Amazon Web Services ブログ
Amazon DynamoDB ストリームを使用して、順序付けされたデータをアプリケーション間でレプリケーションする方法
AWS の顧客は、Amazon DynamoDB を使用してミッションクリティカルなデータを保存しています。このような顧客のアプリケーションから 1 秒に何百万ものリクエストが、何百テラバイトの項目を含む個々の DynamoDB テーブルに送られます。顧客は DynamoDB が瞬時に結果を返すことを頼りにしています。
多くの場合、これらのアプリケーションには特定のトランザクション、監査、またはアーカイブトランザクションについて他のシステムとユーザーに通知し、データを別のデータストアにほぼリアルタイムでレプリケートするという要件があります。これらの要件は、DynamoDB 内の項目への変更の順序を維持することで満たすことができます。このような機能を構築するには、DynamoDB 内の項目への変更が並列処理され、ほぼリアルタイムのパフォーマンスを達成することが必要です。
Amazon DynamoDB ストリーム を他の AWS サービスと統合して、順序付けられたほぼリアルタイムのデータ処理機能を構築することができます。DynamoDB ストリームは、DynamoDB テーブルの項目レベルの変更に対して時間順序のシーケンスをキャプチャし、その情報を最高 24 時間まで保存します。そしてアプリケーションからは、ほぼリアルタイムで DynamoDB ストリームからの一連のストリームレコードにアクセスすることができます。
この記事では、AWS サーバーレスコンピューティングの一部である複数の AWS サービスを使用して DynamoDB ストリームを処理するための複数のパターンを評価します。また、他のシステムやユーザーに通知し、トランザクションをアーカイブし、順序付けされた処理を維持しながらデータを別のデータストアにレプリケートするために、ほぼリアルタイムの DynamoDB ストリーム処理を実行できる最も信頼性の高いスケーラブルなパターンの詳細にも触れます。
AWS Lambda を使用した DynamoDB ストリームの処理
AWS Lambda は、サーバーをプロビジョニングまたは管理せずにコードを実行できるサービスです。たとえば Lambda は、DynamoDB ストリームのイベント (項目の挿入、更新、削除など) に基づいてコードを実行できます。Lambda は DynamoDB ストリームをポーリングし、新しいレコードを検出すると Lambda 関数を呼び出し、1 つ以上のイベントを実行します。
Lambda による DynamoDB ストリームの処理の過程を理解するには、DynamoDB ストリームの仕組みを理解する必要があります。DynamoDB はデータをパーティションに保存します。パーティションは、パーティションキーのみ、またはパーティションキーと ソートキーの両方、のどちらかに基づきます。DynamoDB テーブルでストリームを有効化した場合、DynamoDB はパーティションごとに最低 1 つのシャードを作成します。
DynamoDB ストリーム内のシャードはストリームレコードの集合です。各ストリームレコードは、ストリームが属する DynamoDB テーブル内の単一データの変更を表します。
次の図は、ストリーム、ストリーム内のシャード、シャード内のストリームレコードの関係性を示します。シャードについての詳細は、「DynamoDB ストリーム を使用したテーブルアクティビティのキャプチャ」を参照してください。

次の図は 3 つのパーティションのある DynamoDB テーブルを示します。このテーブル用に有効化されたストリームで、DynamoDB はパーティションごとに 1 つ、最低 3 つのシャードを作成します。DynamoDB は、パーティション内の各項目に実行された変更 (挿入、更新、削除) を、変更された順序を維持したまま対応するシャードに中継します。このプロセスは、指定されたキー 1 つが多くても 1 つのシャードに存在し、その順序が維持されるようにします。
1 つの Lambda 関数が DynamoDB ストリームを処理するよう設定されている場合、その Lambda 関数の 1 個のインスタンスがシャードごとに呼び出されます。次の図の DynamoDB ストリームには 3 つのシャードがあることから、 各パーティションの 1 つまたは複数の項目に変更があると、3 つの Lambda 関数が同時に呼び出されます。

DynamoDB ストリームへの複数の Lambda 関数の設定
DynamoDB を使用して、1 つのストリームに複数の Lambda 関数を設定してデータの並列処理を有効化する場合、各関数はシャードごとに同時に呼び出されます。次の図は DynamoDB ストリームで同時に呼び出されるように設定された、2 つの Lambda 関数の例を示します。

DynamoDB では 1 つのストリームに複数の Lambda 関数を設定できますが、ストリームごとに 3 つ以上の Lambda 関数を設定するとリクエストが失敗する可能性が高くなります。DynamoDB ストリームから読み込める Lambda 関数またはプロセスの数は、今後増える可能性があります。ストリーム内でデータをリアルタイムで確実に処理するには、Lambda 関数のリクエストが成功することが必要です。ストリームデータの順序付けられた並列処理を有効化し、Lambda 関数のリクエストを成功させるには、ファンアウトパターンを実装します。
ファンアウトパターンを使用した DynamoDB ストリームの処理
DynamoDB ストリーム処理のためのファンアウトパターンには、次の複数のパターンがあります。
- Lambda ファンアウトパターン
- Amazon SQS への Amazon SNS ファンアウトパターン
- Kinesis Data Streams ファンアウトパターン
Lambda ファンアウトパターン
Lambda ファンアウトパターンでは、単一のLambda 関数を設定して DynamoDB ストリームを処理します。Lambda は DynamoDB ストリームをポーリングし、新しいレコードを検出すると、1 つ以上のイベントを実行して、この Lambda 関数を呼び出します。Lambda 関数は各項目を処理し、ダウンストリームサービスまたは API を呼び出します。
次の例は、DynamoDB ストリームを処理する Lambda 関数を示します。この関数は別の Lambda 関数を呼び出してユーザーに通知し、DynamoDB テーブルを更新して Amazon Kinesis Data Stream に書き込みます。この関数のスループットは、ダウンストリームサービスまたは API 上で一括操作を実施する能力に依存します。

Lambda ファンアウトパターンを使用した際の利点には以下が含まれます。
- Lambda 関数の処理が失敗した場合、Lambda は成功するまで、またはストリームからのデータの有効期限が切れるまでレコードのバッチ全体を再試行します。この再試行のメカニズムは、すべてのイベントが正しい順序で処理されるために役立ちます。AWS Lambda が失敗した際の処理の詳細については、「再試行動作について」を参照してください。
このパターンを使用した際、弱点となるものには以下が含まれます。
- Lambda は部分的な失敗への処理として再試行を実施しますが、システムは完全なリアルタイムではなくなります。
- ダウンストリームサービスへの書き込み時に部分的な失敗を処理する際、メッセージの書き込み順序を保証することは難しくなります。
- 新しいダウンストリームサービスにデータを送信するためには、Lambda 関数を再度デプロイする必要があります。
- Lambda の処理が失敗すると、レコードのバッチ全体が再処理されるため、Kinesis Data Streams または DynamoDB 内のレコード重複につながることがあります。
- Lambda 関数のスループットは、ダウンストリームデータの保存時またはアプリケーションの導入時に低下します。
Amazon SQS への Amazon SNS ファンアウトパターン
Amazon Simple Notification Service (Amazon SNS) は柔軟な完全マネージド型のパブリッシュ/サブスクライブのメッセージングおよびモバイル通知サービスで、登録中のエンドポイントやクライアントに配信するメッセージを調整できます。Amazon Simple Queue Service (Amazon SQS) は完全マネージド型のメッセージキューサービスで、マイクロサービス、分散システム、サーバーレスアプリケーションの分離とスケーリングを容易にします。
Amazon SQS への Amazon SNS ファンアウトパターンでは、単一の Lambda 関数を設定して DynamoDB ストリームを処理します。Lambda は DynamoDB ストリームをポーリングし、新しいレコードを検出すると、1 つ以上のイベントを実行して、この Lambda 関数を呼び出します。Lambda 関数は各項目を処理し、発行 API を使用して SNS トピックへ書き込みます。
SNS トピックへサブスクライブする SQS キューを作成すると、各キューはメッセージがそのトピックへとプッシュされるたびに同一の通知を受信します。その後、これらの SQS キューにアタッチされているサービスは、これらのメッセージを非同期処理および並列処理します。
次の例では、DynamoDB ストリームを処理している Lambda 関数が SNS トピックにメッセージを書き込みます。SNS はそのメッセージをそのトピックにサブスクライブされている各 SQS キューに配信します。Amazon CloudWatch Events を使用してスケジュールされた Lambda 関数は、これらのメッセージをさらに処理し、ダウンストリームサービスまたは API と通信するために使用されます。
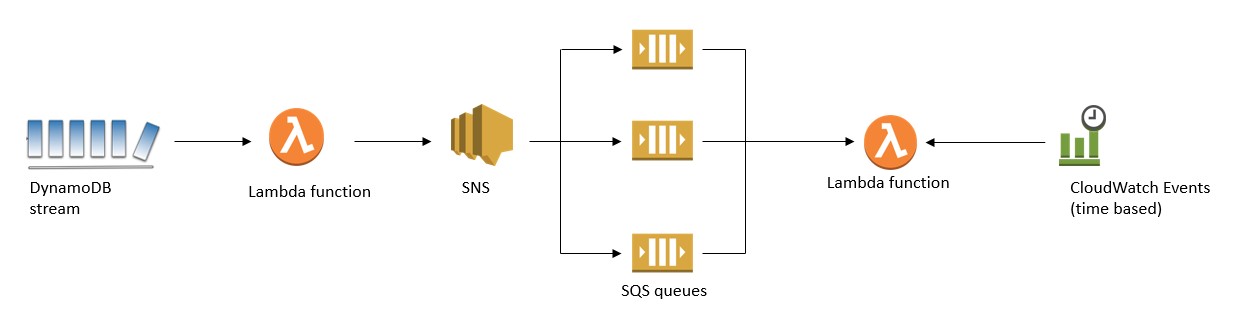
このパターンを使用した際の利点には以下が含まれます。
- 1 つの SNS トピックに多くの AWS のサービスをサブスクライブできるため、拡張可能なサブスクリプションメカニズムを提供します。
- Lambda 関数の処理が失敗した場合、Lambda は成功するまで、またはストリームからのデータの有効期限が切れるまでレコードのバッチ全体を再試行します。この再試行のメカニズムによって、すべてのイベントが正しい順序で処理されます。AWS Lambda が失敗した際の処理の詳細については、「再試行動作について」を参照してください。
このパターンの弱点となるものには以下が含まれます。
- Amazon SNS にはメッセージサイズが 256 KB までという制限があるため、DynamoDB の項目のサイズもこの制限内となります。
- SNS が SQS キューへ書き込む際に部分的に失敗している間、メッセージの書き込みは順序付けられません。
- 関数の処理が失敗した際の再試行によって、システムは完全なリアルタイムではなくなります。
- Amazon SQS 内のメッセージは、CloudWatch Events でスケジュールされた Lambda 関数によって処理されますが、システムは完全なリアルタイムではなくなります。
- Lambda の処理が失敗すると、レコードのバッチ全体が再処理されるため、SQS 内でレコードが重複することがあります。
Kinesis Data Streams ファンアウトパターン
Kinesis Data Streams では、ストリーミングデータを処理または分析するカスタムアプリケーションを構築することができます。Kinesis Data Streams は、数百万件のソースから 1 時間あたりテラバイト単位のデータを継続的にキャプチャし保存することができます。
Kinesis Data Streams ファンアウトパターンでは、単一の Lambda 関数を設定して DynamoDB ストリームを処理します。Lambda は DynamoDB ストリームをバックグラウンドでポーリングします。そして新しいレコードを検出すると、1 つ以上のイベントを実行して、この Lambda 関数を呼び出します。Lambda 関数は各項目を処理し、 PutRecord API を使用して Kinesis Data Stream に書き込みます。Kinesis Data Streams は、Kinesis Client Library (KCL) を使用して構築された Lambda または Kinesis アプリケーションを使用して処理できます。
次の例はこのファンアウトパターンを示しています。

Kinesis Data Streams ファンアウトパターンを使用する際の利点には、以下が含まれます。
- Kinesis Data Streams は、 DynamoDB によって生成される書き込み順イベントへの手段を提供します。
- Lambda 関数の処理が失敗した場合、Lambda は成功するまで、またはストリームからのデータの有効期限が切れるまでレコードのバッチ全体を再試行します。この再試行のメカニズムによって、すべてのイベントが正しい順序で処理されます。AWS Lambda が失敗した際の処理の詳細については、「再試行動作について」を参照してください。
- 複数のデータストリームを一緒にチェーンすることで、Kinesis Data Streams のさらなるファンアウトが可能です。
- Kinesis Data Firehose を使用して Amazon S3、Amazon Redshift、Amazon Elasticsearch Service へデータのアーカイブができます。
- DynamoDB テーブル内で定義されたパーティションキー以外のパーティションキーを使用したデータ集約が可能です。
このパターンの弱点となるものには以下が含まれます。
- このパターンは、書き込み順を確実にするため PutRecord API のシリアル呼び出しパターンを奨励するため、スループットが制限されます。
- Lambda の処理が失敗すると、レコードのバッチ全体が再処理されるため、Kinesis Data Streams 内でレコードが重複することがあり、ダウンストリーム DynamoDB テーブルおよび Kinesis Data Streams でも重複することがあります。
次の図は、DynamoDB ストリームの順序付けられ、向上した並列処理を可能にする Kinesis Data Streams ファンアウトパターンを示します。これは、この記事の冒頭で触れたアプリケーションの要件に対応するものです。
 以下は前述のアーキテクチャ図の詳細な説明です。
以下は前述のアーキテクチャ図の詳細な説明です。
- DynamoDB は DynamoDB ストリームに項目の変更を中継する。
- Lambda は DynamoDB ストリームをポーリングし、ストリーム内で新しい項目を検出すると、設定されている Lambda 関数
StreamForwarderを呼び出す。 StreamForwarder関数は、書き込み順序を維持するためPutRecordAPI を使用して各項目を Kinesis Data Stream へ書き込む。- Kinesis Data Stream は Kinesis Data Firehose へのデータソースとして設定されている。
- Kinesis Data Firehose にストリームされるデータは Amazon S3 にアーカイブされる。
- Lambda は Kinesis Data Stream をポーリングし、設定済みの Lambda 関数を同時に呼び出す。
- Lambda 関数は SNS サブスクライバーにメールで通知する。
- Lambda 関数は DynamoDB テーブルにデータを集約して保存する。
- Lambda 関数はデータを別の Kinesis Data Stream に変換して挿入する。
- Lambda はこの Kinesis Data Stream をポーリングし、設定済みの Lambda 関数を同時に呼び出す。これにより、DynamoDB ストリームの並列処理がさらに増加する。
Kinesis Data Streams を使用して書き込み順序を有効化する
Kinesis Data Streams では、多くの Kinesis Data Streams アプリケーションに同じ順序でレコードの順序付け、レコードの読み込みと再生ができます。書き込みの順序付けを有効化するには、Kinesis Data Streamsで PutRecord API をコールしてシャードに逐次書き込むようにし、sequenceNumberForOrdering パラメータも使用します。このパラメータを設定することで、同じクライアントからの PutRecord、および同じパーティションキーへの PutRecord のシーケンス番号の数字が確実に増加することが保証されます。
次の Lambda 関数が、このストリームを処理する実装を示します。関数は PutRecord API をコールし、データを ProductCatalog Kinesis Data Stream に書き込みます。書き込み順を維持するため、関数は sequenceNumberForOrdering パラメータを、その前の項目に対する PutRecord API コールから取得した sequenceNumber の値で設定します。
PutRecord API への最初のコールは、前の sequenceNumber が存在しないため sequenceNumberForOrdering パラメータの設定なしに行われますが、その項目への書き込みは順序付けされます。それは Kinesis がこの項目の到達時間を基に順序付けるためで、実際 Lambda はその前の呼び出し後、少し遅れてこの関数を呼び出します。
結論
この記事では、DynamoDB ストリームの順序付けされたほぼリアルタイムの処理を実装するための Kinesis Data Streams の利用方法について説明しました。多数のファンアウトパターンを利用して、DynamoDB ストリームを並列処理することができます。しかし Kinesis Data Streams には、書き込み順、読み込み順、そしてスケーラブルな取り込みパイプラインという利点があります。また、Kinesis Client Library で書かれたアプリケーションを使用して、または Lambda を使用して Kinesis Data Streams からのデータを処理することもできます。しかしながら Kinesis Data Streamsを使用したファンアウトパターン実装時のスループットには、Lambda を使用した DynamoDB ストリームの並列処理と比較すると制限があります。ただし Lambda には 2 つしか読み込めないという制限があります。
今回のブログ投稿者について
 Aravind Kodandaramaiah はアマゾン ウェブ サービスのソリューションデベロッパーです。
Aravind Kodandaramaiah はアマゾン ウェブ サービスのソリューションデベロッパーです。