and scale their workloads with predictable pricing. This includes: 1/ Ready2Run workflows from third-party software companies and open-source pipelines that allows customers to run pre-built pipelines for primary analysis with a few clicks or a single API call; 2/ Support for NVIDIA T4 and a10 graphical processing units (GPUs) in Omics private workflows for accelerated and AI-based genomics analysis with NVIDIA Parabricks and open-source protein folding pipelines; 3/ Direct data ingestion to Omics storage using new ingestion APIs for storing FASTQ, BAM, and CRAM files at a cost-effective price at scale; 4/ Easier querying and analysis with automatic variant data parsing by allowing customers to transform Variant Call Files (VCFs) and annotation data for use in multi-omic and multi-modal analysis; 5/ Integration of event-driven applications with Amazon EventBridge allowing Amazon Omics published events to easily integrate with other AWS services and software applications such as Laboratory Information Management Systems (LIMS) or diagnostic reporting systems. These new capabilities are already in use today by customers such as Kite Pharma, Columbia University Medical Center, and FYR Diagnostics, helping them run industry standard analysis workflows without needing to make any modifications.
No discussion on data can be considered comprehensive without addressing the critical aspect of governance. In a fireside chat, Collibra shared insights about best practices for building a data-driven culture within organizations, making data readily available through self-service methods like stewardship management, comprehensive business glossary, centralized policy management, and most importantly, simplifying secure and governed data access.
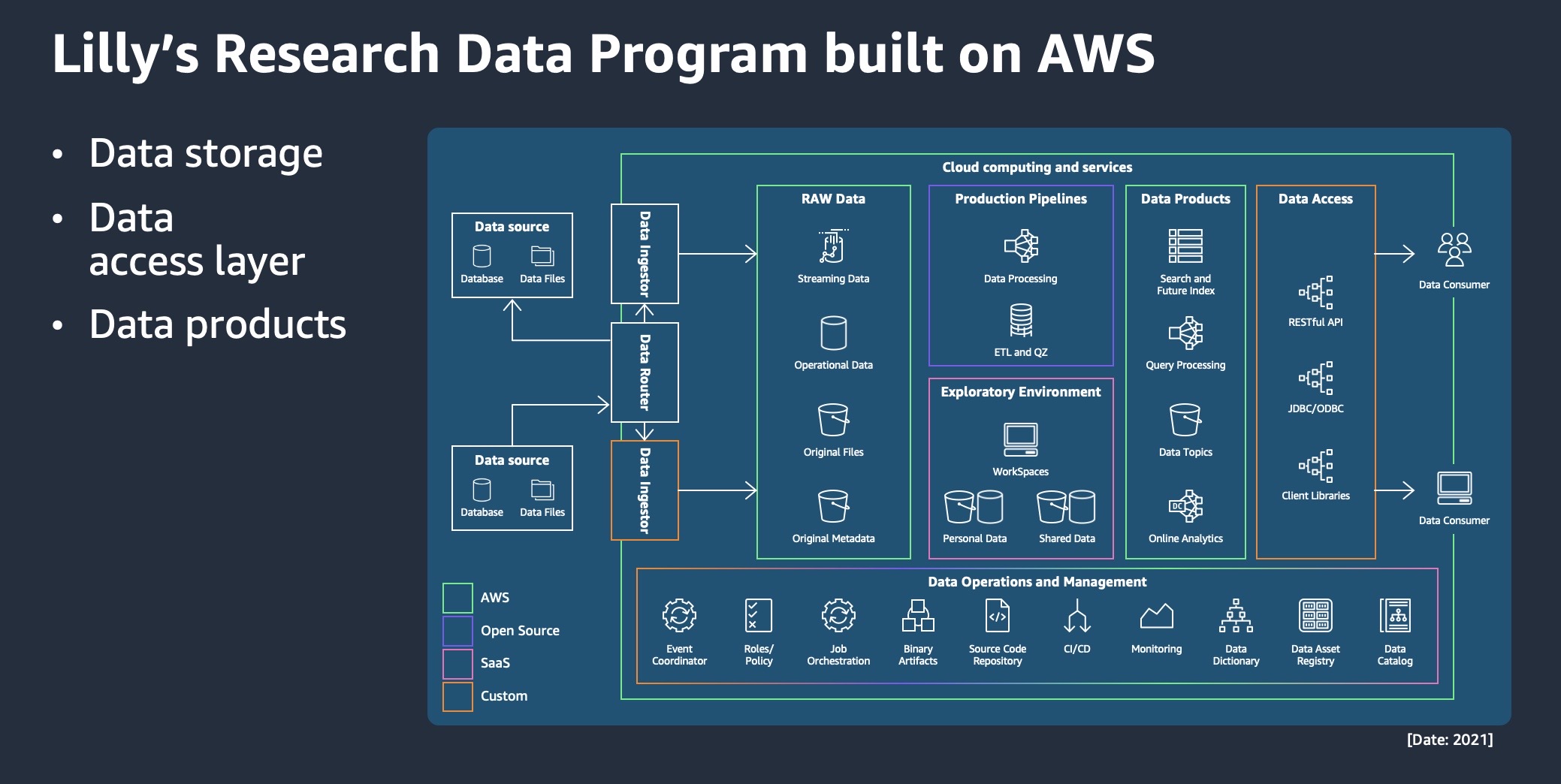
This provided the backdrop for the lighting talks by two bio-pharma organizations Eli Lilly and Foundation Medicine on unlocking the value of their own data. 140+ years old Lilly presented how they are accelerating R&D by harnessing its extensive multi-modal data landscape (aligned to FAIR principles), using a deep ecosystem of data products on AWS. The highlight was a deep-dive into how their Research Data Platform uses a range of AWS services to build its data storage, data access, and data products layers, to help scientists gain insights for portfolio decisions faster and more efficiently. Lilly also spoke about their future initiatives of using LLMs and conversational AI in drug discovery. Foundation Medicine, on the other hand, shared how their enterprise data platforms are expediting FDA approvals and fostering closer collaboration with academic medical centers.
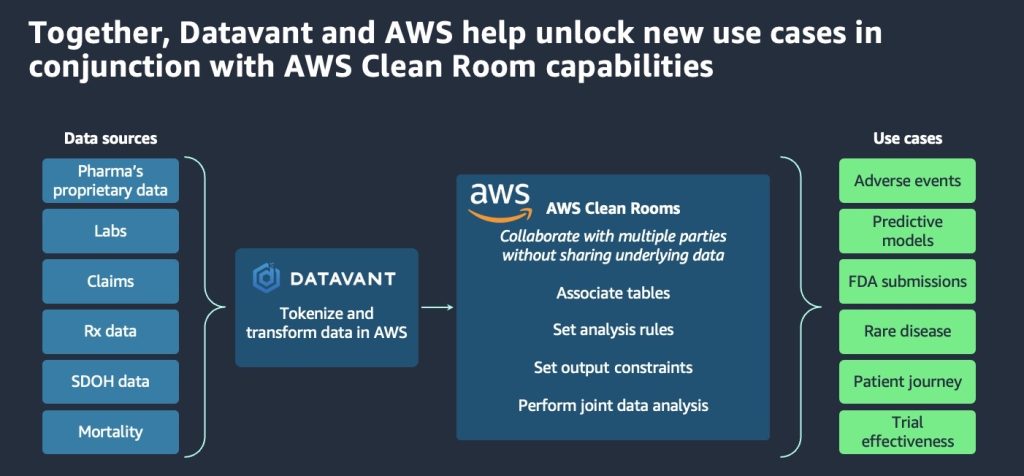
Continuing on the thread of collaboration, the next session had AWS and our partner, Datavant, come together to announce that AWS Clean Rooms is now HIPAA-eligible. Healthcare and life sciences organizations can create an AWS Clean Rooms collaboration in minutes with their partners, and analyze their collective datasets without sharing underlying data, or moving it outside of AWS. Datavant demoed their data de-identification and tokenization capabilities that enables customers to replace identifiable patient information with an encrypted “token” that can’t be reverse-engineered to reveal the original information, facilitating collective analysis to gain new insights.
We also covered the recent changes in US federal regulation that mandates researchers across academic institutions, nonprofits, and federal agencies to make all NIH-funded research data accessible to the public starting this past January. This landmark executive rule has widespread implications for clinical research and life sciences. MITRE, who is designated as one of the technology development locations, presented how these changes impact key programs such as the Cancer Moonshot Initiative. They explained how using cloud infrastructure and software solutions will enhance mechanisms for data collection and sharing, in the nation’s journey towards decreasing the cancer mortality rate by 50% within 25 years. Attendees got a view into CC-Direct, a program for creating a portable, shareable, standardized cancer health record to reduce barriers to care; mCode, a data standard to increase the quality of EHR data for all cancer types; and CodeX, a platform to accelerate interoperable data modeling and implementation around mCODE, leading to step-change improvements in cancer care.

Lastly, AWS Partner, TrinetX, presented on their innovative approach of creating real-world data products with ROI. Attendees got a glimpse into their massive real-world data ecosystem, built on AWS, comprising linked data from 150M+ patients from over 200 health care organizations. Pharma companies can collaborate with TrinetX to access patient cohorts from its global network of HCOs, for a range of use cases from trial operations to evidence generation. Using Amazon Data Exchange via Amazon S3 and Amazon Redshift, organizations can effortlessly access this data to derive insights in minutes, without the need to maintain any infrastructure.

It was crucial for us to ensure that everything that was presented during the sessions was made actionable for our customers. As a part of that commitment, we hosted a dedicated Ask-the-Expert demo and networking expo after the sessions, where attendees met with AWS experts to view in-depth demos of our offerings and ask any clarifying questions.
One final thought, clinical and life sciences researchers were at the forefront of cloud adoption when we launched AWS 17 years ago. And witnessing the industry leaders unite and take significant steps towards personalized health at our Symposium was inspiring—it was a true depiction of what we call ‘the art of the possible’.
To learn more about our comprehensive set of data offerings, visit the AWS Health for Data website. If you’d like to schedule a one-on-one with an AWS specialist to discuss your specific business needs, please reach out to us here.